
Oracle Awr報告_awr報告解讀_基礎簡要資訊
匯出
關於awr報告的匯出,上一篇部落格已經進行過講述了。部落格連結地址:https://www.cnblogs.com/liyasong/p/oracle_report1.html 這裡就不再贅述。
各個欄位的含義
awr報告的HTML報告,可以在網頁上直接開啟。這裡,按照每一部分介紹下awr報告的各個欄位。
1.報告基本資訊
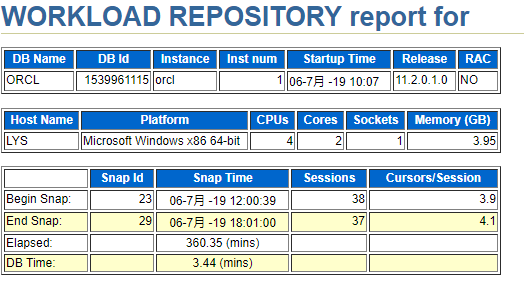
這一部分,是報告的一些基本資訊。分別包括:
上面部分,資料庫物理環境相關資訊。
第一行,DB Name 資料庫名(資料庫名是儲存在控制檔案中,代表資料庫所有物理檔案的總稱)。DB Id 資料庫id(資料庫的dbid可能在資料庫檔案恢復中需要用到,查詢資料庫DB Id的sql語句為:select dbId from v$database;)。Instance 例項名 (例項名(sid),寫資料庫地址的時候,192.168.*.*:1521/orcl 這裡的orcl就是例項名)初始例項編號(暫時不知道幹什麼用的,歡迎指導)。Startup Time 資料庫啟動時間(本次匯出awr報告對應時段的資料庫啟動時間)。Release 資料庫版本(不同的版本awr報告不全一樣,這裡是11.2版本的資料庫)。RAC real application cluster 資料庫自己的集群系統(分散式資料庫,安裝設定好集群后,從叢集的任何一個節點資料庫都可以同步到其他節點,這裡沒有開啟)
第二行,HostName 伺服器名(oracle所在伺服器的名稱,連結的時候需要驗證的一個資訊)。Platform 作業系統(orale的安裝環境,什麼系統,多少位)。CPUs(伺服器多少顆cpu)。Cores(伺服器幾核)。Sockets (主機板上CPU插槽個數)Memory (GB) 記憶體大小。
下面部分,快照資訊。
|
snap id 快照id |
snap time 快照時間 |
session 會話 |
Cursors/Session 遊標/ 會話 |
|
| begin Snap(起始快照) | ||||
| end snap (終止快照) | ||||
| elapsed: (跨度) | ||||
| DB TIme(請求時間) |
其中,快照起始/終止時間和起始/終止Id是建立awr報告的時候自己選的。會話數量表示在這次快照採集的時間內,oracle總共有多少次會話連結。Cursors/Session 每個會話平均使用多少個遊標(遊標,一個記憶體工作區,臨時儲存從資料庫中提取的資料塊)。DB Time:是記錄的伺服器花在資料庫運算 ( 非後臺程序 ) 和等待( 非空閒等待 ) 上的時間。不包括 Oracle 後臺程序消耗的時間。db time= cpu time + wait time(不包含空閒等待) (非後臺程序) 這裡是這樣算的:首先,有四個cpu總共耗時3.4mins 。平均每隔cpu耗時不到一分鐘。cpu利用率只有 1/360(快照採集總間隔時間) 百分之0.3不到,說明系統處於空閒狀態。這也是為什麼我們要儘可能使用需要分析的時間段的快照來進行分析的原因,因為快照跨度太長,有可能會導致dbtime的指標受到影響。
2.報告簡要資訊
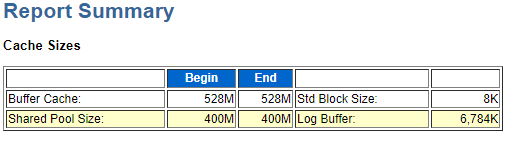
①.cache size 快取大小
這裡粗略的展示下系統的記憶體使用情況。其中包括:Buffer Cache 資料高速緩衝區,存放著oracle訪問的資料塊,存滿後,自動去除最不常用的資料。通俗講,就是將高頻率使用的sql查詢結果進行快取,提高查詢效率。Std Block Size 資料塊大小 。 Shared Pool Size 共享池 ,用來快取被執行的sql和被使用的資料定義。包括 Library cache和Data dictionary cache ,Library cache 用來存放sql語句的文字,分析後代碼及執行計劃。Data dictionary cache 快取資料字典,存放有關表、列和其他欄位及相對應的許可權。Log Buffer 全名redo log buffer 快取被執行的SQL語句和被使用的資料定義。
②.Load Profile 資料庫負載屬性資訊

DB Times 請求時間 等待cpu的時間與資料庫消耗CPU時間的總和。
DB CPU 資料庫消耗cpu時間(所有使用者的累加值)
Redo size 產生日誌的大小,標識資料庫的變更語句執行頻率,資料庫任務的繁忙程度。
