
新特性解讀 | MySQL 8.0 直方圖
MySQL 8.0 推出了histogram,也叫柱狀圖或者直方圖。先來解釋下什麼叫直方圖。
關於直方圖
我們知道,在DB中,優化器負責將SQL轉換為很多個不同的執行計劃,完了從中選擇一個最優的來實際執行。但是有時候優化器選擇的最終計劃有可能隨著DB環境的變化不是最優的,這就導致了查詢效能不是很好。比如,優化器無法準確的知道每張表的實際行數以及參與過濾條件的列有多少個不同的值。那其實有時候有人就說了,索引不是可以解決這個問題嗎?是的,不同型別的索引可以解決這個問題,但是你不能每個列都建索引吧?如果一張表有1000個欄位,那全欄位索引將會拖死對這張表的寫入。而此時,直方圖就是相對來說,開銷較小的方法。
直方圖就是在 MySQL 中為某張表的某些欄位提供了一種數值分佈的統計資訊。比如欄位NULL的個數,每個不同值出現的百分比、最大值、最小值等等。如果我們用過了 MySQL 的分析型引擎brighthouse,那對這個概念太熟悉了。
MySQL的直方圖有兩種,等寬直方圖和等高直方圖。等寬直方圖每個桶(bucket)儲存一個值以及這個值累積頻率;等高直方圖每個桶需要儲存不同值的個數,上下限以及累計頻率等。MySQL會自動分配用哪種型別的直方圖,我們無需參與。
MySQL 定義了一張meta表column_statistics 來儲存直方圖的定義,每行記錄對應一個欄位的直方圖,以json儲存。同時,新增了一個引數histogram_generation_max_mem_size來配置建立直方圖記憶體大小。
不過直方圖有以下限制:
1. 不支援幾何型別以及json。
2. 不支援加密表和臨時表。
3. 不支援列值完全唯一。
4. 需要手工的進行鍵值分佈。
那我們來舉個簡單的例子說明直方圖對查詢的效果提升。
舉例
表相關定義以及行數資訊等:
mysql> show create table t2\G *************************** 1. row *************************** Table: t2 Create Table: CREATE TABLE `t2` ( `id` int(11) NOT NULL AUTO_INCREMENT, `rank1` int(11) DEFAULT NULL, `rank2` int(11) DEFAULT NULL, `rank3` int(11) DEFAULT NULL, `log_date` date DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_rank1` (`rank1`), KEY `idx_log_date` (`log_date`) ) ENGINE=InnoDB AUTO_INCREMENT=49140 DEFAULT CHARSET=utf8mb4 \ COLLATE=utf8mb4_0900_ai_ci STATS_PERSISTENT=1 STATS_AUTO_RECALC=0 1 row in set (0.00 sec) mysql> select count(*) from t2; +----------+ | count(*) | +----------+ | 30940 | +----------+ 1 row in set (0.00 sec)
同時對t2克隆了一張表t3
mysql> create table t3 like t2;
Query OK, 0 rows affected (0.13 sec)
mysql> insert into t3 select * from t2;
Query OK, 30940 rows affected (1.94 sec)
Records: 30940 Duplicates: 0 Warnings: 0給表t3列rank1和log_date 新增histogram
mysql> analyze table t3 update histogram on rank1,log_date;
+--------+-----------+----------+-----------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+--------+-----------+----------+-----------------------------------------------------+
| ytt.t3 | histogram | status | Histogram statistics created for column 'log_date'. |
| ytt.t3 | histogram | status | Histogram statistics created for column 'rank1'. |
+--------+-----------+----------+-----------------------------------------------------+
2 rows in set (0.19 sec)我們來看看histogram的分佈狀況
mysql> select json_pretty(histogram) result from information_schema.column_statistics where table_name = 't3' and column_name = 'log_date'\G
*************************** 1. row ***************************
result: {
"buckets": [
[
"2018-04-17",
"2018-04-20",
0.01050420168067227,
4
],
...
,
[
"2019-04-14",
"2019-04-16",
1.0,
3
]
],
"data-type": "date",
"null-values": 0.0,
"collation-id": 8,
"last-updated": "2019-04-17 03:43:01.910185",
"sampling-rate": 1.0,
"histogram-type": "equi-height",
"number-of-buckets-specified": 100
}
1 row in set (0.03 sec)
MySQL自動為這個欄位分配了等高直方圖,預設為100個桶。
SQL A:
select count(*) from t2/t3 where (rank1 between 1 and 10) and log_date < '2018-09-01';SQL A的執行結果:
mysql> select count(*) from t2/t3 where (rank1 between 1 and 10) and log_date < '2018-09-01';
+----------+
| count(*) |
+----------+
| 2269 |
+----------+
1 row in set (0.01 sec)無histogram的執行計劃
mysql> explain format=json select count(*) from t2 where (rank1 between 1 and 10) and log_date < '2018-09-01'\G
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "2796.11"
},
"table": {
"table_name": "t2",
"access_type": "range",
"possible_keys": [
"idx_rank1",
"idx_log_date"
],
"key": "idx_rank1",
"used_key_parts": [
"rank1"
],
"key_length": "5",
"rows_examined_per_scan": 6213,
"rows_produced_per_join": 3106,
"filtered": "50.00",
"index_condition": "(`ytt`.`t2`.`rank1` between 1 and 10)",
"cost_info": {
"read_cost": "2485.46",
"eval_cost": "310.65",
"prefix_cost": "2796.11",
"data_read_per_join": "72K"
},
"used_columns": [
"rank1",
"log_date"
],
"attached_condition": "(`ytt`.`t2`.`log_date` < '2018-09-01')"
}
}
}
有histogram的執行計劃
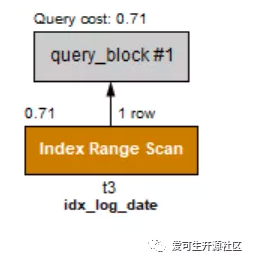
mysql> explain format=json select count(*) from t3 where (rank1 between 1 and 10) and log_date < '2018-09-01'\G
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "0.71"
},
"table": {
"table_name": "t3",
"access_type": "range",
"possible_keys": [
"idx_rank1",
"idx_log_date"
],
"key": "idx_log_date",
"used_key_parts": [
"log_date"
],
"key_length": "4",
"rows_examined_per_scan": 1,
"rows_produced_per_join": 1,
"filtered": "100.00",
"index_condition": "(`ytt`.`t3`.`log_date` < '2018-09-01')",
"cost_info": {
"read_cost": "0.61",
"eval_cost": "0.10",
"prefix_cost": "0.71",
"data_read_per_join": "24"
},
"used_columns": [
"rank1",
"log_date"
],
"attached_condition": "(`ytt`.`t3`.`rank1` between 1 and 10)"
}
}
}
1 row in set, 1 warning (0.00 sec)我們看到兩個執行計劃的對比,有Histogram的執行計劃cost比普通的sql快了好多倍。
上面文字可以看起來比較晦澀,貼上兩張圖,看起來就很簡單了。
無histogram

有histogram
當然,我這裡舉得例子相對簡單,有興趣的朋友可以更深入學習其他