
DM 原始碼閱讀系列文章(九)shard DDL 與 checkpoint 機制的實現
作者:張學程
本文為 DM 原始碼閱讀系列文章的第九篇,在 上篇文章 中我們詳細介紹了 DM 對 online schema change 方案的同步支援,對 online schema change 同步方案以及實現細節等邏輯進行了分析。
在本篇文章中,我們將對 shard DDL 同步機制以及 checkpoint 機制等進行詳細的介紹,內容包括 shard group 的定義、shard DDL 的同步協調處理流程、checkpoint 機制以及與之相關的 safe mode 機制。
shard DDL 機制的實現
DM 中通過 庫表路由與列值轉換 功能,實現了對分庫分表合併場景下 DML 的同步支援。但當需要同步的各分表存在 DDL 變更時,還需要對 DDL 的同步進行更多額外的處理。有關分表合併時 shard DDL 同步需要處理的問題以及 DM 中的同步支援原理,請先閱讀
shard group
在 這篇文章 中,我們介紹了 DM 在處理 shard DDL 同步時引入了兩級 shard group 的概念,即用於執行分表合併同步任務的各 DM-worker 組成的 shard group、每個 DM-worker 內需要進行合表同步的各上游分表組成的 shard group。
DM-worker 組成的 shard group
由 DM-worker 組成的 shard group 是由叢集部署拓撲及同步任務配置決定的,即任務配置檔案中定義的需要進行合表同步的所有上游 MySQL 例項對應的所有 DM-worker 例項即組成了一個 shard group。為了表示同步過程中的相關動態資訊,DM-master 內部引入了兩個概念:
-
Lock:對於每組需要進行合併的表,其中每一條需要進行同步協調的 shard DDL,由一個 Lock 例項進行表示;每個 Lock 例項在有 shard DDL 需要協調同步時被建立、在協調同步完成後被銷燬;在 dmctl 中使用 show-ddl-locks 命令檢視到的每一個 Lock 資訊即對應一個該例項
-
LockKeeper:維護所有的 Lock 例項資訊並提供相關的操作介面
Lock 中各主要成員變數的作用如下:
| 成員變數 | 作用 |
|---|---|
ID | 用於標識一個 lock,由同步任務名、合併後同步到的目標表對應的 schema 及 table 名構造得到 |
Task | 該 lock 所對應的同步任務名 |
Owner | 該 lock 的 owner 對應的 ID,即第一個向 DM-master 上報 shard DDL 資訊的 DM-worker 對應的 ID |
remain | 尚未上報待同步 shard DDL 資訊的 DM-worker 數量 |
ready | 標識各 DM-worker 是否已上報過待同步 shard DDL 資訊 |
ddls | 該 lock 對應的需要進行協調同步到下游的 DDL statements(shard DDL 通過 TiDB parser 轉換後可能會被分拆為多條 DDL) |
DM-worker 內分表組成的 shard group
每個 DM-worker 內的 shard group 是由對應上游 MySQL 例項內分表及同步任務配置決定的,即任務配置檔案中定義的對應 MySQL 例項內需要進行合併同步到同一個下游目標表的所有分表組成一個 shard group。在 DM-worker 內部,我們維護了下面兩個物件:
-
ShardingGroup:對於每一組需要進行合併的表,由一個 ShardingGroup 例項進行表示;每個 ShardGroup 例項在同步任務啟動階段被建立,在任務停止時被銷燬
-
ShardingGroupKeeper:維護所有的 ShardingGroup 例項資訊並提供相關的操作介面
ShardingGroup 中各主要成員變數的作用如下:
| 成員變數 | 作用 |
|---|---|
sourceID | 當前 DM-worker 對應於上游 MySQL 的 source-id |
remain | 尚未收到對應 shard DDL 的分表數量 |
sources | 標識是否已收到各上游分表對應的 shard DDL 資訊 |
meta | 當前 shard group 內各分表收到的 DDL 相關資訊 |
shard DDL 同步流程
對於兩級 shard group,DM 內部在依次完成兩個級別的 相應的 shard DDL 同步協調。
