
Salesforce Admin篇(一)Duplicate Management
參考資料:https://help.salesforce.com/articleView?id=managing_duplicates_overview.htm
Salesforce 很重要的一個平臺是Sales Cloud,涉及到的流程是Lead-Cash。銷售團隊跟進潛在的客戶,爭取讓他們變成自己的客戶並創造機會購買他們的產品。有時,銷售人員可能會電話或者其他方式聯絡不屬於他own的Account或者Lead,由於系統中存在著重複的Account/Lead資料,導致銷售人員做了很多無用功,同時被電聯的客戶也會被浪費時間以及認為公司團隊辦事混亂。所以重複的資料造成的影響特別大,針對這種重複資料的管理也特別有必要。
Salesforce提供了一套針對針對Duplicate資料的管理方式,Duplicate Management可用於以下的object的資料: Account(business & person) / Contact / Lead / 自定義物件。Sales force針對重複資料的管理基於兩個Rule: Matching Rule & Duplicate Rule。
通過下面的截圖可以看到, Matching rule是用來識別兩條記錄是否是重複資料的,當我們用Matching Rule確定是否重複以後,通過Duplicate Rule的配置方式來進行後續的操作。

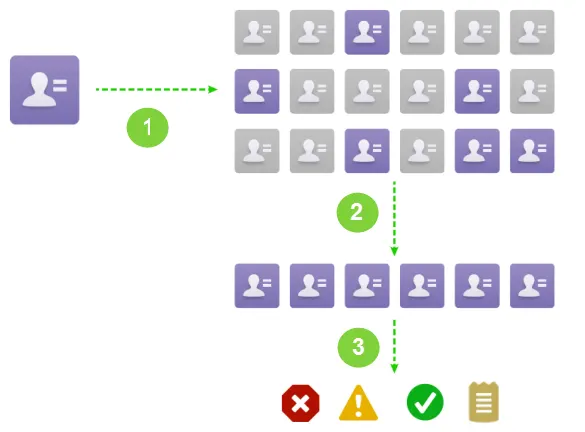
當我們進行一條Contact插入時,Duplicate Management會進行以下的步驟:
1. 一個Contact 建立;
2. 通過Matching Rule規則去檢視有哪些匹配到的重複的Contact資料;
3. 通過不同的Duplicate Rule會有不同的操作,比如可以block住建立的操作,也可以彈出alert提示框然後允許其繼續建立,針對繼續建立也可以做到將潛在的重複記錄生成report傳送給他的經理郵件。下面分別講一下Matching Rule以及Duplicate Rule的使用。
Mattching Rule 以及 Duplicate Rule可在Set Up中搜索Duplicate,在Duplicate Management下進行訪問,下面針對這兩個規則進行詳細的說明。
一. Matching Rule
Salesforce預設提供了關於Account / Contact / Lead的標準的Matching Rule,針對這三種Matching Rule的詳細使用如下連結所示:
Account Standard Matching Rule:https://help.salesforce.com/articleView?id=matching_rules_standard_account_rule.htm&type=0
Contact Standard Matching Rule:https://help.salesforce.com/articleView?err=1&id=matching_rules_standard_contact_rule.htm&type=5
Lead Standard Matching Rule: https://help.salesforce.com/articleView?err=1&id=matching_rules_standard_leads_on_accounts_rule.htm&type=5
我們下面的內容講的是如何建立自定義的Matching Rule,以及建立好以後如何判斷兩條記錄是Matching的還是不同的。
1. 首先我們在系統中新建一個Matching Rule,管理員需要設定Matching Criteria。我們在demo中設定了4列,並且設定他們的邏輯為(1 OR 2) AND (3 OR 4).
