
《Predict Anchor Links across Social Networks via an Embedding Approach》閱讀筆記
基本資訊
文獻:Predict Anchor Links across Social Networks via an Embedding Approach
時間:2016
期刊:IJCAI
引言
預測跨社交網路的錨鏈接對於一系列應用具有重要意義,包括跨網路資訊擴散和跨域推薦。一個具有挑戰性的問題是:如果只有網路的結構資訊可用,我們是否能夠以及在多大程度上解決錨鏈預測問題。
有關錨鏈接的資訊通常在實際情況下不可用,因為大多數使用者沒有動機或不願意在不同的線上社交網路中明確關聯他們的身份。這就引出了錨鏈接預測的問題,即,識別跨不同社交網路的隱藏錨鏈接。利用網路結構進行錨鏈預測的現有方法分為兩大類:
第一類方法是以無監督的方法來解決,因此不需要任何關於跨網路的顯式對應的資訊。這些方法將錨鏈接預測問題看作一個網路結構對齊問題,通過在網路中找到節點之間的某些結構相似性來進行解決,但這種方法通常是 NP-Hard 的組合優化問題。因此,這些方法要麼限於具有中等規模的網路,要麼僅適用於稀疏假設下的大規模網路。
第二類方法是採用監督的方法,即通過已知的錨鏈接的監督來解決錨鏈接預測問題。大多數現有的監督方法直接採用社交網路的結構特徵,例如度,聚類係數,涉及的三角形的數量,共同的鄰居等。在沒有捕獲社交網路的內在結構規律的情況下,這些方法對網路結構特別敏感,因此網路結構的輕微變化或噪聲可能導致顯著不同的結果。
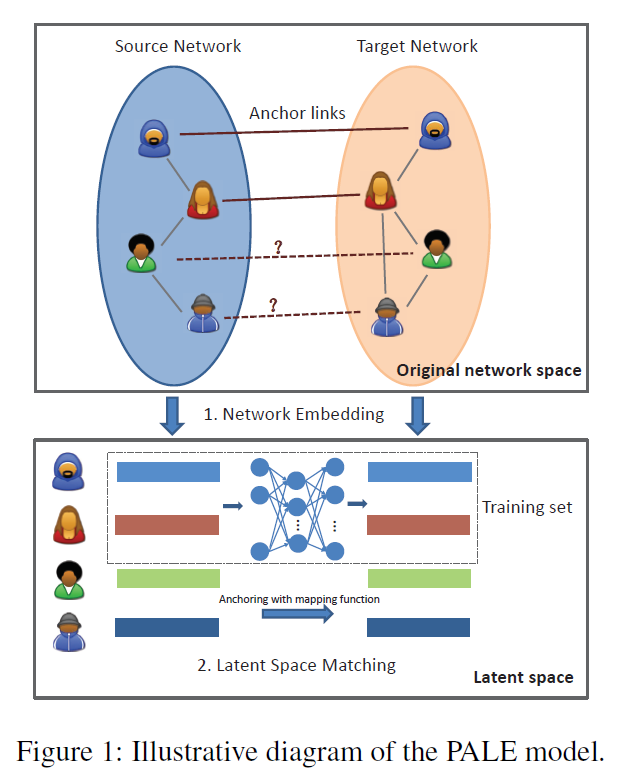
為了彌補這些差距,作者提出了一個新的監督方法,稱為 PALE(Predicting Anchor Links via Embedding)來解決錨鏈接預測問題。該模型包含兩個錨鏈接感知階段,即嵌入和匹配。
嵌入(Embedding):該階段主要是將每個網路嵌入到一個低維向量空間來學習每個節點的有效表示。通過這種方式,可以很好地捕獲網路的主要結構規律,同時濾除無關緊要的一些細節。同時,利用觀察到的錨鏈作為監督資訊,網路嵌入也保留了特定的結構規律,該方法使我們的模型對網路結構的微小變化具有魯棒性。
