
大話注意力機制(Attention Mechanism)

當我們人類在看東西時,一般會將注意力集中注視著某個地方,而不會關注全部所有資訊。例如當我們一看到下面這張貓的圖片時,主要會將目光停留在貓的臉部,以及留意貓的軀幹,而後面的草地則會被當成背景忽略掉,也就是說我們在每一處空間位置上的注意力分佈是不一樣的。

通過這種方式,人類在需要重點關注的目標區域,會投入更多的注意力資源,以獲取更多的細節資訊,而抑制其它區域資訊,這樣使人類能夠利用有限的注意力資源從大量資訊中快速獲取到高價值的資訊,極大地提升了大腦處理資訊的效率。
那麼人類的這種“注意力機制”是否可用在AI中呢?
我們來看一下,圖片描述(Image Caption)中引入了“注意力機制”後的效果。“圖片描述”是深度學習的一個典型應用,即輸入一張圖片,AI系統根據圖片上的內容輸出一句描述文字出來。下面看一下“圖片描述”的效果,左邊是輸入原圖,下邊的句子是AI系統自動生成的描述文字,右邊是當AI系統生成劃橫線單詞的時候,對應圖片中聚焦的位置區域,如下圖:

可以看到,當輸出frisbee(飛碟)、dog(狗)等單詞時,AI系統會將注意力更多地分配給圖片中飛碟、狗的對應位置,以獲得更加準確地輸出,是不是很神奇呢,這又是如何實現的呢?
1、什麼是“注意力機制”
深度學習中的注意力機制(Attention Mechanism)和人類視覺的注意力機制類似,就是在眾多資訊中把注意力集中放在重要的點上,選出關鍵資訊,而忽略其他不重要的資訊。
2、Encoder-Decoder框架(編碼-解碼框架)
目前大多數的注意力模型附著在Encoder-Decoder框架下,所以我們先來了解下這個框架。Encoder-Decoder框架可以看作是一種文字處理領域的研究模式,該框架的抽象表示如下圖:

給定輸入X,通過Encoder-Decoder框架生成目標Y。其中,Encoder(編碼器)就是對輸入X進行編碼,通過非線性變換轉化為中間語義表示C;Decoder(解碼器),根據輸入X的語義表示C和之前已生成的歷史資訊生成目標資訊。
Encoder-Decoder框架是個通用框架,有很多的場景,在文字處理、影象處理、語音識別等各領域經常使用,Encoder、Decoder可使用各種模型組合,例如CNN/RNN/BiRNN/LSTM等。例如對於自動問答,X是一個問句,Y是答案;對於機器翻譯,X是一種語言,Y是另外一種語言;對於自動摘要,X是一篇文章,Y是摘要;對於圖片描述,X是一張圖片,Y是圖片的文字描述內容……
3、注意力模型
本文開頭講到的人類視覺注意力機制,它在處理資訊時注意力的分佈是不一樣的。而Encoder-Decoder框架將輸入X都編碼轉化為語義表示C,這樣就會導致所有輸入的處理權重都一樣,沒有體現出注意力集中,因此,也可看成是“分心模型”。
為了能體現注意力機制,將語義表示C進行擴充套件,用不同的C來表示不同注意力的集中程度,每個C的權重不一樣。那麼擴充套件後的Encoder-Decoder框架變為:

下面通過一個英文翻譯中文的例子來說明“注意力模型”。
例如輸入的英文句子是:Tom chase Jerry,目標的翻譯結果是“湯姆追逐傑瑞”。那麼在語言翻譯中,Tom, chase, Jerry這三個詞對翻譯結果的影響程度是不同的,其中,Tom, Jerry是主語、賓語,是兩個人名,chase是謂語,是動作,那麼這三個詞的影響程度大小順序分別是Jerry>Tom>chase,例如(Tom,0.3)(Chase,0.2) (Jerry,0.5),不同的影響程度代表AI模型在翻譯時分配給不同單詞的注意力大小,即分配的概率大小。
使用上圖擴充套件了Ci的Encoder-Decoder框架,則翻譯Tom chase Jerry的過程如下。
生成目標句子單詞的過程如下面的形式:
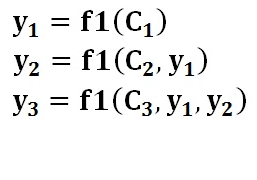
其中,f1是Decoder(解碼)的非線性變換函式
每個Ci對應著不同的源單詞的注意力分配概率分佈,計算如下面的形式:

其中,f2函式表示Encoder(編碼)節點中對輸入英文單詞的轉換函式,g函式代表Encoder(編碼)表示合成整個句子中間語義表示的變換函式,一般採用加權求和的方式,如下式:

其中aij表示權重,hj表示Encoder的轉換函式,即h1=f2(“Tom”),h2=f2(“Chase”),h3=f2(“Jerry”),Tx表示輸入句子的長度
當i是“湯姆”時,則注意力模型權重aij分別是0.6, 0.2, 0.2。那麼這個權重是如何得到的呢?
aij可以看做是一個概率,反映了hj對ci的重要性,可使用softmax來表示:
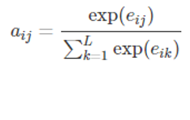
其中,
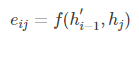
這裡的f表示一個匹配度的打分函式,可以是一個簡單的相似度計算,也可以是一個複雜的神經網路計算結果。在這裡,由於在計算ci時還沒有h’i,因此使用最接近的h’i-1代替。當匹配度越高,則aij的概率越大。
因此,得出aij的過程如下圖:
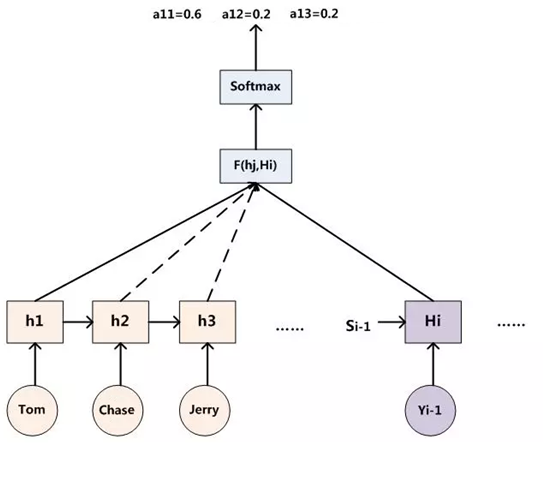
其中,hi表示Encoder轉換函式,F(hj,Hi)表示預測與目標的匹配打分函式
將以上過程串起來,則注意力模型的結構如下圖所示:
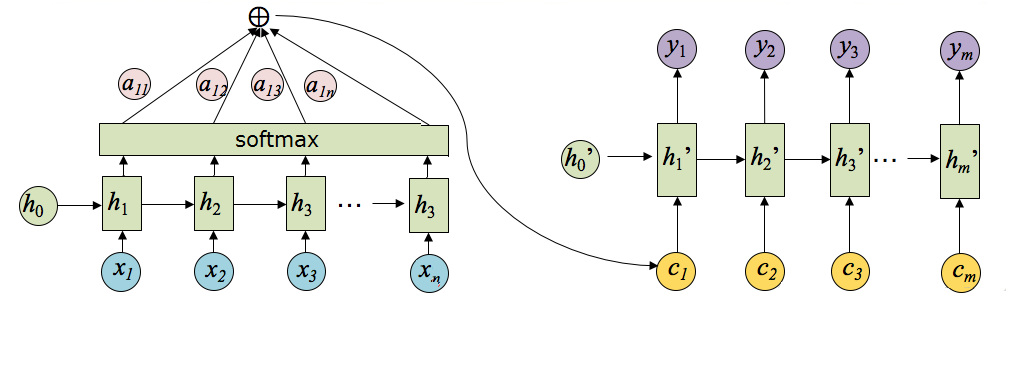
其中,hi表示Encoder階段的轉換函式,ci表示語義編碼,h’i表示Decoder階段的轉換函式。
以上介紹的就是經典的Soft-Attention模型,而注意力模型按不同維度還有其它很多分類。
4、注意力模型的分類
按注意力的可微性,可分為:
- Hard-Attention,就是0/1問題,某個區域要麼被關注,要麼不關注,這是一個不可微的注意力;
- Soft-Attention,[0,1]間連續分佈問題,用0到1的不同分值表示每個區域被關注的程度高低,這是一個可微的注意力。
按注意力的關注域,可分為:
- 空間域(spatial domain)
- 通道域(channel domain)
- 層域(layer domain)
- 混合域(mixed domain)
- 時間域(time domain)
推薦相關閱讀
1、AI 實戰系列
- 【AI實戰】手把手教你文字識別(文字檢測篇:MSER、CTPN、SegLink、EAST 等)
- 【AI實戰】手把手教你文字識別(入門篇:驗證碼識別)
- 【AI實戰】快速掌握TensorFlow(一):基本操作
- 【AI實戰】快速掌握TensorFlow(二):計算圖、會話
- 【AI實戰】快速掌握TensorFlow(三):激勵函式
- 【AI實戰】快速掌握TensorFlow(四):損失函式
- 【AI實戰】搭建基礎環境
- 【AI實戰】訓練第一個模型
- 【AI實戰】編寫人臉識別程式
- 【AI實戰】動手訓練目標檢測模型(SSD篇)
- 【AI實戰】動手訓練目標檢測模型(YOLO篇)
2、大話深度學習系列
- 【精華整理】CNN進化史
- 大話文字識別經典模型(CRNN)
- 大話文字檢測經典模型(CTPN)
- 大話文字檢測經典模型(SegLink)
- 大話文字檢測經典模型(EAST)
- 大話文字檢測經典模型(PixelLink)
- 大話卷積神經網路(CNN)
- 大話迴圈神經網路(RNN)
- 大話深度殘差網路(DRN)
- 大話深度信念網路(DBN)
- 大話CNN經典模型:LeNet
- 大話CNN經典模型:AlexNet
- 大話CNN經典模型:VGGNet
- 大話CNN經典模型:GoogLeNet
- 大話目標檢測經典模型:RCNN、Fast RCNN、Faster RCNN
- 大話目標檢測經典模型:Mask R-CNN
- 大話注意力機制
3、圖解 AI 系列
4、AI 雜談
5、大資料超詳細系列