
深度學習-LeCun、Bengio和Hinton的聯合綜述
深度學習其實要入門也很簡單,不要被深度學習、卷積神經網路CNN、迴圈神經網路RNN等某些“高大上”的專有名詞所嚇到或被忽悠,要相信大道至簡,一個高中生只要願意學也完全可以入門級瞭解並依賴一些成熟的Tensorflow、pytorch等框架去實現一些常用模型。有關《深度學習》的綜述或翻譯已有很多,在此不在贅述,深度學習是機器學習的一種,今天將從更廣的視覺來分析。
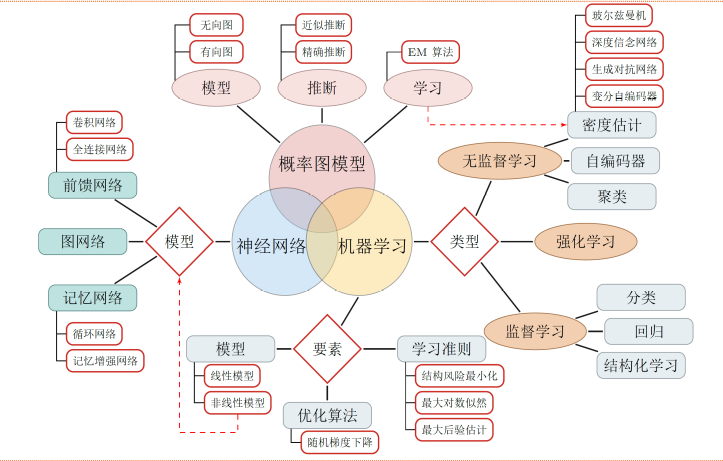
圖1 深度學習是機器學習的子問題
1.機器學習
機器學習(Machine Learning, ML)是指利用機器(計算機)從有限的觀測資料中通過訓練學習到一般性的規律,並將這些規律應用到新的未觀測樣本上的方法,正如人類可以通過多次訓練學習到騎自行車或者游泳的規律。傳統的機器學習處理流程一般需要將資料表示為一組特徵(Feature),特徵的表示可以是連續的數值、離散的符號或者其他形式。如下圖:
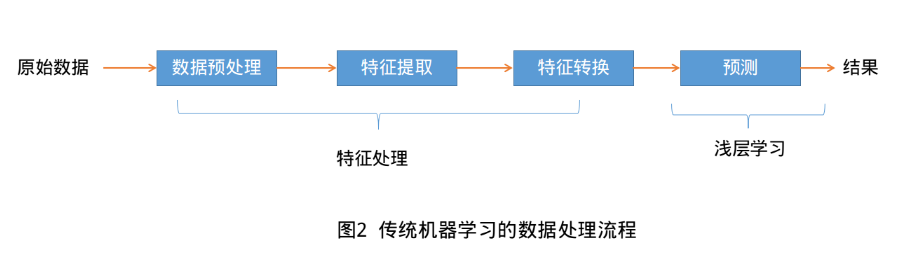
傳統機器學習主要包括資料預處理-->特徵處理(特徵提取、轉換和選擇)-->機器演算法學習訓練(核心)-->預測。 傳統的機器學習模型主要關注最後一步,即構建預測函式。但也遵從“二八定律”,前期的特徵處理(又叫特徵工程)需要大量的人工干預,需要結合具體問題專家領域背景的知識來從原始資料中進行特徵轉換加工,如特徵升維和降維。常用的特徵轉換方法主要有主成分分析(Principal components analysis, PCA)、線性判別分析(Linear Discriminant Analysis)等。由於需要人類的經驗來選取好的特徵,很多模式識別問題變成來特徵工程(Feature Engineering)問題。開發一個機器學習系統的主要工作量都消耗在來預處理、特徵提取以及特徵轉換上,佔用人工80%以上的精力。如何能自動化有效解決資料表示這個瓶頸成了眾多科學家追求的目標。
2.表示學習
為了提高機器學習系統的準確率,我們就需要將原始輸入資料資訊轉換為有效的特徵,或者更一般成為表示(representation)。如果有一種演算法可以自動的學習出有效的特徵,並最終提高機器學習模型的效能,那麼這種學習就叫做表示學習(Resprentation Learning). 那麼如何學習學習到一個好的表示呢? 通常我們使用兩種方式來表示特徵:區域性表示(Local Respresentation)和分散式表示(Distributed Respresentation).以文字分類中單詞的表示為例,傳統的區域性表示就是One-hot編碼,假設所有單詞構成一個詞表V,詞表大小為|V|,則可以用一個|V|維的Ont-Hot向量來表示每個單詞。第i個單詞的One-hot向量中,第i維的值為1,其它都為0.如下圖
粉紅色:[,0,0,0,0,0,0,…,0,0,0,0,0,0,0,1,0]
區域性表示有兩個很明顯的不足就是:(1)One-hot編碼維數很高,佔用空間大,且難以擴充套件。如碰到新詞,只能擴大詞表維數。(2)不同單詞相似度均為0,如上面例子中紅色和粉紅色語義上很接近,相似度卻被計算為0.
