
ZooKeeper 系列(一)—— ZooKeeper核心概念詳解
一、Zookeeper簡介
Zookeeper是一個開源的分散式協調服務,目前由Apache進行維護。Zookeeper可以用於實現分散式系統中常見的釋出/訂閱、負載均衡、命令服務、分散式協調/通知、叢集管理、Master選舉、分散式鎖和分散式佇列等功能。它具有以下特性:
- 順序一致性:從一個客戶端發起的事務請求,最終都會嚴格按照其發起順序被應用到Zookeeper中;
- 原子性:所有事務請求的處理結果在整個叢集中所有機器上都是一致的;不存在部分機器應用了該事務,而另一部分沒有應用的情況;
- 單一檢視:所有客戶端看到的服務端資料模型都是一致的;
- 可靠性:一旦服務端成功應用了一個事務,則其引起的改變會一直保留,直到被另外一個事務所更改;
- 實時性:一旦一個事務被成功應用後,Zookeeper可以保證客戶端立即可以讀取到這個事務變更後的最新狀態的資料。
二、Zookeeper設計目標
Zookeeper致力於為那些高吞吐的大型分散式系統提供一個高效能、高可用、且具有嚴格順序訪問控制能力的分散式協調服務。它具有以下四個目標:
2.1 目標一:簡單的資料模型
Zookeeper通過樹形結構來儲存資料,它由一系列被稱為ZNode的資料節點組成,類似於常見的檔案系統。不過和常見的檔案系統不同,Zookeeper將資料全量儲存在記憶體中,以此來實現高吞吐,減少訪問延遲。
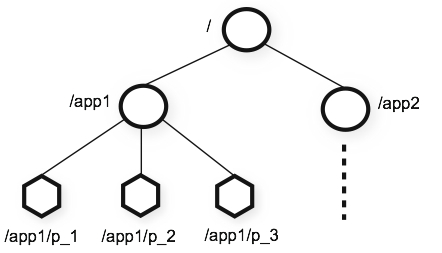
2.2 目標二:構建叢集
可以由一組Zookeeper服務構成Zookeeper叢集,叢集中每臺機器都會單獨在記憶體中維護自身的狀態,並且每臺機器之間都保持著通訊,只要叢集中有半數機器能夠正常工作,那麼整個叢集就可以正常提供服務。
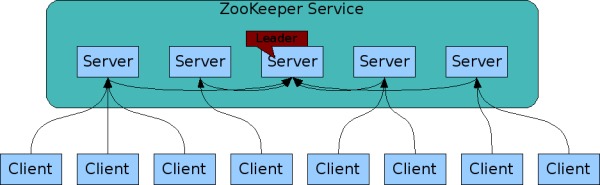
2.3 目標三:順序訪問
對於來自客戶端的每個更新請求,Zookeeper都會分配一個全域性唯一的遞增ID,這個ID反映了所有事務請求的先後順序。
2.4 目標四:高效能高可用
ZooKeeper將資料存全量儲在記憶體中以保持高效能,並通過服務叢集來實現高可用,由於Zookeeper的所有更新和刪除都是基於事務的,所以其在讀多寫少的應用場景中有著很高的效能表現。
三、核心概念
3.1 叢集角色
Zookeeper叢集中的機器分為以下三種角色:
- Leader :為客戶端提供讀寫服務,並維護叢集狀態,它是由叢集選舉所產生的;
- Follower :為客戶端提供讀寫服務,並定期向Leader彙報自己的節點狀態。同時也參與寫操作“過半寫成功”的策略和Leader的選舉;
- Observer :為客戶端提供讀寫服務,並定期向Leader彙報自己的節點狀態,但不參與寫操作“過半寫成功”的策略和Leader的選舉,因此Observer可以在不影響寫效能的情況下提升叢集的讀效能。
3.2 會話
Zookeeper客戶端通過TCP長連線連線到服務叢集,會話(Session)從第一次連線開始就已經建立,之後通過心跳檢測機制來保持有效的會話狀態。通過這個連線,客戶端可以傳送請求並接收響應,同時也可以接收到Watch事件的通知。
關於會話中另外一個核心的概念是sessionTimeOut(會話超時時間),當由於網路故障或者客戶端主動斷開等原因,導致連線斷開,此時只要在會話超時時間之內重新建立連線,則之前建立的會話依然有效。
3.3 資料節點
Zookeeper資料模型是由一系列基本資料單元Znode(資料節點)組成的節點樹,其中根節點為/。每個節點上都會儲存自己的資料和節點資訊。Zookeeper中節點可以分為兩大類:
- 持久節點 :節點一旦建立,除非被主動刪除,否則一直存在;
- 臨時節點 :一旦建立該節點的客戶端會話失效,則所有該客戶端建立的臨時節點都會被刪除。
臨時節點和持久節點都可以新增一個特殊的屬性:SEQUENTIAL,代表該節點是否具有遞增屬性。如果指定該屬性,那麼在這個節點建立時,Zookeeper會自動在其節點名稱後面追加一個由父節點維護的遞增數字。
3.4 節點資訊
每個ZNode節點在儲存資料的同時,都會維護一個叫做Stat的資料結構,裡面儲存了關於該節點的全部狀態資訊。如下:
| 狀態屬性 | 說明 |
|---|---|
| czxid | 資料節點建立時的事務ID |
| ctime | 資料節點建立時的時間 |
| mzxid | 資料節點最後一次更新時的事務ID |
| mtime | 資料節點最後一次更新時的時間 |
| pzxid | 資料節點的子節點最後一次被修改時的事務ID |
| cversion | 子節點的更改次數 |
| version | 節點資料的更改次數 |
| aversion | 節點的ACL的更改次數 |
| ephemeralOwner | 如果節點是臨時節點,則表示建立該節點的會話的SessionID;如果節點是持久節點,則該屬性值為0 |
| dataLength | 資料內容的長度 |
| numChildren | 資料節點當前的子節點個數 |
3.5 Watcher
Zookeeper中一個常用的功能是Watcher(事件監聽器),它允許使用者在指定節點上針對感興趣的事件註冊監聽,當事件發生時,監聽器會被觸發,並將事件資訊推送到客戶端。該機制是Zookeeper實現分散式協調服務的重要特性。
3.6 ACL
Zookeeper採用ACL(Access Control Lists)策略來進行許可權控制,類似於UNIX檔案系統的許可權控制。它定義瞭如下五種許可權:
- CREATE:允許建立子節點;
- READ:允許從節點獲取資料並列出其子節點;
- WRITE:允許為節點設定資料;
- DELETE:允許刪除子節點;
- ADMIN:允許為節點設定許可權。
四、ZAB協議
4.1 ZAB協議與資料一致性
ZAB協議是Zookeeper專門設計的一種支援崩潰恢復的原子廣播協議。通過該協議,Zookeepe基於主從模式的系統架構來保持叢集中各個副本之間資料的一致性。具體如下:
Zookeeper使用一個單一的主程序來接收並處理客戶端的所有事務請求,並採用原子廣播協議將資料狀態的變更以事務Proposal的形式廣播到所有的副本程序上去。如下圖:
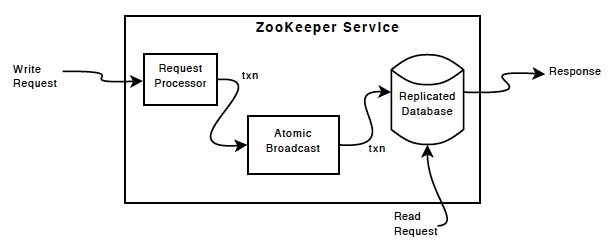
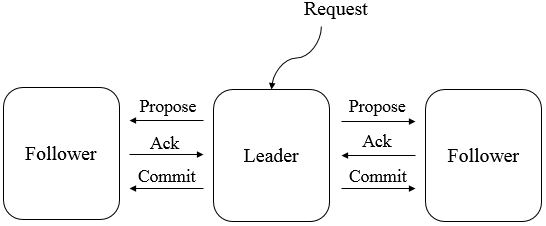
具體流程如下:
所有的事務請求必須由唯一的Leader服務來處理,Leader服務將事務請求轉換為事務Proposal,並將該Proposal分發給叢集中所有的Follower服務。如果有半數的Follower服務進行了正確的反饋,那麼Leader就會再次向所有的Follower發出Commit訊息,要求將前一個Proposal進行提交。
4.2 ZAB協議的內容
ZAB協議包括兩種基本的模式,分別是崩潰恢復和訊息廣播:
1. 崩潰恢復
當整個服務框架在啟動過程中,或者當Leader伺服器出現異常時,ZAB協議就會進入恢復模式,通過過半選舉機制產生新的Leader,之後其他機器將從新的Leader上同步狀態,當有過半機器完成狀態同步後,就退出恢復模式,進入訊息廣播模式。
2. 訊息廣播
