
咱們從頭到尾說一次 Java 垃圾回收

之前上學的時候有這個一個梗,說在食堂裡吃飯,吃完把餐盤端走清理的,是 C++ 程式設計師,吃完直接就走的,是 Java 程式設計師。
確實,在 Java 的世界裡,似乎我們不用對垃圾回收那麼的專注,很多初學者不懂 GC,也依然能寫出一個能用甚至還不錯的程式或系統。但其實這並不代表 Java 的 GC 就不重要。相反,它是那麼的重要和複雜,以至於出了問題,那些初學者除了開啟 GC 日誌,看著一堆0101的天文,啥也做不了。
今天我們就從頭到尾完整地聊一聊 Java 的垃圾回收。
什麼是垃圾回收
- 垃圾回收(Garbage Collection,GC),顧名思義就是釋放垃圾佔用的空間,防止記憶體洩露。有效的使用可以使用的記憶體,對記憶體堆中已經死亡的或者長時間沒有使用的物件進行清除和回收。
- Java 語言出來之前,大家都在拼命的寫 C 或者 C++ 的程式,而此時存在一個很大的矛盾,C++ 等語言建立物件要不斷的去開闢空間,不用的時候又需要不斷的去釋放控制元件,既要寫建構函式,又要寫解構函式,很多時候都在重複的 allocated,然後不停的析構。於是,有人就提出,能不能寫一段程式實現這塊功能,每次建立,釋放控制元件的時候複用這段程式碼,而無需重複的書寫呢?
- 1960年,基於 MIT 的 Lisp 首先提出了垃圾回收的概念,用於處理C語言等不停的析構操作,而這時 Java 還沒有出世呢!所以實際上 GC 並不是Java的專利,GC 的歷史遠遠大於 Java 的歷史!
怎麼定義垃圾
既然我們要做垃圾回收,首先我們得搞清楚垃圾的定義是什麼,哪些記憶體是需要回收的。
引用計數演算法
引用計數演算法(Reachability Counting)是通過在物件頭中分配一個空間來儲存該物件被引用的次數(Reference Count)。如果該物件被其它物件引用,則它的引用計數加1,如果刪除對該物件的引用,那麼它的引用計數就減1,當該物件的引用計數為0時,那麼該物件就會被回收。
String m = new String("jack");
先建立一個字串,這時候"jack"有一個引用,就是 m。
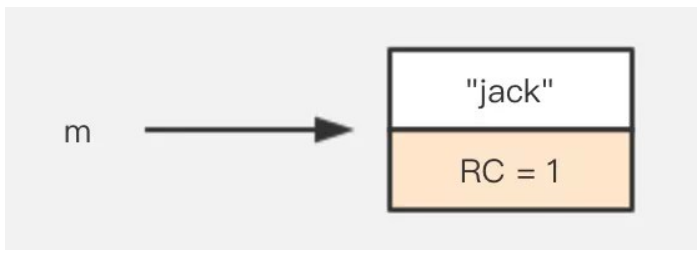
然後將 m 設定為 null,這時候"jack"的引用次數就等於0了,在引用計數演算法中,意味著這塊內容就需要被回收了。
m = null;
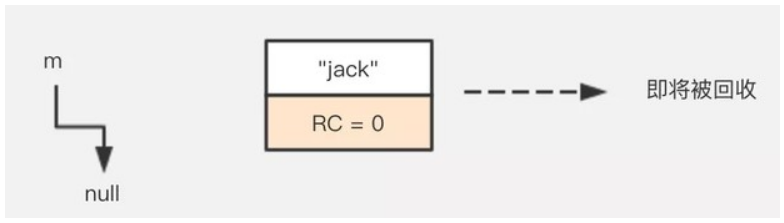