分散式表示是通過更低維的實數向量空間來表示,如文字中詞向量Word2vec演算法或顏色表示中的RGB表示法,將上萬維的Ont-hot編碼對映到一個非常低維的分散式表示空間R^d,d<<|V|.這這個低維空間中,每個特徵不在是座標軸上的點,而是分散中整個低維空間中,特徵之間也可以有語義上的相似度。這個過程也稱為嵌入(Embedding),所以文字中很多單詞表示稱為Word Embedding,詞嵌入。
3. 深度學習
要學習到一種好的高層語義表示(分散式表示),通常需要從底層特徵開始,經過多步非線性轉換才能得到(從底層特徵,到中層特徵,再到高層特徵)。這樣我們就需要一種學習方法可以從資料中學習一個“深度模型”,也就是深度學習(Deep Learning, DL).深度學習是機器學習的一個子問題,其主要目的是從資料中自動學習到有效的特徵表示。深度學習將原始的資料特徵通過多步轉換變成為更高層次、更抽象的表示。這些學習到的表示可以代替人工設計的特徵,從而避免昂貴的耗費大量人力的“特徵工程”。
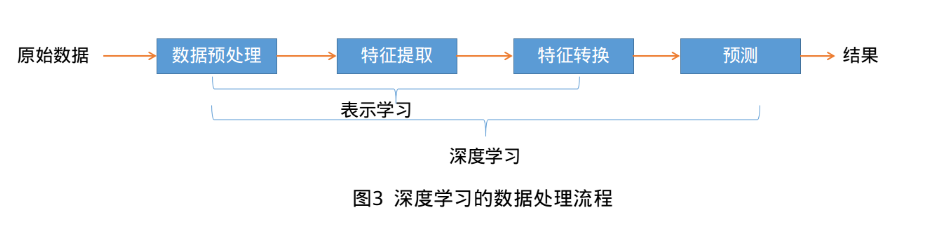
如何自動學習有效的資料表示成為機器學習中的關鍵問題。早期的表示方法,如特徵抽取和特徵選擇,需要人工引入一些主觀假設來進行學習,得到的表示不一定對後續的機器學習任務有效只能不斷嘗試。而深度學習是將表示學習和預測模型的學習進行端到端的學習,中間不需要人工干預。是的,深度學習核心原理說白了,就是這麼簡單————從原始資料經過一些簡單的但非線性的模型轉變成更高層次,更加抽象的表達。通過足夠多的轉換組合(深度),非常複雜的函式也可以被學習到。目前,深度學習主要以神經網路模型為基礎,研究如何設計模型結構,如何有效地學習模型的引數,如何優化模型效能以及在不同任務上的應用等。
4. 深度學習的反思
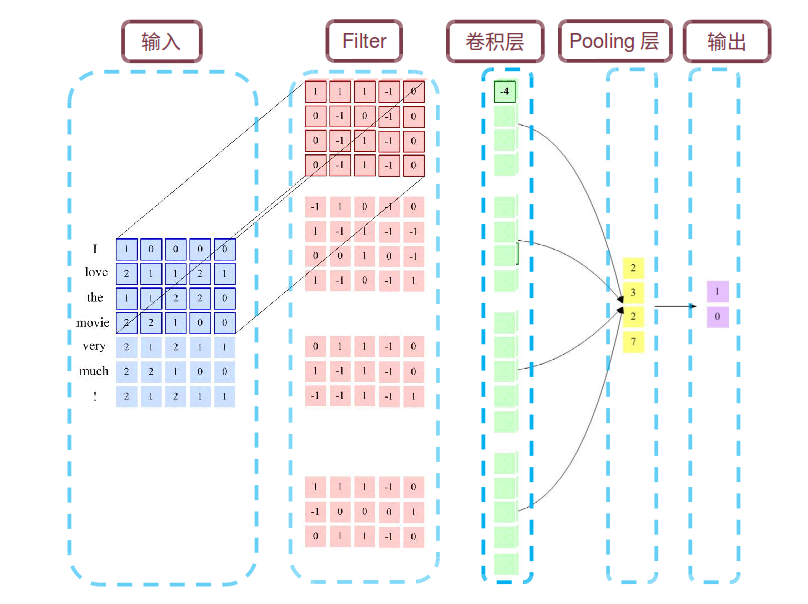
深度神經網路揭示了很多自然訊號具有複合結構的特點。高層特徵可以通過低層特徵組合得到。影象中,稜邊經過區域性組合可以構成基本圖案,基本圖案組合成部件,部件又構成物體。語音和文字也存在相似結構,由聲音到語音,再到音素、音節、單詞、句子、文章。下采樣層可以保證新的特徵層不敏感於前一層元素在位置和表現上的變化。
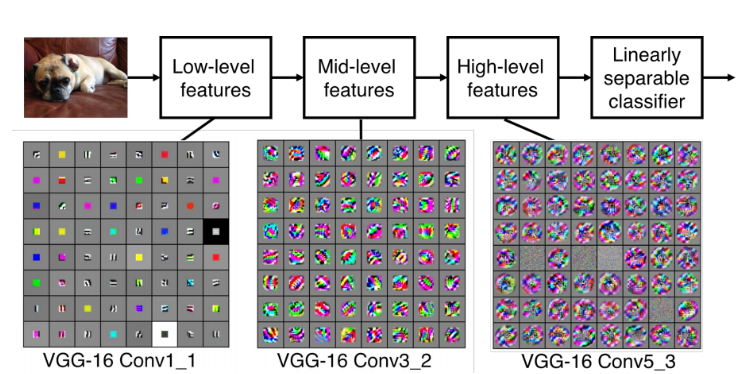
圖4 深度模型表示學習
