
MyBatis 核心配置綜述之Executor
目錄
- MyBatis四大元件之 Executor執行器
- Executor的繼承結構
- Executor建立過程以及原始碼分析
- Executor介面的主要方法
- Executor 的現實抽象
- MyBatis四大元件之 Executor執行器
上一篇我們對SqlSession和SqlSessionFactory的建立過程有了一個詳細的瞭解,但上述的建立過程只是為SQL執行和SQL對映做了基礎的鋪墊而已,就和我們Spring原始碼為Bean容器的載入進行許多初始化的工作相同,那麼做好前期的準備工作接下來該做什麼了?該做資料庫連線驅動管理和SQL解析工作了!那麼本篇本章就來討論一下資料庫驅動連線管理和SQL解析的管理元件之 Executor執行器。
MyBatis四大元件之 Executor執行器
每一個SqlSession都會擁有一個Executor物件,這個物件負責增刪改查的具體操作,我們可以簡單的將它理解為JDBC中Statement的封裝版。
Executor的繼承結構
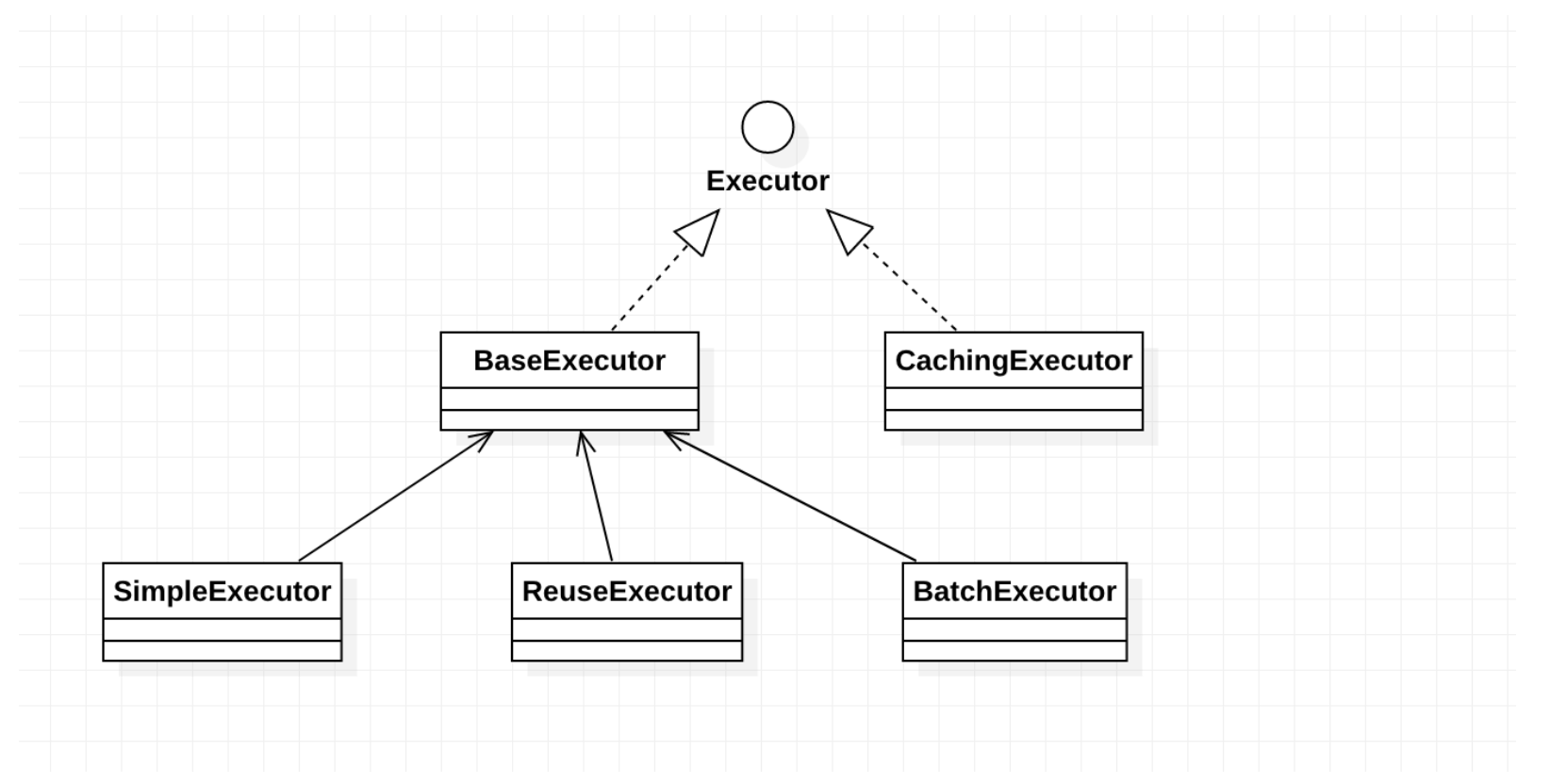
如圖所示,位於繼承體系最頂層的是Executor執行器,它有兩個實現類,分別是BaseExecutor和 CachingExecutor。
BaseExecutor 是一個抽象類,這種通過抽象的實現介面的方式是介面卡設計模式之介面適配的體現,是Executor的預設實現,實現了大部分Executor介面定義的功能,降低了介面實現的難度。BaseExecutor的子類有三個,分別是SimpleExecutor
ReuseExecutor和BatchExecutor。
SimpleExecutor: 簡單執行器,是MyBatis中預設使用的執行器,每執行一次update或select,就開啟一個Statement物件,用完就直接關閉Statement物件(可以是Statement或者是PreparedStatment物件)
ReuseExecutor: 可重用執行器,這裡的重用指的是重複使用Statement,它會在內部使用一個Map把建立的Statement都快取起來,每次執行SQL命令的時候,都會去判斷是否存在基於該SQL的Statement物件,如果存在Statement物件並且對應的connection還沒有關閉的情況下就繼續使用之前的Statement物件,並將其快取起來。因為每一個SqlSession都有一個新的Executor物件,所以我們快取在ReuseExecutor上的Statement作用域是同一個SqlSession。
BatchExecutor: 批處理執行器,用於將多個SQL一次性輸出到資料庫
CachingExecutor: 快取執行器,先從快取中查詢結果,如果存在,就返回;如果不存在,再委託給Executor delegate 去資料庫中取,delegate可以是上面任何一個執行器
Executor建立過程以及原始碼分析
上面我們分析完SqlSessionFactory的建立過程的準備工作後,我們下面就開始分析會話的建立以及Executor的執行過程。
在建立完SqlSessionFactory之後,呼叫其openSession方法:
SqlSession sqlSession = factory.openSession();SqlSessionFactory的預設實現是DefaultSqlSessionFactory,所以我們需要關心的就是DefaultSqlSessionFactory中的openSession()方法
openSession呼叫的是openSessionFromDataSource方法,傳遞執行器的型別,方法傳播級別,是否自動提交,然後在openSessionFromDataSource方法中會建立一個執行器
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
// 得到configuration 中的environment
final Environment environment = configuration.getEnvironment();
// 得到configuration 中的事務工廠
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 獲取執行器
final Executor executor = configuration.newExecutor(tx, execType);
// 返回預設的SqlSession
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}呼叫newExecutor方法,根據傳入的ExecutorType型別來判斷是哪種執行器,然後執行相應的邏輯
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
// defaultExecutorType預設是簡單執行器, 如果不傳executorType的話,預設使用簡單執行器
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
// 根據執行器型別生成對應的執行器邏輯
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 如果允許快取,則使用快取執行器
// 預設是true,如果不允許快取的話,需要手動設定
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// 外掛開發。
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}ExecutorType的選擇:
ExecutorType來決定Configuration物件建立何種型別的執行器,它的賦值可以通過兩個地方進行賦值:
- 可以通過
標籤來設定當前工程中所有的SqlSession物件使用預設的Executor <settings> <!--取值範圍 SIMPLE, REUSE, BATCH --> <setting name="defaultExecutorType" value="SIMPLE"/> </settings>
- 另外一種直接通過Java對方法賦值的方式
session = factory.openSession(ExecutorType.BATCH);ExecutorType是一個列舉,它只有三個值SIMPLE, REUSE, BATCH