-
對於 DM-worker 內由各分表組成的 shard group,其 shard DDL 的同步在對應 DM-worker 內部進行協調
-
對於由各 DM-worker 組成的 shard group,其 shard DDL 的同步由 DM-master 進行協調
DM-worker 間 shard DDL 協調流程
我們基於在 這篇文章 中展示過的僅包含兩個 DM-worker 的 shard DDL 協調流程示例(如下圖)來了解 DM 內部的具體實現。
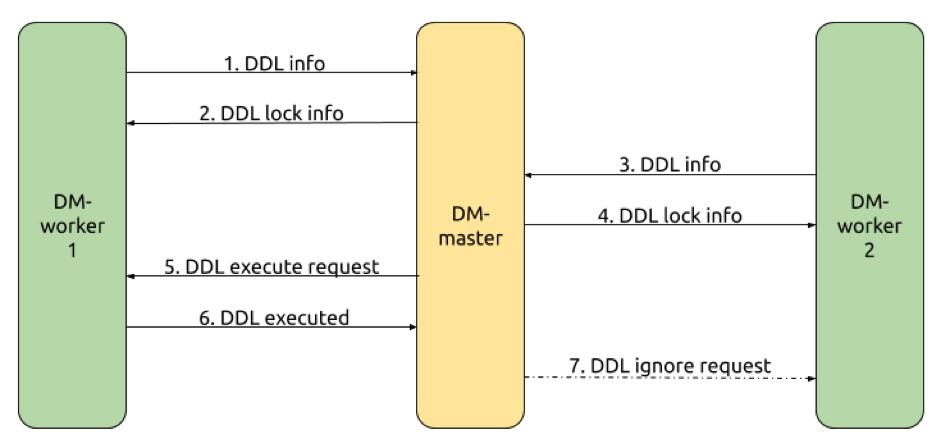
-
DM-worker-1 將 shard DDL 資訊傳送給 DM-master
a. 當 DM-worker-1 內部 shard DDL 協調完成時,DM-worker-1 將對應的 shard DDL 資訊儲存在 channel 中供 DM-master 通過 gRPC 獲取
b. DM-master 在 fetchWorkerDDLInfo 方法中以 gRPC streaming 的方式讀取到 DM-worker-1 的 shard DDL 資訊
c. DM-master 呼叫 ShardingGroupKeeper 的 TrySync 方法建立對應的 lock 資訊,並在 lock 中標記已收到 DM-worker-1 的 shard DDL 資訊
-
DM-master 將 lock 資訊發回給 DM-worker-1
a. DM-master 以 gRPC streaming 的方式將 lock 資訊傳送給 DM-worker-1
b. DM-worker-1 將來自 DM-master 的 lock 資訊儲存在記憶體中用於在 DM-master 請求 DM-worker 執行/跳過 shard DDL 時進行驗證
-
DM-worker-2 將 shard DDL 資訊傳送給 DM-master(流程與 step.1 一致)
-
DM-master 將 lock 資訊發回給 DM-worker-2(流程與 step.2 一致)
-
DM-master 協調 DM-worker-1 向下遊同步 shard DDL
a. DM-master 根據 step.1 與 step.3 時收到的 shard DDL 資訊判定已經收到 shard group 內所有 DM-worker 的 shard DDL 資訊
b. DM-master 在 resolveDDLLock 方法中向 DM-worker-1 傳送向下遊同步 shard DDL 的請求(Exec 引數為 true)
-
DM-worker-1 向下遊同步 shard DDL
a. DM-worker-1 接收到來自 DM-master 的向下遊執行 shard DDL 的請求
b. DM-worker-1 構造 DDL job 並新增到 DDL 執行佇列中
c. DM-worker-1 將 shard DDL 執行結果儲存在 channel 中供 DM-master 通過 gRPC 獲取
-
DM-worker-2 忽略向下遊同步 shard DDL
a. DM-master 獲取 DM-worker-1 向下遊同步 shard DDL 的結果判斷得知 DM-worker-1 同步 shard DDL 成功
b. DM-master 向 DM-worker-2 傳送忽略向下遊同步 shard DDL 的請求(Exec 引數為 false)
DM-worker 內 shard DDL 同步流程
我們基於在 實現原理文章 中展示過的一個 DM-worker 內僅包含兩個分表 (table_1,table_2) 的 shard DDL(僅一條 DDL)協調處理流程示例來了解 DM 內部的具體實現。
-
DM-worker 收到
table_1的 DDLa. 根據 DDL 及 binlog event position 等資訊更新對應的 shard group
b. 確保 binlog replication 過程已進入 safe mode(後文介紹 checkpoint 機制時會再介紹 safe mode)
c. 更新
table_1的 checkpoint(後文會詳細介紹 checkpoint 機制) -
DM-worker 繼續解析後續的 binlog event
根據 step.1 時返回的更新後的 shard group 資訊得知還未收到 shard group 內所有分表對應的 shard DDL,不向下游同步 shard DDL 並繼續後續解析
-
忽略
