
JVM(九):垃圾回收演算法
JVM(九):垃圾回收演算法
在本文中,我們將從概念模型的角度探討 JVM 是如何回收物件,包括 JVM 是如何判斷一個物件已經死亡,什麼時候在哪裡進行了垃圾回收,垃圾回收有幾種核心演算法,每個演算法優劣是什麼等。
為何需要GC
Java 中的一個核心技術就是自動垃圾回收,該技術使得程式設計師可以不用像寫 C++ 一樣手動分配和釋放記憶體,那麼為何還需要我們去學習垃圾回收呢。這裡就要說到兩個概念了。
- 記憶體洩露:有已經不再使用的物件仍然佔用著記憶體;
- 記憶體溢位:已經沒有足夠的空間可以讓 JVM 分配記憶體給物件了。
大量的記憶體洩露會引發記憶體溢位,但記憶體溢位不一定是記憶體洩露引起的,也可能是因為總共的記憶體空間就不夠大,而需要分配的物件太大導致。
學習垃圾回收的背後邏輯,可以讓我們在程式發生記憶體溢位的時候,快速高效地排查出問題進行解決。並且學習了 GC 的細節,也有助於我們調節 JVM 的一些執行引數,讓系統達到更高的併發量。
物件的死亡
如果要銷燬一個物件,那麼就需要確定該物件已經死亡,只有這樣才能夠將該物件所佔的記憶體空間進行釋放。那麼 JVM 是如何判斷一個物件已經死亡了呢。
引用計數法
引用計數法實現十分簡單,就是給每一個物件增加一個計數器,每當有一個地方對其進行了引用就 +1,當引用失效時就 -1,如果計數器的值為 0,則代表該物件已經不再被使用了,可以對其回收了。
這種方式的最大優點就是實現簡單,判定效率高。但其有一個致命的缺點就是 迴圈引用問題。當兩個物件互相引用,但其實他們已經沒有任何其他用處了。此時因為彼此間還存在引用,就會發生迴圈引用,使用引用計數法就無法對其進行回收。
可達性分析演算法
正是因為引用計數法那個致命的缺點,因此主流的實現都是通過 可達性分析 來判斷物件能否進行銷燬。其核心思想是 通過一系列稱為 "GC Roots" 的節點來作為起始點,從這些節點開始搜尋,這個搜尋的軌跡被稱為 "引用鏈",如果一個物件沒有包含在任何一個引用鏈中,那麼就判斷該物件是無效的。
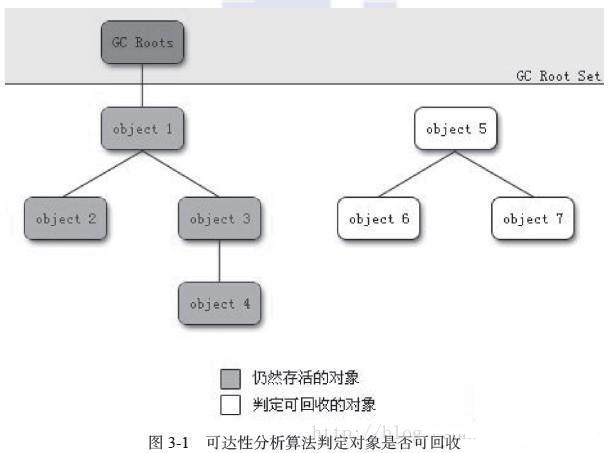
概念中說到是通過 GC Roots 來作為起始點,那麼哪些物件可以作為GC Roots呢。
- 虛擬機器棧中引用的物件;
- 本地方法棧中引用的物件;
- 方法區中靜態屬性引用的物件;
- 方法區中常量引用的物件。
引用的區分
在判斷物件能否被銷燬的時候,都使用到了 引用 這個詞語,說的是如果有被引用的,那麼就不銷燬,如果沒有引用則將其進行銷燬,這種分別方式非黑即白,太過強硬,因此 JDK1.2 之後對引用的含義進行了擴充,實現了多級回收的效果。即在記憶體不緊張的時候,有一些物件是可以進行保留的,但如果記憶體緊張的時候,就需要對其進行回收。
- 強引用:我們平常在程式設計使用的引用都是這種,普遍存在的引用,只要是這個,就不會被回收;
- 軟引用:有用但非必需。在記憶體很緊張快要溢位的時候,就會回收這些物件,如果回收後還沒有空餘空間才會報記憶體溢位。這種引用通常用來實現記憶體敏感的快取;
- 弱引用:比軟引用更弱一些,只能活到下一次垃圾回收前。其實主要回收的就是這些記憶體;
- 虛引用:虛引用不對物件生存時間造成影響,也無法通過虛引用獲得物件例項。其存在的價值就是在物件收到回收的時候,能夠讓系統做一些事。應用場景為跟蹤物件被 GC 的活動,因為其被回收的時候系統會受到一條系統通知。
方法區的回收
前面說的都是物件的回收,即對堆記憶體的回收,但其實在方法區內也是有垃圾回收的。在方法區內回收的內容主要是 廢棄常量 和 無用的類。
其中廢棄常量很好理解。就是常量池中的一個常量已經沒有任何物件引用它了,即其已經沒有價值了,那麼就會將其移出常量池,回收其空間。
而對無用的類進行回收又是怎麼理解的呢。首先我們需要判斷什麼是無用的類。一個類是無用的,需要滿足以下3點:
- 該類的例項都已經被回收了,即堆中沒有該類的例項物件
- 載入該類的 ClassLoader 已經被回收