建立完成Executor之後,會把Executor執行器放入一個DefaultSqlSession物件中來對四個屬性進行賦值,他們分別是 configuration、executor、 dirty、autoCommit。
Executor介面的主要方法
Executor介面的方法還是比較多的,這裡我們就幾個主要的方法和呼叫流程來做一個簡單的描述
大致流程
Executor中的大部分方法的呼叫鏈其實是差不多的,下面都是深入原始碼分析執行過程,如果你沒有時間或者暫時不想深入研究的話,給你下面的執行流程圖作為參考。
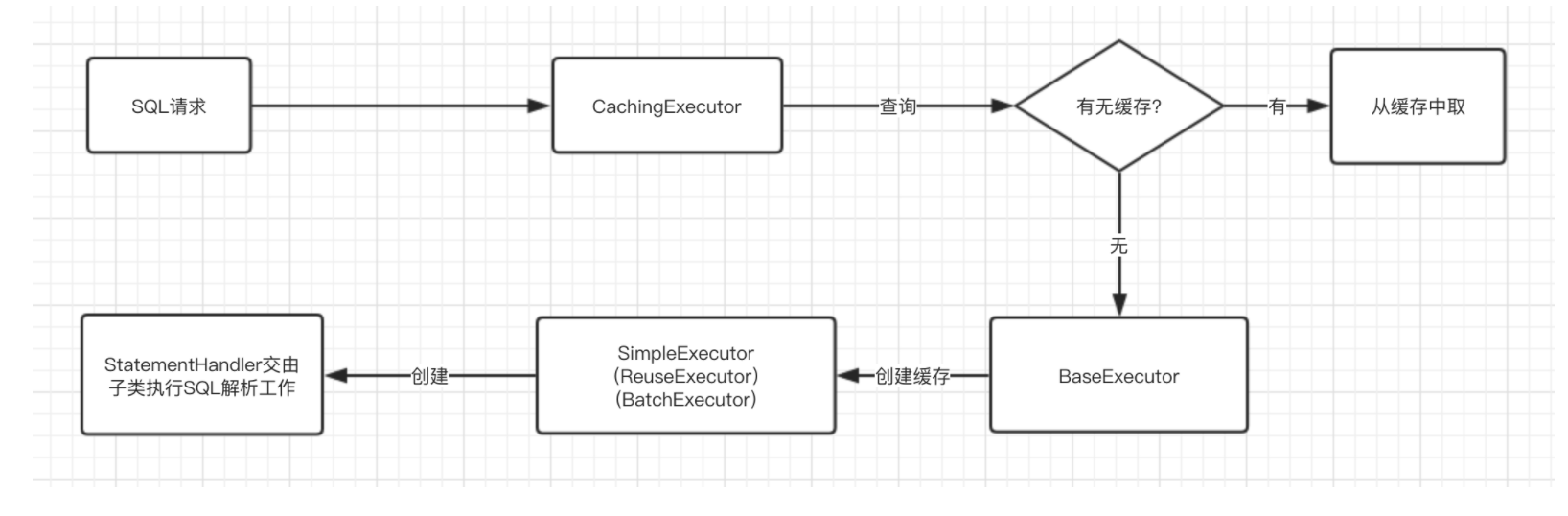
query()方法
query方法有兩種形式,一種是直接查詢;一種是從快取中查詢,下面來看一下原始碼
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException;
<E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException;當有一個查詢請求訪問的時候,首先會經過Executor的實現類CachingExecutor,先從快取中查詢SQL是否是第一次執行,如果是第一次執行的話,那麼就直接執行SQL語句,並建立快取,如果第二次訪問相同的SQL語句的話,那麼就會直接從快取中提取
CachingExecutor.j
// 第一次查詢,並建立快取
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
MapperStatement維護了一條<select|update|delete|insert>節點的封裝,包括資源(resource),配置(configuration),SqlSource(sql原始檔)等。使用Configuration的getMappedStatement方法來獲取MappedStatement物件
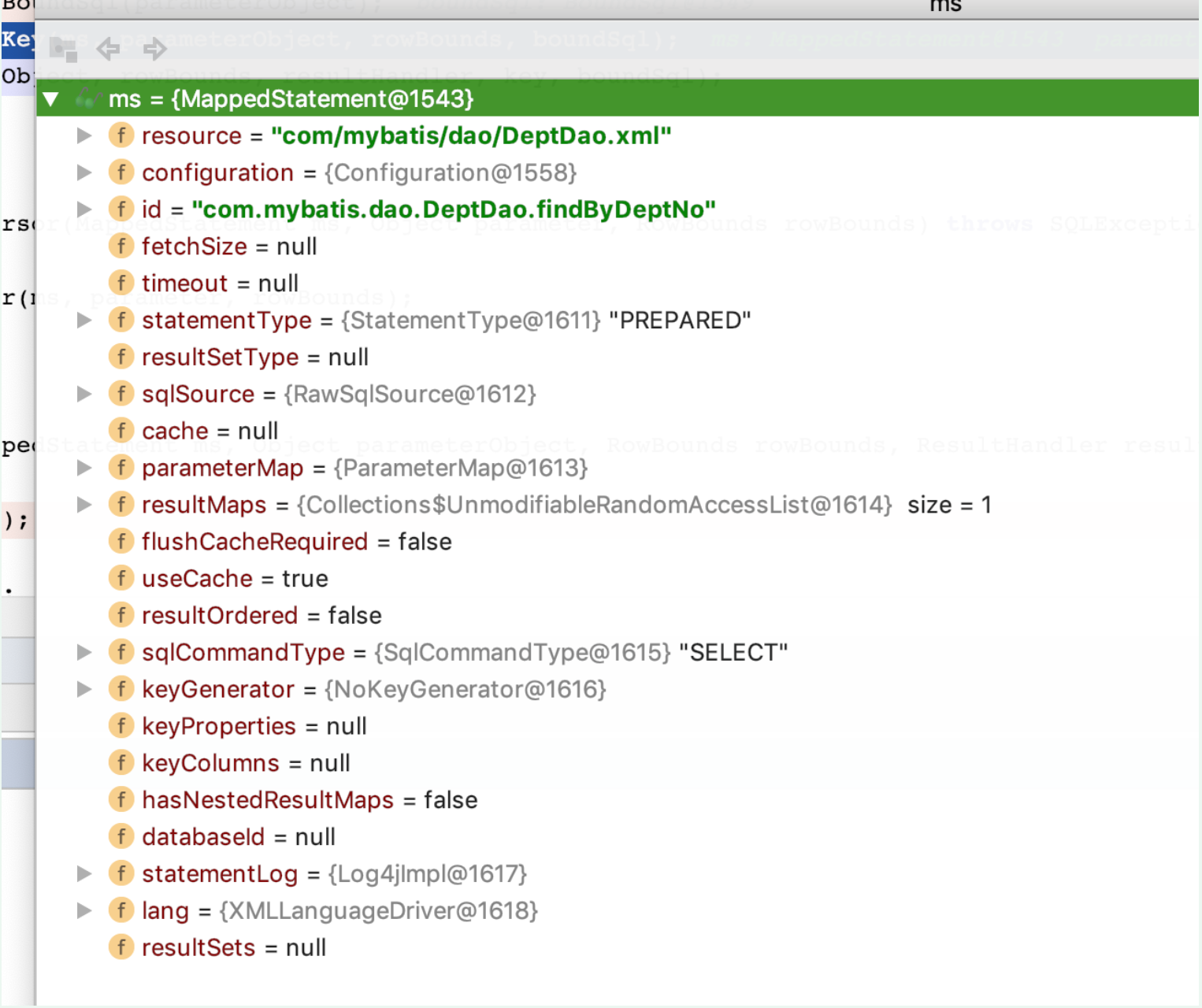
BoundSql這個類包括SQL的基本資訊,基本的SQL語句,引數對映,引數型別等
上述的query方法會呼叫到CachingExecutor類中的query查詢快取的方法
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 得到快取
Cache cache = ms.getCache();
if (cache != null) {
// 如果需要的話重新整理快取
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list);
}
return list;
}
}
// 委託模式,交給SimpleExecutor等實現類去實現方法。
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}由delegate執行query方法,delegate即是BaseExecutor,然後由具體的執行器去真正執行query方法
注意:原始碼中一般以do** 開頭的方法都是真正載入執行的方法
// 經過一系列的呼叫,會呼叫到下面的方法(與主流程無關,故省略)