ZAB協議的訊息廣播過程使用的是原子廣播協議。在整個訊息的廣播過程中,Leader伺服器會每個事物請求生成對應的Proposal,併為其分配一個全域性唯一的遞增的事務ID(ZXID),之後再對其進行廣播。具體過程如下:
Leader服務會為每一個Follower伺服器分配一個單獨的佇列,然後將事務Proposal依次放入佇列中,並根據FIFO(先進先出)的策略進行訊息傳送。Follower服務在接收到Proposal後,會將其以事務日誌的形式寫入本地磁碟中,並在寫入成功後反饋給Leader一個Ack響應。當Leader接收到超過半數Follower的Ack響應後,就會廣播一個Commit訊息給所有的Follower以通知其進行事務提交,之後Leader自身也會完成對事務的提交。而每一個Follower則在接收到Commit訊息後,完成事務的提交。
五、Zookeeper的典型應用場景
5.1資料的釋出/訂閱
資料的釋出/訂閱系統,通常也用作配置中心。在分散式系統中,你可能有成千上萬個服務節點,如果想要對所有服務的某項配置進行更改,由於資料節點過多,你不可逐臺進行修改,而應該在設計時採用統一的配置中心。之後釋出者只需要將新的配置傳送到配置中心,所有服務節點即可自動下載並進行更新,從而實現配置的集中管理和動態更新。
Zookeeper通過Watcher機制可以實現資料的釋出和訂閱。分散式系統的所有的服務節點可以對某個ZNode註冊監聽,之後只需要將新的配置寫入該ZNode,所有服務節點都會收到該事件。
5.2 命名服務
在分散式系統中,通常需要一個全域性唯一的名字,如生成全域性唯一的訂單號等,Zookeeper可以通過順序節點的特性來生成全域性唯一ID,從而可以對分散式系統提供命名服務。
5.3 Master選舉
分散式系統一個重要的模式就是主從模式(Master/Salves),Zookeeper可以用於該模式下的Matser選舉。可以讓所有服務節點去競爭性地建立同一個ZNode,由於Zookeeper不能有路徑相同的ZNode,必然只有一個服務節點能夠建立成功,這樣該服務節點就可以成為Master節點。
5.4 分散式鎖
可以通過Zookeeper的臨時節點和Watcher機制來實現分散式鎖,這裡以排它鎖為例進行說明:
分散式系統的所有服務節點可以競爭性地去建立同一個臨時ZNode,由於Zookeeper不能有路徑相同的ZNode,必然只有一個服務節點能夠建立成功,此時可以認為該節點獲得了鎖。其他沒有獲得鎖的服務節點通過在該ZNode上註冊監聽,從而當鎖釋放時再去競爭獲得鎖。鎖的釋放情況有以下兩種:
- 當正常執行完業務邏輯後,客戶端主動將臨時ZNode刪除,此時鎖被釋放;
- 當獲得鎖的客戶端發生宕機時,臨時ZNode會被自動刪除,此時認為鎖已經釋放。
當鎖被釋放後,其他服務節點則再次去競爭性地進行建立,但每次都只有一個服務節點能夠獲取到鎖,這就是排他鎖。
5.5 叢集管理
Zookeeper還能解決大多數分散式系統中的問題:
- 如可以通過建立臨時節點來建立心跳檢測機制。如果分散式系統的某個服務節點宕機了,則其持有的會話會超時,此時該臨時節點會被刪除,相應的監聽事件就會被觸發。
- 分散式系統的每個服務節點還可以將自己的節點狀態寫入臨時節點,從而完成狀態報告或節點工作進度彙報。
- 通過資料的訂閱和釋出功能,Zookeeper還能對分散式系統進行模組的解耦和任務的排程。
- 通過監聽機制,還能對分散式系統的服務節點進行動態上下線,從而實現服務的動態擴容。
參考資料
- 倪超 . 從Paxos到Zookeeper——分散式一致性原理與實踐 . 電子工業出版社 . 2015-02-01
更多大資料系列文章可以參見個人 GitHub 開源專案: 大資料入門指南