table_1的 DML 並同步table_2的 DML由於
table_1已收到 shard DDL 但 shard DDL 自身還未完成同步,忽略對table_1相關 DML 的同步 -
DM-worker 收到
table_2的 DDL(流程與 step.1 一致) -
DM-worker 向下遊同步 shard DDL
a. 根據 step.4 時返回的更新後的 shard group 資訊得知已經收到 shard group 內所有分表對應的 shard DDL
b. 嘗試讓 binlog replication 過程退出 safe mode
c. 將當前 shard DDL 同步完成後 re-sync 時重新同步 step.3 忽略的 DML 所需的相關資訊儲存在 channel 中
d. 等待已分發的所有 DML 同步完成(確保等待併發同步的 DML 都同步到下游後再對下游 schema 進行變更)
e. 將 shard DDL 相關資訊儲存在 channel 中以進行 DM-worker 間的同步(見前文 DM-worker 間 shard DDL 協調流程)
f. 待 DM-worker 間協調完成後,向下遊同步 shard DDL
-
將 binlog 的解析位置重定向回 step.1 對應 DDL 後的 binlog event position 進入 re-sync 階段
根據 step.5 中儲存的資訊,將 binlog 的解析位置重定向回 step.1 對應的 DDL 後的 binlog event position
-
重新解析 binlog event
-
對於不同表的 DML 做不同的處理
a. 對於
table_1在 step.3 時忽略的 DML,解析後向下游同步 -
解析到達 step.4 時 DDL 對應的 binlog position,re-sync 階段完成
-
繼續進行後續的 DDL 與 DML 的同步
需要注意的是,在上述 step.1 與 step.4 之間,如果有收到 table_1 的其他 DDL,則對於該 shard group,需要協調同步由一組 shard DDL 組成的 ShardingSequence。當在 step.9 對其中某一條 shard DDL 同步完成後,如果有更多的未同步的 shard DDL 需要協調處理,則會重定向到待處理的下一條 shard DDL 對應的位置重新開始解析 binlog event。
checkpoint 機制的實現
DM 中通過 checkpoint 機制來實現同步任務中斷後恢復時的續傳功能。對於 load 階段,其 checkpoint 機制的實現在 DM 原始碼閱讀系列文章(四)dump/load 全量同步的實現 文章中我們已經進行了介紹,本文不再贅述。在本文中,我們將介紹 binlog replication 增量同步階段的 checkpoint 機制的實現及與之相關的 safe mode 機制的實現。
checkpoint 機制
DM 在 binlog replication 階段以 binlog event 對應的 position 為 checkpoint,包括兩類:
-
全域性 checkpiont:對應已成功解析並同步到下游的 binlog event 的 position,同步任務中斷恢復後將從該位置重新進行解析與同步
-
每個需要同步 table 的 checkpoint:對應該 table 已成功解析並同步到下游的 binlog event 的 position,主要用於在 re-sync 過程中避免對已同步的資料進行重複同步
DM 的 checkpoint 資訊儲存在下游資料庫中,通過 RemoteCheckPoint 物件進行讀寫,其主要成員變數包括:
-
globalPoint:用於儲存全域性 checkpoint -
points:用於儲存各 table 的 checkpoint
checkpoint 資訊在下游資料庫中對應的 schema 通過 createTable 方法進行建立,其中各主要欄位的含義為:
| 欄位 | 含義 |
|---|---|
id | 標識待同步資料對應的上游資料來源,當前該欄位值對應為 source-id |
cp_schema | checkpoint 資訊所屬 table 對應的 schema 名稱,對於全域性 checkpoint 該欄位值為空字串 |
cp_table | checkpoint 資訊所屬 table 的名稱,對於全域性 checkpoint 該欄位值為空字串 |
binlog_name | checkpoint 資訊的 binlog filename |
