
一步步動手實現簡單的執行緒池 —— 生動有趣解析 Java 執行緒池原始碼
零、引子
某天小奈與小夥伴肥宅埋的日常技(cai)術(ji)研(hu)討(zhuo)中聊起了執行緒池。

自詡十分熟悉併發程式設計的小奈馬上侃侃而談,“執行緒池幫助我們管理執行緒,減少執行緒頻繁建立與銷燬資源損耗.....balabla”。小奈說起這些,周圍的人便都看著他笑。
肥宅埋叫道,“小奈,那你可知道執行緒池是怎麼實現的嗎?”,小奈沒有回答,對櫃裡說,“溫兩碗酒,要一碟茴香豆。”便排出九文大錢。
肥宅埋又故意的高聲嚷道,“你一定沒看過執行緒池的原始碼!”
小奈睜大眼睛說,“你怎麼這樣憑空汙人清白……”。
“什麼清白?我前天親眼見你手裡捧著《Java併發程式設計實戰》,剛看完不久就出來吹水。”
小奈便漲紅了臉,額上的青筋條條綻出,爭辯道,“剛看完的知識不能算吹……吹水!……讀書人的事,能算吹麼?”接連便是難懂的話,什麼“執行緒池的四種建立方式”,什麼“計算密集型和IO密集型執行緒池大小”之類,引得眾人都鬨笑起來:店內外充滿了快活的空氣。
“那你看過執行緒池的原始碼嘛?”小奈不落下風,不料這一句話也將肥宅埋嗆住。“既然大家都沒看過,那就按照自己的理解來實現一個吧。”這個提議一出馬上得到了肥宅埋的贊同。
小奈順勢就地拿出了電腦,開啟 IDE,準備開始編寫執行緒池。
一、執行緒的複用
“首當其衝的問題就是,如何複用執行緒。”肥宅埋直戳本質,雖然肥宅埋知道要去達到複用執行緒的複用,但是這如何實現卻是傷了腦筋。她只好以退為進,先丟擲自己的見解,看對方如何應對。
小奈也考慮到了這個問題,不過這個難不倒自詡熟悉併發程式設計的小奈。小奈冷靜分析,稍加思索,嚶......第一版執行緒池就出來了:

/** * Created by Anur IjuoKaruKas on 2019/7/16 */ public class ThreadPoolExecutor { private final BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(); private final Runnable runnable = () -> { try { while (true) { Runnable take = workQueue.poll(); if (take == null) { Thread.sleep(200); } else { take.run(); } } } catch (InterruptedException e) { e.printStackTrace(); } }; public ThreadPoolExecutor() { new Thread(runnable).start(); } public void execute(Runnable command) { workQueue.offer(command); } }
肥宅埋過了一眼,很快就發現其中玄妙之處:在小奈的 ThreadPoolExecutor 中,定製了一套 runnable 流程,負責不斷從 workQueue 這個佇列中拉取由 #execute 方法提交過來的任務,並執行其 run() 方法。這樣,無論提交過來多少個任務,始終都是這個執行緒池內建的執行緒在執行任務。當獲取不到任務的時候,執行緒池會自己進入休眠狀態。
二、worker執行緒的自動建立、銷燬以及最大 worker 數
“雖然這達到了執行緒複用,但是你的這個執行緒完全沒辦法自動建立和銷燬啊?甚至它的執行緒池數量都是不可控制的。”肥宅埋雖然感嘆於對方可以這麼快實現執行緒複用,但還是持續展開攻勢。
“既然要實現執行緒池可控,最直截了當的想法便是將方才的那套 runnable 流程封裝成一個物件,我們只需控制這個物件的建立、銷燬、以及複用即可。”作為一隻長期浸泡在 OOP 思維中的程式媛,這種問題難不倒小奈。她很快就寫出了一個內部類,叫做 Worker,其中 #runWorker(this); 就是剛才那個 runnable 流程,負責不斷從佇列中獲取任務,並呼叫它的 #run() 方法。
private final class Worker implements Runnable {
final Thread thread;
Runnable firstTask;
Worker(Runnable firstTask) {
this.firstTask = firstTask;
this.thread = threadFactory.newThread(this);
}
@Override
public void run() {
runWorker(this);
}
}
小奈為後續將要完成的 worker 執行緒數量控制打下了基石:ThreadPoolExecutor 中增加了一個雜湊集,用於存放 worker,增加了一個 ThreadFactory,供使用者定製化 worker 執行緒的建立。
