
Map、Set、List集合差別及聯絡詳解
前言:
陣列Array和集合的區別:
1、陣列是大小固定的,並且同一個陣列只能存放型別一樣的資料(基本型別/引用型別)
2、JAVA集合可以儲存和運算元目不固定的一組資料。
3、若程式時不知道究竟需要多少物件,需要在空間不足時自動擴增容量,則需要使用容器類庫,array不適用。
注:使用相應的toArray()和Arrays.asList()方法可以相互轉換。
一、集合
集合類存放於Java.util包中。
集合類存放的都是物件的引用,而非物件本身,出於表達上的便利,我們稱集合中的物件就是指集合中物件的引用。
集合型別主要有三種:set(集)、list(列表)、map(對映)。
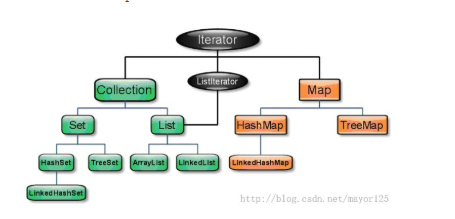
1、Collection介面
Collection是最基本的集合介面,一個Collection代表一組Object,即Collection的元素。Java SDK提供的類都是繼承自Collection的“子介面”如List和Set。
如何遍歷Collection中的每一個元素?不論Collection的實際型別如何,它都支援一個iterator()的方法,該方法返回一個迭代子,使用該迭代子即可逐一訪問Collection中每一個元素。典型的用法如下:
Iterator it = collection.iterator(); // 獲得一個迭代子 while(it.hasNext()) { Object obj = it.next(); // 得到下一個元素 }
由Collection介面派生的兩個介面是List和Set。
2、Set
Set介面同樣是Collection介面的一個子介面,Set不包含重複的元素。
HashSet:使用hashmap的一個集的實現。雖然集定義成無序,但必須存在某種方法能高效地找到一個物件。使用一個hashmap物件實現集的儲存和檢索操作時在固定時間內實現的。
TreeSet:在集中以升序對物件排序的集的實現。這意味著從一個TreeSet物件獲得第一個迭代器將按升序提供物件。TreeSet類使用了一個TreeMap。
為優化hashset空間的使用,可以調優初始容量和負載因子。TreeSet 不包含調優選項,因為樹總是平衡的,保證了插入、刪除、查詢的效能的高效。
當您要從集合中以有序的方式抽取元素時,TreeSet實現會有用處。為了能順利進行,新增到TreeSet的元素必須是可排序的。
import java.util.*;
public class SetExample {
public static void main(String args[]) {
Set set = new HashSet();
set.add("Bernadine");
set.add("Elizabeth");
set.add("Gene");
set.add("Elizabeth");
set.add("Clara");
System.out.println(set);
Set sortedSet = new TreeSet(set);
System.out.println(sortedSet);
}
}[Gene, Clara, Bernadine, Elizabeth]
[Bernadine, Clara, Elizabeth, Gene]3、List
List介面繼承了Collection介面,定義一個允許重複項的有序集合。該介面不但能夠對列表的一部分進行處理,還添加了面向位置的操作。
實際上有兩種list:一種是基本的ArrayList,其優點在於隨機訪問元素,另一種是更強大的LinkedList,它並不是快速隨機訪問設計的,而是具有更通用的方法。
List : 次序是List最重要的特點:它保證維護元素特定的順序。
ArrayList : 由陣列實現的List。允許對元素進行快速隨機訪問,但是向List中間插入與移除元素的速度很慢。
LinkedList : 對順序訪問進行了優化,向List中間插入與刪除的開銷並不大,隨機訪問則相對較慢。還具有下列方法:addFirst(), addLast(), getFirst(), getLast(), removeFirst() 和 removeLast(), 這些方法 (沒有在任何介面或基類中定義過)使得LinkedList可以當作堆疊、佇列和雙向佇列使用。
Vector:實現一個類似陣列一樣的表,自動增加容量來容納你所需的元素。使用下標儲存和檢索物件就象在一個標準的陣列中一樣。你也可以用一個迭代器從一個Vector中檢索物件Vector是唯一的同步容器類!!
