
爬蟲遇到IP訪問頻率限制的解決方案
背景:
大多數情況下,我們遇到的是訪問頻率限制。如果你訪問太快了,網站就會認為你不是一個人。這種情況下需要設定好頻率的閾值,否則有可能誤傷。如果大家考過託福,或者在12306上面買過火車票,你應該會有這樣的體會,有時候即便你是真的用手在操作頁面,但是因為你滑鼠點得太快了,它都會提示你: “操作頻率太快...”。
遇到這種網頁,最直接的辦法是限制訪問時間。例如每隔5秒鐘訪問一次頁面。但是如果遇到聰明一點的網站,它檢測到你的訪問時間,這個人訪問了幾十個頁面,但是每次訪問都剛好5秒鐘,人怎麼可能做到這麼準確的時間間隔?肯定是爬蟲,被封也是理所當然的!所以訪問時間間隔你可以設定為一個隨機值,例如0到10之間的隨機秒數。
當然,如果遇到限制訪問頻率的網站,我們使用Selenium來訪問就顯得比較有優勢了,因為Selenium這個東西開啟一個頁面本身就需要一定的時間,所以我們因禍得福,它的效率低下反而讓我們繞過了頻率檢查的反爬蟲機制。而且Selenium還可以幫我們渲染網頁的JavaScript,省去了人工分析JavaScript原始碼的麻煩,可謂一舉兩得。
下面是我經常使用的修改訪問頻率的幾種場景,供大家參考:
1、Request 單機版爬蟲:
上面的程式碼可以放在request請求之後

2、scrapy 單機版爬蟲或者scrapy_redis分散式爬蟲

在這裡設定請求間隔時間,其他引數的講解,我會更新到新的博文中,敬請大家期待
另外,不明確 scapy 和 scrapy_redis 區別的朋友們,可以移步到這裡
https://
3、有一種情況可以忽略
有些網站,比如在我之前遇到過的這種網站(hwt),伺服器會限制你的訪問頻率,但是並不會封IP,頁面將持續顯示403(伺服器拒絕訪問),偶爾顯示200(請求成功),那麼就證明(前提是我們設定過請求頭等資訊),這樣的反爬機制,只是限制了請求的頻率,但是並不會影響到正常的採集,當然這樣的情況也不多見,所以我們要學會針對性地寫爬蟲。
4、某些伺服器由於效能原因,響應較慢(會導致響應超時,從而終止請求)
這種場景一般出現在小網站較多,如(DYW),在我們將請求的引數都安排好之後,卻發現,由於伺服器的效能原因,採集程式持續報網頁404,出現這種情況我們只能延長響應超時的時長,如下圖所示:

5、代理IP或者分散式爬蟲:
如果對頁的爬蟲的效率有要求,那就不能通過設定訪問時間間隔的方法來繞過頻率檢查了。
代理IP訪問可以解決這個問題。如果用100個代理IP訪問100個頁面,可以給網站造成一種有100個人,每個人訪問了1頁的錯覺。這樣自然而然就不會限制你的訪問了。
代理IP經常會出現不穩定的情況。你隨便搜一個“免費代理”,會出現很多網站,每個網站也會給你很多的代理IP,但實際上,真正可用的代理IP並不多。你需要維護一個可用的代理IP池,但是一個免費的代理IP,也許在你測試的時候是可以使用的,但是幾分鐘以後就失效了。使用免費代理IP是已經費時費力,而且很考驗你運氣的事情。
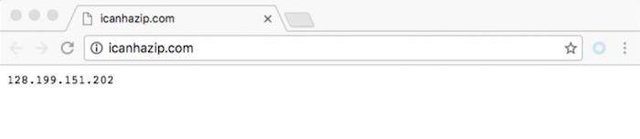
大家可以使用http://icanhazip.com/ 這個網站來檢測你的代理IP是否設定成功。當你直接使用瀏覽器訪問這個網站的時候,它會返回你的IP地址。如下圖所示:
通過requests,我們可以設定代理訪問網站,在requests的get方法中,有一個proxies引數,它接收的資料是一個字典,在這個字典中我們可以設定代理。
大家可以在requests的官方中文文件中看到關於設定代理的更多資訊:http://docs.python-requests.org/zh_CN/latest/user/advanced.html#proxies
我選擇第一個HTTP型別的代理來給大家做測試,執行效果如下圖所示:
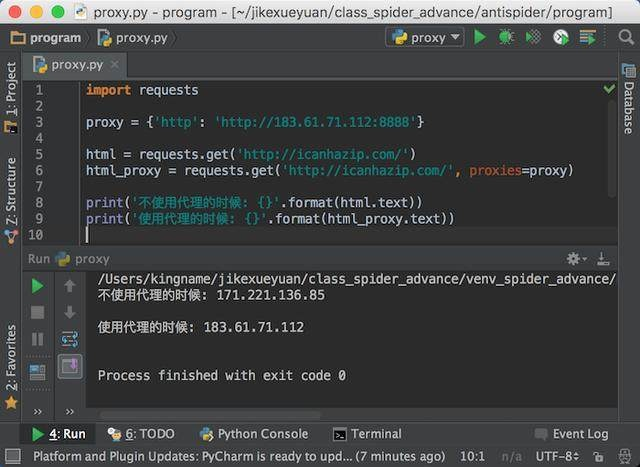
從上圖可以看出,我們成功通過了代理IP來訪問網站。
我們還可以使用分散式爬蟲。分散式爬蟲會部署在多臺伺服器上,每個伺服器上的爬蟲統一從一個地方拿網址。這樣平均下來每個伺服器訪問網站的頻率也就降低了。由於伺服器是掌握在我們手上的,因此實現的爬蟲會更加的穩定和高效。這也是我們這個課程最後要實現的目標。
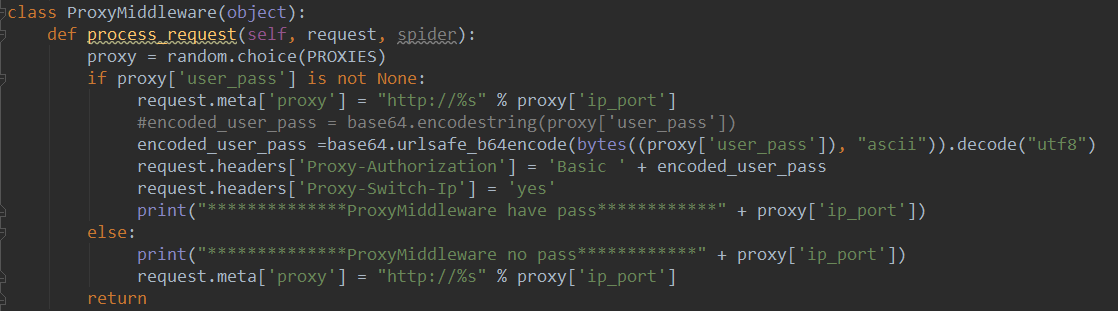
那麼分散式的爬蟲,動態代理IP是在settings.py中設定的,如下圖:

然後在這裡呼叫

最終是在middlewares.py中生效
有一些網站,他們每個相同型別的頁面的原始碼格式都不一樣,我們必需要針對每一個頁面寫XPath或者正則表示式,這種情況就比較棘手了。如果我們需要的內容只是文字,那還好說,直接把所有HTML標籤去掉就可以了。可是如果我們還需要裡面的連結等等內容,那就只有做苦力一頁一頁的去看了。
&n