其中比較核心的方法叫做 #addWorker(),負責建立並初始化 worker 執行緒,並將其納入雜湊集中管理。當然,這個執行緒池還無法自動建立,不過已經可以自動銷燬了。可以看到,在拉取不到任務時,#getTask() 則返回空,會跳出 #runWorker() 的 while 迴圈,之後呼叫 #processWorkerExit();,將 worker 執行緒從雜湊集中移除。
/**
* Created by Anur IjuoKaruKas on 2019/7/16
*/
public class ThreadPoolExecutor {
private final HashSet<Worker> workers = new HashSet<>();
private volatile ThreadFactory threadFactory;
private final BlockingQueue<Runnable> workQueue;
public ThreadPoolExecutor(BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) {
this.threadFactory = threadFactory;
this.workQueue = workQueue;
}
public void execute(Runnable command) {
workQueue.offer(command);
}
/**
* 新建一個 worker 執行緒、啟動並納入 workers
*/
private boolean addWorker(Runnable firstTask) {
Worker w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
workers.add(w);
t.start();
}
return true;
}
/**
* worker 執行緒池不斷從 workQueue 中拉取 task 進行消費
*/
private void runWorker(Worker w) {
Runnable task = w.firstTask;
w.firstTask = null;
while (task != null || (task = getTask()) != null) {
task.run();
}
processWorkerExit(w);
}
/**
* 當執行緒執行完畢之前,將其從 workers 中移除
*/
private void processWorkerExit(Worker w) {
workers.remove(w);
}
private Runnable getTask() {
return workQueue.poll();
}
}
看到這裡,肥宅埋已經能預測到接下來的思路了。

執行緒池需要加入一個變數 maximumPoolSize,以防無限建立執行緒,每次進行 #addWorker() 時,需要判斷一下是否可以繼續新增 worker,如果可以,則新增新的 worker,否則將任務丟入佇列:
#addWorker() 中加入拒絕的邏輯,確保不能無限建立 worker。
再修改一下 #execute() 方法,優先建立 worker,如果建立 worker 失敗( workers.size() >= maximumPoolSize),則直接將任務丟入佇列。
public void execute(Runnable command) {
if (addWorker(command)) {
return;
}
workQueue.offer(command);
}
/**
* 新建一個 worker 執行緒、啟動並納入 workers
*/
private boolean addWorker(Runnable firstTask) {
int ws = workers.size();
if (ws >= maximumPoolSize) {
return false;
}
Worker w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
workers.add(w);
t.start();
}
return true;
}
三、核心執行緒、最大執行緒與 keepAliveTime
已經寫到這裡小奈可謂是趾高氣揚,彷彿實現一個執行緒池已經不在話下。

“這樣貌似有點問題啊?雖然說你已經實現了執行緒的動態建立與銷燬,但在任務沒有那麼緊湊的情況下,基本是每個任務都進來都需要建立一次執行緒,再銷燬一次執行緒,說好的複用到哪裡去了?”肥宅埋給了膨脹的小奈當頭一棒。
“咳咳......嘛,銷燬的時候做一下判斷就可以了,我們加入一個新的變數,叫做 keepAliveTime,當拿不到任務的時候,就進行阻塞休眠,比如 20ms,每次對 keepAliveTime 減 20ms,直到小於等於 0 ,再銷燬執行緒。”小奈反應迅速,很快給出了答案,並準備動手對執行緒池進行改動。