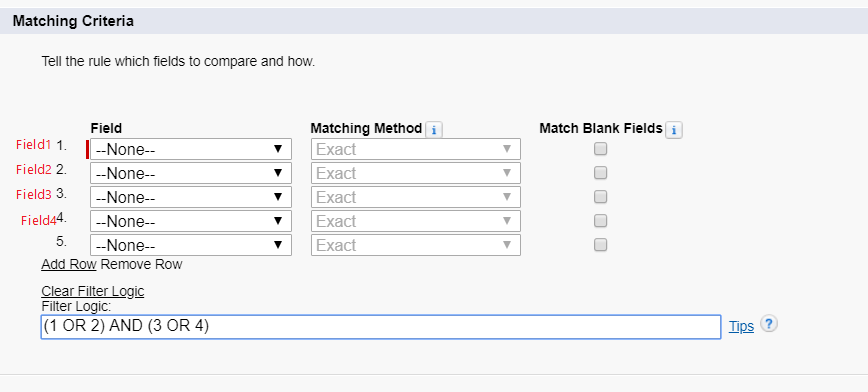
通過上圖自定義Matching Rule我們可以看到Matching Criteria有三列,這三列的含義如下:
Field: 用來指定哪個欄位用來做比較,支援的比較型別包括email, lookup relationship, master-detail relationship, number, phone, standard picklists, custom picklists (single-select only), text, and URL。
Matching Method: 定義Field如何進行比較的方法。有兩種型別可供選擇: Exact / Fuzzy。 Exact大部分欄位都可以選擇,Fuzzy針對常用的欄位可以選擇。針對Exact以及Fuzzy選擇如何影響匹配規則會在下面說明。
Match Blank Fields: 指定在欄位比較時,空字串是否被用於比較。如果沒有勾選,則如果兩條記錄的比較的欄位都是空的也會被認為是不一致的。如果勾選的情況下,如果兩個記錄的比較的欄位均為空,則認為是一致,如果一個為空,一個不為空也不認為是一致的。
當我們選擇了上面的邏輯進行操作以後,Salesforce適用了一系列的運算邏輯和運算演算法來實現匹配。這裡涉及到幾個關鍵的概念。
1. Matching equation:
我們在Matching Criteria 選擇了欄位以及匹配了規則以後,我們便知道了 Matching equation。通過下圖可以知道,當前的匹配規則為:
(Field1 OR Field2) & (Field3 OR Field4)。Matching Equation知道以後,我們需要變形,括號內適用AND連結,括號外適用OR連結。
所以 (Field1 OR Field2)AND (Field3 OR Field4) =
(Field1 AND Field3) OR
(Field1 AND Field4) OR
(Field2 AND Field3) OR
(Field2 AND Field4)
我們通過解析成OR的形式便可以知道當前的 matching key的個數,即一個OR的group對應一個 matching key. demo中總共有4個matching key
matching key 由兩部分進行自動生成,一個是matching equation,一個是matching method(exact/fuzzy)。當Matching Rule執行時,實際上是根據matching key是否匹配來判斷兩條資料是否為重複資料,如果matching key匹配,則認為是潛在的匹配資料進行評估,如果matching key不匹配,則認為兩條資料不是重複資料。
上面的matching equation已經可以通過Matching Criteria確定出來,matching method可以由管理員勾選選項確定下來。matching method兩種方式的詳細區別以及用途如下:
exact:顧名思義,精確匹配,用來匹配字串完全一樣的資訊。如果你使用的是國際化的資料,建議使用exact模式,大部分欄位都支援此種類型匹配,包括自定義欄位;
fuzzy: 模糊匹配,尋找與目標字串近乎匹配的字串。此種方式匹配不是所有的欄位都可以使用,通常使用者Account/Contact/Lead的標準欄位。
看到上面的兩個宣告方式,可以看到exact需要完全匹配,fuzzy可以模糊匹配,那針對匹配兩個值的準確率是多少,運用什麼規則匹配,我們還要針對fuzzy方式提出另外幾個概念。
2. Matching Algorithm
定義兩個欄位是否匹配的邏輯的演算法。針對exact模式,則自動使用精確匹配的演算法。針對模糊匹配的演算法,官方提供了各種模糊匹配的演算法。每個欄位都是根據匹配程度來評分,用來記錄當前的兩個欄位的匹配分值。針對fuzzy方式可能會有各種評分的匹配值,針對exact只有0和100。Salesforce提供了以下的匹配演算法,各個匹配演算法描述如下所示。
| MATCHING ALGORITHM | DESCRIPTION |
| Acronym | 判斷一個公司的名稱是否和他的縮寫名稱一致。比如上面例子中的International Business Machines和IBM會被認為是一致的。 |
| Edit Distance |
通過兩個字串之間的刪除,新增,字元的替換來決定兩個字串的相似度。比如 VP Sales 和 VP Of Sales匹配分數為73% |
| Initials |
比較兩個名字的首字母是否相同。比如First Name: Jane 和首字母為J的匹配相似度為100. 需要注意的一點是,如果我們在match rule中配置了First Name為 Fuzzy方式的匹配,設定Last Name為Exact方式的匹配,則我們的match key應該是First Name的首字母加上First Name的最後一個字母加上Last Name全部作為match key。比如Jane Smith,Jane作為First Name使用了Fuzzy方式,Smith作為Last Name使用了Exact方式。則匹配的key應該為 jesmith. |