匹配(Matching):該階段主要是將節點的低維表示作為特徵,並以已經觀察到的錨鏈接作為監督資訊,從而學習兩個低維空間之間的對映函式。為了使得兩個潛在空間可以靈活地進行非線性相關,作者採用了多層感知器(MLP)來學習對映函式。最後,對於一個網路中的每個節點,我們根據學習的對映函式識別另一個網路中最可能的對應節點。
除了魯棒性之外,作者提出的模型的另一個重要優點是網路結構的低維表示可以容易地與內容和人口統計特徵相結合,以進一步提高錨鏈預測的準確性。
Predict Anchor Links via Embedding
令 \(G=\lbrace V,E \rbrace\) 表示一個社交網路,\(V\) 表示節點集合,\(E\subset (V\times V)\) 表示邊集合。在生活中,存在一些使用者同時涉及到兩個不同的社交網路中,從而兩個社交網路間的錨鏈接。為了不失一般性,將其中一個網路作為源網路,另一個網路作為目標網路,分別用 \(G^s\) 和 \(G^t\) 表示。對於源網路的每一個節點,我們的目的是在目標網路中識別其對應的節點(如果存在的話)。這可以正式表述為以下錨鏈接預測問題。
Anchor link prediction:
給定兩個社交網路 \(G^s=\lbrace V^s,E^s \rbrace\) 和 \(G^t=\lbrace V^t,E^t \rbrace\) ,和一個已經觀察到的錨鏈接集合 \(T=\lbrace (v,u)|v\in V^s, u\in V^t \rbrace\),該問題旨在識別 \(G^s\) 和 \(G^t\) 間的其它隱藏錨鏈接。
作者通過將兩個社交網路分別表示為兩個低維空間 \(Z^s\) 和 \(Z^t\) ,然後再學習兩個嵌入空間的對映函式: \(\phi:Z^s \to Z^t\)。因此,PALE 模型的目的就是通過最小化下列目標函式來找到最佳的 \(Z^s\), \(Z^t\) 和 \(\phi\) 。
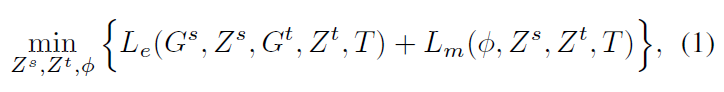
其中,\(L_e(G^s,Z^s,G^t,Z^t,T)\) 表示將源網路 \(G^s\) 和目標網路 \(G^t\) 分別轉化為低維空間 \(Z^s\) 和 \(Z^t\) 的損失,而 \(L_m(\phi, Z^s,Z^t,T)\) 是匹配時的損失函式,反映了匹配函式 \(\phi\) 是否將在 \(T\) 中已知的錨鏈接正確預測。
然而,由於 \(Z^s\), \(Z^t\) 和 \(\phi\) 之間的相互依賴,上述的目標函式很難得到有效地最優解。因此,作者採用了兩階段的嵌入和匹配的方法來轉而去找到一個近似解。如下圖所示:
