
大資料(hadoop-自定義資料型別、檔案格式)
阿新 • • 發佈:2019-06-11
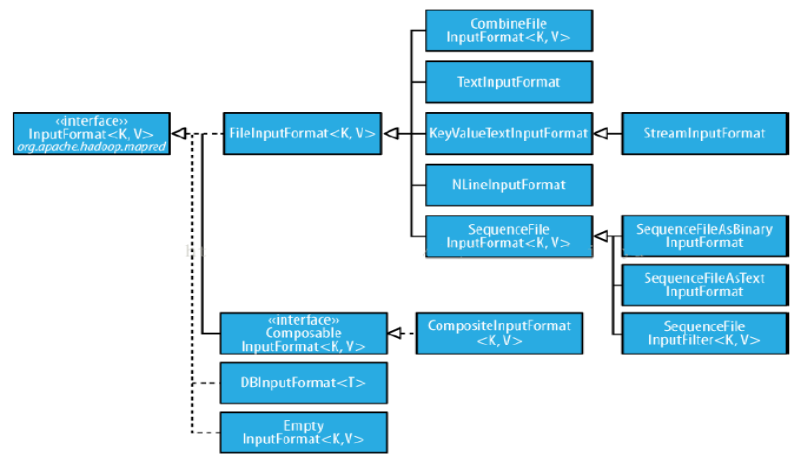
自定義InputFormat
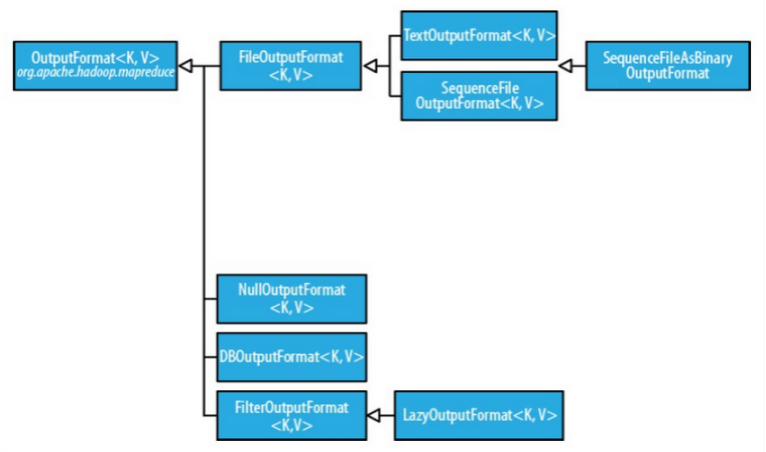
OutputFormat
示例程式碼
package com.vip09; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class ScoreWritable implements WritableComparable<Object>{ //在自定義的資料型別中,建議使用java原生的資料型別 private float chinese ; private float math ; private float english ; private float physics ; private float chemistry ; //在自定義的資料型別中,必須要有一個無參的構造方法 public ScoreWritable(){} public ScoreWritable(float chinese, float math, float english, float physics, float chemistry) { this.chinese = chinese; this.math = math; this.english = english; this.physics = physics; this.chemistry = chemistry; } public void set(float chinese, float math, float english, float physics, float chemistry){ this.chinese = chinese; this.math = math; this.english = english; this.physics = physics; this.chemistry = chemistry; } public float getChinese() { return chinese; } public float getMath() { return math; } public float getEnglish() { return english; } public float getPhysics() { return physics; } public float getChemistry() { return chemistry; } //是在寫入資料的時候呼叫,進行序列化 @Override public void write(DataOutput out) throws IOException { out.writeFloat(chinese); out.writeFloat(math); out.writeFloat(english); out.writeFloat(physics); out.writeFloat(chemistry); } //該方法是在取出資料時呼叫,反序列化,以便生成物件 @Override public void readFields(DataInput in) throws IOException { chinese = in.readFloat() ; math = in.readFloat() ; english = in.readFloat() ; physics = in.readFloat() ; chemistry = in.readFloat() ; } @Override public int compareTo(Object o) { // TODO Auto-generated method stub return 0; } }
package com.vip09; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class ScoreCount extends Configured implements Tool{ //map和reduce public static class ScoreMapper extends Mapper<Text, ScoreWritable, Text, ScoreWritable>{ @Override protected void map(Text key, ScoreWritable value, Context context) throws IOException, InterruptedException { context.write(key, value); } } public static class ScoreReducer extends Reducer<Text, ScoreWritable, Text, Text>{ private Text text = new Text() ; @Override protected void reduce(Text key, Iterable<ScoreWritable> value, Context context) throws IOException, InterruptedException { float totalScore = 0.0f ; float avgScore = 0.0f ; for (ScoreWritable sw : value) { totalScore = sw.getChinese() + sw.getEnglish() + sw.getMath() + sw.getPhysics() + sw.getChemistry() ; avgScore = totalScore/5 ; } text.set(totalScore + "\t" + avgScore); context.write(key, text); } } @Override public int run(String[] args) throws Exception { Configuration conf = new Configuration() ; //刪除已經存在的輸出目錄 Path mypath = new Path(args[1]) ; FileSystem hdfs = mypath.getFileSystem(conf); if(hdfs.isDirectory(mypath)){ hdfs.delete(mypath, true) ; } Job job = Job.getInstance(conf, "scorecount") ; job.setJarByClass(ScoreCount.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(ScoreMapper.class); job.setReducerClass(ScoreReducer.class); //如果是自定義的型別,需要進行設定 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(ScoreWritable.class); //設定自定義的輸入格式 job.setInputFormatClass(ScoreInputFormat.class); job.waitForCompletion(true) ; return 0; } public static void main(String[] args) throws Exception { String[] args0 = {"hdfs://192.168.153.111:9000/input5", "hdfs://192.168.153.111:9000/output15"} ; int res = ToolRunner.run(new ScoreCount(), args0) ; System.exit(res); } }
package com.vip09; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; public class ScoreInputFormat extends FileInputFormat<Text, ScoreWritable> { //需要注意的是: /* * 對於一個數據輸入格式,都需要一個對應的RecordReader * 重寫createRecordReader()方法,其實也就是重寫其返回的物件 * 這裡就是自定義的ScoreRecordReader類,該類需要繼承RecordReader,實現資料的讀取 * */ @Override public RecordReader<Text, ScoreWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { // TODO Auto-generated method stub return new ScoreRecordReader(); } }
