
分析了京東內衣銷售記錄,告訴你妹子們的真Size!
阿新 • • 發佈:2019-07-26
>今天閒暇之餘寫了一個爬蟲例子。通過爬蟲去爬取京東的使用者評價,通過分析爬取的資料能得到很多結果,比如,哪一種顏色的胸罩最受女性歡迎,以及中國女性的平均size(僅供參考哦~)
開啟開發者工具-network,在使用者評價頁面我們發現瀏覽器有這樣一個請求
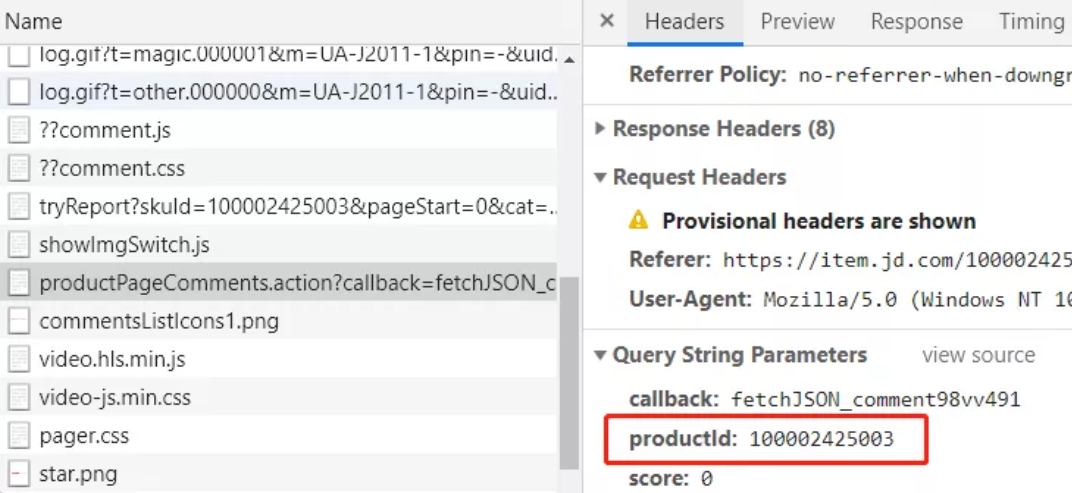
通過分析我們發現主要用的引數有三個productId,page,pageSize。後兩個為分頁引數,productId是每個商品的id,通過這個id去獲取商品的評價記錄,所以我們只需要知道每個商品的productId就輕而易舉的獲取評價了。再來分析搜尋頁面的網頁原始碼

通過分析我們發現每個商品都在li標籤中,而li標籤又有一個data-pid屬性,這個對應的值就是商品的productId了。
大概瞭解了整個流程,就可以開始我們的爬蟲工作了。
---
首先我們需要在搜尋頁面獲取商品的id,為下面爬取使用者評價提供productId。key_word為搜尋的關鍵字,這裡就是【胸罩】
```python
import requests
import re
"""
查詢商品id
"""
def find_product_id(key_word):
jd_url = 'https://search.jd.com/Search'
product_ids = []
# 爬前3頁的商品
for i in range(1,4):
param = {'keyword': key_word, 'enc': 'utf-8', 'page': i}
response = requests.get(jd_url, params=param)
# 商品id
ids = re.findall('data-pid="(.*?)"', response.text, re.S)
product_ids += ids
return product_ids
```
將前三頁的商品id放入列表中,接下來我們就可以爬取評價了
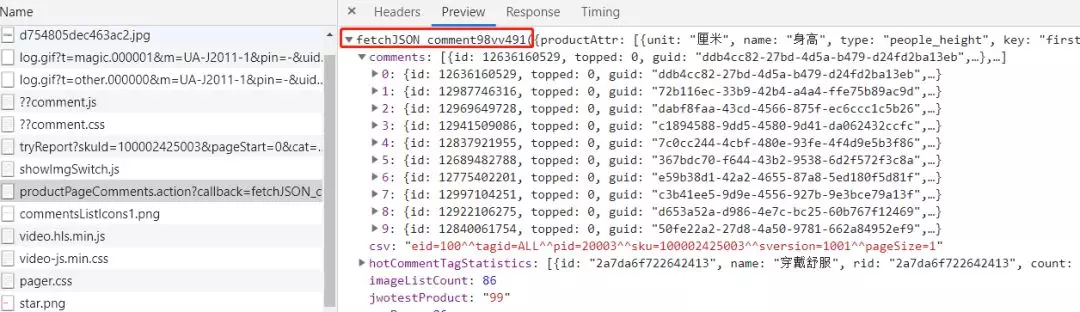
我們通過分析preview發現獲取使用者評價這個請求響應的格式是一個字串後面拼接了一個json(如下圖),所以我們只要將無用的字元刪除掉,就可以獲取到我們想要的json物件了。
而在json物件中的comments的內容就是我們最終想要的評價記錄
```python
"""
獲取評論內容
"""
def get_comment_message(product_id):
urls = ['https://sclub.jd.com/comment/productPageComments.action?' \
'callback=fetchJSON_comment98vv53282&' \
'productId={}' \