嵌入階段
該階段將每一個網路都嵌入到一個低維潛在空間,每個節點 \(v_i\) 被表示為一個低維向量 \(z_i\)。該問題的關鍵是對社交網路中那些未觀察到的邊的處理,即那些還未明確建立地或者沒有爬取成功的社交關係。當將網路嵌入潛在空間時,這些缺失的邊可能導致不可靠的表示。
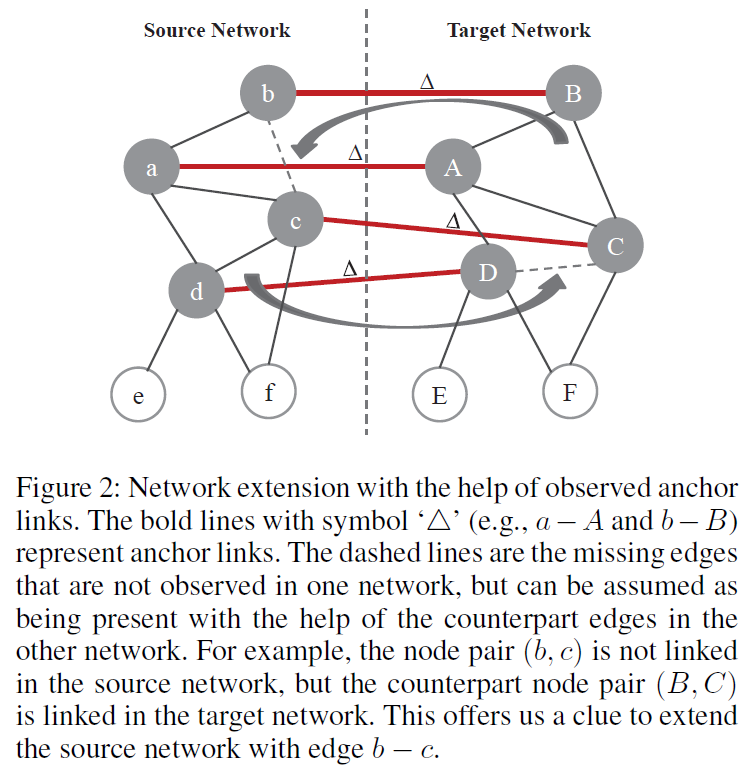
跨網路擴充套件
因此,作者提出了一個基於已經觀察到的錨鏈接和其它網路的社交結構來識別隱藏的邊的策略。如果兩個節點在一個社交網路中沒有關聯關係,但是他們在另一個社交網路中的對應節點間存在關聯關係,則應該在當前網路中增加這兩個節點間的邊,如 Figure 2 所示:
即,對於給定的兩個社交網路 \(G^s\) 和 \(G^t\),以及它們之間的已觀察到的錨鏈接集合 \(T\)。源網路 \(G^s\) 的擴充套件網路 \(\tilde{G}^s\) 可以表示為:
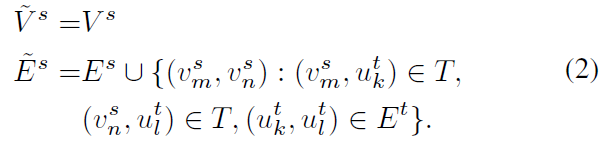
注意,在該模型中,擴網路擴充套件並不是強制要求的。該步驟只是為了更好地進行網路表示。
網路嵌入
由於是獨立地將兩個網路嵌入到兩個向量空間,所以該部分對於源網路和目標網路使用不加上標的統一表示。對於一對節點 \(v_i\) 和 \(v_j\),給定他們的 \(d\) 維表示 \(z_i\) 和 \(z_j\),則它們之間觀察到邊的概率為:
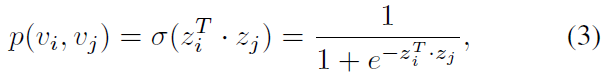
為了學習網路的潛在表示,作者採用極大似然估計的方法,即根據給定的網路結構來反推出最有可能出現該結構的節點表示,即最大化以下目標函式:
\[L=\prod_{(i,j)\in \tilde{E}}{p(v_i,v_j)}\]
將其轉化為對數似然函式:
\[\sum_{(i,j)\in \tilde{E}}{\log p(v_i,v_j)}=\sum_{(i,j)\in \tilde{E}}{\log \sigma(z_i^T\cdot z_j)}\]
作者進一步引入了負取樣機制,但是這部分的原理本人沒有弄懂:
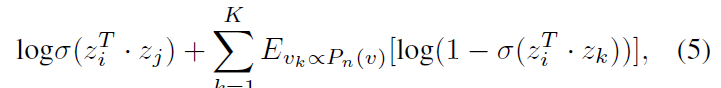
直接使用極大似然估計會存在什麼問題?
負取樣的原理和機制是怎麼樣的?
負取樣的推理過程?