- 無法通過反射訪問該類,即該類對應的 java.lang.Class 物件沒有被呼叫
只有滿足以上3點的類才可以被回收,但其是否回收取決於 JVM 啟動時的引數控制。JVM 可以在啟動時設定不對類進行回收。
回收演算法
上面我們已經明白了什麼物件是可以回收的,那麼我們該如何針對這些物件進行回收呢。回收前後記憶體空間又是如何佈局的呢。下面就讓我們來看一下幾個主流的 GC 演算法。
標記-清除演算法
標記-清除演算法是最簡單,最基本的演算法。其本質就如同其名字一樣,分為2個步驟,首先標記出所有需要清除的物件,然後在回收階段,統一清除即可。
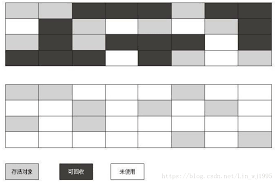
但其擁有兩個嚴重的缺點。一個是標記和清除階段都不快,效率很低;另一個是其只是單純的將無用的物件清除,很容易造成大量的記憶體碎片,如果記憶體碎片太多,那麼在分配大物件的時候,就很容易造成記憶體不夠的情況。因此針對這些情況,就出現了幾個改進的優良版本。
標記-整理演算法
標記-整理演算法解決的是記憶體碎片的問題,在標記階段還是採取一樣的解決方式,但在下個階段並不是直接清除掉無用物件,而是先將有用的物件移到記憶體的一邊,然後直接回收掉分界線一邊的物件,這樣就可以騰出許多規整的空間。
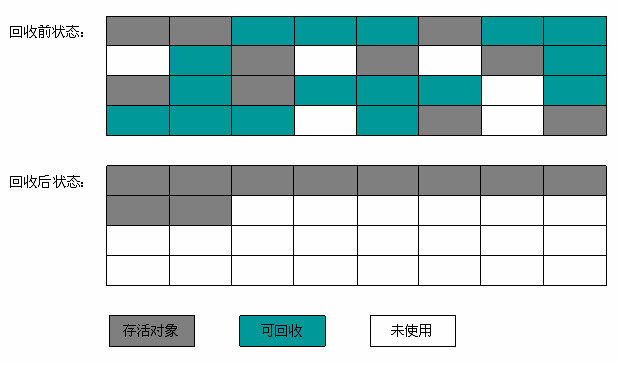
複製演算法
標記-整理演算法只是解決了記憶體碎片的問題,但是效率問題還是一個痛點,因此就有人提出了複製演算法。其將記憶體空間分為 2 部分,每一次只使用其中一塊,當這一塊的空間用完了,就將存活的物件複製到另一邊去,然後將使用過的空間直接清理掉即可。這種演算法十分的高效,也解決了記憶體碎片的問題。
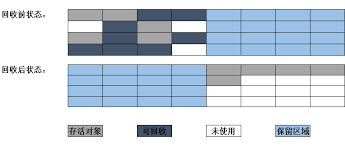
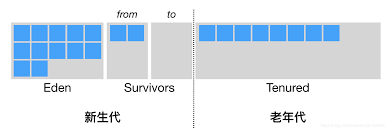
但其將可用空間簡單的劃分為了50-50,代價十分的高昂。不過經過研究表明,新生代物件大部分都是朝生夕死的,因此不需要按照 1:1 的比例來劃分空間。商用的虛擬機器 HotSpot 就是預設將記憶體劃分為 8:1:1,即一塊Eden區,兩個Survivor區,在進行分配時,將 Eden 和一個 Survivor 直接複製到另一個 Survivor 即可,這樣解決了複製演算法空閒空間太大的問題,又提高了 GC 的效率。
但是也正是因為這樣的劃分,Survivor 的記憶體空間是比較小的,因此需要有一個其他記憶體進行分配擔保,確保大物件也能夠進行記憶體分配,這就老年代存在的價值之一。當另一塊 Survivor 沒有足夠空間放置物件時,將會直接將物件分配至老年代。而老年代採取的 GC 演算法為標記-整理演算法。
分代演算法
經過上面 3 種演算法的分析,想必大家也想到了,分代演算法其實並不是一個新演算法,其只是根據前面演算法的優劣將記憶體空間進行了劃分,對每個不同的空間採取不同的演算法,以便根據各個不同的年代採取不同的,最適合的演算法。
在 Java8 之前,方法區稱為永久代,也如同堆空間一樣被 GC 進行管理,但在 Java8 之後,這種實現方式被MetaSpace 取代,採用直接記憶體的方式來進行記憶體分配管理.
Hotspot 將記憶體劃分為新生代和老年代。新生代因為大部分的物件都是快節奏的,因此採用複製演算法來處理。而老年代因為物件存活率高,且已經沒有額外空間對齊進行分配擔保了,因此採用標記-清理或標記-整理演算法進行處理。
總結
在本文中,我們介紹了什麼是垃圾回收,如何判斷物件應該進行回收了,以及回收邏輯的幾個不同抽象模型。在後面的文章,我們將對演算法的具體實現進行探討,瞭解當前業內主流的虛擬機器實現,看看在實際生產情況下,不同的 垃圾收集器 的具體實現方式.

文章在公眾號 “iceWang" 第一手更新,有興趣的朋友可以關注公眾號,第一時間看到筆者分享的各項知識點,謝謝!筆芯!
本系列文章主要借鑑自《深入分析 JavaWeb 技術內幕》和《深入理解 Java 虛擬機器-JVM高階特性與最佳實踐》。