Logical Read 邏輯讀,從(或試圖從)Buffer Cache中讀取資料塊。邏輯讀包括當前資料讀取和一致性讀取:Logical Reads= Consistent Gets + DB Block Gets 。邏輯讀受制於CPU效能,可以反映CPU使用情況。
Block changes 修改的資料塊數量,標識資料的變化頻率。
Physical Read 物理讀資料塊數量,物理讀消耗io資源。
Physical writes 物理寫資料塊數量,包括寫入資料庫+寫入快取
User Calls 使用者呼叫次數
Parses 解析次數,包括 fast parse ,軟解析和硬解析。其中fast parse 是最快的,直接在PGA中命中(需要設定session_cached_cursors=n);其次是軟解析,在shared pool中命中;都不命中,則觸發hard parse 。parses 超過300 意味著SQL解析複用效率不高。
Hard Parses 硬解析,硬解析標識SQL不命中的次數,每秒應小於20次。超過一百次,需要檢查是不是共享池(shared pool)設定的不合理。
W/A MB processed 工作區處理的任務數量 。
Logons 使用者登入次數。併發session越高,數值越大。
Executes 標識 SQL執行次數,反映執行效率。
Rollback 回滾次數。
Transactions 事物數。每秒的事物數可以反映任務的繁重情況。
SQL解析過程:
軟解析和硬解析,Oracle對SQL的處理過程:
1.語法檢查(syntax check) 檢查SQL語法是否符合規範。
2.語義檢查(semantic check) 檢查SQL中對應的物件(表,檢視等)是否存在及該使用者是否具備相應的許可權。
3.解析SQL語句 (prase) 對SQL進行解析,生成解析樹(parse tree)及執行計劃(execution plan)。
4.執行SQL 返回結果集。
首先,fast prase :在設定session_cursor_cache 這個引數後,Cursor被直接Cache在當前Session的PGA中,在解析的時候對SQL進行語法分析、許可權物件分析之後。先轉到PGA中查詢,如果發現完全相同的SQL,直接獲取結果返回。
其次,軟解析(soft parse) 在第3步執行前,先在共享池(Shared Pool )中找是否有相同的SQL,如果找到,直接使用該SQL解析好的解析樹和執行計劃。
最後,硬解析(Hard Parse) 沒有任何快取,直接解析SQL並執行,得到相應返回結果。
邏輯讀,物理讀
邏輯讀:指從Buffer Cache中讀取資料塊
1、及時讀:即時讀即讀取資料塊當前的最新資料。任何時候在Buffer Cache中都只有一份當前資料塊。即時讀通常發生在對資料進行修改、刪除操作時。這時,程序會給資料加上行級鎖,並且標識資料為“髒”資料。
2、資料一致性讀:Oracle是一個多使用者系統。當一個會話開始讀取資料還未結束讀取之前,可能會有其他會話修改它將要讀取的資料。如果會話讀取到修改後的資料,就會造成資料的不一致。一致性讀就是為了保證資料的一致性。在Buffer Cache中的資料塊上都會有最後一次修改資料塊時的SCN。如果一個事務需要修改資料塊中資料,會先在回滾段中儲存一份修改前資料和SCN的資料塊,然後再更新Buffer Cache中的資料塊的資料及其SCN,並標識其為“髒”資料。當其他程序讀取資料塊時,會先比較資料塊上的SCN和自己的SCN。如果資料塊上的SCN小於等於程序本身的SCN,則直接讀取資料塊上的資料;如果資料塊上的SCN大於程序本身的SCN,則會從回滾段中找出修改前的資料塊讀取資料。通常,普通查詢都是一致性讀。
物理讀:資料塊是oracle最基本的讀寫單位,但使用者所需要的資料,並不是整個塊,而是塊中的行,或列.當用戶發出SQL語句時,此語句被解析執行完畢,就開始了資料的抓取階段,在此階段,伺服器程序會先將行所在的資料塊從資料檔案中讀入buffer cache,這個過程叫做物理讀,每讀取一個塊,就算一次物理讀。
③. Instance Efficiency Percentages (Target 100%)
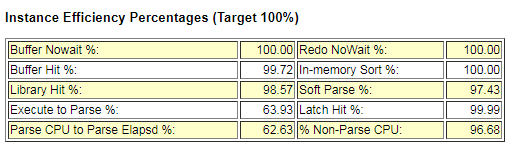
上面這些所有目標都是100%,越大越好。正常情況下,值在0-100之間。
Buffer Nowat: session 在訪問一個buffer時,立即可以訪問的比率。如果低於99%說明存在記憶體爭用的情況。