| Jaro-Winkler Distance | 比較一個字串轉換成另外一個字串所需要的替換的數量的相似度。通常用於短的字串的比較。比如Johnny和Johny匹配分數為97 |
| Keyboard Distance | 比較一個字串通過刪除,新增,字元替換轉換成另外一個字串的(由鍵盤的鍵的位置加權)來確定兩個字串的相似度。 |
| Kullback Liebler Distance | 根據兩個欄位中的相同的單詞所佔的比例來確定相似度。比如Director of Engineering 和 Engineering Director 有2個單詞匹配,匹配分數為65% |
| Metaphone 3 | 根據兩個字串發音來確定兩個單詞的相似度,這個針對First Name和Last Name都有效。比如Joseph和Josef兩個單詞發音一樣,所以匹配程度為100. |
| Name Variant | 根據兩個單詞是否為相互之間的變形來確定兩個單詞的相似度,官方給的單詞為Bob是Robert的變形,所以返回100, Bob不是Bill的變形,所以返回0 |
| Syllable Alignment | 根據兩個單詞的發音來確定兩個單詞的相似度,首先先將單詞轉換成音節的字串,然後使用Edit Distance algorithm比較相似度。 |
3. Threshold
當我們使用了Fuzzy的匹配方法以後,我們需要知道針對每個欄位的匹配相似度最低在多少情況下,salesforce才認為是匹配的。下面的表例舉了針對Fuzzy的各個標準欄位適用的匹配演算法以及匹配的權重的最小值。
| Matching Method | MATCHING ALGORITHMS | SCORING METHOD | THRESHOLD | SPECIAL HANDLING |
| Exact | Exact | |||
| Fuzzy: First Name |
Exact Initials Jaro-Winkler Name Variant |
Maximum | 85 |
如果Middle Name欄位用來作為matching rule的比較欄位,則根據Fuzzy:First Name matching method比較 |
| Fuzzy: Last Name |
Exact Keyboard Distance Metaphone 3 |
Maximum | 90 | |
| Fuzzy: Company Name |
Acronym Exact Syllable Alignment |
Maximum | 70 | 在比較欄位以前需要先移除inc, corp等詞。除此之外,公司名稱也遵循規範化的。比如IBM會先規範化成International Business Machines |
| Fuzzy: Phone | Exact | Weighted Average | 80 |
電話號碼會分成多個部分進行比較。每個部分都有自己的匹配方法和匹配分數。部分分數經過加權後得出該欄位的一個分數。這個計算過程最適合北美的資料。 International code (exact, 10% of field’s match score) 當我們比較這兩個號碼:1-415-555-1234 and 1-415-555-5678. 1 1 415 415 555 555 1234 5678 前三個部分都匹配,最後一個不匹配,最後一個佔的權重為90%超過了80,所以我們認為這兩個號碼是匹配的。 |
| Fuzzy: City |
Edit Distance Exact |
Maximum | 85 | |
| Fuzzy: Street | Exact | Weighted Average | 80 | 街道欄位的比較方式和上面的電話號碼類似,差分成多個比較,不同模組會有不同的權重。這個也是最適合北美的資料。 |
| Fuzzy: ZIP | Exact | Weighted Average | 80 | ZIP code也拆分成多個模組比較
First five digits (Exact, 90% of field’s match score) Next four digits (Exact, 10% of field’s match score) 因為前5個匹配便已經90超過80,所以前5位匹配即認為相同 |
| Fuzzy: Title |
Acronym Exact Kullback-Liebler Distance |
Maximum | 50 |
4. Matching Key
上文也提到了,我們在有了Matching equation 以後,需要變形成指定的格式,目的就是為了生成 Matching Key。Matching Key有助於提高匹配演算法的效能。我們可以根據生成的Matching Key來比較兩個欄位的相似度,從而可以知道權重是否滿足在salesforce規定的範圍內。那Matching Key需要如何生成?有哪些要求?