引用計數演算法是將垃圾回收分攤到整個應用程式的運行當中了,而不是在進行垃圾收集時,要掛起整個應用的執行,直到對堆中所有物件的處理都結束。因此,採用引用計數的垃圾收集不屬於嚴格意義上的"Stop-The-World"的垃圾收集機制。
看似很美好,但我們知道JVM的垃圾回收就是"Stop-The-World"的,那是什麼原因導致我們最終放棄了引用計數演算法呢?看下面的例子。
public class ReferenceCountingGC {
public Object instance;
public ReferenceCountingGC(String name){}
}
public static void testGC(){
ReferenceCountingGC a = new ReferenceCountingGC("objA");
ReferenceCountingGC b = new ReferenceCountingGC("objB");
a.instance = b;
b.instance = a;
a = null;
b = null;
}
1. 定義2個物件
2. 相互引用
3. 置空各自的宣告引用
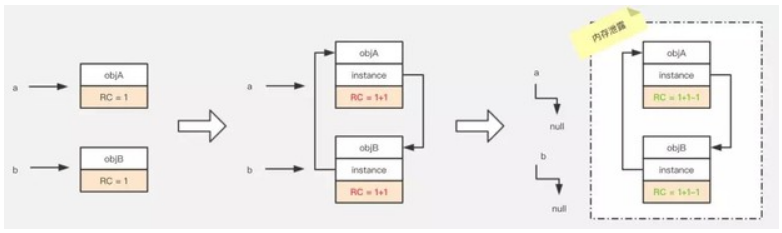
我們可以看到,最後這2個物件已經不可能再被訪問了,但由於他們相互引用著對方,導致它們的引用計數永遠都不會為0,通過引用計數演算法,也就永遠無法通知GC收集器回收它們。
可達性分析演算法
可達性分析演算法(Reachability Analysis)的基本思路是,通過一些被稱為引用鏈(GC Roots)的物件作為起點,從這些節點開始向下搜尋,搜尋走過的路徑被稱為(Reference Chain),當一個物件到 GC Roots 沒有任何引用鏈相連時(即從 GC Roots 節點到該節點不可達),則證明該物件是不可用的。
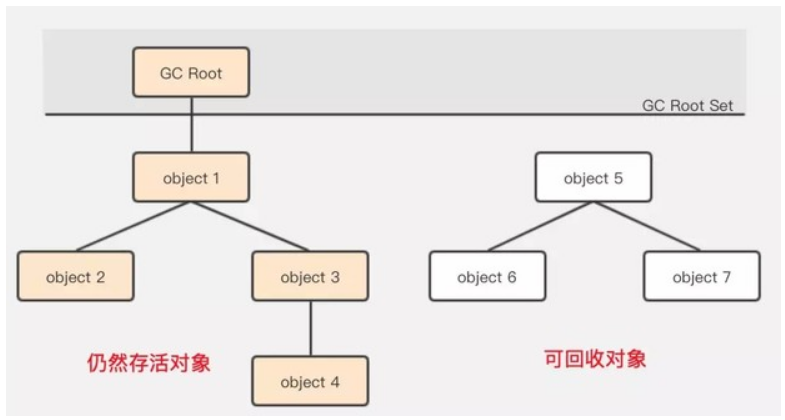
通過可達性演算法,成功解決了引用計數所無法解決的問題-“迴圈依賴”,只要你無法與 GC Root 建立直接或間接的連線,系統就會判定你為可回收物件。那這樣就引申出了另一個問題,哪些屬於 GC Root。
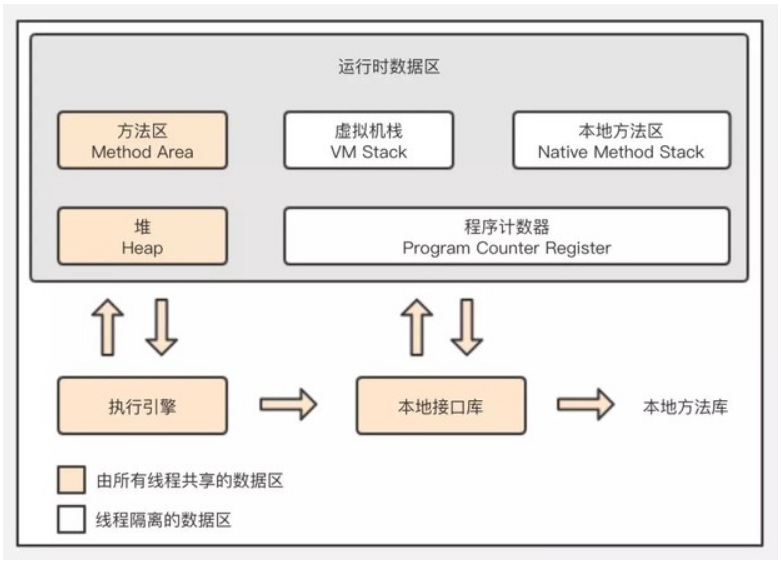
Java 記憶體區域
在 Java 語言中,可作為 GC Root 的物件包括以下4種:
- 虛擬機器棧(棧幀中的本地變量表)中引用的物件
- 方法區中類靜態屬性引用的物件
- 方法區中常量引用的物件
- 本地方法棧中 JNI(即一般說的 Native 方法)引用的物件
1、虛擬機器棧(棧幀中的本地變量表)中引用的物件
