
深入理解Java的switch...case...語句
switch...case...中條件表示式的演進
- 最早時,只支援int、char、byte、short這樣的整型的基本型別或對應的包裝型別Integer、Character、Byte、Short常量
- JDK1.5開始支援enum,原理是給列舉值進行了內部的編號,進行編號和列舉值的對映
- 1.7開始支援String,但不允許為null。(原因可以看後文)
case表示式僅限字面值常量嗎?
case表示式既可以用字面值常量,也可以用final修飾且初始化過的變數。例如以下程式碼可正常編譯並執行:
public static int test(int i) { final int j = 2; int result; switch (i) { case 0: result = 0; break; case j: result = 1; break; case 10: result = 4; break; default: result = -1; } return result; }
但是沒有初始化就不行,比如下面的程式碼就無法通過編譯
public class SwitchTest { private final int caseJ; public int test(int i) { int result; switch (i) { case 0: result = 0; break; case caseJ: result = 1; break; case 10: result = 4; break; default: result = -1; } return result; } SwitchTest(int caseJ) { this.caseJ = caseJ; } public static void main(String[] args) { SwitchTest testJ = new SwitchTest(1); System.out.print(testJ.test(2)); } }
lookupswitch和tableswitch
下面兩種幾乎一樣的程式碼,會編譯出大相徑庭的位元組碼。
lookupswitch
public static int test(int i) { int result; switch (i) { case 0: result = 0; break; case 2: result = 1; break; case 10: result = 4; break; default: result = -1; } return result; }
對應位元組碼
public static int test(int);
Code:
0: iload_0
1: lookupswitch { // 3
0: 36
2: 41
10: 46
default: 51
}
36: iconst_0
37: istore_1
38: goto 53
41: iconst_1
42: istore_1
43: goto 53
46: iconst_4
47: istore_1
48: goto 53
51: iconst_m1
52: istore_1
53: iload_1
54: ireturntableswitch
public static int test(int i) {
int result;
switch (i) {
case 0:
result = 0;
break;
case 2:
result = 1;
break;
case 4:
result = 4;
break;
default:
result = -1;
}
return result;
} public static int test(int);
Code:
0: iload_0
1: tableswitch { // 0 to 4
0: 36
1: 51
2: 41
3: 51
4: 46
default: 51
}
36: iconst_0
37: istore_1
38: goto 53
41: iconst_1
42: istore_1
43: goto 53
46: iconst_4
47: istore_1
48: goto 53
51: iconst_m1
52: istore_1
53: iload_1
54: ireturn兩種位元組碼,最大的區別是執行了不同的指令:lookupswitch和tableswitch。
兩種switch區別
- tableswitch使用了一個數組,通過下標可以直接定位到要跳轉的行。但是在生成位元組碼時,有的行可能在原始碼中並不存在。通過這種方式可以獲得O(1)的時間複雜度。
- lookupswitch維護了一個key-value的關係,通過逐個比較索引來查詢匹配的待跳轉的行數。而查詢最好的效能是O(log n),如二分查詢。
可見,通過用冗餘的機器碼,tableswitch換取了更好的效能。
但是,在分支比較少的情況下,O(log n)其實並不大。n=2時,log n 約為2.8;即使n=100, log n 約為 6.6,與1仍未達到1個數量級的差距。
何時生成tableswitch?何時生成lookupswitch?
在JDK1.8環境下,通過檢索langtools這個包,可以在langtools/src/share/classes/com/sun/tools/javac/jvm/Gen.java看到以下程式碼:
long table_space_cost = 4 + ((long) hi - lo + 1); // words
long table_time_cost = 3; // comparisons
long lookup_space_cost = 3 + 2 * (long) nlabels;
long lookup_time_cost = nlabels;
int opcode =
nlabels > 0 && table_space_cost + 3 * table_time_cost <= lookup_space_cost + 3 * lookup_time_cost
?
tableswitch : lookupswitch;這段程式碼的上下文:
- hi和lo分別代表值的上下限,是通過遍歷switch...case...每個分支獲取的。
- nlabels表示switch...case...的分支個數
可以看出,決策的條件綜合考慮了時間複雜度(table_time_cost/lookup_time_cost)和空間複雜度(table_space_cost/lookup_space_cost),並且時間複雜度的權重是空間複雜度的3倍。
存疑點:
- 各種幻數沒有解釋取值的原因,比如4、3,應該和具體細節實現有關。
- lookupswitch的時間複雜度使用的是nlabels而沒有取log n。此處可以看做是近似計算。
switch...case...優於if...else...嗎?