其中,第一項對已觀察的邊進行建模,第二個期望項從一個空模型中取樣負邊(negative edges),每個節點以概率 \(P_n(v)\sim d_v^{3/4}\),\(K\) 為取樣的負邊的數目,\(d_v\) 為節點的度。通過分別對兩個社交網路中所有邊按照公式(5)求和並進行最大化就能得到兩個社交網路的潛在表示,最大化的過程可以將其轉化為最小化而使用隨機梯度下降的方法。
負取樣
本文提到的負取樣機制參考了 skip-gram 模型,具體內容可以參看 文獻一 和 基於 Negative Sampling 的模型。
該思想是採用了噪音對比估計(Noise Contrastive Estimation, NCE),該方法認為一個好的模型應該能夠通過邏輯迴歸將資料與噪聲區分開來。由於 Skipgram 模型僅關注學習高質量的向量表示,因此只要向量表示保持其質量,我們就可以自由地簡化 NCE 。採用公式(4)的方式定義負取樣來替換 Skip-gram 目標函式中的每一個 \(\log P(w_O|w_I)\) 項。因此,任務是使用邏輯迴歸將目標詞 \(w_O\) 與從噪聲分佈 \(P_n(w)\) 抽樣的詞區分開,其中對於每個資料樣本存在 k 個負樣本。負取樣和 NCE 之間的主要區別在於 NCE 需要樣本和噪聲分佈的數值概率,而負取樣僅使用樣本。
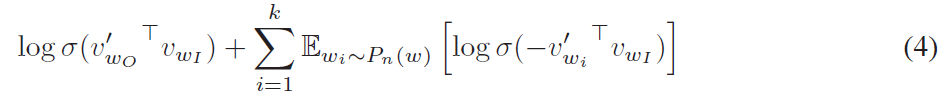
匹配階段
在匹配階段,基於學習到的兩個網路的潛在表示,其目的是利用已知的錨鏈接 \((v_l^s,u_n^t)\in T\) 以及對應的潛在表示 \(z_l^s\) 和 \(z_n^t\) 來學習一個對映函式 \(\phi\)。對映函式的目的是使得在源網路 \(Z^s\) 中的節點表示 \(z_l^s\) ,經過對映函式 \(\phi\) 後,其與在目標網路 \(Z^t\) 中對應節點的距離應該最小。令 \(\Theta\) 表示對映函式的所有引數,則損失函式可以如下定義:
\[L_m(\phi,Z^s,Z^t,T)=\sum_{(v_l^s,u_n^t)\in T}{||\phi(z_l^s;\Theta)-z_n^t||_F}\]
對於對映函式,作者分別考慮了線性和非線性函式。
對於線性對映函式,\(\Theta\) 是一個 \(d\times d\) 維的矩陣,即:
\[\phi(z_l^s;\Theta)=\Theta \times z_l^s\]
其目的是找到一個最好的矩陣 \(\Theta\) ,使得對於所有標記的錨鏈接對 \((v_l^s,u_n^t)\in T\) 都有 \(\Theta \times v_l^s\) 非常近似於 \(v_n^t\) 。
對於非線性對映函式,作者採用了多層感知器(MLP)來捕獲源空間和目標空間的非線性關係。以這種方式,在網路嵌入階段中獲得的兩個空間不需要線性對齊,這為嵌入階段提供了更大的靈活性以捕獲網路的結構規律。
錨鏈接預測
預測階段,對於源網路中的任意一個節點 \(v_l^s\),首先獲取其嵌入表示 \(z_l^s\);然後根據學習到的對映函式 \(\phi(z_l^s; \Theta)\) 將其對映到目標向量空間;最後通過識別與 \(\phi(z_l^s; \Theta)\) 最接近的對應節點 \(u_n^t\) 來預測錨鏈接,對應節點可以通過以下方式查詢:
\[\min_n||\phi(z_l^s; \Theta)-z_n^t||_F\]
對於源網路的每個節點,都可以通過上述方式提供目標網路中的一個候選節點列表。從而用
hits指標評估。
時間複雜度
在嵌入階段,一個網路 \(G\) 的總時間複雜度為 \(O(kd|E|)\),其中 \(k\) 為迭代次數,\(d\) 是嵌入向量的維度,\(|E|\) 是網路中邊的數目。
在潛在空間匹配階段,線性對映函式和非線性對映函式有不同的時間複雜度。線性對映函式的時間複雜度為 \(O(|T|d^3)\);而使用 MLP 作為非線性對映函式,其時間複雜度為 \(O(kd|T|)\)。
