
我是這樣理解--SVM,不需要繁雜公式的那種!(附程式碼)
1. 講講SVM
1.1 一個關於SVM的童話故事
支援向量機(Support Vector Machine,SVM)是眾多監督學習方法中十分出色的一種,幾乎所有講述經典機器學習方法的教材都會介紹。關於SVM,流傳著一個關於天使與魔鬼的故事。
傳說魔鬼和天使玩了一個遊戲,魔鬼在桌上放了兩種顏色的球。魔鬼讓天使用一根木棍將它們分開。這對天使來說,似乎太容易了。天使不假思索地一擺,便完成了任務。魔鬼又加入了更多的球。隨著球的增多,似乎有的球不能再被原來的木棍正確分開,如下圖所示。

SVM實際上是在為天使找到木棒的最佳放置位置,使得兩邊的球都離分隔它們的木棒足夠遠。依照SVM為天使選擇的木棒位置,魔鬼即使按剛才的方式繼續加入新球,木棒也能很好地將兩類不同的球分開。
看到天使已經很好地解決了用木棒線性分球的問題,魔鬼又給了天使一個新的挑戰,如下圖所示。

按照這種球的擺法,世界上貌似沒有一根木棒可以將它們 完美分開。但天使畢竟有法力,他一拍桌子,便讓這些球飛到了空中,然後憑藉 念力抓起一張紙片,插在了兩類球的中間。從魔鬼的角度看這些 球,則像是被一條曲線完美的切開了。

後來,“無聊”的科學家們把這些球稱為“資料”,把木棍稱為“分類面”,找到最 大間隔的木棒位置的過程稱為“優化”,拍桌子讓球飛到空中的念力叫“核對映”,在 空中分隔球的紙片稱為“分類超平面”。這便是SVM的童話故事。
1.2 理解SVM:第一層
支援向量機,因其英文名為support vector machine,故一般簡稱SVM,通俗來講,它是一種二類分類模型,其基本模型定義為特徵空間上的間隔最大的線性分類器,其學習策略便是間隔最大化,最終可轉化為一個凸二次規劃問題的求解。
線性分類器:給定一些資料點,它們分別屬於兩個不同的類,現在要找到一個線性分類器把這些資料分成兩類。如果用x表示資料點,用y表示類別(y可以取1或者0,分別代表兩個不同的類),一個線性分類器的學習目標便是要在n維的資料空間中找到一個超平面(hyper plane),這個超平面的方程可以表示為( wT中的T代表轉置):
\[w^Tx+b=0\]
這裡可以檢視我之前的邏輯迴歸章節回顧:點選開啟
這個超平面可以用分類函式 \(f(x)=w^Tx+b\) 表示,當f(x) 等於0的時候,x便是位於超平面上的點,而f(x)大於0的點對應 y=1 的資料點,f(x)小於0的點對應y=-1的點,如下圖所示:

1.2.1 函式間隔與幾何間隔
在超平面wx+b=0確定的情況下,|wx+b|能夠表示點x到距離超平面的遠近,而通過觀察wx+b的符號與類標記y的符號是否一致可判斷分類是否正確,所以,可以用(y(w*x+b))的正負性來判定或表示分類的正確性。於此,我們便引出了函式間隔(functional margin)的概念。
函式間隔公式:\[\gamma=y(w^Tx+b)=yf(x)\]
而超平面(w,b)關於資料集T中所有樣本點(xi,yi)的函式間隔最小值(其中,x是特徵,y是結果標籤,i表示第i個樣本),便為超平面(w, b)關於訓練資料集T的函式間隔:
\[\gamma=min\gamma i(i=1,...n)\]
但這樣定義的函式間隔有問題,即如果成比例的改變w和b(如將它們改成2w和2b),則函式間隔的值f(x)卻變成了原來的2倍(雖然此時超平面沒有改變),所以只有函式間隔還遠遠不夠。
幾何間隔
事實上,我們可以對法向量w加些約束條件,從而引出真正定義點到超平面的距離--幾何間隔(geometrical margin)的概念。假定對於一個點 x ,令其垂直投影到超平面上的對應點為 x0 ,w 是垂直於超平面的一個向量,\(\gamma\)為樣本x到超平面的距離,如下圖所示:

