
尋覓Azure上的Athena和BigQuery(一):落寞的ADLA
AWS Athena和Google BigQuery都是亞馬遜和谷歌各自雲上的優秀產品,有著相當高的使用者口碑。它們都屬於無伺服器互動式查詢型別的服務,能夠直接對位於雲端儲存中的資料進行訪問和查詢,免去了資料搬運的麻煩。對於在公有云的原生儲存上儲存有大量資料的許多客戶而言,此類服務無疑非常適合進行靈活的查詢分析,幫助業務進行資料洞察。
AWS Athena和Google BigQuery當然互相之間也存在一些側重和差異,例如Athena主要只支援外部表(使用S3作為資料來源),而BigQuery同時還支援自有的儲存,更接近一個完整的資料倉庫。因本文主要關注分析雲端儲存中資料的場景,所以兩者差異這裡不作展開。
對於習慣了Athena/BigQuery相關功能的Azure新使用者,自然也希望在微軟雲找到即席查詢雲端儲存資料這個常見需求的實現方式。這個問題比較少有直接而正面的回答,故本系列文章就此專題進行探討和實驗。
我們先以AWS Athena為例來看看所謂面向雲端儲存的互動式查詢是如何工作的。我們準備了一個約含一千行資料的小型csv檔案,放置在s3儲存中,然後使用Athena建立一個外部表指向此csv檔案:

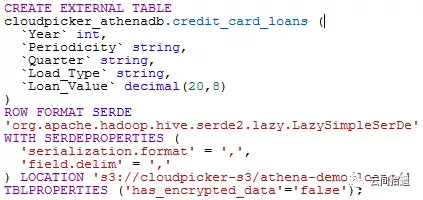
這裡使用的測試資料來自一個國外的公開資料集,是中東某地區的信用卡借貸資料,是公開且脫敏的。資料來源相關連結為 https://data.opendatasoft.com/explore/dataset/consumer-and-credit-card-loans%40kapsarc/information/?disjunctive.periodicity&disjunctive.quarter&disjunctive.load_type
然後我們建立一個簡單的SQL查詢,用以統計多年來每個季度的總借貸額並以降序排列:

得到的查詢結果為:

嗯,看上去AWS Athena輕鬆地完成了我們的分析任務。接下來則輪到Azure出場了。總的來說,Azure可以有多種服務和方式可達到類似AWS Athena的分析效果,不同的方法各自有優勢和取捨。