binlog_pos | checkpoint 資訊的 binlog event position |
is_global | 標識該條 checkpoint 資訊是否是全域性 checkpoint |
對於全域性 checkpoint,在以下情況下會更新記憶體中的資訊:
-
收到 XID event 時(表示一個 DML 事務的結束)
對於各 table checkpoint,在以下情況下會更新記憶體中的資訊:
對於全域性與 table 的 checkpoint,會在以下情況下 flush 到下游資料庫中:
-
收到 flush 通知(如同步任務將暫停或停止時)
值得注意的是,在 shard DDL 未同步到下游之前,為確保中斷恢復後仍能繼續整個 shard DDL 的協調過程,DM 不會將全域性 checkpoint 更新為比 shard DDL 起始 position 更大的 position,DM 也不會將 shard DDL 協調過程中對應 table 的 checkpoint flush 到下游。
safe mode 機制
當同步任務中斷恢復後,DM 在 binlog replication 階段通過 checkpoint 機制保證了重新開始同步的起始點前的資料都已經成功同步到了下游資料庫中,即保證了 at-least-once 語義。但由於 flush checkpoint 與同步 DDL、DML 到下游不是在同一個事務中完成的,因此從 checkpoint 開始重新同步時,可能存在部分資料被重複同步的可能,即不能保證 at-most-once 。
在 DM 的 binlog replication 階段,通過增加 safe mode 機制確保了重複同步資料時的可重入,即:
目前,safe mode 會在以下情況時啟用:
-
啟動或恢復任務時的前 5 分鐘,確保從 checkpoint 位置開始被重複同步的部分資料最終一致
-
DM-worker 內進行 shard DDL 同步協調時(見前文 DM-worker 內 shard DDL 同步流程),確保即使 shard DDL 協調過程中異常重啟且 5 分鐘內無法重複同步完之前已同步資料也能最終一致
-
使用者在同步任務配置檔案中指定了啟用 safe mode,用於其他需要以 safe mode 同步超 5 分鐘的場景
小結
本篇文章詳細地介紹了 shard DDL 機制與 checkpoint 機制的實現,內容包括了兩級 shard group 的定義與 DM-worker 間及 DM-worker 內的 shard DDL 同步協調處理流程、checkpoint 機制及與之相關的 safe mode 機制。下一篇文章中,我們將介紹用於保證 DM 正確性與穩定性的測試框架的實現,敬請期待。
相關推薦
DM 原始碼閱讀系列文章(九)shard DDL 與 checkpoint 機制的實現
作者:張學程 本文為 DM 原始碼閱讀系列文章的第九篇,在 上篇文章 中我們詳細介紹了 DM 對 online schema ch
DM 原始碼閱讀系列文章(七)定製化資料同步功能的實現
作者:王相 本文為 DM 原始碼閱讀系列文章的第七篇,在 上篇文章 中我們介紹了 relay log 的實現,主要包括 relay
DM 原始碼閱讀系列文章(八)Online Schema Change 同步支援
作者:lan 本文為 DM 原始碼閱讀系列文章的第八篇,上篇文章 對 DM 中的定製化資料同步功能進行詳細的講解,包括庫表路由(T
DM 原始碼閱讀系列文章(十)測試框架的實現
作者:楊非 本文為 DM 原始碼閱讀系列文章的第十篇,之前的文章已經詳細介紹過 DM 資料同步各元件的實現原理和程式碼解析,相信大
TiDB 原始碼閱讀系列文章(二)初識 TiDB 原始碼
本文為 TiDB 原始碼閱讀系列文章的第二篇,第一篇文章介紹了 TiDB 整體的架構,知道 TiDB 有哪些模組,分別是做什麼的,從哪裡入手比較好,哪些可以忽略,哪些需要仔細閱讀。 這篇文章是一篇入門文件,難度係數比較低,其中部分內容可能大家在其他渠道已經看過
TiDB Binlog 原始碼閱讀系列文章(四)Pump server 介紹
作者: satoru 在 上篇文章 中,我們介紹了 TiDB 如何通過 Pump client 將 binlog 發往 Pump,
TiDB 原始碼閱讀系列文章(十九)tikv-client(下)
