
LightGBM,面試會問到的都在這了(附程式碼)!
1. LightGBM是什麼東東
不久前微軟DMTK(分散式機器學習工具包)團隊在GitHub上開源了效能超越其他boosting工具的LightGBM,在三天之內GitHub上被star了1000次,fork了200次。知乎上有近千人關注“如何看待微軟開源的LightGBM?”問題,被評價為“速度驚人”,“非常有啟發”,“支援分散式”,“程式碼清晰易懂”,“佔用記憶體小”等。
LightGBM (Light Gradient Boosting Machine)(請點選https://github.com/Microsoft/LightGBM)是一個實現GBDT演算法的框架,支援高效率的並行訓練。
LightGBM在Higgs資料集上LightGBM比XGBoost快將近10倍,記憶體佔用率大約為XGBoost的1/6,並且準確率也有提升。GBDT在每一次迭代的時候,都需要遍歷整個訓練資料多次。如果把整個訓練資料裝進記憶體則會限制訓練資料的大小;如果不裝進記憶體,反覆地讀寫訓練資料又會消耗非常大的時間。尤其面對工業級海量的資料,普通的GBDT演算法是不能滿足其需求的。
LightGBM提出的主要原因就是為了解決GBDT在海量資料遇到的問題,讓GBDT可以更好更快地用於工業實踐。
1.1 LightGBM在哪些地方進行了優化 (區別XGBoost)?
- 基於Histogram的決策樹演算法
- 帶深度限制的Leaf-wise的葉子生長策略
- 直方圖做差加速直接
- 支援類別特徵(Categorical Feature)
- Cache命中率優化
- 基於直方圖的稀疏特徵優化多執行緒優化。

1.2 Histogram演算法
直方圖演算法的基本思想是先把連續的浮點特徵值離散化成k個整數(其實又是分桶的思想,而這些桶稱為bin,比如[0,0.1)→0, [0.1,0.3)→1),同時構造一個寬度為k的直方圖。
在遍歷資料的時候,根據離散化後的值作為索引在直方圖中累積統計量,當遍歷一次資料後,直方圖累積了需要的統計量,然後根據直方圖的離散值,遍歷尋找最優的分割點。
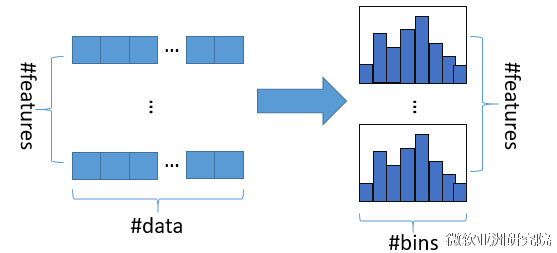
使用直方圖演算法有很多優點。首先,最明顯就是記憶體消耗的降低,直方圖演算法不僅不需要額外儲存預排序的結果,而且可以只儲存特徵離散化後的值,而這個值一般用8位整型儲存就足夠了,記憶體消耗可以降低為原來的1/8。然後在計算上的代價也大幅降低,預排序演算法每遍歷一個特徵值就需要計算一次分裂的增益,而直方圖演算法只需要計算k次(k可以認為是常數),時間複雜度從O(#data#feature)優化到O(k#features)。
1.3 帶深度限制的Leaf-wise的葉子生長策略
在XGBoost中,樹是按層生長的,稱為Level-wise tree growth,同一層的所有節點都做分裂,最後剪枝,如下圖所示:
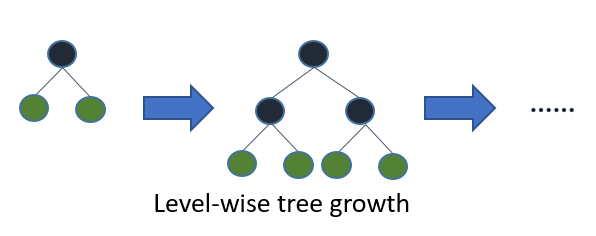
Level-wise過一次資料可以同時分裂同一層的葉子,容易進行多執行緒優化,也好控制模型複雜度,不容易過擬合。但實際上Level-wise是一種低效的演算法,因為它不加區分的對待同一層的葉子,帶來了很多沒必要的開銷,因為實際上很多葉子的分裂增益較低,沒必要進行搜尋和分裂。
在Histogram演算法之上,LightGBM進行進一步的優化。首先它拋棄了大多數GBDT工具使用的按層生長 (level-wise)
的決策樹生長策略,而使用了帶有深度限制的按葉子生長 (leaf-wise)演算法。
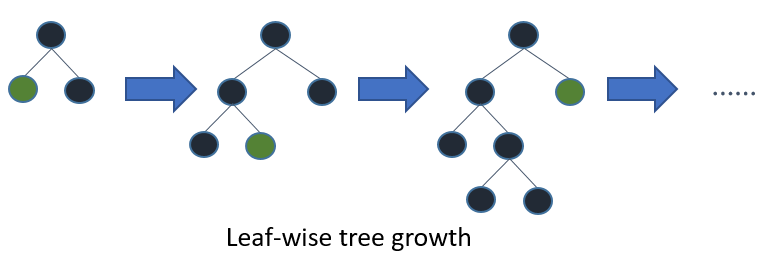
Leaf-wise則是一種更為高效的策略,每次從當前所有葉子中,找到分裂增益最大的一個葉子,然後分裂,如此迴圈。因此同Level-wise相比,在分裂次數相同的情況下,Leaf-wise可以降低更多的誤差,得到更好的精度。Leaf-wise的缺點是可能會長出比較深的決策樹,產生過擬合。因此LightGBM在Leaf-wise之上增加了一個最大深度的限制,在保證高效率的同時防止過擬合。
1.4 直方圖差加速
LightGBM另一個優化是Histogram(直方圖)做差加速。一個容易觀察到的現象:一個葉子的直方圖可以由它的父親節點的直方圖與它兄弟的直方圖做差得到。通常構造直方圖,需要遍歷該葉子上的所有資料,但直方圖做差僅需遍歷直方圖的k個桶。
利用這個方法,LightGBM可以在構造一個葉子的直方圖後,可以用非常微小的代價得到它兄弟葉子的直方圖,在速度上可以提升一倍。
1.5 直接支援類別特徵
實際上大多數機器學習工具都無法直接支援類別特徵,一般需要把類別特徵,轉化到多維的0/1特徵,降低了空間和時間的效率。而類別特徵的使用是在實踐中很常用的。基於這個考慮,LightGBM優化了對類別特徵的支援,可以直接輸入類別特徵,不需要額外的0/1展開。並在決策樹演算法上增加了類別特徵的決策規則。在Expo資料集上的實驗,相比0/1展開的方法,訓練速度可以加速8倍,並且精度一致。據我們所知,LightGBM是第一個直接支援類別特徵的GBDT工具。
2. LightGBM優點
LightGBM (Light Gradient Boosting Machine)(請點選https://github.com/Microsoft/LightGBM)是一個實現GBDT演算法的框架,支援高效率的並行訓練,並且具有以下優點:
- 更快的訓練速度
- 更低的記憶體消耗
- 更好的準確率
- 分散式支援,可以快速處理海量資料
3. 程式碼實現
為了演示LightGBM在Python中的用法,本程式碼以sklearn包中自帶的鳶尾花資料集為例,用lightgbm演算法實現鳶尾花種類的分類任務。
GitHub:點選進入
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
歡迎大家加入討論!共同完善此專案!群號:【541954936】