第一種方法,是使用Azure Data Lake Analytics(下簡稱ADLA)。因為從產品佈局上講,ADLA是與AWS Athena最為對應的Azure服務。該服務最初於2015年公佈,於2016年GA,筆者兩年前系統梳理微軟生態的文章中曾提到了它。該服務可通過與第一代的Azure Data Lake Storage(下簡稱ADLS)配套使用,實現大規模的資料並行處理與查詢。其主要支援的查詢語言是U-SQL,一個結合了SQL與C#特點的獨有語言。
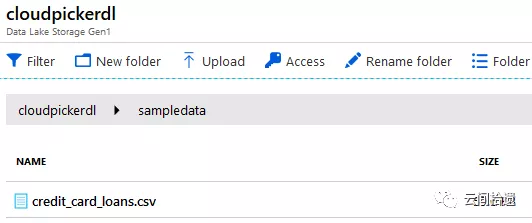
百聞不如一見,我們還是直接動手嘗試一下,使用ADLA來實現上面Athena的同樣任務。首先,需要把待分析檔案存入配合使用的儲存服務ADLS(ADLA/ADLS相關服務並未在Azure中國區上線,此處使用的是Global Azure):
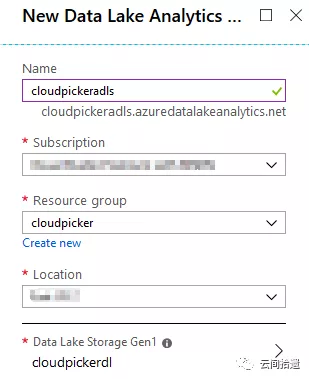
其次,需要新建一個ADLA的服務“賬戶”並指向剛才的ADLS儲存:
然後就可以開始進行資料查詢了。任務(Job)是ADLA中的核心概念,我們可以新建一個任務,配以一段U-SQL指令碼來表達和前面Athena例子中SQL相同的語義:(ADLA沒有互動式查詢視窗,所以我們把結果落地儲存到一個csv檔案中)
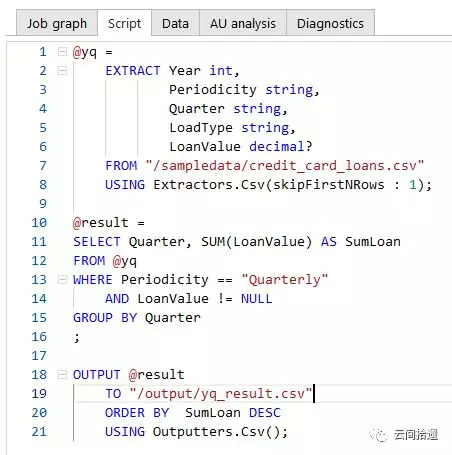
可以看到U-SQL寫起來很有意思,的確是結合了C#和SQL的語法與特點。與SQL類似,其核心處理物件為RowSet,即行的集合。我們的指令碼中沒有使用外部表(U-SQL中外部表僅支援SQLServer係數據庫)但通過Extractors.Csv方法達到了同樣的目的。事實上更復雜的U-SQL指令碼還可以新增上C#類庫引用和函式呼叫等功能,這樣結合兩種語言的優勢來撰寫指令碼可發揮各自優勢,使得ADLA具有十分強大的分析能力。
然後我們執行這個任務,ADLS的引擎就會開始執行相應指令碼,同時繪製出具體的執行計劃和步驟:
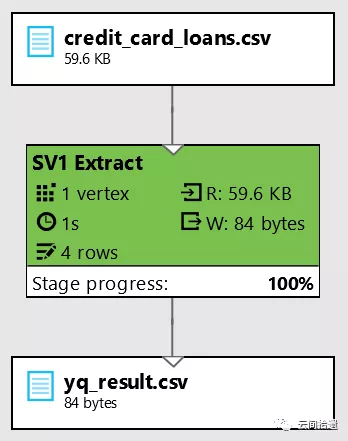
最後我們看一下輸出檔案的內容,同前面的結果是一致的:
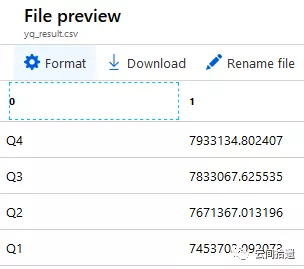