'&score=0&sortType=5&' \
'page={}' \
'&pageSize=10&isShadowSku=0&rid=0&fold=1'.format(product_id, page) for page in range(1, 11)]
for url in urls:
response = requests.get(url)
html = response.text
# 刪除無用字元
html = html.replace('fetchJSON_comment98vv53282(', '').replace(');', '')
data = json.loads(html)
comments = data['comments']
t = threading.Thread(target=save_mongo, args=(comments,))
t.start()
```
在這個方法中只獲取了前10頁的評價的url,放到urls這個列表中。通過迴圈獲取不同頁面的評價記錄,這時啟動了一個執行緒用來將留言資料存到到MongoDB中。
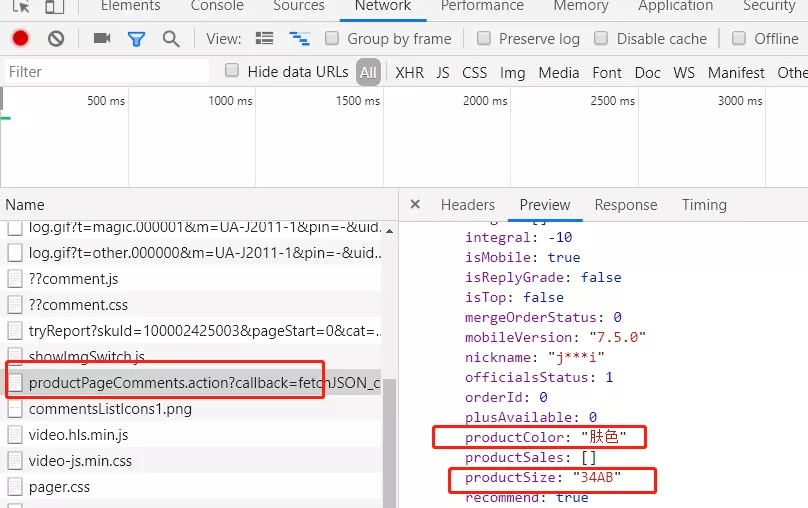
我們繼續分析評價記錄這個介面發現我們想要的兩條資料
- productColor:產品顏色
- productSize:產品尺寸
```python
# mongo服務
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
# jd資料庫
db = client.jd
# product表,沒有自動建立
product_db = db.product
# 儲存mongo
def save_mongo(comments):
for comment in comments:
product_data = {}
# 顏色
# flush_data清洗資料的方法
product_data['product_color'] = flush_data(comment['productColor'])
# size
product_data['product_size'] = flush_data(comment['productSize'])
# 評論內容
product_data['comment_content'] = comment['content']
# create_time
product_data['create_time'] = comment['creationTime']
# 插入mongo
product_db.insert(product_data)
```
因為每種商品的顏色、尺寸描述上有差異,為了方面統計,我們進行了簡單的資料清洗。這段程式碼非常的不Pythonic。不過只是一個小demo,大家無視即可。
```python
def flush_data(data):
if '膚' in data:
return '膚色'