1. 將匹配的方程式從 OR語句格式轉換成AND語句格式
2. 匹配規則中的欄位的值是規範化的
3. 一個matching rule最多隻能有10個matching key,也就是說OR語句轉成AND後的數量必須在10個以內,否則會報錯。
4. match key用於針對每條記錄將規範化的值組合。
第一個我們在前面已經瞭解了,第二個規範化有什麼意義?salesforce又是如何設計的?
意義: 在我們比較兩個欄位相似度時,不同的欄位型別,不同銷售人員填的內容可能是不一樣的。比如針對名稱,可能有些人添加了稱呼語(Mr./Mrs),針對公司名稱,有些人可能填寫的時縮寫,有些人可能在名稱中添加了 and,the這種連線詞等,大大的增加了匹配的難度以及準確性,所以針對部分欄位,我們將其按照某種規則在比較以前進行規範化,可以大幅度的增強匹配的準確性以及匹配的效率。
salesforce針對主要欄位的規範化如下表所示:
| FIELD | NORMALIZATION DETAILS | APPLIES TO STANDARD AND CUSTOM MATCHING RULES? | EXAMPLES |
| City | 將所有字元小寫。刪除非字母和非數字字元,包括空格也要刪掉。最多保留6位字元 | 如果適用自定義Match Rule,City的match method需要是fuzzy |
San Francisco = sanfra 首先先將空格去掉,然後全部小寫,最後保留前6個字串 Rome = rome 如果不到6位的字串則完全保留 |
| Company | 針對縮寫的公司名稱先變成全稱,將所有的字元小寫,刪除字尾字串,比如Corporation, Incorporated, Inc, Limited, and Ltd等。移除and, the , of這種單詞。移除特殊字元和accent. | 同上。 |
IBM = international business machines Intel Corp. = intel |
| First Name | 如果適用的情況下,將名字替換成別名。移除dear,sir這種稱呼語,移除特殊字元。只保留第一個單詞的第一個字母並且將字母小寫。 | 同上。 |