一般來說,更多的限制能帶來更好的效能。
從上文可以看出,無論是tableswitch還是lookupswitch,都有對隨機查詢的優化,而if...else...是沒有的,可以看下面的原始碼和位元組碼。
public static int test2(int i) {
int result;
if(i == 0) {
result = 0;
} else if(i == 1) {
result = 1;
} else if(i == 4) {
result = 4;
} else {
result = -1;
}
return result;
} public static int test2(int);
Code:
0: iload_0
1: ifne 9
4: iconst_0
5: istore_1
6: goto 31
9: iload_0
10: iconst_1
11: if_icmpne 19
14: iconst_1
15: istore_1
16: goto 31
19: iload_0
20: iconst_4
21: if_icmpne 29
24: iconst_4
25: istore_1
26: goto 31
29: iconst_m1
30: istore_1
31: iload_1
32: ireturn字串常量的case表示式及位元組碼
舉例如下,這段原始碼有兩個特點:
- case "ghi"分支裡是沒有賦值程式碼
- case "test"分支和case "test2"分支相同
public static int testString(String str) {
int result = -4;
switch (str) {
case "abc":
result = 0;
break;
case "def":
result = 1;
break;
case "ghi":
break;
case "test":
case "test2":
result = 1;
break;
default:
result = -1;
}
return result;
}對應位元組碼
public static int testString(java.lang.String);
Code:
0: bipush -4
2: istore_1
3: aload_0
4: astore_2
5: iconst_m1
6: istore_3
7: aload_2
8: invokevirtual #2 // Method java/lang/String.hashCode:()I
11: lookupswitch { // 5
96354: 60
99333: 74
102312: 88
3556498: 102
110251488: 116
default: 127
}
60: aload_2
61: ldc #3 // String abc
63: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
66: ifeq 127
69: iconst_0
70: istore_3
71: goto 127
74: aload_2
75: ldc #5 // String def
77: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
80: ifeq 127
83: iconst_1
84: istore_3
85: goto 127
88: aload_2
89: ldc #6 // String ghi
91: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
94: ifeq 127
97: iconst_2
98: istore_3
99: goto 127
102: aload_2
103: ldc #7 // String test
105: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
108: ifeq 127
111: iconst_3
112: istore_3
113: goto 127
116: aload_2
117: ldc #8 // String test2
119: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z
122: ifeq 127
125: iconst_4
126: istore_3
127: iload_3
128: tableswitch { // 0 to 4
0: 164
1: 169
2: 174
3: 177
4: 177
default: 182
}
164: iconst_0
165: istore_1
166: goto 184
169: iconst_1
170: istore_1
171: goto 184
174: goto 184
177: iconst_1
178: istore_1
179: goto 184
182: iconst_m1
183: istore_1
184: iload_1
185: ireturn可以看到與整型常量的不同:
- String常量判等,先計算hashCode,在lookupswitch分支中再比較是否真正相等。這也是不支援null的原因,此時hashCode無法計算。
- lookupswitch分支中,會給每個分支分配一個新下標值,作為後面的tableswitch的索引。原始碼中的分支語句統一在tableswitch中對應分支執行。
為什麼要再生成一段tableswitch?從位元組碼來看,兩個平行的分支("test"和"test2"),雖然沒有在tableswitch中用同一個陣列下標,但是使用了同一個跳轉行177,在這種情況下減少了位元組碼冗餘。
列舉的case表示式及位元組碼
樣例程式碼如下
public static int testEnum(StatusEnum statusEnum) {
int result;
switch (statusEnum) {
case INIT:
result = 0;
break;
case FINISH:
result = 1;
break;
default:
result = -1;
}
return result;
}對應位元組碼
public static int testEnum(com.example.StatusEnum);
Code:
0: getstatic #9 // Field com/example/SwitchTest$1.$SwitchMap$com$example$core$service$domain$enums$StatusEnum:[I
3: aload_0
4: invokevirtual #10 // Method com/example/core/service/domain/enums/StatusEnum.ordinal:()I
7: iaload
8: lookupswitch { // 2
1: 36
2: 41
default: 46
}
36: iconst_0
37: istore_1
38: goto 48
41: iconst_1
42: istore_1
43: goto 48
46: iconst_m1
47: istore_1
48: iload_1
49: ireturn可以看到,使用了列舉的ordinal方法確定序號。
其他
通過檢視位元組碼,可以發現原始碼的break關鍵字,對應的是位元組碼goto到具體行的語句。 如果不用break,那麼對應的位元組碼就會“滑落”到下一行語句,繼續執行。
附1——idea檢視位元組碼方法
Mac下preference->Tools->External Tools,點選+,按如下頁面配置即可。
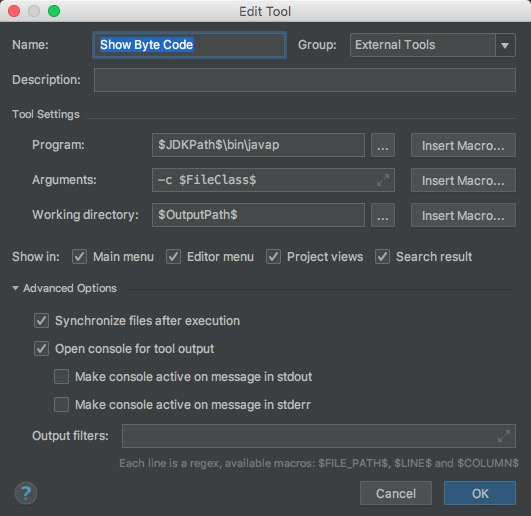
Windows下需要將上圖填入的javap改為javap.exe。
注意:每次檢視位元組碼前,要確保對應類被重新編譯,才能看到最新版。
附2——JDK7或8下,switch...case...使用字串常量編譯報錯解決方式
這種情況的真實原因是,JDK設定不一致,IDE沒有完全使用預期的編譯器版本。
在IDEA裡可以這樣解決:
Project Settings -> Project 設定專案語言
如果仍未解決,檢查
File -> Project Structure -> Modules, 檢視所有模組是否都是預期的等級。
還有一處也可以看下File -> Settings -> Compiler -> Java Compiler. 這裡可以設定專案及模組的編譯器版本。
備註
文中所有log n均為以2為底n的對數。
本文的寫作契機是參加公司的XX安全學習,提到了switch...case...和if...else...的效能有差異,因此花了一天研究了一番。
參考文件
通過位元組碼分析java中的switch語句
Difference between JVM's LookupSwitch and TableSwitch?
IntelliJ switch statement using Strings error: use -source 7
Intellij idea快速檢視Java類位元組