肥宅埋嘆了一口氣,“我看你是被膨脹矇蔽了雙眼,既然我們已經使用了阻塞佇列,那麼就可以充分利用阻塞佇列的特性!阻塞佇列中內建了一個顯式鎖,利用鎖的 condition 物件,使用它的 #awaitNanos() 與 #notify() 方法,就可以直接精準地實現執行緒排程了。”畢竟肥宅埋也是一隻學霸,聽到小奈的想法後提出了更具有建設性的設計。
小奈也很快反應過來,阻塞佇列有一個 #poll() 方法,底層是藉助 condition 物件封裝的 LockSupport.parkNanos(this, nanosTimeout); 來實現的,會阻塞直到有新的元素加入,當有新的元素加入,這個 condition 就會被喚醒,來實現 當呼叫阻塞佇列的 #poll() 時,如果阻塞佇列為空,會進行一段時間的休眠,直到被喚醒,或者休眠超時。
肥宅埋一手接管了改造執行緒池的大權,馬上大刀闊斧地改了起來。
改動十分簡單,原先的 #getTask() 是直接呼叫阻塞佇列的 #take() 方法,如果佇列為空,則直接返回,只要將其改為 #poll 方法即可。
/**
* 當 runWorker 一定時間內獲取不到任務時,就會 processWorkerExit 銷燬
*/
private Runnable getTask() {
boolean timedOut = false;
while (true) {
try {
if (timedOut) {
return null;
}
Runnable r = workQueue.poll(keepAliveTime, unit);
if (r != null) {
return r;
} else {
timedOut = true;
}
} catch (InterruptedException e) {
timedOut = false;
}
}
}
“一般來說,我們的任務提交都不會太過於均勻,如果我們平常不需要那麼多執行緒來消費,但又想避免任務一直被堆積導致某些任務遲遲不被消費,就需要引入**核心執行緒 corePoolSize ** 與 **最大執行緒 maximumPoolSize ** 的概念。”肥宅埋想到了一個簡單的可以優化的點,頭頭是道地分析道:“我們可以不用做那麼複雜的動態 worker 消費池,最簡單的,如果我們的阻塞佇列滿了,就繼續建立更多的執行緒池,這樣,堆積的任務能比以往更快速的降下來。”
說起來好像複雜,實際上程式碼十分簡單。小奈看見肥宅埋修改了 #addWorker() 方法,增加了一個引數 core,其作用只有一個,如果是核心執行緒,則建立時,數量必須小於等於 corePoolSize,否則數量必須小於等於 maximumPoolSize。
另外, #execute() 方法的改動也十分簡單,前面的改動不大,主要是,當任務 #offer() 失敗後,建立非核心 worker 執行緒。
/**
* 優先建立核心執行緒,核心執行緒滿了以後,則優先將任務放入佇列
*
* 佇列滿了以後,則啟用非核心執行緒池,以防任務堆積
*/
public void execute(Runnable command) {
if (getPoolSize() < corePoolSize) {
if (addWorker(command, true)) {
return;
}
}
if (!workQueue.offer(command)) {
addWorker(command, false);
}
}
/**
* 新建一個 worker 執行緒、啟動並納入 workers
*/
private boolean addWorker(Runnable firstTask, boolean core) {
int ws = workers.size();
if (ws >= (core ? corePoolSize : maximumPoolSize)) {
return false;
}
Worker w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
workers.add(w);
t.start();
}
return true;
}
四、拒絕策略
“現在這個版本的執行緒池看起來真是有模有樣呢 ~ 可以動態建立與銷燬執行緒,執行緒也能複用,還可以動態增加更多的執行緒來消費堆積的執行緒!” 肥宅埋滿意地看著兩人的傑作,“其實我還發現有個地方不太友好,在推送任務時,呼叫方可能並不知道自己的任務是否失敗。”
“這個簡單鴨,只需要在呼叫 #execute() 時返回 flase 來代表新增失敗,或者丟擲對應的異常即可。”小奈給出了很直觀的設計。
“這確實不失為一個好方法,但是對於呼叫方來說,如果所有使用執行緒池的地方都需要去做這個判斷,那豈不是太麻煩了!”肥宅埋對方案進行了補充:“這個是面向切面程式設計的一種思想,我們可以提供一個如何處理這些佇列已經放不下,且無法建立更多消費執行緒的切面入口,就叫它 AbortPolicy 吧!”