上篇文章 中,我們介紹了資料讀寫過程中 tikv-client 需要解決的幾個具體問題,本文將繼續介紹 tikv-client 裡的兩個主要的模組——負責處理分散式計算的 copIterator 和執行二階段提交的 twoPhaseCommitter。 copIterator cop
TiDB 原始碼閱讀系列文章(二十)Table Partition
作者:肖亮亮 Table Partition 什麼是 Table Partition Table Partition 是指根據一定規則,將資料庫中的一張表分解成多個更小的容易管理的部分。從邏輯上看只有一張表,但是底層卻是由多個物理分割槽組成。相信對有關係型資料庫使用背景的使用者來
TiDB 原始碼閱讀系列文章(二十一)基於規則的優化 II
在 TiDB 原始碼閱讀系列文章(七)基於規則的優化 一文中,我們介紹了幾種 TiDB 中的邏輯優化規則,包括列剪裁,最大最小消除,投影消除,謂詞下推和構建節點屬性,本篇將繼續介紹更多的優化規則:聚合消除、外連線消除和子查詢優化。 聚合消除 聚合消除會檢查 SQL 查詢中 Group By 語句所使用的列是否
TiKV 原始碼解析系列文章(三)Prometheus(上)
開發十年,就只剩下這套架構體系了! >>>
TiKV 原始碼解析系列文章(七)gRPC Server 的初始化和啟動流程
作者:屈鵬 本篇 TiKV 原始碼解析將為大家介紹 TiKV 的另一週邊元件—— grpc-rs。grpc-rs 是 PingCA
讀logback原始碼系列文章(四)——記錄日誌
今天晚上本來想來寫一下Logger怎麼記錄日誌,以及Appender元件。不過9點才從丈母孃家回來,又被幾個兄弟喊去喝酒,結果回來晚了,所以時間就只夠寫一篇Logger類的原始碼分析了。Appender找時間再寫 上篇部落格介紹了LoggerContext怎麼生成Logger
讀logback原始碼系列文章(八)——記錄日誌的實際工作類Encoder
本系列的部落格從logback怎麼對接slf4j開始,逐步介紹了LoggerContext、Logger、ContextInitializer、Appender、Action等核心元件。跟讀logback的原始碼到這個程度,雖然不能說精通,不過至少日常的配置,和簡單的自定義擴
TiKV 原始碼解析系列文章(十一)Storage
作者:張金鵬 背景知識 TiKV 是一個強一致的支援事務的分散式 KV 儲存。TiKV 通過 raft 來保證多副本之間的強一致,
Java系列文章(全)
java 學習JVMJVM系列:類裝載器的體系結構 JVM系列:Class文件檢驗器JVM系列:安全管理器JVM系列:策略文件Java垃圾回收機制深入剖析Classloader(一)--類的主動使用與被動使用深入剖析Classloader(二)-根類加載器,擴展類加載器與系統類加載器深入理解JVM—JVM內存
Linux系列教程(九)——Linux常用命令之網絡和關機重啟命令
route 註意 端口號 post rac pos 名稱 window ebo 前一篇博客我們講解了Linux壓縮和解壓縮命令,使用的最多的是tar命令,因為現在很多源碼包都是.tar.gz的格式,通過 tar -zcvf 能完成解壓。然後對於.zip格式的文件,使用g
openstack系列文章(四)
cnblogs 調度器 5.5 min 代碼位置 虛機 inux latest 階段 學習 openstack 的系列文章 - Nova Nova 基本概念 Nova 架構 openstack Log Nova 組件介紹 Nova 操作介紹 1. Nova 基本概念
[搬運工系列]-JMeter (九)分散式測試
Jmeter 是java 應用,對於CPU和記憶體的消耗比較大,因此,當需要模擬數以千計的併發使用者時,使用單臺機器模擬所有的併發使用者就有些力不從心,甚至會引起JAVA記憶體溢位錯誤。為了讓jmeter工具提供更大的負載能力,jmeter短小精悍一有了使用多臺機器同時產生負載的機制。
SVM支援向量機系列理論(九) 核嶺迴歸
1. 嶺迴歸問題 嶺迴歸就是使用了L2正則化的線性迴歸模型。當碰到資料有多重共線性時(自變良量存在高相關性),我們就會用到嶺迴歸。 嶺迴歸模型的優化策略為: minw 1N∑i(yi−w⋅zi)2+λNwTw&nbs
element-ui Steps步驟條元件原始碼分析整理筆記(九)
Steps步驟條元件原始碼: steps.vue <template> <!--設定 simple 可應用簡潔風格,該條件下 align-center / description / direction / space 都將失效。--> <div clas