Dr. Jane = j Dr是稱呼語,所以刪掉,Jane的首字母是J小寫以後為j Mr. Bob= robert = r Mr是稱呼語,Bob是robert的變形,可以理解成別名,所以Bot替換成Robert首字母為R小寫成r |
| Last Name | 刪除特殊字元和字尾,將連續的相同的子音字母替換成單個的子音字母(b,c,d,f等)。將第一個字母小寫。在上述操作標準化以後,使用雙變音演算法(double metaphone)用來規避拼寫錯誤和拼寫變體情況。 | 同上。 |
O’Reilly, Jr. = oreily (without double metaphone) O’Reilly, Jr. = oreily = arl (with double metaphone) |
| 刪除部分字串。例如下劃線和點(.),保留@字串 | 只適用於標準的Match Rule | [email protected] = johndoe@salesforcecom | |
| Phone | 刪除所有的非字母和非數字字元,針對美國的電話號碼,將字母字元轉換成數字字元並刪除國際電碼。刪除後4位小數。 | 如果適用自定義的Phone,match method需要Fuzzy |
1-800-555-1234 = 800555 44 20 0540 0202 = 44200540 |
| Street Address | 刪除所有的字元除了連線符。刪除所有的禁用詞,比如Avenue和Street等。取前兩個單詞(token)的前5個字串 | 同上 |
123 Ocean View Avenue = 123ocean 567 Fifty-fourth St. = 567fifty |
| Website | 刪除協議名稱(http/https),刪除子域(www),刪除檔案路徑。取2個或者3個的單詞(token) | 只適用於標準的Match Rule |
http://www.us.salesforce.com/product = salesforce.com http://www.ox.ac.uk/ = ox.ac.uk |