Buffer Hit : 記憶體命中率。在一般資料庫中,如果此值低於80% 應該給資料庫分配更多的記憶體。如果命中率突然增大, 可以檢查 top buffer get SQL,檢視導致大量邏輯讀的語句和索引,如果命中率突然減小,可以檢查 top physical reads SQL,檢查產生大量物理讀的語句,主要是那些沒有使用索 引或者索引被刪除的。
Redo NoWait: 緩衝區獲得Buffer未等待比例。不低於90%,不太需要考慮。
In-memory Sort 記憶體中完成的排序比例。應大於 95%,不太需要考慮。
Library Hit : 執行計劃命中率,當應用程式呼叫SQL或儲存過程的時候,如果在library Cache 中可以檢索到執行計劃,直接執行。不存在,解析SQL並快取。如果該值低於90% 可能需要調大共享池的記憶體大小。應保持在95%以上。
Soft Parse: 軟解析比例。重要解析指標。軟解析次數和總解析次數的比值,應該大於95 % 。
Execute to Parse 執行解析比 1-(parse/execute) 這裡軟解析也是解析次數,軟解析依然會消耗DBTime 所以可以通過使用靜態SQL,動態繫結、session_cached_cursor、open cursors等技術減少軟解析。
Latch Hit :資料塊內部行鎖不需要等待的比例。應大於99%。當前是因為系統中未共享SQL導致的低於該值。
Parse CPU To Parse Elapsd:該指標反映了 快照內解析CPU時間和總的解析時間的比值(Parse CPU Time/ Parse Elapsed Time); 若該指標水平很低,那麼說明在整個解析過程中 實際在CPU上運算的時間是很短的,而主要的解析時間都耗費在各種其他非空閒的等待事件上了(如latch:shared pool,row cache lock之類等)
Non-Parse CPU 非解析cpu比例,公式為 (DB CPU – Parse CPU)/DB CPU,比值越高,說明執行查詢工作的資源越多,分析查詢的資源消耗越少。
④.Shared Pool Statistics

一個大概的SQL重用及共享池記憶體使用。
Memory Usage 共享池記憶體使用率,應穩定在 75%-90%之間。如果太小,說明記憶體空間有浪費。如果高於90% 說明記憶體不足,有記憶體爭用的情況。
SQL with executions >1 複用的SQL佔總的SQL語句的比率,如果值太小,需要優化SQL。
Memory for SQL w/exec>1 :執行次數大於 1 的 SQL消耗記憶體的佔比。大概值會在 75-85% 之間。
⑤。Top 5 Time Events

系統最嚴重的5個等待,正常情況下,DBCPU應該排在最前面。
Waits : 該等待事件發生的次數, 對於DB CPU此項不可用
Times : 該等待事件消耗的總計時間,單位為秒, 對於DB CPU 而言是前臺程序所消耗CPU時間片的總和,但不包括Wait on CPU QUEUE
Avg Wait(ms) : 該等待事件平均等待的時間, 實際就是 Times/Waits,單位ms, 對於DB CPU此項不可用
Wait Class: 等待型別:Concurrency,System I/O,User I/O,Administrative,Other,Configuration,Scheduler,Cluster,Application,Idle,Network,Commit
⑥ CPU
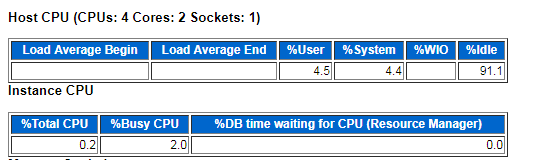
“Load Average” begin/end值代表每個CPU的大致執行佇列大小。
%User+%System=> 總的CPU使用率。
%Total CPU,該例項所使用的CPU佔總CPU的比例
%Busy CPU,該例項所使用的Cpu佔總的被使用CPU的比例
`⑦.記憶體使用

host mem 主機記憶體.
SGA use SGA 使用記憶體。SystemGlobal Area是OracleInstance的基本組成部分,在例項啟動時分配;系統全域性域SGA主要由三部分構成:共享池、資料緩衝區、日誌緩衝區。
PGA use PGA記憶體。ProcessGlobal Area是為每個連線到Oracledatabase的使用者程序保留的記憶體。
Host Mem used for SGA+PGA: 資料庫使用記憶體佔總記憶體比例。