
軟體開發規範
一. 軟體的開發規範
什麼是開發規範?為什麼要有開發規範呢?
你現在包括之前寫的一些程式,所謂的'專案',都是在一個py檔案下完成的,程式碼量撐死也就幾百行,你認為沒問題,挺好。但是真正的後端開發的專案,系統等,少則幾萬行程式碼,多則十幾萬,幾十萬行程式碼,你全都放在一個py檔案中行麼?當然你可以說,只要能實現功能即可。咱們舉個例子,如果你的衣物只有三四件,那麼你隨便堆在櫥櫃裡,沒問題,咋都能找到,也不顯得特別亂,但是如果你的衣物,有三四十件的時候,你在都堆在櫥櫃裡,可想而知,你找你穿過三天的襪子,最終從你的大衣口袋裡翻出來了,這是什麼感覺和心情......
軟體開發,規範你的專案目錄結構,程式碼規範,遵循PEP8規範等等,讓你更加清晰滴,合理滴開發。
那麼接下來我們以部落格園系統的作業舉例,將我們之前在一個py檔案中的所有程式碼,整合成規範的開發。
首先我們看一下,這個是我們之前的目錄結構(簡化版):


py檔案的具體程式碼如下:


status_dic = { 'username': None, 'status': False, } flag = True def login(): i = 0 with open('register', encoding='utf-8') as f1: dic = {i.strip().split('|')[0]: i.strip().split('|')[1] for i in f1} while i < 3: username = input('請輸入使用者名稱:').strip() password = input('請輸入密碼:').strip() if username in dic and dic[username] == password: print('登入成功') return True else: print('使用者名稱密碼錯誤,請重新登入') i += 1 def register(): with open('register', encoding='utf-8') as f1: dic = {i.strip().split('|')[0]: i.strip().split('|')[1] for i in f1} while 1: print('\033[1;45m 歡迎來到註冊頁面 \033[0m') username = input('請輸入使用者名稱:').strip() if not username.isalnum(): print('\033[1;31;0m 使用者名稱有非法字元,請重新輸入 \033[0m') continue if username in dic: print('\033[1;31;0m 使用者名稱已經存在,請重新輸入 \033[0m') continue password = input('請輸入密碼:').strip() if 6 <= len(password) <= 14: with open('register', encoding='utf-8', mode='a') as f1: f1.write(f'\n{username}|{password}') status_dic['username'] = str(username) status_dic['status'] = True print('\033[1;32;0m 恭喜您,註冊成功!已幫您成功登入~ \033[0m') return True else: print('\033[1;31;0m 密碼長度超出範圍,請重新輸入 \033[0m') def auth(func): def inner(*args, **kwargs): if status_dic['status']: ret = func(*args, **kwargs) return ret else: print('\033[1;31;0m 請先進行登入 \033[0m') if login(): ret = func(*args, **kwargs) return ret return inner @auth def article(): print(f'\033[1;32;0m 歡迎{status_dic["username"]}訪問文章頁面\033[0m') @auth def diary(): print(f'\033[1;32;0m 歡迎{status_dic["username"]}訪問日記頁面\033[0m') @auth def comment(): print(f'\033[1;32;0m 歡迎{status_dic["username"]}訪問評論頁面\033[0m') @auth def enshrine(): print(f'\033[1;32;0m 歡迎{status_dic["username"]}訪問收藏頁面\033[0m') def login_out(): status_dic['username'] = None status_dic['status'] = False print('\033[1;32;0m 登出成功 \033[0m') def exit_program(): global flag flag = False return flag choice_dict = { 1: login, 2: register, 3: article, 4: diary, 5: comment, 6: enshrine, 7: login_out, 8: exit_program, } while flag: print(''' 歡迎來到部落格園首頁 1:請登入 2:請註冊 3:文章頁面 4:日記頁面 5:評論頁面 6:收藏頁面 7:登出 8:退出程式''') choice = input('請輸入您選擇的序號:').strip() if choice.isdigit(): choice = int(choice) if 0 < choice <= len(choice_dict): choice_dict[choice]() else: print('\033[1;31;0m 您輸入的超出範圍,請重新輸入 \033[0m') else: print('\033[1;31;0m 您您輸入的選項有非法字元,請重新輸入 \033[0m')
View Code
此時我們是將所有的程式碼都寫到了一個py檔案中,如果程式碼量多且都在一個py檔案中,那麼對於程式碼結構不清晰,不規範,執行起來效率也會非常低。所以我們接下來一步一步的修改:
- 程式配置.
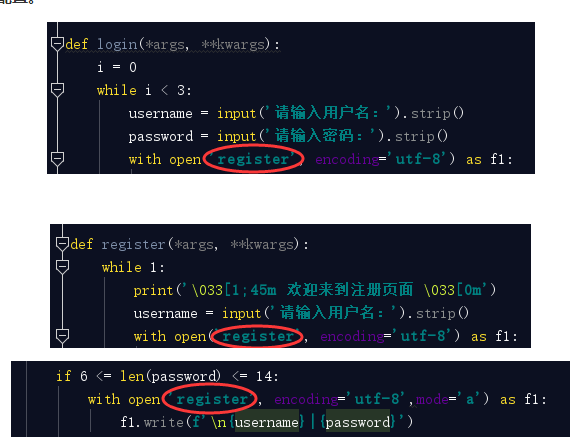
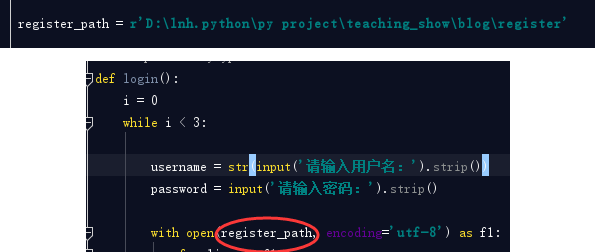
你專案中所有的有關檔案的操作出現幾處,都是直接寫的register相對路徑,如果說這個register登錄檔路徑改變了,或者你改變了register登錄檔的名稱,那麼相應的這幾處都需要一一更改,這樣其實你就是把程式碼寫死了,那麼怎麼解決? 我要統一相同的路徑,也就是統一相同的變數,在檔案的最上面寫一個變數指向register登錄檔的路徑,程式碼中如果需要這個路徑時,直接引用即可。


