
基於 MySQL Binlog 的 Elasticsearch 資料同步實踐 原
一、背景
隨著馬蜂窩的逐漸發展,我們的業務資料越來越多,單純使用 MySQL 已經不能滿足我們的資料查詢需求,例如對於商品、訂單等資料的多維度檢索。
使用 Elasticsearch 儲存業務資料可以很好的解決我們業務中的搜尋需求。而資料進行異構儲存後,隨之而來的就是資料同步的問題。
二、現有方法及問題
對於資料同步,我們目前的解決方案是建立資料中間表。把需要檢索的業務資料,統一放到一張MySQL 表中,這張中間表對應了業務需要的 Elasticsearch 索引,每一列對應索引中的一個Mapping 欄位。通過指令碼以 Crontab 的方式,讀取 MySQL 中間表中 UTime 大於上一次讀取時間的所有資料,即該段時間內的增量,寫入Elasticsearch。
所以,一旦業務邏輯中有相應欄位的資料變更,需要同時顧及 MySQL 中間表的變更;如果需要 Elasticsearch 中的資料即時性較高,還需要同時寫入 Elasticsearch。
隨著業務資料越來越多,MySQL 中間表的資料量越來越大。當需要在 Elasticsearch 的索引中新增 Mapping 欄位時,相應的 MySQL 中間表也需要新增列,在資料量龐大的表中,擴充套件列的耗時是難以忍受的。
而且 Elasticsearch 索引中的 Mapping 欄位隨著業務發展增多,需要由業務方增加相應的寫入 MySQL 中間表方法,這也帶來一部分開發成本。
三、方案設計
1. 整體思路
現有的一些開源資料同步工具,如阿里的 DataX 等,主要是基於查詢來獲取資料來源,這會存在如何確定增量(比如使用utime欄位解決等)和輪詢頻率的問題,而我們一些業務場景對於資料同步的實時性要求比較高。為了解決上述問題,我們提出了一種基於 MySQL Binlog 來進行 MySQL 資料同步到 Elasticsearch 的思路。Binlog 是 MySQL 通過 Replication 協議用來做主從資料同步的資料,所以它有我們需要寫入 Elasticsearch 的資料,並符合對資料同步時效性的要求。
使用 Binlog 資料同步 Elasticsearch,業務方就可以專注於業務邏輯對 MySQL 的操作,不用再關心資料向 Elasticsearch 同步的問題,減少了不必要的同步程式碼,避免了擴充套件中間表列的長耗時問題。
經過調研後,我們採用開源專案 go-mysql-elasticsearch 實現資料同步,並針對馬蜂窩技術棧和實際的業務環境進行了一些定製化開發。
2. 資料同步正確性保證
公司的所有表的 Binlog 資料屬於機密資料,不能直接獲取,為了滿足各業務線的使用需求,採用接入 Kafka 的形式提供給使用方,並且需要使用方申請相應的 Binlog 資料使用許可權。獲取使用許可權後,使用方以 Consumer Group 的形式讀取。
這種方式保證了 Binglog 資料的安全性,但是對保證資料同步的正確性帶來了挑戰。因此我們設計了一些機制,來保證資料來源的獲取有序、完整。
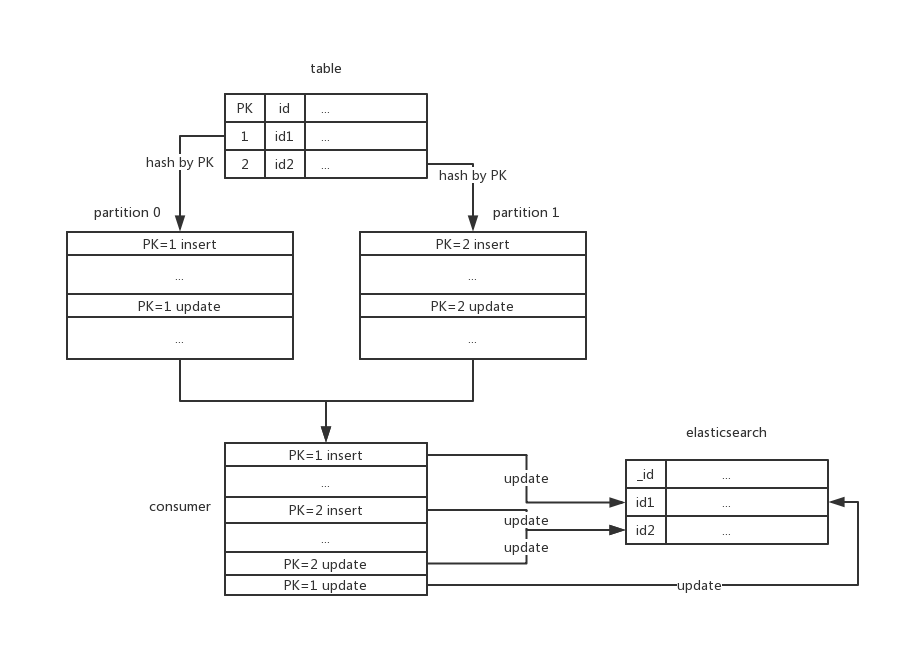
1). 順序性