if '黑' in data:
return '黑色'
if '紫' in data:
return '紫色'
if '粉' in data:
return '粉色'
if '藍' in data:
return '藍色'
if '白' in data:
return '白色'
if '灰' in data:
return '灰色'
if '檳' in data:
return '香檳色'
if '琥' in data:
return '琥珀色'
if '紅' in data:
return '紅色'
if '紫' in data:
return '紫色'
if 'A' in data:
return 'A'
if 'B' in data:
return 'B'
if 'C' in data:
return 'C'
if 'D' in data:
return 'D'
```
這幾個模組的功能編寫完畢,下面只需要將他們聯絡起來
```python
# 建立一個執行緒鎖
lock = threading.Lock()
# 獲取評論執行緒
def spider_jd(ids):
while ids:
# 加鎖
lock.acquire()
# 取出第一個元素
id = ids[0]
# 將取出的元素從列表中刪除,避免重複載入
del ids[0]
# 釋放鎖
lock.release()
# 獲取評論內容
get_comment_message(id)
product_ids = find_product_id('胸罩')
for i in (1, 5):
# 增加一個獲取評論的執行緒
t = threading.Thread(target=spider_jd, args=(product_ids,))
# 啟動執行緒
t.start()
```
上面程式碼加鎖的原因是為了防止重複消費共享變數
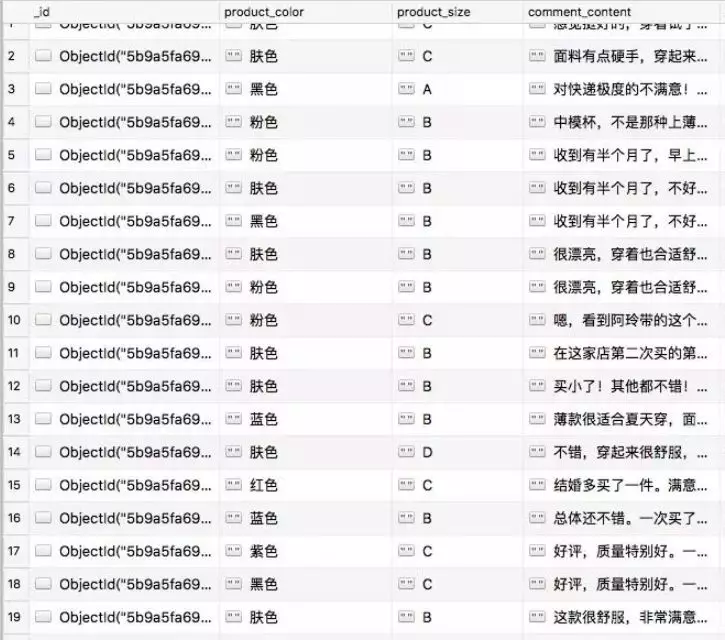
執行之後的檢視MongoDB:
得到結果之後,為了能更直觀的表現資料,我們可以用matplotlib庫進行圖表化展示
```python
import pymongo
from pylab import *
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
# jd資料庫
db = client.jd
# product表,沒有自動建立
product_db = db.product
# 統計以下幾個顏色
color_arr = ['膚色', '黑色', '紫色', '粉色', '藍色', '白色', '灰色', '香檳色', '紅色']
color_num_arr = []
for i in color_arr:
num = product_db.count({'product_color': i})
color_num_arr.append(num)