在預測階段,對於任意一個節點,識別其在目標網路中的對應節點的時間複雜度為 \(O(|V|d^2)\)。
實驗
實驗採用兩個資料集,一個是基於 Facebook 取樣的兩個子網路,另一個則是不同研究領域的兩個共同作者網路。對比方案分別為:
- Degree-Based Alignment:即依據節點的度來進行匹配,作為一個基線方法;
- Matching Across Domains(MAD):它通過奇異值分解來匹配同構網路上的共享節點,採用無監督方法;
- Multi-Network Anchoring(MNA):它從部分對齊的社交網路中提取成對的社交特徵,然後將錨鏈接預測問題解決為分類問題;
- Collective Random Walk(CRW):在具有錨鏈接的網路上進行隨機遊走以識別另一網路中的每個節點的對應物;
- PALE(LIN):PALE 模型加上線性對映函式;
- PALE(MLP):PALE 模型加上 MLP 作為非線性對映函式。
評估指標採用 F1-measure 和 MAP@30。
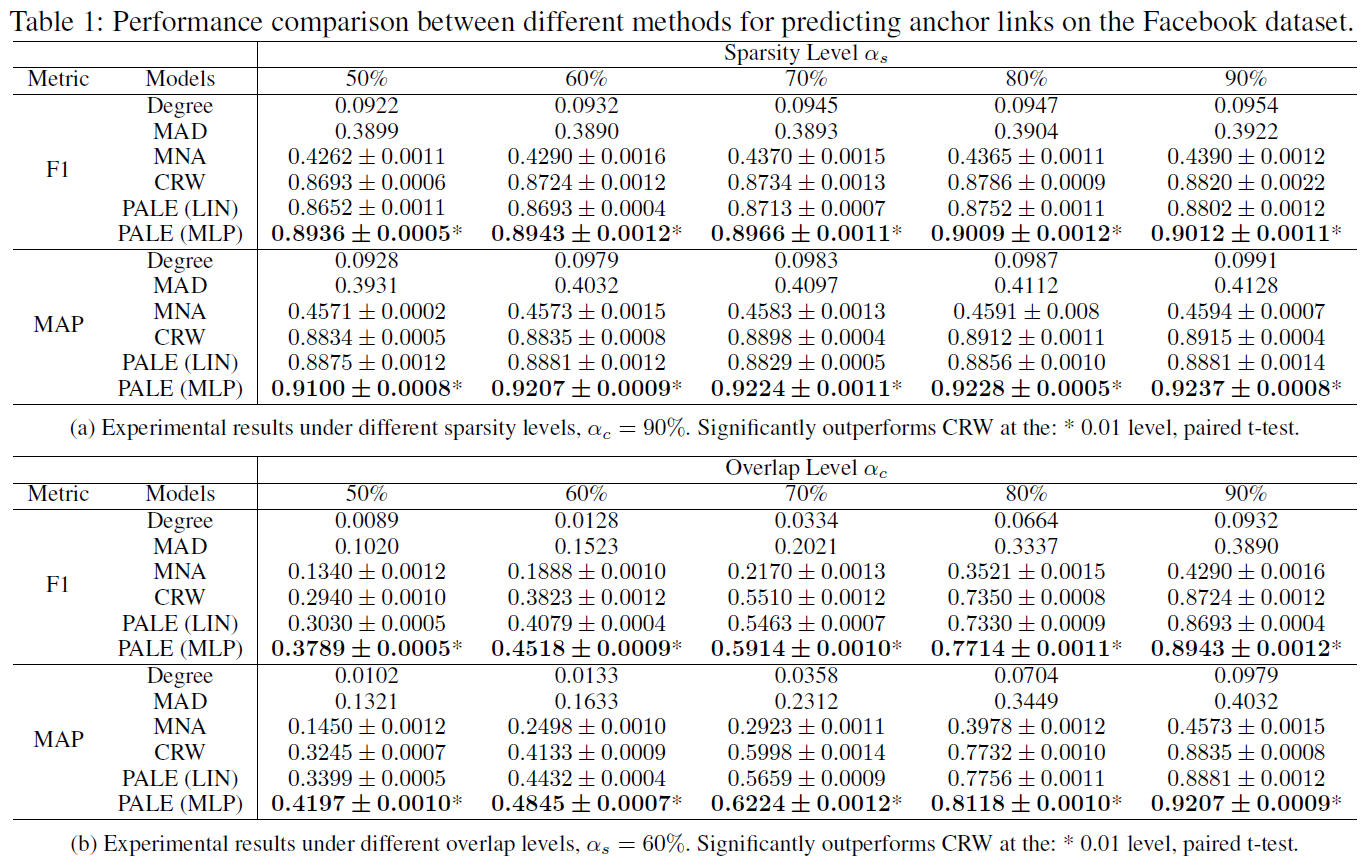
基於 Facebook 的實驗
第一個資料集為 Facebook 資料集,作者首先過濾了那些度小於 5 的節點,最終保留了 40710 個使用者和 766519 條邊。接著作者基於過濾的資料取樣得到兩個子網路,每個網路都保留了原始網路中的所有節點。而對於每一條邊,利用 [0, 1] 均勻分佈來生成一個隨機值。如果 \(p\leq 1-2\alpha_s+\alpha_s\alpha_c\),直接丟棄這條邊;如果 \(1-2\alpha_s+\alpha_s\alpha_c < p \leq 1-\alpha_s\),則將其只保留在第一個子網路中;如果 \(1-\alpha_s< p \leq 1-\alpha_s\alpha_c\) ,則將其只保留在第二個子網路中;否則,將該條邊同時保留在兩個子網路中。通過上述方式,兩個子網路都平均保留了原始網路中的 \(\alpha_s\) 比例的邊。引數 \(\alpha_c\) 表明了兩個子網路中有多少比例的邊是共享的。
由於兩個子網路都保留了原始網路中的所有節點,所以源網路和目標網路中的每對對應的節點都是可以作為 ground truth 的錨鏈接,實驗選擇其中的 \(\alpha_t\) 作為監督錨鏈接集合 \(T\),並分別在不同的稀疏級別 \(\alpha_s\) 和不同的覆蓋級別 \(\alpha_c\) 上進行實驗。
基於共同作者網路的實驗
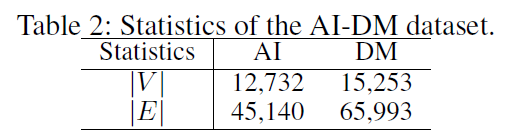
第二個資料集是由人工智慧(AI)和資料探勘(DM)領域的會議論文組成的共同作者網路,表示為 AI-DM。該資料集來源於 MAG ,這是一個異構圖,包含出版物的數目資訊,出版物之間的引文關係,以及作者和機構的資訊。作者分別選擇了 AI 和 DM 領域的 10 個會議,然後在這兩組論文上建立了兩個共同作者網路,並且過濾掉少於 3 個共同作者關係的作者。這兩個網路間有 1154 個共同作者,形成了錨鏈接的 ground truth。

相關推薦
《Predict Anchor Links across Social Networks via an Embedding Approach》閱讀筆記
基本資訊 文獻:Predict Anchor Links across Social Networks via an Embedding Approach 時間:2016 期刊:IJCAI 引言 預測跨社交網路的錨鏈接對於一系列應用具有重要意義,包括跨網路資訊擴散和跨域推薦。一個具有挑戰性的問題是:如果只有網
Grad-CAM:Visual Explanations from Deep Networks via Gradient-based L閱讀筆記-網路視覺化NO.3
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization 閱讀筆記 這是網路視覺化的第三篇,其餘兩篇分別是: ①《Visualizing and