通過 Kafka 獲取 Binlog 資料,首先需要保證獲取資料的順序性。嚴格說,Kafka 是無法保證全域性訊息有序的,只能區域性有序,所以無法保證所有 Binlog 資料都可以有序到達 Consumer。
但是每個 Partition 上的資料是有序的。為了可以按順序拿到每一行 MySQL 記錄的 Binglog,我們把每條 Binlog 按照其 Primary Key,Hash 到各個 Partition 上,保證同一條 MySQL 記錄的所有 Binlog 資料都發送到同一個 Partition。
如果是多 Consumer 的情況,一個 Partition 只會分配給一個 Consumer,同樣可以保證 Partition 內的資料可以有序的 Update 到 Elasticsearch 中。
2). 完整性
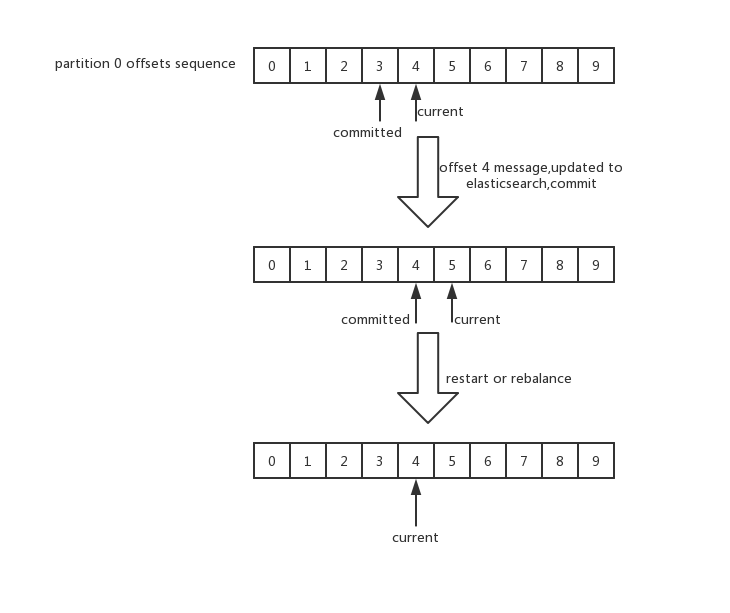
考慮到同步程式可能面臨各種正常或異常的退出,以及 Consumer 數量變化時的 Rebalance,我們需要保證在任何情況下不能丟失 Binlog 資料。
利用 Kafka 的 Offset 機制,在確認一條 Message 資料成功寫入 Elasticsearch 後,才 Commit 該條 Message 的 Offset,這樣就保證了資料的完整性。而對於資料同步的使用場景,在保證了資料順序性和完整性的情況下,重複消費是不會有影響的。
四、技術實現

1. 功能模組
配置解析模組
負責解析配置檔案(toml 或 json 格式),或在配置中心(Skipper)配置的 json 字串。包括 Kafka 叢集配置、Elasticsearch 地址配置、日誌記錄方式配置、MySQL 庫表及欄位與 Elasticsearch 的 Index 和 Mapping 對應關係配置等。
規則模組
規則模組決定了一條 Binlog 資料應該寫入到哪個 Elasticsearch 索引、文件_id 對應的 MySQL 欄位、Binlog 中的各個 MySQL 欄位與索引 Mapping 的對應關係和寫入型別等。
在本地化過程中,根據我們的業務場景,增加了對 MySQL 表各欄位的 where 條件判斷,來過濾掉不需要的 Binlog 資料。
Kafka 相關模組
該模組負責連線 Kafka 叢集,獲取 Binlog 資料。
在本地化過程中,該模組的大部分功能已經封裝成了一個通用的 Golang Kafka Consumer Client。包括 Dba Binlog 訂閱平臺要求的 SASL 認證,以及從指定時間點的 Offset 開始消費資料。
Binlog 資料解析模組
原專案中的 Binlog 資料解析針對的是原始的 Binlog 資料,包含了解析 Replication 協議的實現。在我們的使用場景中,Binlog 資料已經是由 canal 解析成的 json 字串,所以對該模組的功能進行了簡化。
binlog json字串示例

上面是一個簡化的 binlog json 字串,通過該條 binlog 的 database 和 table 可以命中一條配置規則,根據該配置規則,把 Data 中的 key-value 構造成一個與對應 Elasticsearch 索引相匹配的 key-value map,同時包括一些資料型別的轉換:

Elasticsearch相關模組
Binlog 資料解析模組生成的 key-value map,由該模組拼裝成請求_bulk 介面的 update payload,寫入 Elasticsearch。考慮到 MySQL 頻繁更新時對 Elasticsearch 的寫入壓力,key-value map 會暫存到一個 slice 中,每 200ms 或 slice 長度達到一定長度時(可以通過配置調整),才會呼叫 Elasticsearch 的_bulk 介面,寫入資料。
2. 定製化開發
1). 適應業務需求
upsert
業務中使用的索引資料可能是來自多個不同的表,同一個文件的資料來自不同表的時候,先到的資料是一條 index,後到的資料是一條 update,在我們無法控制先後順序時,需要實現 upsert 功能。在_bulk 引數中加入
{
"doc_as_upsert" : true
}

Filter
實際業務場景中,可能業務需要的資料只是某張表中的部分資料,比如用 type 欄位標識該條資料來源,只需要把 type=1或2的資料同步到 Elasticsearch 中。我們擴充套件了規則配置,可以支援對 Binlog 指定欄位的過濾需求,類似:
select * from sometable where type in (1,2)
2)快速增量
資料同步一般分為全量和增量。接入一個業務時,首先需要把業務現有的歷史 MySQL 資料匯入到 Elasticsearch 中,這部分為全量同步。在全量同步過程中以及後續增加的資料為增量資料。
在全量資料同步完成後,如果從最舊開始消費 Kafka,佇列資料量很大的情況下,需要很長時間增量資料才能追上當前進度。為了更快的拿到所需的增量 Binlog,在 Consumer Group 消費 Kafka 之前,先獲取各個 Topic 的 Partition 在指定時間的 offset 值,並 commit 這些 offset,這樣在 Consumer Group 連線 Kafka 叢集時,會從剛才提交的 offset 開始消費,可以立即拿到所需的增量 Binlog。
3). 微服務和配置中心
專案使用馬蜂窩微服務部署,為新接入業務提供了快速上線支援,並且在業務 Binlog 資料突增時可以方便快速的擴容 Consumer。
馬蜂窩配置中心支援了各個接入業務的配置管理,相比於開源專案中的 toml 格式配置檔案,使用配置中心可以更方便的管理不同業務不同環境的配置。
五、日誌與監控

從上圖中可以看出,訂單各個表的資料同步延時平均在 1s 左右。把延時資料接入 ElastAlert,在延時資料過多時傳送報警通知。
另一個監控指標是心跳檢測,單獨建立一張獨立於業務的表,crontab 指令碼每分鐘修改一次該表,同時檢查上一次修改是否同步到了指定的索引,如果沒有,則傳送報警通知。該心跳檢測,監控了整個流程上的 Kafka、微服務和 ES,任何一個會導致資料不同步的環節出問題,都會第一個接到通知。
六、結語