package com.vip09;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.LineReader;
public class ScoreRecordReader extends RecordReader<Text, ScoreWritable>{
public LineReader in ; //行讀取器
public Text lineKey ; //自定義key型別
public ScoreWritable linevalue ; //自定義的value型別
public Text line ; //行資料
//初始化方法,只執行一次
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
FileSplit fsplit = (FileSplit)split ;
Configuration conf = context.getConfiguration();
Path file = fsplit.getPath();
FileSystem fs = file.getFileSystem(conf);
FSDataInputStream filein = fs.open(file);
in = new LineReader(filein, conf) ;
line = new Text() ;
lineKey = new Text() ;
linevalue = new ScoreWritable() ;
}
//讀取每一行資料的時候,都會執行該方法
//我們只需要根據自己的需求,重點編寫該方法即可,其他的方法比較固定,仿照就好
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
int linesize = in.readLine(line);
if(linesize == 0){
return false ;
}
String[] pieces = line.toString().split("\\s+") ;
if(pieces.length != 7){
throw new IOException("無效的資料") ;
}
//將學生的每門成績轉換為float型別
float a =0 , b= 0 , c = 0 ,d = 0, e =0 ;
try{
a = Float.parseFloat(pieces[2].trim()) ;
b = Float.parseFloat(pieces[3].trim()) ;
c = Float.parseFloat(pieces[4].trim()) ;
d = Float.parseFloat(pieces[5].trim()) ;
e = Float.parseFloat(pieces[6].trim()) ;
}catch(NumberFormatException nfe){
nfe.printStackTrace();
}
lineKey.set(pieces[0] + "\t" + pieces[1]); //完成自定義的key資料
linevalue.set(a, b, c, d, e); //封裝自定義的value資料
return true;
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return lineKey;
}
@Override
public ScoreWritable getCurrentValue() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return linevalue;
}
@Override
public float getProgress() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return 0;
}
@Override
public void close() throws IOException {
if(in != null){
in.close();
}
}
}
package com.vip09;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MapReduceCaseEmail extends Configured implements Tool{
public static class EmailMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1) ;
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
context.write(value, one);
}
}
public static class EmailReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable() ;
//輸出到多個檔案或多個資料夾,使用Multipleoutputs
private MultipleOutputs<Text, IntWritable> mout ;
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
mout = new MultipleOutputs<Text, IntWritable>(context) ;
}
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int begin = key.toString().indexOf("@") ;
int end = key.toString().indexOf(".") ;
if(begin >= end){
return ;
}
//獲取郵箱類別,比如qq,163等
String name = key.toString().substring(begin + 1, end);
int sum = 0 ;
for (IntWritable value : values) {
sum += value.get() ;
}
result.set(sum);
//baseoutputpath-r-nnnnn
mout.write(key, result, name);
}
@Override
protected void cleanup(Context context)
throws IOException, InterruptedException {
mout.close();
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration() ;
//刪除已經存在的輸出目錄
Path mypath = new Path(args[1]) ;
FileSystem hdfs = mypath.getFileSystem(conf);
if(hdfs.isDirectory(mypath)){
hdfs.delete(mypath, true) ;
}
Job job = Job.getInstance(conf, "emailcount") ;
job.setJarByClass(MapReduceCaseEmail.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(EmailMapper.class);
job.setReducerClass(EmailReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true) ;
return 0;
}
public static void main(String[] args) throws Exception {
String[] args0 = {"hdfs://192.168.153.111:9000/input6",
"hdfs://192.168.153.111:9000/output16"} ;
int res = ToolRunner.run(new MapReduceCaseEmail(), args0) ;
System.exit(res);
}
}