Generative Adversarial Networks: An Overview文獻閱讀筆記
Generative Adversarial Networks: An Overview筆記 Abstract Generative adversarial networks (GANs) provide a way to learn deep representations w
(DaSiamRPN)Distractor-aware Siamese Networks for Visual Object Tracking 閱讀筆記
2018年的VOT競賽結果已出,基於深度特徵(Deep Feature)的相關濾波依舊強勢,但值得注意的是,基於孿生網路(Siamese Network)的方法異軍突起,在主賽上有不俗表現的同時,在實時
Squeeze-and-Excitation Networks(SE network)閱讀筆記
SE Block詳解 SE Block通過學習通道之間的關係,調節特徵圖通道之間的權重,從而達到attention集中的目的,改善網路的表達能力。 SE Block可以替代任意的卷積操作。 上圖為SE Block描述圖。可以看到,通過SE Block以後特
Recommendations in LBSN Social Networks(Notes)
rfi behaviors instant oge for nsh structure pap common Recommendations in LBSN Social Networks Section 2 Concepts of LBSN Social Networks
Estimating the number of receiving nodes in 802.11 networks via machine learning
當前 網絡通信 works 存儲 bsp ron 測量 分析 輸入 來源:IEEE International Conference on Communications 作者:Matteo Maria 年份:2016 摘要: 現如今很多移動設備都配有多個無線接口,比如藍牙
Addiction and Microtargeting: How “Social” Networks Expose us to Manipulation
Roger McNamee, an early investor in Facebook, has stated that to keep us occupied such platforms “have taken all the techniques of Edward Bernays and Josep
New social infrastructure for an algorithmic world: Coping not Coding, Part 1
New social infrastructure for an algorithmic worldThe Internet and data are making new demands on society and we’re increasingly being asked to adapt as in
Marginally Interesting: Pheed, Tent.io, and the Future of Social Networks
Tweet Pheed made the news lately because they managed to get a large nu
【論文:麥克風陣列增強】An alternative approach to linearly constrained adaptive beamforming