目前接入的最重要業務方是電商的訂單索引,資料同步延時穩定在 1s 左右。這次的開源專案本地化實踐,希望能為一些有 Elasticsearch 資料同步需求的業務場景提供幫助。
本文作者:張坤,馬蜂窩電商研發團隊度假業務高階研發工程師。
(馬蜂窩技術原創內容,轉載請保留出處及文末二維碼,謝謝)
相關推薦
基於 MySQL Binlog 的 Elasticsearch 資料同步實踐 原
一、背景 隨著馬蜂窩的逐漸發展,我們的業務資料越來越多,單純使用 MySQL 已經不能滿足我們的資料查詢需求,例如對於商品、訂單等資料的多維度檢索。 使用 Elasticsearch 儲存業務資料可以很好的解決我們業務中的搜尋需求。而資料進行異構儲存後,隨之而來的就是資料同步的問題。 二、現有方法及問題
基於MYSQL的Binlog增量資料同步服務
(by 劉延允) 系統工作原理 基於MYSQL日誌增量資料同步原理: 1、DBAsync偽裝自己為mysql slave,向mysql master傳送dump協議 2、mysql mast
基於 MySQL 的數據庫實踐(更名運算)
AI 方法 希望 log Go 最低工資 HERE 笛卡爾 clas 考慮下面的查詢查詢。 select name, course_id from instructor, teaches where instructor.ID = teaches.ID; 它的結果是一個具有
基於 MySQL 的數據庫實踐(擴展運算)
之間 art history 上進 簡化 source 希望 AC 顯示 select 中的通配符 星號 * 可以用在 select 子句中表示所有的屬性。 mysql> select instructor.* -> from instructor, t
logstash-input-jdbc實現mysql 與elasticsearch實時同步
實現MySQL資料庫中資料到Elasticsearch的實時同步: 首先需要做好的準備工作: 1、伺服器上安裝好elasticsearch和logstash 2、安裝logstash-input-jdbc外掛,但從logstash5.X開始,已經至少集成了logstash-input-j
elasticsearch資料同步
elasticsearch 對於資料搜尋效率較快 當資料量較大的情況下 後臺由於sql或者其他因素直接從資料庫獲取資料比較慢 於是這次給大家做一下資料庫資料同步 一原理對比 傳統查詢 ES將資料同步 使用ES 可以將查詢效率進行提高 二同步資料 資料庫準備兩張表 stu tea 三同
scrapy框架 基於mysql資料庫儲存資料方法、案例
流程思路 將解析資料存到items物件 使用yield 將items交給管道檔案處理 在管道檔案pipelines編寫程式碼儲存到資料庫 在setting配置檔案開啟管道 案例 items中 按照格式定義欄位 import s
mysql database 單向資料同步:otter
[[email protected] ~]# wget https://raw.github.com/alibaba/otter/master/manager/deployer/src/main/resources/sql/otter-manager-schema.
