
程式設計師修神之路--做好分庫分表其實很難之二(繼續送書)
菜菜哥,上次聽你給我講了分庫的情況後,我明白了很多,能再給我講講分表嗎

有收穫就好,分表其實有很多情況和分庫類似

還有不一樣的情況嗎?
有呀,本來資料庫和表是不同層面的東西,肯定有差異
那你給講講唄
講可以,一杯coffee如何?
為什麼分

在正式開始之前,菜菜還是要強調一點,你的資料表是否應該分,需要綜合考慮很多因素,比如業務的資料量是否到達了必須要切分的數量級,是否可以有其他方案來解決當前問題?我不止一次的見過,有的leader在不考慮綜合情況下,盲目的進行表拆分業務,導致的情況就是大家不停的加班,連續幾周996,難道leader你不掉頭髮嗎?還有的架構師在一個小小業務初期就進行表拆分,大家為了配合你也是馬不停蹄的加班趕進度,上線之後反而發現業務資料量很小,但是程式碼上卻被分表策略牽制了太多。拆表引起的問題在特定的場景下,有時候代價真的很大。
資料庫表的拆分解決的問題主要是儲存和效能問題,mysql在單表資料量達到一定量級後,效能會急劇下降,相比較於sqlserver和Oracle這些收費DB來說,mysql在某些方面還是處於弱勢,但是表的拆分這個策略卻適用於幾乎所有的關係型資料庫。