- 劃分檔案。

一個專案的函式不能只是這些,我們只是舉個例子,這個小作業函式都已經這麼多了,那麼要是一個具體的實際的專案,函式會非常多,所以我們應該將這些函式進行分類,然後分檔案而治。在這裡我劃分了以下幾個檔案:
settings.py: 配置檔案,就是放置一些專案中需要的靜態引數,比如檔案路徑,資料庫配置,軟體的預設設定等等
類似於我們作業中的這個:


common.py:公共元件檔案,這裡面放置一些我們常用的公共元件函式,並不是我們核心邏輯的函式,而更像是服務於整個程式中的公用的外掛,程式中需要即呼叫。比如我們程式中的裝飾器auth,有些函式是需要這個裝飾器認證的,但是有一些是不需要這個裝飾器認證的,它既是何處需要何處呼叫即可。比如還有密碼加密功能,序列化功能,日誌功能等這些功能都可以放在這裡。

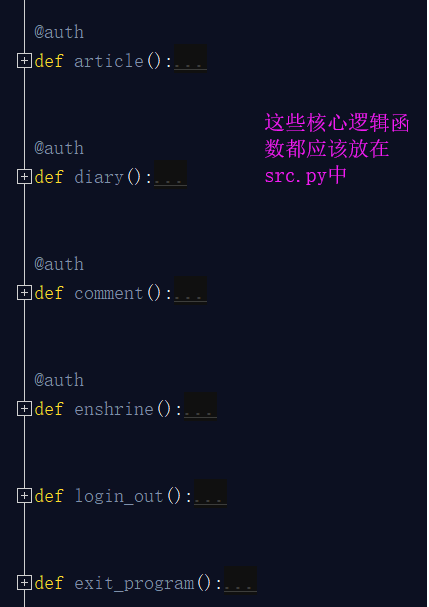
src.py:這個檔案主要存放的就是核心邏輯功能,你看你需要進行選擇的這些核心功能函式,都應該放在這個檔案中。
start.py:專案啟動檔案。你的專案需要有專門的檔案啟動,而不是在你的核心邏輯部分進行啟動的,有人對這個可能不太理解,我為什麼還要設定一個單獨的啟動檔案呢?你看你生活中使用的所有電器基本都一個單獨的啟動按鈕,汽車,熱水器,電視,等等等等,那麼為什麼他們會單獨設定一個啟動按鈕,而不是在一堆線路板或者內部隨便找一個地方開啟呢? 目的就是放在顯眼的位置,方便開啟。你想想你的專案這麼多py檔案,如果src檔案也有很多,那麼到底哪個檔案啟動整個專案,你還得一個一個去尋找,太麻煩了,這樣我把它單獨拿出來,就是方便開啟整個專案。
那麼我們寫的專案開啟整個專案的程式碼就是下面這段: 

你把這些放置到一個檔案中也可以,但是沒有必要,我們只需要一個命令或者一個開啟指令就行,就好比我們開啟電視只需要讓人很快的找到那個按鈕即可,對於按鈕後面的一些複雜的線路板,我們並不關心,所以我們要將上面這個段程式碼整合成一個函式,開啟專案的''按鈕''就是此函式的執行即可。
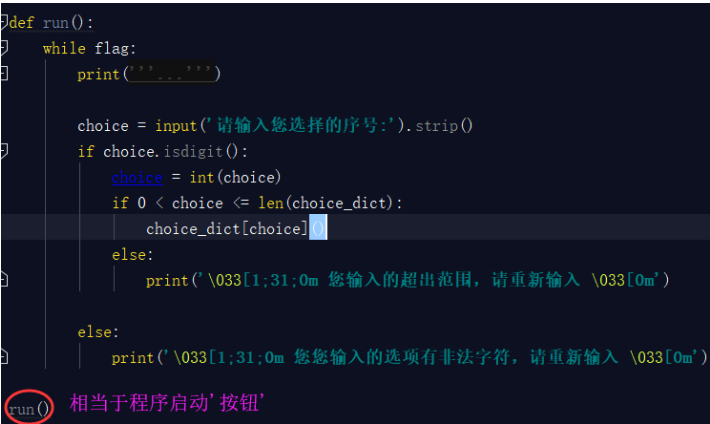
這個按鈕要放到啟動檔案start.py裡面。
除了以上這幾個py檔案之外還有幾個檔案,也是非常重要的:
類似於register檔案:這個檔案檔名不固定,register只是我們專案中用到的登錄檔,但是這種檔案就是儲存資料的檔案,類似於文字資料庫,那麼我們一些專案中的資料有的是從資料庫中獲取的,有些資料就是這種文字資料庫中獲取的,總之,你的專案中有時會遇到將一些資料儲存在檔案中,與程式互動的情況,所以我們要單獨設定這樣的檔案。