# 顯示的顏色
color_arr = ['bisque', 'black', 'purple', 'pink', 'blue', 'white', 'gray', 'peru', 'red']
#labeldistance,文字的位置離遠點有多遠,1.1指1.1倍半徑的位置
#autopct,圓裡面的文字格式,%3.1f%%表示小數有三位,整數有一位的浮點數
#shadow,餅是否有陰影
#startangle,起始角度,0,表示從0開始逆時針轉,為第一塊。一般選擇從90度開始比較好看
#pctdistance,百分比的text離圓心的距離
#patches, l_texts, p_texts,為了得到餅圖的返回值,p_texts餅圖內部文字的,l_texts餅圖外label的文字
patches,l_text,p_text = plt.pie(sizes, labels=labels, colors=colors,
labeldistance=1.1, autopct='%3.1f%%', shadow=False,
startangle=90, pctdistance=0.6)
#改變文字的大小
#方法是把每一個text遍歷。呼叫set_size方法設定它的屬性
for t in l_text:
t.set_size=(30)
for t in p_text:
t.set_size=(20)
# 設定x,y軸刻度一致,這樣餅圖才能是圓的
plt.axis('equal')
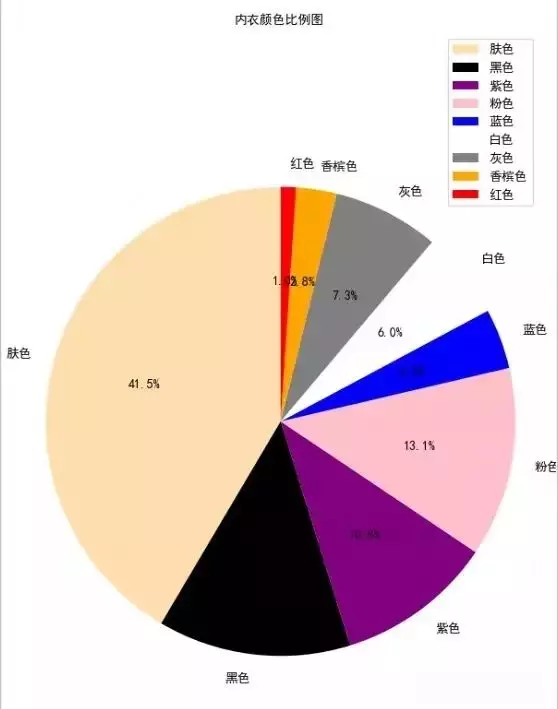
plt.title("內衣顏色比例圖", fontproperties="SimHei") #
plt.legend()
plt.show()
```
執行程式碼,我們發現膚色的最受歡迎 其次是黑色 (鋼鐵直男表示不知道是不是真的...)
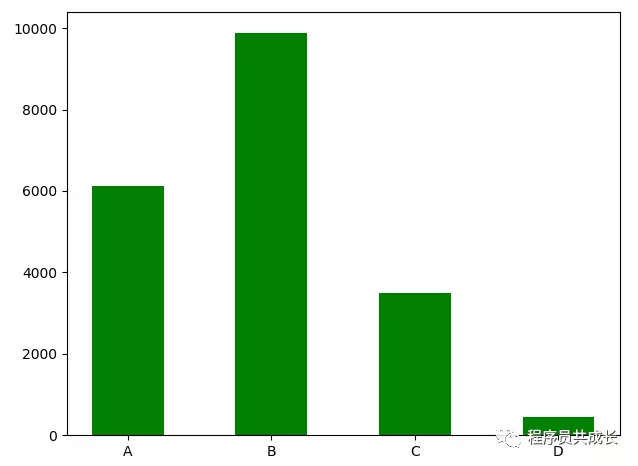
接下來我們再來統計一下size 的分佈圖,這裡用柱狀圖進行顯示
```python
index=["A","B","C","D"]
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
db = client.jd
product_db = db.product
value = []
for i in index:
num = product_db.count({'product_size': i})
value.append(num)
plt.bar(left=index, height=value, color="green", width=0.5)
plt.show()
```
執行後我們發現 B size的女性更多一些
---
最後,歡迎大家關注我的公眾號(python3xxx)。每天都會推送不一樣的Python乾貨。
![圖片描述](//img.mukewang.com/5d39d61c00017fad04760