tor rain 延遲 margin 不同 .cn 估計 梯度下降 rst 作者:桂。 時間:2017-06-03 21:46:59 鏈接:http://www.cnblogs.com/xingshansi/p/6937259.html 原文下載:http://p
閱讀筆記:ImageNet Classification with Deep Convolutional Neural Networks
時間 ica gpu ati 做了 alexnet 小數 而且 響應 概要: 本文中的Alexnet神經網絡在LSVRC-2010圖像分類比賽中得到了第一名和第五名,將120萬高分辨率的圖像分到1000不同的類別中,分類結果比以往的神經網絡的分類都要好。為了訓練更快,使用了
論文閱讀筆記(六)Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
采樣 分享 最終 產生 pre 運算 減少 att 我們 作者:Shaoqing Ren, Kaiming He, Ross Girshick, and Jian SunSPPnet、Fast R-CNN等目標檢測算法已經大幅降低了目標檢測網絡的運行時間。可是盡管如此,仍然
[論文學習]An Effective Approach for Mining Mobile User Habits:一種高效挖掘移動使用者習慣的方法
原文: Cao H, Bao T, Yang Q, et al. An effective approach for mining mobile user habits[C]//Proceedings of the 19th ACM international confere
論文閱讀筆記(九)YOLOv3: An Incremental Improvement
專案地址 Abstract 該技術報告主要介紹了作者對 YOLOv1 的一系列改進措施(注意:不是對YOLOv2,但是借鑑了YOLOv2中的部分改進措施)。雖然改進後的網路較YOLOv1大一些,但是檢測結果更精確,執行速度依然很快。在輸入影象解析度
CLR VIA C# 閱讀筆記和感悟(三)
前言:如今.NetCore已經進入了2.1版本,但這本書的學習還是很重要,我們繼續學習和總結,以便於在.NetCore新技術的學習上能有個對比,幫助我們學習新知識。 執行緒池:執行緒的建立和銷燬都是要消耗資源的,所以微軟為了優化執行緒的使用,提出了執行緒池,執行緒池中的執行緒是可重用的,線上程初始
CLR VIA C# 閱讀筆記和感悟(二)
GC垃圾回收:垃圾回收機制其實是對記憶體的碎片化管理,首先會暫停所有執行緒的執行,防止碎片化管理時,物件的狀態被修改,然後遍歷託管堆中的所有物件,刪除沒有變數引用的物件,並且移動堆中的所有物件的記憶體地址,刪除物件之間的空隙,變成一塊連續的記憶體,提高物件的引用效率,節省更多的記憶體空間,但這會導致
CLR VIA C# 的閱讀筆記和感悟(一)
寫在前面的話: 工作一年了,從最初的小白,通過慢慢地做專案,百度查資料,慢慢地也適應了程式設計師的工作,從最初做專案的焦頭爛額,到現在已經可以較為輕鬆得從事開發工作,當然還是停留在簡單開發的層次,就是根
Flower classification using deep convolutional neural networks 閱讀筆記
** Flower classification using deep convolutional neural networks ** 本部落格主要是對該篇論文做一個閱讀筆記 ,用FCN+CNN去做識別 期刊: IET Computer Vision 內容: (1)自動分割
03.敏捷估計與規劃——An Agile Approach筆記
00.敏捷開發過程承認每個人都具有特定的能力(以及缺點)並對之加以利用,而不是試圖把所有人都當作一樣。 01.敏捷開發小組認為可用軟體的價值重於複雜的文件。其原因在於,可用的軟體可以幫助開發人員在每次迭代結束時獲得一個穩定的、逐漸增強的版本,從而允許儘早開始,並且更為頻繁地收集對產品過程的反