深度學習模型有大量的引數,當模型引數遠大於資料量時,容易產生過擬合,層次不夠引數遠小於資料量時,相當於求超定方程,可能無解或者有解但準確率很低,即欠擬合問題。在當年的資料量和計算能力侷限下,深度學習與傳統機器學習方法並沒有太大的優勢。在2006年加拿大多倫多大學教授、機器學習泰斗——Geoffrey Hinton和他的學生Ruslan從理論層面論證多隱層的人工神經網路具有優異的特徵學習能力並提出“逐層初始化”有效克服訓練上的難點,特別是2012年Hinton的學生Alex在ILSVRC(ImageNet Large Scale Visual Recognition Challenge, ImageNet大規模視覺識別競賽, http://image-net.org/challenges/LSVRC/)上大比分桂冠後從真正開啟深度學習在學術和工業界的浪潮。深度神經網路原理好像也並不複雜,那麼為何發展了數十年是在2012年而不是其它時間爆發呢?
(1) 更大的資料集,如ImageNet
(2) 新的深度學習技術,如ReLU、Dropout等技術
(3) 新的計算硬體,如GPU,DCNN.
近些年隨著各大網際網路巨頭的發力,相關大資料集的釋出和深度學習框架的發展,未來必將不斷加速,取得更大的輝煌。
未來發展方向:
(1) 為了減少引數,提高泛化能力,提出卷積神經網路CNN: 區域性連線、權值共享、下采樣(匯聚操作)來簡化神經網路結構。ConvNet
(2) 為了解決資訊過載,增加網路容量,提出迴圈神經網路RNN:注意力和記憶機制: LSTM,GRU,Attention Model
(3) NLP相對於CV方向,更注重於邏輯推理,更具學術性、挑戰性,更難以工程落地。
常用的比較代表性和流行的深度學習框架:
(1) TensorFlow: 出身名門Google,將計算過程利用資料流圖來表示,功能強大,更新改進快。
(2) PyTorch: 同樣出身豪門FaceBook、NVIDIA、Twitter等公司開發維護,基於動態計算圖。在需要動態改變神經網路結構的任務中優勢明顯。
(3) Keras:基於Tensorflow和Theano, 更高一層封裝,簡單粗暴有效,但不夠靈活。
(4) Caffe:簡單方便,所要實現的網路結構可在配置檔案中指定,不需要編碼。主要用於計算機視覺。
此外,還有蒙特利爾大學的Theano, 日本的Chainer,微軟的CNTK,亞馬遜和卡內基梅隆大學的MXNet和百度開發的PaddlePaddle等。
&n