當我們規範化完以後,我們將根據規則來確定哪些欄位和哪些字串用於match key裡面。
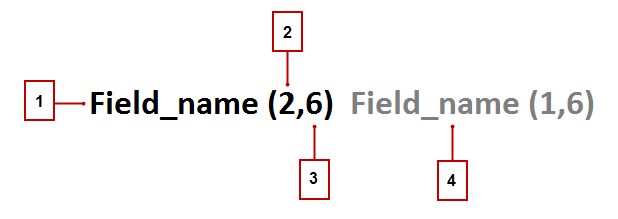
1代表在match key裡面的欄位。
2代表在match key裡面的單詞或者token的數量,沒有單詞數量則所有單詞全新增。
3代表在match key裡面的單詞的字元數,沒有單詞則字元全算。
4代表著在match key裡面的其他的欄位。
下面可以通過1個例子直觀的展示match key如何操作以及如何生成。
| FIELDS | Matching Method | Match Blank Fields |
| Company | Fuzzy(Company) | Yes |
| Exact | Yes | |
| Phone | Fuzzy(Phone) | Yes |
Matching equation為(Company OR Email) ANDPhone這邊有兩條資料:
| Company | Phone | |
| Elite Sport | [email protected] | 1-415-555-1235 |
| Elite Sports | [email protected] | 1-415-555-1234 |
第一步,轉換成AND模式: (Company OR Email) AND Phone = (Company AND Phone) OR (Email AND Phone)第二步,規範化需要匹配的欄位的值。針對第一條:company: Elite Sport -> elite sportEmail: [email protected]Phone: 415555針對第二條:company: Elites Sports -> elites sportEmail: [email protected]
Phone: 415555
第三步,生成matching key.
針對第一條會生成兩個matching key
Company(2,5) Phone = elitesport415555
Email Phone = [email protected]