這裡我直接給出幾何間隔的公式,詳細推到請檢視博文:點選進入
幾何間隔:\(\gamma^{'}=\frac{\gamma}{||w||}\)
從上述函式間隔和幾何間隔的定義可以看出:幾何間隔就是函式間隔除以||w||,而且函式間隔y(wx+b) = yf(x)實際上就是|f(x)|,只是人為定義的一個間隔度量,而幾何間隔|f(x)|/||w||才是直觀上的點到超平面的距離。
1.2.2 最大間隔分類器的定義
對一個數據點進行分類,當超平面離資料點的“間隔”越大,分類的確信度(confidence)也越大。所以,為了使得分類的確信度儘量高,需要讓所選擇的超平面能夠最大化這個“間隔”值。這個間隔就是下圖中的Gap的一半。

通過由前面的分析可知:函式間隔不適合用來最大化間隔值,因為在超平面固定以後,可以等比例地縮放w的長度和b的值,這樣可以使得 \(f(x)=w^Tx+b\) 的值任意大,亦即函式間隔可以在超平面保持不變的情況下被取得任意大。但幾何間隔因為除上了,使得在縮放w和b的時候幾何間隔的值是不會改變的,它只隨著超平面的變動而變動,因此,這是更加合適的一個間隔。換言之,這裡要找的最大間隔分類超平面中的“間隔”指的是幾何間隔。
如下圖所示,中間的實線便是尋找到的最優超平面(Optimal Hyper Plane),其到兩條虛線邊界的距離相等,這個距離便是幾何間隔,兩條虛線間隔邊界之間的距離等於2倍幾何間隔,而虛線間隔邊界上的點則是支援向量。由於這些支援向量剛好在虛線間隔邊界上,所以它們滿足\(y(w_Tx+b)=1\),對於所有不是支援向量的點,則顯然有\(y(w_Tx+b)>1\)。

OK,到此為止,算是瞭解到了SVM的第一層,對於那些只關心怎麼用SVM的朋友便已足夠,不必再更進一層深究其更深的原理。
1.2.3 最大間隔損失函式Hinge loss
SVM 求解使通過建立二次規劃原始問題,引入拉格朗日乘子法,然後轉換成對偶的形式去求解,這是一種理論非常充實的解法。這裡換一種角度來思考,在機器學習領域,一般的做法是經驗風險最小化 (empirical risk minimization,ERM),即構建假設函式(Hypothesis)為輸入輸出間的對映,然後採用損失函式來衡量模型的優劣。求得使損失最小化的模型即為最優的假設函式,採用不同的損失函式也會得到不同的機器學習演算法。SVM採用的就是Hinge Loss,用於“最大間隔(max-margin)”分類。
\[L_i=\sum_{j\neq t_i}max(0,f(x_i,W)_j-(f(x_i,W)_{y_i}-\bigtriangleup))\]
- 對於訓練集中的第i個數據xi
- 在W下會有一個得分結果向量f(xi,W)
- 第j類的得分為我們記作f(xi,W)j
要理解這個公式,首先先看下面這張圖片:

- 在生活中我們都會認為沒有威脅的才是最好的,比如拿成績來說,自己考了第一名99分,而第二名緊隨其後98分,那麼就會有不安全的感覺,就會認為那傢伙隨時都有可能超過我。如果第二名是85分,那就會感覺安全多了,第二名需要花費很大的力氣才能趕上自己。拿這個例子套到上面這幅圖也是一樣的。
- 上面這幅圖delta左邊的紅點是一個安全警戒線,什麼意思呢?也就是說預測錯誤得分超過這個安全警戒線就會得到一個懲罰權重,讓這個預測錯誤值退回到安全警戒線以外,這樣才能夠保證預測正確的結果具有唯一性。
- 對應到公式中,\(f(x_i,W)_j\) 就是錯誤分類的得分。後面一項就是 正確得分 - delta = 安全警戒線值,兩項的差代表的就是懲罰權重,越接近正確得分,權重越大。當錯誤得分在警戒線以外時,兩項相減得到負數,那麼損失函式的最大值是0,也就是沒有損失。
- 一直往復迴圈訓練資料,直到最小化損失函式為止,也就找到了分類超平面。
1.3 深入SVM:第二層
1.3.1 從線性可分到線性不可分
接著考慮之前得到的目標函式(令函式間隔=1):
\[max\frac{1}{||w||}s.t.,y_i(w^Tx_i+b)\ge1,i=1,...,n\]
轉換為對偶問題,解釋一下什麼是對偶問題,對偶問題是實質相同但從不同角度提出不同提法的一對問題。
由於求 \(\frac{1}{||w||}\) 的最大值相當於求 \(\frac{1}{2}||w||^2\) 的最小值,所以上述目標函式等價於(w由分母變成分子,從而也有原來的max問題變為min問題,很明顯,兩者問題等價):
\[min\frac{1}{2}||w||^2s.t.,y_i(w^Tx_i+b)\ge1,i=1,...,n\]
因為現在的目標函式是二次的,約束條件是線性的,所以它是一個凸二次規劃問題。這個問題可以用現成的QP (Quadratic Programming) 優化包進行求解。一言以蔽之:在一定的約束條件下,目標最優,損失最小。
此外,由於這個問題的特殊結構,還可以通過拉格朗日對偶性(Lagrange Duality)變換到對偶變數 (dual variable) 的優化問題,即通過求解與原問題等價的對偶問題(dual problem)得到原始問題的最優解,這就是線性可分條件下支援向量機的對偶演算法,這樣做的優點在於:一者對偶問題往往更容易求解;二者可以自然的引入核函式,進而推廣到非線性分類問題。
詳細過程請參考文章末尾給出的參考連結。
1.3.2 核函式Kernel
事實上,大部分時候資料並不是線性可分的,這個時候滿足這樣條件的超平面就根本不存在。在上文中,我們已經瞭解到了SVM處理線性可分的情況,那對於非線性的資料SVM咋處理呢?對於非線性的情況,SVM 的處理方法是選擇一個核函式 κ(⋅,⋅) ,通過將資料對映到高維空間,來解決在原始空間中線性不可分的問題。
具體來說,線上性不可分的情況下,支援向量機首先在低維空間中完成計算,然後通過核函式將輸入空間對映到高維特徵空間,最終在高維特徵空間中構造出最優分離超平面,從而把平面上本身不好分的非線性資料分開。如圖所示,一堆資料在二維空間無法劃分,從而對映到三維空間裡劃分:

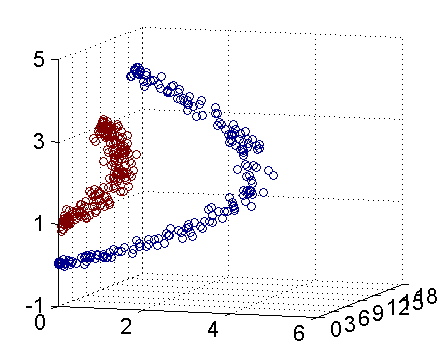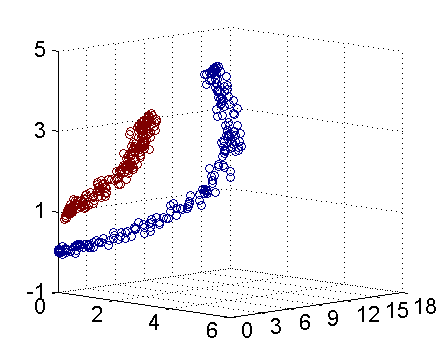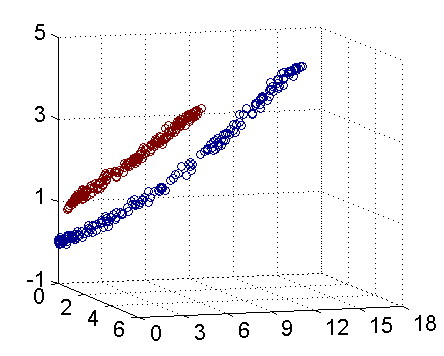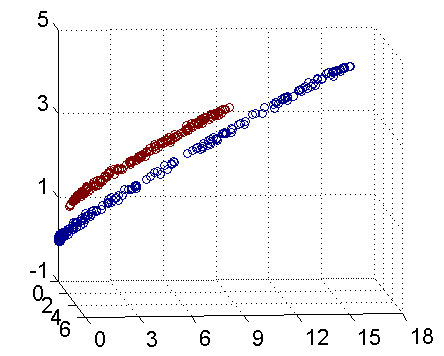
通常人們會從一些常用的核函式中選擇(根據問題和資料的不同,選擇不同的引數,實際上就是得到了不同的核函式),例如:多項式核、高斯核、線性核。
讀者可能還是沒明白核函式到底是個什麼東西?我再簡要概括下,即以下三點:
- 實際中,我們會經常遇到線性不可分的樣例,此時,我們的常用做法是把樣例特徵對映到高維空間中去(對映到高維空間後,相關特徵便被分開了,也就達到了分類的目的);
- 但進一步,如果凡是遇到線性不可分的樣例,一律對映到高維空間,那麼這個維度大小是會高到可怕的。那咋辦呢?
- 此時,核函式就隆重登場了,核函式的價值在於它雖然也是將特徵進行從低維到高維的轉換,但核函式絕就絕在它事先在低維上進行計算,而將實質上的分類效果表現在了高維上,避免了直接在高維空間中的複雜計算。
如果資料中出現了離群點outliers,那麼就可以使用鬆弛變數來解決。
1.3.3 總結
不準確的說,SVM它本質上即是一個分類方法,用 w^T+b 定義分類函式,於是求w、b,為尋最大間隔,引出1/2||w||^2,繼而引入拉格朗日因子,化為對拉格朗日乘子a的求解(求解過程中會涉及到一系列最優化或凸二次規劃等問題),如此,求w.b與求a等價,而a的求解可以用一種快速學習演算法SMO,至於核函式,是為處理非線性情況,若直接對映到高維計算恐維度爆炸,故在低維計算,等效高維表現。
OK,理解到這第二層,已經能滿足絕大部分人一窺SVM原理的好奇心,針對於面試來說已經足夠了。
1.4 SVM的應用
SVM在很多諸如文字分類,影象分類,生物序列分析和生物資料探勘,手寫字元識別等領域有很多的應用,但或許你並沒強烈的意識到,SVM可以成功應用的領域遠遠超出現在已經在開發應用了的領域。
2. SVM的一些問題
是否存在一組引數使SVM訓練誤差為0?
答:存在
訓練誤差為0的SVM分類器一定存在嗎?
答:一定存在
加入鬆弛變數的SVM的訓練誤差可以為0嗎?
答:使用SMO演算法訓練的線性分類器並不一定能得到訓練誤差為0的模型。這是由 於我們的優化目標改變了,並不再是使訓練誤差最小。
帶核的SVM為什麼能分類非線性問題?
答:核函式的本質是兩個函式的內積,通過核函式將其隱射到高維空間,在高維空間非線性問題轉化為線性問題, SVM得到超平面是高維空間的線性分類平面。其分類結果也視為低維空間的非線性分類結果, 因而帶核的SVM就能分類非線性問題。