// 以SimpleExecutor簡單執行器為例
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
// 獲取環境配置
Configuration configuration = ms.getConfiguration();
// 建立StatementHandler,解析SQL語句
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
// 由handler來對SQL語句執行解析工作
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}由上面的原始碼可以看出,Executor執行器所起的作用相當於是管理StatementHandler 的整個生命週期的工作,包括建立、初始化、解析、關閉。
ReuseExecutor完成的doQuery 工作:幾乎和SimpleExecutor完成的工作一樣,其內部不過是使用一個Map來儲存每次執行的查詢語句,為後面的SQL重用作準備。
BatchExecutor完成的doQuery 工作:和SimpleExecutor完成的工作一樣。
update() 方法
在分析完上面的查詢方法後,我們再來聊一下update()方法,update()方法不僅僅指的是update()方法,它是一條update鏈,什麼意思呢?就是*insert、update、delete在語義上其實都是更新的意思,而查詢在語義上僅僅只是表示的查詢,那麼我們來偷窺一下update方法的執行流程,與select的主要執行流程很相似,所以一次性貼出。
// 首先在頂級介面中定義update 方法,交由子類或者抽象子類去實現
// 也是首先去快取中查詢是否具有已經執行過的相同的update語句
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
flushCacheIfRequired(ms);
return delegate.update(ms, parameterObject);
}
// 然後再交由BaseExecutor 執行update 方法
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
// 往往do* 開頭的都是真正執行解析的方法,所以doUpdate 應該就是真正要執行update鏈的解析方法了
// 交給具體的執行器去執行
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.update(stmt);
} finally {
closeStatement(stmt);
}
}ReuseExecutor完成的doUpdate 工作:幾乎和SimpleExecutor完成的工作一樣,其內部不過是使用一個Map來儲存每次執行的更新語句,為後面的SQL重用作準備。
BatchExecutor完成的doUpdate 工作:和SimpleExecutor完成的工作相似,只是其內部有一個List列表來一次行的儲存多個Statement,用於將多個sql語句一次性輸送到資料庫執行.
queryCursor()方法