此時的 s,即為 GC Root,當s置空時,localParameter 物件也斷掉了與 GC Root 的引用鏈,將被回收。
public class StackLocalParameter {
public StackLocalParameter(String name){}
}
public static void testGC(){
StackLocalParameter s = new StackLocalParameter("localParameter");
s = null;
}
2、方法區中類靜態屬性引用的物件
s 為 GC Root,s 置為 null,經過 GC 後,s 所指向的 properties 物件由於無法與 GC Root 建立關係被回收。
而 m 作為類的靜態屬性,也屬於 GC Root,parameter 物件依然與 GC root 建立著連線,所以此時 parameter 物件並不會被回收。
public class MethodAreaStaicProperties {
public static MethodAreaStaicProperties m;
public MethodAreaStaicProperties(String name){}
}
public static void testGC(){
MethodAreaStaicProperties s = new MethodAreaStaicProperties("properties");
s.m = new MethodAreaStaicProperties("parameter");
s = null;
}
3、方法區中常量引用的物件
m 即為方法區中的常量引用,也為 GC Root,s 置為 null 後,final 物件也不會因沒有與 GC Root 建立聯絡而被回收。
public class MethodAreaStaicProperties {
public static final MethodAreaStaicProperties m = MethodAreaStaicProperties("final");
public MethodAreaStaicProperties(String name){}
}
public static void testGC(){
MethodAreaStaicProperties s = new MethodAreaStaicProperties("staticProperties");
s = null;
}
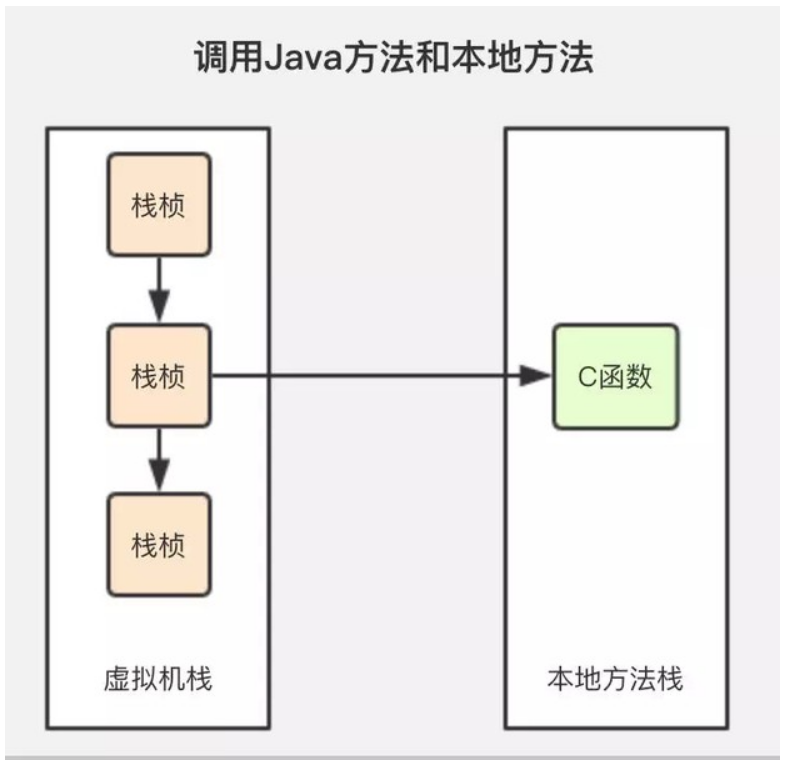
4、本地方法棧中引用的物件