如何選擇核函式?
- 如果特徵的數量大到和樣本數量差不多,則選用LR或者線性核的SVM;
- 如果特徵的數量小,樣本的數量正常,則選用SVM+高斯核函式;
- 如果特徵的數量小,而樣本的數量很大,則需要手工新增一些特徵從而變成第一種情況。
3. LR和SVM的聯絡與區別
3.1 相同點
- 都是線性分類器。本質上都是求一個最佳分類超平面。
- 都是監督學習演算法。
- 都是判別模型。判別模型不關心資料是怎麼生成的,它只關心訊號之間的差別,然後用差別來簡單對給定的一個訊號進行分類。常見的判別模型有:KNN、SVM、LR,常見的生成模型有:樸素貝葉斯,隱馬爾可夫模型。
3.2 不同點
- LR是引數模型,svm是非引數模型,linear和rbf則是針對資料線性可分和不可分的區別;
- 從目標函式來看,區別在於邏輯迴歸採用的是logistical loss,SVM採用的是hinge loss,這兩個損失函式的目的都是增加對分類影響較大的資料點的權重,減少與分類關係較小的資料點的權重。
- SVM的處理方法是隻考慮support vectors,也就是和分類最相關的少數點,去學習分類器。而邏輯迴歸通過非線性對映,大大減小了離分類平面較遠的點的權重,相對提升了與分類最相關的資料點的權重。
- 邏輯迴歸相對來說模型更簡單,好理解,特別是大規模線性分類時比較方便。而SVM的理解和優化相對來說複雜一些,SVM轉化為對偶問題後,分類只需要計算與少數幾個支援向量的距離,這個在進行復雜核函式計算時優勢很明顯,能夠大大簡化模型和計算。
- logic 能做的 svm能做,但可能在準確率上有問題,svm能做的logic有的做不了。
4. 線性分類器與非線性分類器的區別以及優劣
線性和非線性是針對模型引數和輸入特徵來講的;比如輸入x,模型y=ax+ax^2 那麼就是非線性模型,如果輸入是x和X^2則模型是線性的。
線性分類器可解釋性好,計算複雜度較低,不足之處是模型的擬合效果相對弱些。
LR,貝葉斯分類,單層感知機、線性迴歸
非線性分類器效果擬合能力較強,不足之處是資料量不足容易過擬合、計算複雜度高、可解釋性不好。
決策樹、RF、GBDT、多層感知機
SVM兩種都有(看線性核還是高斯核)
5. 程式碼實現
新聞分類 GitHub:點選進入
6. 參考文獻
支援向量機通俗導論(理解SVM的三層境界)
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
歡迎大家加入討論!共同完善此專案!群號:【541954936】