資料庫進行表拆分不要太盲目

分表策略
表的拆分和資料庫的拆分有相似之處,但是拆分的規則也有不同。以下的拆分規則針對的是拆分一個表。
橫向切分
橫向切分是諸多業務中最常用的切分方式,本質是把一個表中的資料行按照規則分散到多個表中,比如最常見的按照ID範圍,按照業務主鍵的雜湊值等。至於表資料到達什麼數量級之後進行切分,這和表中存的資料格式有關,比如一個表只有幾列的int欄位肯定要比幾列text型別的表儲存的極限要高。姑且認為這個極限是1000萬吧。但是作為一個系統的負責人或者架構師來說,當表的資料量級到達千萬級別要引起重視,因為這是一個系統性能瓶頸的隱患。
相對於資料表的橫向切分,在符合業務優化的場景下我更傾向於做表分割槽,按照規則把不同的分割槽分配到不同的物理磁碟,這樣的話,業務裡的sql語句幾乎可以不用改動。我司的一個sqlserver資料庫,某個業務的表做了表分割槽之後,已經到達幾十億級別的資料量,但是查詢和插入速度還是能滿足業務的需求(優化一個系統還是要花精力優化業務層面)。
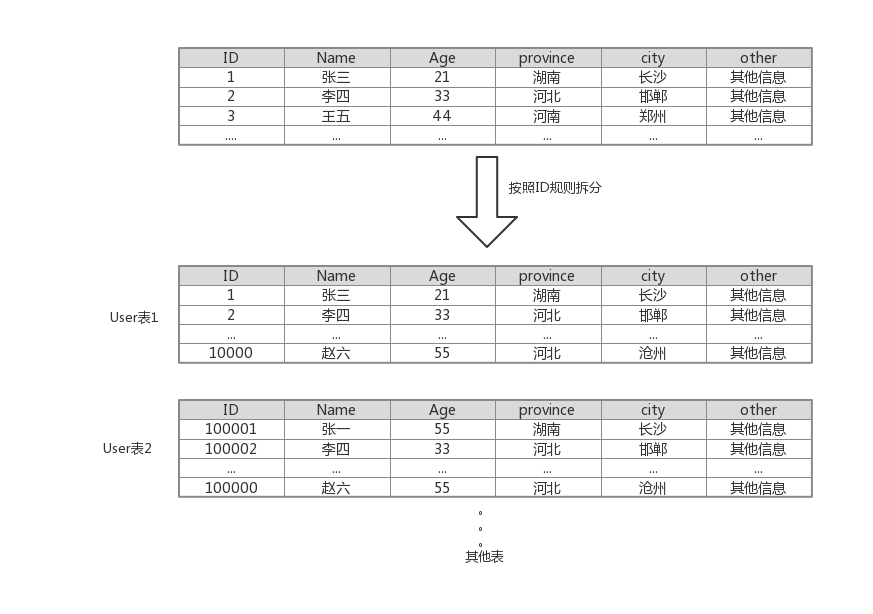
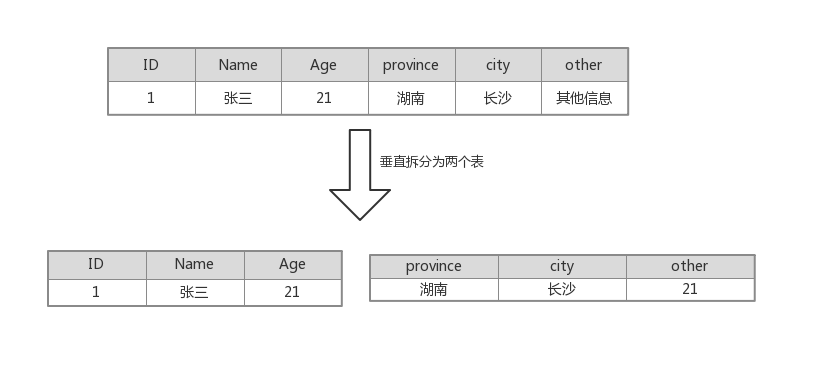
垂直切分
說到垂直拆分,表也可以按照業務來拆分,比如一個數據庫中有使用者的資訊,根據業務可以劃分為基礎資訊和擴充套件資訊,如果對業務有利,完全可以拆分為基礎資訊表和擴充套件資訊表。當然也可以按照別的規則來拆,比如把訪問頻繁的資訊拆分成一個表,其他不頻繁的資訊拆分成一個表,具體的拆分規則還是要看當時要解決的問題是什麼。垂直拆分可能會引入一定複雜性,比如原來查詢一個使用者的基礎資訊和擴充套件資訊可以一次性查詢出結果,分表之後需要進行Join操作或者查詢兩次才能查詢出結果。
分表代價
1. 資料表垂直切分之後,原來一次查詢有可能會變為連表的join查詢,在一定程度上會有效能損失。
2. 資料表橫向切分需要一定的規則,常用的主要有兩種規則:範圍切分和雜湊值切分。範圍切分是指按照某個欄位的範圍來切分,比如使用者表按照使用者ID來切分,id為1到10萬的位於User表1中,100001到200000萬的位於User2中,這樣切分的優勢是,可以無限的擴容下去,不用考慮資料遷移的問題,劣勢就是新表和舊錶資料分佈不均勻,而且分表的範圍選取有一定難度,範圍太小會導致表太多,太大會導致問題根本上沒有解決的困惑。另外一種分表策略就是把某一列按照雜湊值來路由到不同的表中,同樣以使用者ID為例,假如我們一開始就規劃了10個數據庫表,路由演算法可以簡單地用 user_id %10的值來表示資料所屬的資料庫表編號,ID為985的使用者放到編號為 5的子表中,ID為10086的使用者放到編號為 6 的字表中。這種切分規則的優勢是每個表的資料分佈比較均勻,但是後期擴容會設計到部分資料的遷移工作。
3. 表拆分之後如果遇到有order by 的操作,資料庫就無能為力了,只能由業務程式碼或者資料庫中介軟體來完成了。
4. 當有搜尋的業務需求的時候,sql語句只能是Join多個表來進行連表查詢了,類似的還有統計的需求,例如count的統計操作。
你在業務中進行過表拆分嗎?公眾號回覆“抽獎”,送書活動還在繼續!!