任何 native 介面都會使用某種本地方法棧,實現的本地方法介面是使用 C 連線模型的話,那麼它的本地方法棧就是 C 棧。當執行緒呼叫 Java 方法時,虛擬機器會建立一個新的棧幀並壓入 Java 棧。然而當它呼叫的是本地方法時,虛擬機器會保持 Java 棧不變,不再線上程的 Java 棧中壓入新的幀,虛擬機器只是簡單地動態連線並直接呼叫指定的本地方法。
怎麼回收垃圾
在確定了哪些垃圾可以被回收後,垃圾收集器要做的事情就是開始進行垃圾回收,但是這裡面涉及到一個問題是:如何高效地進行垃圾回收。由於Java虛擬機器規範並沒有對如何實現垃圾收集器做出明確的規定,因此各個廠商的虛擬機器可以採用不同的方式來實現垃圾收集器,這裡我們討論幾種常見的垃圾收集演算法的核心思想。
標記 --- 清除演算法
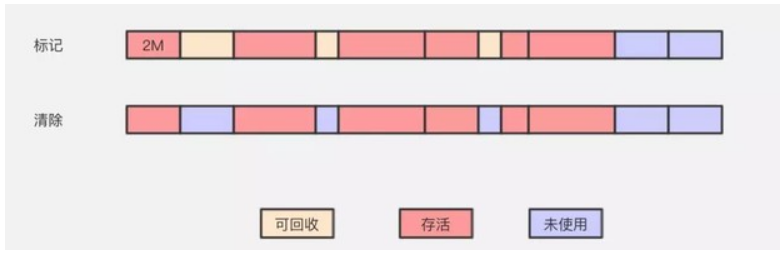
標記清除演算法(Mark-Sweep)是最基礎的一種垃圾回收演算法,它分為2部分,先把記憶體區域中的這些物件進行標記,哪些屬於可回收標記出來,然後把這些垃圾拎出來清理掉。就像上圖一樣,清理掉的垃圾就變成未使用的記憶體區域,等待被再次使用。
這邏輯再清晰不過了,並且也很好操作,但它存在一個很大的問題,那就是記憶體碎片。
上圖中等方塊的假設是 2M,小一些的是 1M,大一些的是 4M。等我們回收完,記憶體就會切成了很多段。我們知道開闢記憶體空間時,需要的是連續的記憶體區域,這時候我們需要一個 2M的記憶體區域,其中有2個 1M 是沒法用的。這樣就導致,其實我們本身還有這麼多的記憶體的,但卻用不了。
複製演算法
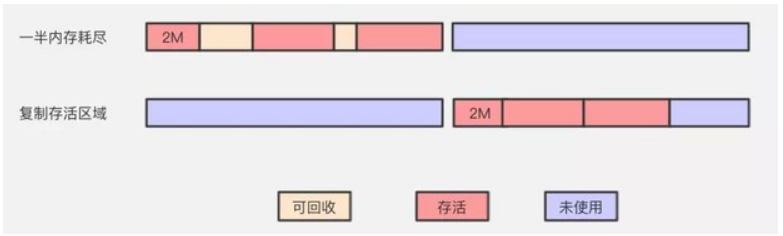
複製演算法(Copying)是在標記清除演算法上演化而來,解決標記清除演算法的記憶體碎片問題。它將可用記憶體按容量劃分為大小相等的兩塊,每次只使用其中的一塊。當這一塊的記憶體用完了,就將還存活著的物件複製到另外一塊上面,然後再把已使用過的記憶體空間一次清理掉。保證了記憶體的連續可用,記憶體分配時也就不用考慮記憶體碎片等複雜情況,邏輯清晰,執行高效。
上面的圖很清楚,也很明顯的暴露了另一個問題,合著我這140平的大三房,只能當70平米的小兩房來使?代價實在太高。
標記整理演算法
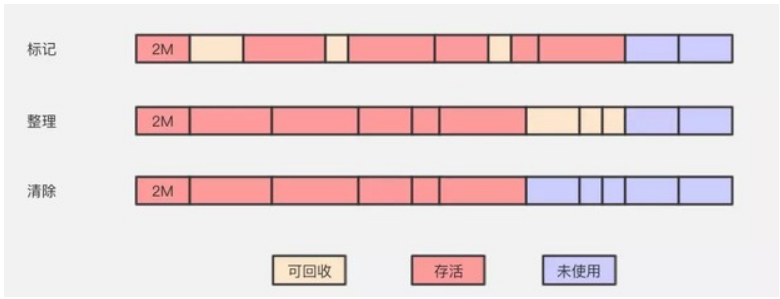
標記整理演算法(Mark-Compact)標記過程仍然與標記 --- 清除演算法一樣,但後續步驟不是直接對可回收物件進行清理,而是讓所有存活的物件都向一端移動,再清理掉端邊界以外的記憶體區域。
