
基於人類獨特性,實現自由人像例項分割檢測
全文共2493字,預計學習時長15分鐘或更長
拍攝:Jezael Melgoza
來源:Unsplash
近年來,由於現實應用需求大,在計算機視覺領域有關“人”的研究層出不窮,實體分割就是其中一員。
一般來說,影象分割首先需要進行物體檢測,然後將物體從邊框檢測中分割開來。不久前,類似於Mask R-CNN的深度學習方法做到了同時檢測和分割物體。但是因為類似身份識別、跟蹤等與人類相關的研究變得越來越普遍,人們可能會好奇為什麼“人類”的獨特性卻被忽視了。
“人類”的獨特性可以很好的通過人的骨架來定義。並且,在多重遮擋的例項當中,人更好地將人體骨骼與邊框區分開來。

圖1 使用人體姿勢比邊框更容易分割高度
本文將回顧《pose2seg:自由檢測人像例項分割》這篇論文。在這篇論文中,作者介紹了一種新型基於姿勢的人像例項分割框架,可基於人體姿勢來分離影象例項。
什麼是例項分割?

圖2 常見的計算機視覺用例
我們想把例項分割可用來在畫素級別影象中識別每一種物品。這說明標記得同時做到分類感知和例項感知,例如圖2(d)對羊1、羊2等作了不同的標記。
例項分割在以下常見用例中被認為最具挑戰性:
分類:圖中有一個人。見圖2(a)
物體檢測:在這張圖中,這些位置有5頭羊。見圖2(b)
語義分割:圖中有羊、人和狗的畫素點。見圖2(c)
例項分割:在這些位置有五頭不同的羊,一個人和一隻狗。見圖2(d)
Pose2Seg:自由人像例項分割檢測
1. 直覺
Pose2Seg背後的產生原因是儘管一般物件例項分割方法運作良好,但這些工作大部分基於強大的物體檢測。也就是說,首先生成大量建議局域,然後使用非極大值抑制(NMS)刪除冗餘區域,如圖3所示。

圖3(左)在非極大值抑制前,(右)在使用非極大值抑制之後。
當同類的兩個事物有很大面積的重疊,NMS會將其當作冗餘的候選區域,然後將它刪除。這種情況說明基本上所有物體檢測方法面對大面積重疊都束手無策。
但是,在處理大多數“人類“時,可通過人類骨架進行定義。如圖1所示,人類骨架更適合用來區分兩個重合面積很大的人。比起邊框,他們可以提供更清晰的個人資訊,比如說不同身體部位的位置和可見性。
2. 網路結構
整體網路結構如圖4所示。網路將所有存在的人類例項以RGB影象輸入。首先,利用主幹網路提取影象特徵;然後,放射對齊模組根據人體姿勢將ROI對齊成統一的大小(為了一致性)。此外,還為每個人體例項生成骨架特徵。
現在,ROI和骨架特徵都融合在一起並傳遞給segmodule分割模組,生成每個ROI的例項分割。最後,仿射對齊操作中的估計矩陣進行反向對齊,得到最終的分割結果。
網路子模組將在下面的小節中詳細描述。

圖4 網路結構概覽:(a)仿射對齊操作(b)骨架特徵(c)SegModule結構
3. 仿射對齊操作
仿射對齊操作主要受快速R-CNN中的ROI池和掩模R-CNN中的ROI對齊的啟發。但是,當根據邊界框對齊人類時,仿射對齊被用來基於人類姿勢的對齊。
要做到這一點,需要離線儲存最常見的人體姿勢,稍後比較訓練/推理時的每個輸入姿勢(參見下面的圖5)。其想法旨在為每個估計姿勢選擇最佳模板。這是通過估計輸入姿態和模板之間的仿射變換矩陣h,並選擇得到最佳分數的仿射變換矩陣h來實現的。
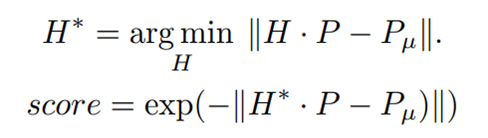
在此P_u代表一個姿勢模板,p代表對一個人的姿勢估計。矩陣H是為最適合每個姿勢模板選擇的仿射變換。最後,將影象或特徵應用得分最高的變換H轉換為所需的解析度。

圖5 仿射對齊操作
4. 骨架特徵

圖6 骨架特徵模型
圖6顯示了骨架特性。對於此任務,將採用部分關聯欄位(PAF)。PAF的輸出是每個骨架2通道的向量場對映。PAF用於表示人體姿勢的骨架結構以及身體部位的部分置信度地圖,以強調身體部位關鍵點周圍區域的重要性。
5. SEGModule
SEGModule是一種簡單的編碼器-解碼器體系結構,其接受域是一大考慮因素。由於在對準後引入了骨架特徵,SEGModule需要有足夠的接收欄位,這不僅能完全理解這些人工特徵,而且能學習它們與基礎網路提取的影象特徵之間的聯絡。因此,它是基於校準的ROI的解析度進行設計的。
該網路首先是7×7,stride -2的卷積層,然後是幾個標準的以實現足夠大的接收場的剩餘單元,用於ROI。然後,用雙線性上取樣層恢復解析度,用另一個剩餘單元和1×1卷積層預測最終結果。這樣一個具有10個剩餘單元的結構可以實現約50個畫素的接收場,相當於 64×64的對齊尺寸。單位越少,網路的學習能力就越差,單位越多,學習能力就越差。
經驗和結果
Pose2Seg在兩類資料庫中得到評測:(1)本文最大的驗證資料集——OCHuman,主要針對過度重合的人類;(2)COCOPerson(COCO的人類別),包含了日常生活中最常見的場景。
該演算法主要與常用的基於檢測的例項分割框架Mask-RCNN進行了比較。
在使用OCHuman資料集對被遮擋資料進行測試時,如表1所示,Pose2Seg框架的效能比Mask R-CNN高出近50%。

表1 遮擋效能。所有的方法在COCOPersons上訓練,並在OCHuman上進行測試。
在一般情況下的測試中,COCOPerson驗證資料集Pose2Seg在例項分割任務中得到0.582ap(平均精度),而Mask R-CNN只得到0.532。見表2

表2 一般情況下表現
要從基於邊框的框架中更好地瞭解pose2seg的優點,請參見下面的圖7。看看“開箱即用”是如何在面具R-CNN中不被分割的。

圖7 在遮擋案例中,pose2seg結果與MaskR-CNN的比較。使用預測的掩模生成邊框,以便更好地進行視覺化和比較。

留言 點贊 關注
我們一起分享AI學習與發展的乾貨
歡迎關注全平臺AI垂類自媒體 “讀芯術”

新增小編微信:dxsxbb
即