肥宅埋修改了一下 #execute() 方法,如果在建立非核心執行緒池的時候失敗,就直接將任務拒絕掉。
/**
* 優先建立核心執行緒,核心執行緒滿了以後,則優先將任務放入佇列
*
* 佇列滿了以後,則啟用非核心執行緒池,以防任務堆積
*
* 如果非核心執行緒池建立失敗,則拒絕這個任務
*/
public void execute(Runnable command) {
if (getPoolSize() < corePoolSize) {
if (addWorker(command, true)) {
return;
}
}
if (!workQueue.offer(command)) {
if (!addWorker(command, false)) {
reject(command);
}
}
}
如何去拒絕任務,交給呼叫者去實現,#reject() 的實現非常簡單,就是呼叫一下 BiConsumer,這個可以供呼叫方自由定製。
private void reject(Runnable command) {
abortPolicy.accept(command, this);
}
五、執行執行緒池
小奈與肥宅埋已經完成了她們的執行緒池,現在需要測試一下執行緒池是否可以正常使用,比較細心的肥宅埋寫了測試用例如下:
核心執行緒數為5,最大執行緒數為10,緊接著每個執行緒在拉取不到任務時會存活一分鐘,有一個長度為 5 的併發阻塞佇列,採用預設的 ThreadFactory,最後,使用了 DiscardPolicy,當任務被拒絕後,直接丟棄任務,並列印日誌。
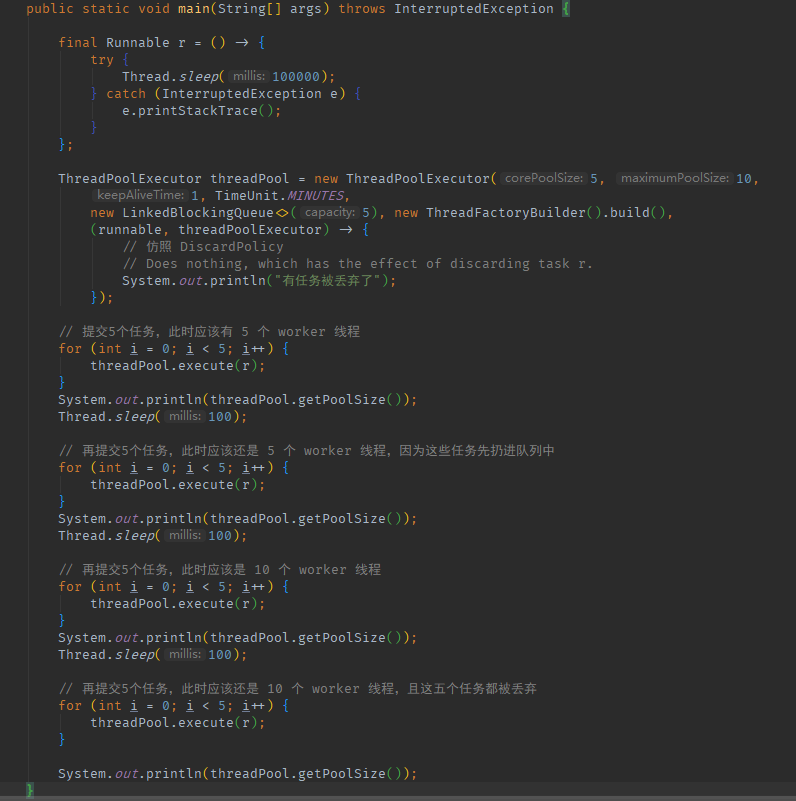
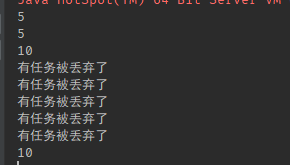
她們運行了程式碼,日誌列印如下。完全符合預期,在阻塞佇列還未裝滿之前,只有 5 個核心執行緒在消費任務,當阻塞佇列滿了以後,會逐步建立更多的執行緒,而當無法建立更多執行緒後,則觸發丟棄策略。
額外的話:
- 執行緒池是仿照
JDK執行緒池主要邏輯所抽出的簡化版本,直接拿去用是有問題的,真正的執行緒池在管理worker時,使用了CAS技術來保證不會在建立時出現併發問題,本文中的執行緒池僅供學習與參考。 - 把文章寫成這個鬼樣子是一個小嚐試,其實博主還挺喜歡類似程式設計師小灰的那種講解模式的。
參考資料:JDK1.8
最後歡迎大佬或者萌新來交流群一起探討、學習 ~

上述執行緒池程式碼 git :