標記整理演算法一方面在標記-清除演算法上做了升級,解決了記憶體碎片的問題,也規避了複製演算法只能利用一半記憶體區域的弊端。看起來很美好,但從上圖可以看到,它對記憶體變動更頻繁,需要整理所有存活物件的引用地址,在效率上比複製演算法要差很多。
分代收集演算法分代收集演算法(Generational Collection)嚴格來說並不是一種思想或理論,而是融合上述3種基礎的演算法思想,而產生的針對不同情況所採用不同演算法的一套組合拳。物件存活週期的不同將記憶體劃分為幾塊。一般是把 Java 堆分為新生代和老年代,這樣就可以根據各個年代的特點採用最適當的收集演算法。在新生代中,每次垃圾收集時都發現有大批物件死去,只有少量存活,那就選用複製演算法,只需要付出少量存活物件的複製成本就可以完成收集。而老年代中因為物件存活率高、沒有額外空間對它進行分配擔保,就必須使用標記-清理或者標記 --- 整理演算法來進行回收。so,另一個問題來了,那記憶體區域到底被分為哪幾塊,每一塊又有什麼特別適合什麼演算法呢?
記憶體模型與回收策略
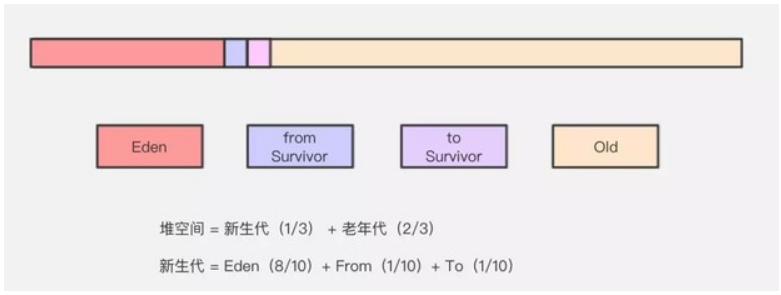
Java 堆(Java Heap)是JVM所管理的記憶體中最大的一塊,堆又是垃圾收集器管理的主要區域,這裡我們主要分析一下 Java 堆的結構。
Java 堆主要分為2個區域-年輕代與老年代,其中年輕代又分 Eden 區和 Survivor 區,其中 Survivor 區又分 From 和 To 2個區。可能這時候大家會有疑問,為什麼需要 Survivor 區,為什麼Survivor 還要分2個區。不著急,我們從頭到尾,看看物件到底是怎麼來的,而它又是怎麼沒的。
Eden 區
IBM 公司的專業研究表明,有將近98%的物件是朝生夕死,所以針對這一現狀,大多數情況下,物件會在新生代 Eden 區中進行分配,當 Eden 區沒有足夠空間進行分配時,虛擬機器會發起一次 Minor GC,Minor GC 相比 Major GC 更頻繁,回收速度也更快。
通過 Minor GC 之後,Eden 會被清空,Eden 區中絕大部分物件會被回收,而那些無需回收的存活物件,將會進到 Survivor 的 From 區(若 From 區不夠,則直接進入 Old 區)。
Survivor 區
Survivor 區相當於是 Eden 區和 Old 區的一個緩衝,類似於我們交通燈中的黃燈。Survivor 又分為2個區,一個是 From 區,一個是 To 區。每次執行 Minor GC,會將 Eden 區和 From 存活的物件放到 Survivor 的 To 區(如果 To 區不夠,則直接進入 Old 區)。
1、為啥需要?