整個流程走下來,可以看到ADLA作為一個完全託管的服務,與Athena的設計理念的確是比較相近的,也能夠輕鬆使用指令碼直接針對物件儲存中的資料檔案進行資料分析。從Azure Portal上來看,整套產品也有著頗高的完成度:
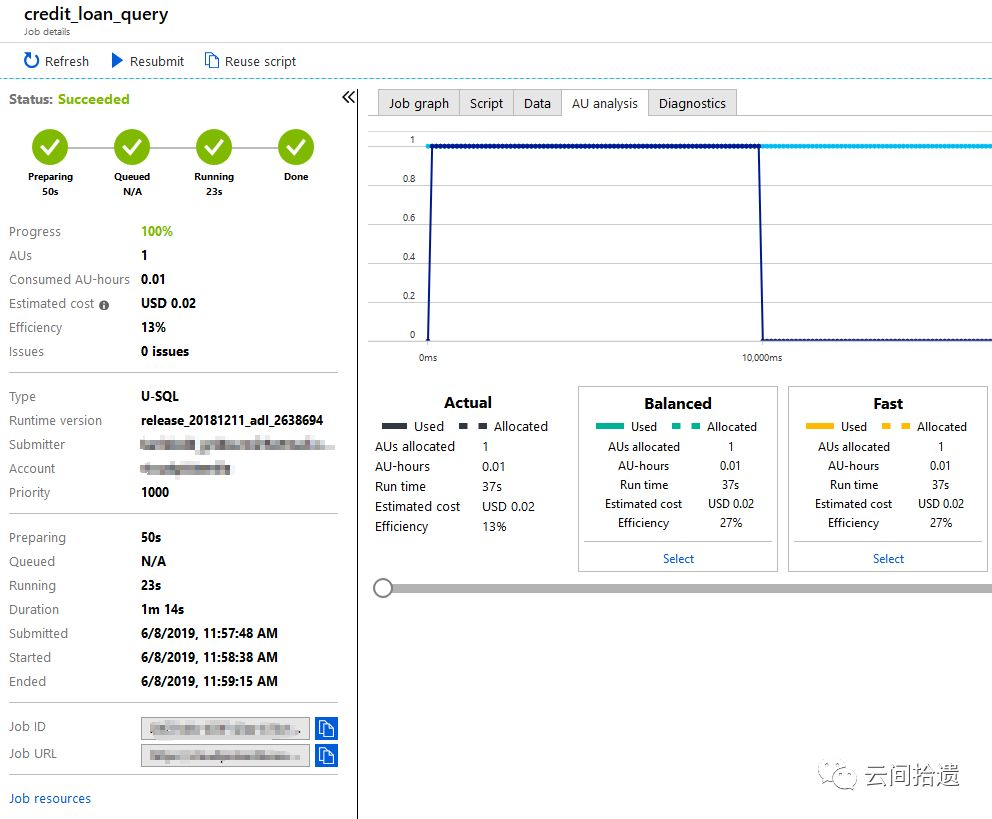
然而,通過實際的操作和體驗,我們也發現了ADLA在產品層面也還是存在一些短板,使得其使用範圍較為受限:
-
ADLA必須配合ADLS Gen1儲存使用,不能適用於最為常見的Azure Blob Storage,這在很多時候需要額外的資料搬運,也不便於應用程式整合;
-
U-SQL語言雖然有獨到之處,但畢竟有些“四不像”,配套的開發環境也尚不夠成熟,導致了學習和遷移成本很高,除錯起來更是非常麻煩(如果不熟悉語法,即便是上面這小段U-SQL也需要折騰好一會兒);
-
該服務主要為超大規模資料處理查詢所設計和優化,對於日常小規模的簡單資料處理顯得過於笨重和緩慢,例如我們上面的指令碼居然需要1分鐘左右來執行。
也許正由於如上所述產品上的種種不足,它正式釋出後叫好不叫座,市場反應比較冷清。逐漸地,ADLA產品似乎進入了維護狀態,新特性的更新較為緩慢;而坊間更是傳聞相應團隊已經重組,與Azure Storage及其他大資料產品團隊進行了整合——這一結果委實令人唏噓。要知道在ADLA/ADLS誕生之初,它們可是揹負著將微軟內部大資料平臺Cosmos(非現在的CosmosDB)進行雲產品化的重任。
其實我們願意相信ADLA背後的技術是十分過硬的,如果它在產品層面有更多的思考,例如更注重與現有Hadoop大資料生態和SQL體系的融合,或是進一步加入和充實.NET生態(如提供C# LINQ Provider),也許會有不同的結果。如今ADLA漸行漸遠的背影顯得有幾分落寞,但將來如果有可能,我們由衷期待它以另一種形式王者歸來。
讓我們回到本文的主題:面向雲端儲存的互動式資料查詢。綜上所述,ADLA不失為一個可行的辦法,但它也存在一些侷限和問題,而且在中國區並未釋出。那麼在Azure上是否還有其他的選擇呢?答案是肯定的。作為第二種方法,我們可以藉助源自SQL Server體系的一項神奇技術。欲知詳情如何,且聽下回分解。
“雲間拾遺”專注於從使用者視角介紹雲端計算產品與技術,堅持以實操體驗為核心輸出內容,同時結合產品邏輯和應用場景的深度解讀。歡迎掃描下方二維碼關注“雲間拾遺”公眾號,或訂閱本部落格。