logstash-input-jdbc實現mysql 與elasticsearch實時同步深入詳解
引言: elasticsearch 的出現使得我們的儲存、檢索資料更快捷、方便。但很多情況下,我們的需求是:現在的資料儲存在mysql、oracle等關係型傳統資料庫中,如何儘量不改變原有資料庫表結構,將這些資料的insert,update,delete操作結果實時同步到elasticsearch(
基於canal的實時資料同步
適用場景 使用canal做資料備份而不用mysql自帶的主從備份的場景主要為: 跨資料庫的資料備份,例如mysql => oracle 資料異構,即對同一份資料做不同的分庫分表查詢。例如賣家和買家各自分庫索引 maven <dependen
基於Webservice API 的資料同步的reset的實現
1、資料庫A主鍵增長值2 資料庫B主鍵增長值2 2、設計資料庫A的公共API 3、呼叫的實現 SqlConnection myconn = new SqlConnection("server=.;databa
多臺伺服器之間如何讓sqlserver,mysql資料庫進行資料同步?
伺服器儲存視訊,頻寬不夠用,想用多臺伺服器,如何讓所有伺服器之間視訊實時同步,可以用什麼軟體!當企業租用伺服器,但是在資料同步的時候,又有著嚴格的要求,要求資料達到一致,在科技發達的今天,這又該如何做到了?下面天下資料為大家介紹多臺伺服器之間讓資料同步的方法! 1、採用高可用sureHA軟體映象型,一臺
21.go-mysql-elasticsearch實現mysql 與elasticsearch實時同步(ES與關係型資料庫同步)
引言:go-mysql-elasticsearch 是國內作者開發的一款外掛。測試表明:該外掛優點:能實現同步增、刪、改、查操作。不足之處(待完善的地方): 1、仍處理開發、相對不穩定階段; 2、沒有日誌,不便於排查問題及檢視同步結果。 本文深入詳解了外掛的安裝、使用、增刪改
基於MySQL Adapter完成資料的增刪和修改操作
using System; using System.Collections.Generic; using System.Linq; using System.Text; using MySql.Data; using MySql.Data.MySqlClient; us
go-mysql-elasticsearch實現mysql 與elasticsearch實時同步深入詳解
引言: go-mysql-elasticsearch 是國內作者開發的一款外掛。測試表明:該外掛優點:能實現同步增、刪、改、查操作。不足之處(待完善的地方): 1、仍處理開發、相對不穩定階段; 2、沒有日誌,不便於排查問題及檢視同步結果。 本文深入詳解了
基於檔案的離線資料同步方案
產品此前的資料備份方案,存在不少問題,所以需要設計一個新的方案。本文總結一下新舊方案的優劣 首先APP是一個支援離線的應用。本地資料儲存在sqlite,在離線環境下,在本地資料庫裡讀寫記錄,在有網路的
27.logstash-output-mongodb實現Mysql到Mongodb資料同步(ES與非關係型資料庫同步)
本文主要講解如何通過logstash-output-mongodb外掛實現Mysql與Mongodb資料的同步。源資料儲存在Mysql,目標資料庫為非關係型資料庫Mongodb。0、前提1)已經安裝好源資料庫:Mysql; 2)已經安裝好目的資料庫:Mongodb; 3)已經
Redis 學習筆記四 Mysql 與Redis的同步實踐
一、測試環境在Ubuntu kylin 14.04 64bit 已經安裝Mysql、Redis、php、lib_mysqludf_json.so、Gearman。 點選這裡檢視測試資料庫及表參考 本文也有些基本操作,在之前文章裡有介紹。 1、安裝
通過WEB伺服器訪問MYSQL,並且資料同步到android SQLite資料庫
2、連線資料庫。 3、訪問資料庫 過程2、3 具體步驟: 1、在Myeclipse下新建一個web專案,為了好統一管理在WEB-INF下建一個web.xml用來載入伺服器啟動時的配置資訊。這個檔案是由大量的<servlet></servle
使用 mysql binlog 恢復資料
【mysqlbinlog】 從binlog裡面摘出需要恢復執行的SQL mysqlbinlog --start-position="$startpos" --stop-datetime="$stoptime" --database="$db" "$binl