log檔案:log檔案顧名思義就是儲存log日誌的檔案。日誌我們一會就會講到,日誌主要是供開發人員使用。比如你專案中出現一些bug問題,比如開發人員對伺服器做的一些操作都會記錄到日誌中,以便開發者瀏覽,查詢。
至此,我們將這個作業原來的兩個檔案,合理的劃分成了6個檔案,但是還是有問題的,如果我們的專案很大,你的每一個部分相應的你一個檔案存不下的,比如你的src主邏輯檔案,函式很多,你是不是得分成:src1.py src2.py?
你的文字資料庫register這個只是一個登錄檔,如果你還有個人資訊表,記錄表呢? 如果是這樣,你的整個專案也是非常凌亂的: 
3. 劃分具體目錄
上面看著就非常亂了,那麼如何整改呢? 其實非常簡單,原來你就是30件衣服放在一個衣櫃裡,那麼你就得分類裝,放外套的地方,放內衣的地方,放佩飾的地方等等,但是突然你的衣服程式設計300件了,那一個衣櫃放不下,我就整多個櫃子,分別放置不同的衣物。所以我們這可以整多個資料夾,分別管理不同的物品,那麼標準版本的目錄結構就來了:
 為什麼要設計專案目錄結構?
為什麼要設計專案目錄結構?
"設計專案目錄結構",就和"程式碼編碼風格"一樣,屬於個人風格問題。對於這種風格上的規範,一直都存在兩種態度:
- 一類同學認為,這種個人風格問題"無關緊要"。理由是能讓程式work就好,風格問題根本不是問題。
- 另一類同學認為,規範化能更好的控制程式結構,讓程式具有更高的可讀性。
我是比較偏向於後者的,因為我是前一類同學思想行為下的直接受害者。我曾經維護過一個非常不好讀的專案,其實現的邏輯並不複雜,但是卻耗費了我非常長的時間去理解它想表達的意思。從此我個人對於提高專案可讀性、可維護性的要求就很高了。"專案目錄結構"其實也是屬於"可讀性和可維護性"的範疇,我們設計一個層次清晰的目錄結構,就是為了達到以下兩點:
- 可讀性高: 不熟悉這個專案的程式碼的人,一眼就能看懂目錄結構,知道程式啟動指令碼是哪個,測試目錄在哪兒,配置檔案在哪兒等等。從而非常快速的瞭解這個專案。
- 可維護性高: 定義好組織規則後,維護者就能很明確地知道,新增的哪個檔案和程式碼應該放在什麼目錄之下。這個好處是,隨著時間的推移,程式碼/配置的規模增加,專案結構不會混亂,仍然能夠組織良好。
所以,我認為,保持一個層次清晰的目錄結構是有必要的。更何況組織一個良好的工程目錄,其實是一件很簡單的事兒。