針對第二條會生成兩個matching key
Company(2,6) Phone = elitessport415555
Email Phone = [email protected]
這兩條資料儘管第一個key不完全匹配,但是第二個匹配,salesforce會認為這兩條時潛在的重複資料。
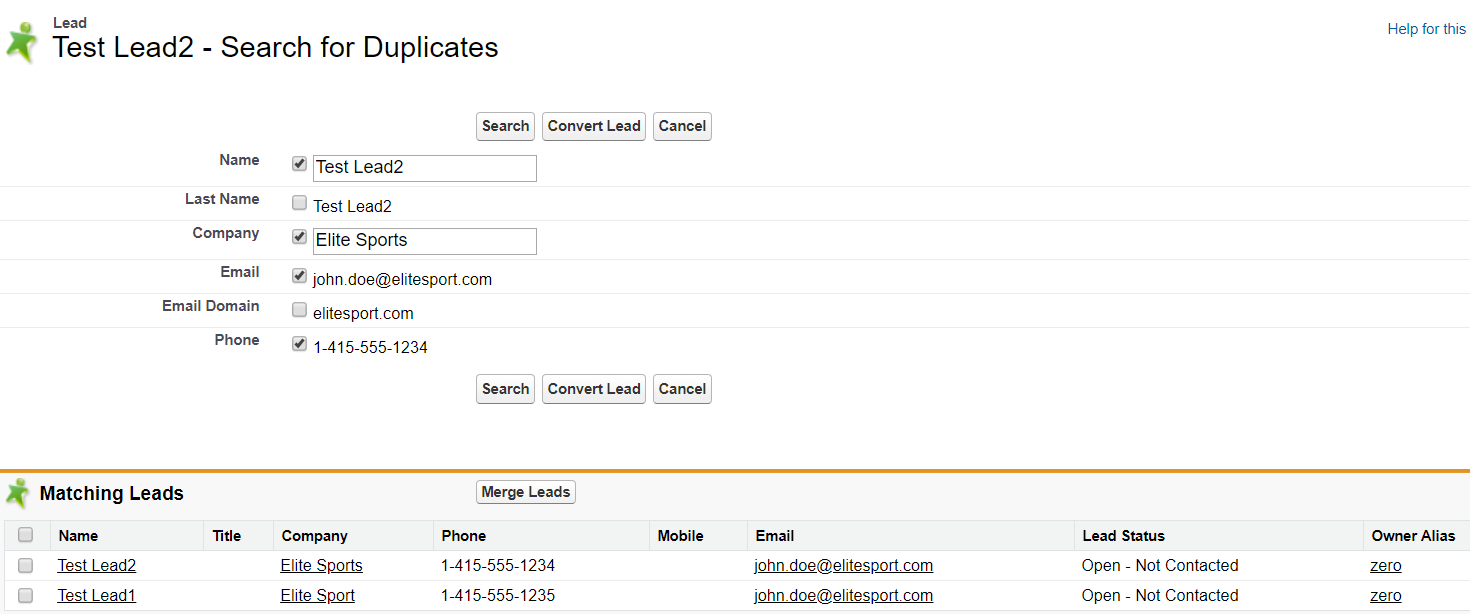
二. Duplicate Rule
我們第一步用了大量的內容去描述Matching Rule的規則,其實Matching Rule一大部分作用是為了Duplicate Rule去服務。使用者更關心的是如果出現了Duplicate 資料要如何去處理。我們可以配置自定義的Duplicate Rule去配置給使用者關於重複資料的後續處理方式。
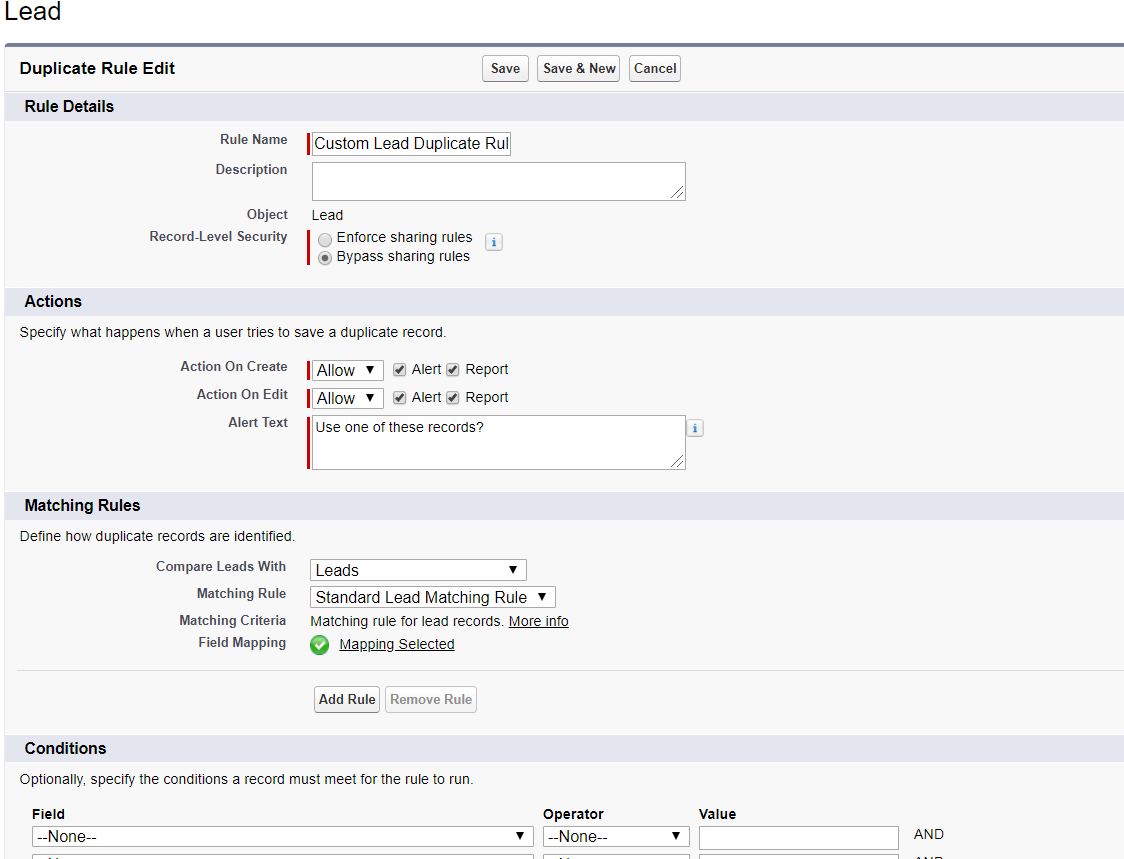
從下圖中我們可以看到Duplicate Rule配置時可以控制的選項。
1. Record Level Security: matching rule比較的範圍,是比較當前使用者有許可權的記錄還是所有的記錄;
2. Action區域可以選擇使用者基於Create / Edit操作時,針對Duplicate是要block建立還是在提出資訊情況下允許建立並且允許report;
3.Matching Rules選擇我們如何來確定兩條資料時matching的;
4. Conditions可以限制某些條件下才執行當前的Duplicate Rule,比如某些profile或者某些role才需要執行。
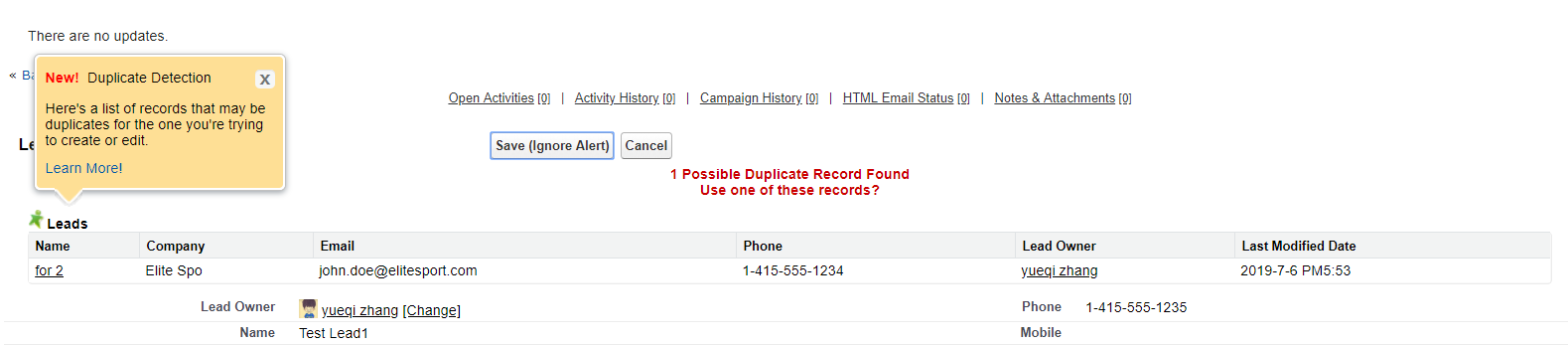
效果展示:當我們active 針對lead的duplicate rule以後,修改了 lead1的資料,會提示以下的內容告訴你有重複的資料。
總結:本篇淺入淺出的講了以下salesforce中關於Duplicate的資料的管理方式。關於Matching Rule / Duplicate Rule的相關的limitation以及深層次的用法沒有涉及。感興趣的可以自行檢視。篇中有錯誤的地方歡迎指出,有問題歡迎留