我們查閱其原始碼的時候,在執行器的執行過程中並沒有發現其與query方法有任何不同之處,但是在doQueryCursor 方法中我們可以看到它返回了一個cursor物件,網上搜索cursor的相關資料並查閱其基本結構,得出來的結論是:用於逐條讀取SQL語句,應對資料量
// 查詢可以返回Cursor<T>型別的資料,類似於JDBC裡的ResultSet類,
// 當查詢百萬級的資料的時候,使用遊標可以節省記憶體的消耗,不需要一次性取出所有資料,可以進行逐條處理或逐條取出部分批量處理。
public interface Cursor<T> extends Closeable, Iterable<T> {
boolean isOpen();
boolean isConsumed();
int getCurrentIndex();
}flushStatements() 方法
flushStatement()的主要執行流程和query,update 的執行流程差不多,我們這裡就不再詳細貼程式碼了,簡單說一下flushStatement()的主要作用,flushStatement()主要用來釋放statement,或者用於ReuseExecutor和BatchExecutor來重新整理快取
createCacheKey() 方法
createCacheKey()方法主要由BaseExecutor來執行並建立快取,MyBatis中的快取分為一級快取和二級快取,關於快取的討論我們將在Mybatis系列的快取章節
Executor 中的其他方法
Executor 中還有其他方法,提交commit,回滾rollback,判斷是否時候快取isCached,關閉close,獲取事務getTransaction一級清除本地快取clearLocalCache等
Executor 的現實抽象
在上面的分析過程中我們瞭解到,Executor執行器是MyBatis中很重要的一個元件,Executor相當於是外包的boss,它定義了甲方(SQL)需要乾的活(Executor的主要方法),這個外包公司是個小公司,沒多少人,每個人都需要幹很多工作,boss接到開發任務的話,一般都找專案經理(CachingExecutor),專案經理幾乎不懂技術,它主要和技術leader(BaseExecutor)打交道,技術leader主要負責框架的搭建,具體的工作都會交給下面的程式設計師來做,程式設計師的技術也有優劣,高階程式設計師(BatchExecutor)、中級程式設計師(ReuseExecutor)、初級程式設計師(SimpleExecutor),它們乾的活也不一樣。一般有新的專案需求傳達到專案經理這裡,專案經理先判斷自己手裡有沒有現成的類庫或者專案直接套用(Cache),有的話就直接讓技術leader拿來直接套用就好,沒有的話就需要搭建框架,再把框架存入本地類庫中,再進行解析。
(本文完)
下文預告: MyBatis 核心配置綜述之StatementHandler
文章參考:
https://www.jianshu.com/p/19686af69b0d
http://www.mybatis.org/mybatis-3/getting-started.html
https://www.cnblogs.com/virgosnail/p/10067964.