不就是新生代到老年代麼,直接 Eden 到 Old 不好了嗎,為啥要這麼複雜。想想如果沒有 Survivor 區,Eden 區每進行一次 Minor GC,存活的物件就會被送到老年代,老年代很快就會被填滿。而有很多物件雖然一次 Minor GC 沒有消滅,但其實也並不會蹦躂多久,或許第二次,第三次就需要被清除。這時候移入老年區,很明顯不是一個明智的決定。
所以,Survivor 的存在意義就是減少被送到老年代的物件,進而減少 Major GC 的發生。Survivor 的預篩選保證,只有經歷16次 Minor GC 還能在新生代中存活的物件,才會被送到老年代。
2、為啥需要倆?
設定兩個 Survivor 區最大的好處就是解決記憶體碎片化。
我們先假設一下,Survivor 如果只有一個區域會怎樣。Minor GC 執行後,Eden 區被清空了,存活的物件放到了 Survivor 區,而之前 Survivor 區中的物件,可能也有一些是需要被清除的。問題來了,這時候我們怎麼清除它們?在這種場景下,我們只能標記清除,而我們知道標記清除最大的問題就是記憶體碎片,在新生代這種經常會消亡的區域,採用標記清除必然會讓記憶體產生嚴重的碎片化。因為 Survivor 有2個區域,所以每次 Minor GC,會將之前 Eden 區和 From 區中的存活物件複製到 To 區域。第二次 Minor GC 時,From 與 To 職責兌換,這時候會將 Eden 區和 To 區中的存活物件再複製到 From 區域,以此反覆。
這種機制最大的好處就是,整個過程中,永遠有一個 Survivor space 是空的,另一個非空的 Survivor space 是無碎片的。那麼,Survivor 為什麼不分更多塊呢?比方說分成三個、四個、五個?顯然,如果 Survivor 區再細分下去,每一塊的空間就會比較小,容易導致 Survivor 區滿,兩塊 Survivor 區可能是經過權衡之後的最佳方案。
Old 區
老年代佔據著2/3的堆記憶體空間,只有在 Major GC 的時候才會進行清理,每次 GC 都會觸發“Stop-The-World”。記憶體越大,STW 的時間也越長,所以記憶體也不僅僅是越大就越好。由於複製演算法在物件存活率較高的老年代會進行很多次的複製操作,效率很低,所以老年代這裡採用的是標記 --- 整理演算法。
除了上述所說,在記憶體擔保機制下,無法安置的物件會直接進到老年代,以下幾種情況也會進入老年代。
1、大物件
大物件指需要大量連續記憶體空間的物件,這部分物件不管是不是“朝生夕死”,都會直接進到老年代。這樣做主要是為了避免在 Eden 區及2個 Survivor 區之間發生大量的記憶體複製。當你的系統有非常多“朝生夕死”的大物件時,得注意了。
2、長期存活物件
虛擬機器給每個物件定義了一個物件年齡(Age)計數器。正常情況下物件會不斷的在 Survivor 的 From 區與 To 區之間移動,物件在 Survivor 區中沒經歷一次 Minor GC,年齡就增加1歲。當年齡增加到15歲時,這時候就會被轉移到老年代。當然,這裡的15,JVM 也支援進行特殊設定。
3、動態物件年齡
虛擬機器並不重視要求物件年齡必須到15歲,才會放入老年區,如果 Survivor 空間中相同年齡所有物件大小的綜合大於 Survivor 空間的一般,年齡大於等於該年齡的物件就可以直接進去老年區,無需等你“成年”。
這其實有點類似於負載均衡,輪詢是負載均衡的一種,保證每臺機器都分得同樣的請求。看似很均衡,但每臺機的硬體不通,健康狀況不同,我們還可以基於每臺機接受的請求數,或每臺機的響應時間等,來調整我們的負載均衡演算法。
原文連結
本文為雲棲社群原創內容,未經