stack:這個類從vector派生而來,並增加了方法實現棧,一種後進先出的儲存結構。
List的用法示例:
package collection;
import java.util.*;
public class SetExample {
public static void main(String[] args) {
List linkedList = new LinkedList();
for (int i = 0; i <= 5; i++) {
linkedList.add("a"+i);
}
System.out.println(linkedList);
linkedList.add(3,"a100");
System.out.println(linkedList);
linkedList.set(6,"a200");
System.out.println(linkedList);
System.out.println(linkedList.get(2));
System.out.println(linkedList.indexOf("a3"));
linkedList.remove(1);
System.out.println(linkedList);
}
}
4、list和set對比
Set子介面:無序,不允許重複,檢索元素效率低下,刪除和插入效率高,插入和刪除不會引起元素位置改變。
List子介面:有序,可以有重複元素,和陣列類似,List可以動態增長,查詢元素效率高,插入刪除元素效率低,因為會引起其他元素位置改變。
Set和List具體子類:
Set
|————HashSet:以雜湊表的形式存放元素,插入刪除速度很快。
List
|————ArrayList:動態陣列
|————LinkedList:連結串列、佇列、堆疊。
5、map
map介面不是Collection介面的繼承。
不重複的鍵到值的對映。
Map.Entry 介面
map的entrySet()方法返回一個實現map.entry介面的物件集合。集合中每個物件都是底層map中一個特定的鍵值對。
HashMap 類和 TreeMap 類
在map中插入、刪除和定位元素,HashMap是最好的選擇。但如果您要按順序遍歷鍵,那麼TreeMap 會更好。根據集合大小,先把元素新增HashMap,再把這種對映轉換成一個用於有序鍵遍歷的TreeMap 可能更快。
為了優化hashmap空間的使用,您可以調優初始容量和負載因子。這個treeMap沒有調優選項,因為該樹總處於平衡狀態。
hashtable:實現一個映象,所有的鍵必須非空。為了能高效的工作,定義鍵的類必須實現hashcode()方法和equal()方法。這個類時前面Java實現的一個繼承,並且通常能在實現映象的其它類中更好地使用。
hashmap:實現一個映象,執行儲存空物件,而且允許鍵是空(由於鍵必須是唯一的,當然只能有一個空)。
WeakHashMap:如果有一個鍵對於一個物件而言不再被引用,鍵將被捨棄,WeakHashMap在具有大量資料時使用。
TreeMap: 實現這樣一個映象,物件是按鍵升序排列的。
map的使用示例:
以下程式演示了具體map類的使用。該程式對自命令列傳遞的詞進行頻率計數。hashmap起初用於資料儲存。後來,對映被轉換為TreeMap以顯示有序的鍵列列表。
package collection;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;
public class MapExample {
public static void main(String[] args) {
String[] array = {"a","b","c","d","e"};
Map map = new HashMap();
Integer ONE = new Integer(1);
for (int i=0, n=array.length; i<n; i++) {
String key = array[i];
int frequency = i+1;
map.put(key, frequency);
}
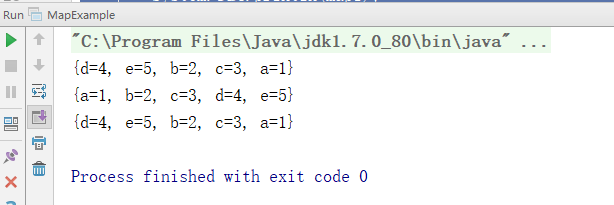
System.out.println(map);
Map sortedMap = new TreeMap(map);
System.out.println(sortedMap);
//hashmap的同步
Map map1 = Collections.synchronizedMap(map);
System.out.println(map1);
}
}結果:
解惑:
1、什麼是iterator
對集合的遍歷,遍歷的時候不建議修改集合。
2、Iterator與ListIterator有什麼區別?
Iterator:只能正向遍歷集合
ListIerator:繼承Iterator,可以雙向列表遍歷
3、HashMap與HashTable有什麼區別?
HashMap允許空值作為鍵或值,不同步的,迭代時採用的是快速失敗機制
HashTable不允許空值,同步的
注:有多執行緒的可能時,使用hashtable,反之使用hashmap。非執行緒安全的資料結構能帶來更好地效能。
如果將來有可能需要按順序獲取鍵值對,hashmap是更好地選擇,因為hashmap的一個子類LinkedHashMap。
如果多執行緒時使用hashmap,Collections.synchronizedMap()可以代替,總的來說HashMap更靈活。
4、在Hashtable上下文中同步是什麼意思?
同步意味著在一個時間點只能有一個執行緒可以改變雜湊表,任何執行緒在執行hashtable的更新操作前需要獲取物件鎖,其它執行緒等待鎖的釋放。
5、為什麼Vector不推薦使用?
使用時ArrayList優先於Vector,Vector是同步的,效能會低一些,如果迭代一個vector,還要加鎖,以避免其他執行緒同一時刻改變集合,加鎖效率更慢。