上面那個圖片就是較好的目錄結構。
二. 按照專案目錄結構,規範部落格園系統
接下來,我就帶領大家把具體的程式碼寫入對應的檔案中,並且將此專案啟動起來,一定要跟著我的步驟一步一步去執行:
- 配置start.py檔案
我們首先要配置啟動檔案,啟動檔案很簡答就是將專案的啟動執行放置start.py檔案中,執行start.py檔案可以成功啟動專案即可。 那麼專案的啟動就是這個指令run() 我們把這個run()放置此檔案中不就行了?

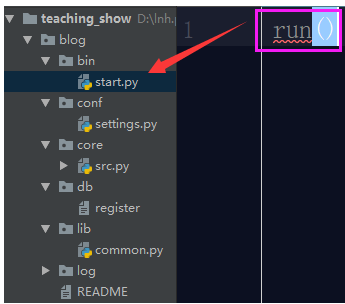
這樣你能執行這個專案麼?肯定是不可以呀,你的starts.py根本就找不到run這個變數,肯定是會報錯的。
NameError: name 'run' is not defined 本檔案肯定是找不到run這個變數也就是函式名的,不過這個難不倒我們,我們剛學了模組, 另個一檔案的內容我們可以引用過來。但是你發現import run 或者 from src import run 都是報錯的。為什麼呢? 騷年,遇到報錯不要慌!我們說過你的模組之所以可以引用,那是因為你的模組肯定在這個三個地方:記憶體,內建,sys.path裡面,那麼core在記憶體中肯定是沒有的,也不是內建,而且sys.path也不可能有,因為sys.path只會將你當前的目錄(bin)載入到記憶體,所以你剛才那麼引用肯定是有問題的,那麼如何解決?記憶體,內建你是左右不了的,你只能將core的路徑新增到sys.path中,這樣就可以了。
import sys
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\core')
from src import run
run()這樣雖然解決了,但是你不覺得有問題麼?你現在從這個start檔案需要引用src檔案,那麼你需要手動的將src的工作目錄新增到sys.path中,那麼有沒有可能你會引用到其他的檔案?比如你的專案中可能需要引用conf,lib等其他py檔案,那麼在每次引用之前,或者是開啟專案時,全部把他們新增到sys.path中麼?
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\core')
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\conf')
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\db')
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog\lib')這樣是不是太麻煩了? 我們應該怎麼做?我們應該把專案的工作路徑新增到sys.path中,用一個例子說明:你想找張三,李四,王五,趙六等人,這些人全部都在一棟樓比如在匯德商廈,那麼我就告訴你匯德商廈的位置:北京昌平區沙河鎮匯德商廈。 你到了匯德商廈你在找具體這些人就可以了。所以我們只要將這個blog專案的工作目錄新增到sys.path中,這樣無論這個專案中的任意一個檔案引用專案中哪個檔案,就都可以找到了。所以:
import sys
sys.path.append(r'D:\lnh.python\py project\teaching_show\blog')
from core.src import run
run()上面還是差一點點,你這樣寫你的blog的路徑就寫死了,你的專案不可能只在你的電腦上,專案是共同開發的,你的專案肯定會出現在別人電腦上,那麼你的路徑就是問題了,在你的電腦上你的blog專案的路徑是上面所寫的,如果移植到別人電腦上,他的路徑不可能與你的路徑相同, 這樣就會報錯了,所以我們這個路徑要動態獲取,不能寫死,所以這樣就解決了:

import sys
import os
# sys.path.append(r'D:\lnh.python\py project\teaching_show\blog')
print(os.path.dirname(__file__))
# 獲取本檔案的絕對路徑 # D:/lnh.python/py project/teaching_show/blog/bin
print(os.path.dirname(os.path.dirname(__file__)))
# 獲取父級目錄也就是blog的絕對路徑 # D:/lnh.python/py project/teaching_show/blog
BATH_DIR = os.path.dirname(os.path.dirname(__file__))
sys.path.append(BATH_DIR)
from core.src import run
run()
那麼還差一個小問題,這個starts檔案可以當做指令碼檔案進行直接啟動,如果是作為模組,被別人引用的話,按照這麼寫,也是可以啟動整個程式的,這樣合理麼?這樣是不合理的,作為啟動檔案,是不可以被別人引用啟動的,所以我們此時要想到 __name__了:
import sys
import os
# sys.path.append(r'D:\lnh.python\py project\teaching_show\blog')
# print(os.path.dirname(__file__))
# 獲取本檔案的絕對路徑 # D:/lnh.python/py project/teaching_show/blog/bin
# print(os.path.dirname(os.path.dirname(__file__)))
# 獲取父級目錄也就是blog的絕對路徑 # D:/lnh.python/py project/teaching_show/blog
BATH_DIR = os.path.dirname(os.path.dirname(__file__))
sys.path.append(BATH_DIR)
from core.src import run
if __name__ == '__main__':
run()
這樣,我們的starts啟動檔案就已經配置成功了。以後只要我們通過starts檔案啟動整個程式,它會先將整個專案的工作目錄新增到sys.path中,然後在啟動程式,這樣我整個專案裡面的任何的py檔案想引用專案中的其他py檔案,都是你可以的了。
- 配置settings.py檔案。
接下來,我們就會將我們專案中的靜態路徑,資料庫的連線設定等等檔案放置在settings檔案中。
我們看一下,你的主邏輯src中有這樣幾個變數:
status_dic = {
'username': None,
'status': False,
}
flag = True
register_path = r'D:\lnh.python\py project\teaching_show\blog\register'
我們是不是應該把這幾個變數都放置在settings檔案中呢?不是!setttings檔案叫做配置檔案,其實也叫做配置靜態檔案,什麼叫靜態? 靜態就是一般不會輕易改變的,但是對於上面的程式碼status_dic ,flag這兩個變數,由於在使用這個系統時會時長變化,所以不建議將這個兩個變數放置在settings配置檔案中,只需要將register_path放置進去就可以。
register_path = r'D:\lnh.python\py project\teaching_show\blog\register'

但是你將這個變數放置在settings.py之後,你的程式啟動起來是有問題,為什麼?
with open(register_path, encoding='utf-8') as f1:
NameError: name 'register_path' is not defined因為主邏輯src中找不到register_path這個路徑了,所以會報錯,那麼我們解決方式就是在src主邏輯中引用settings.py檔案中的register_path就可以了。
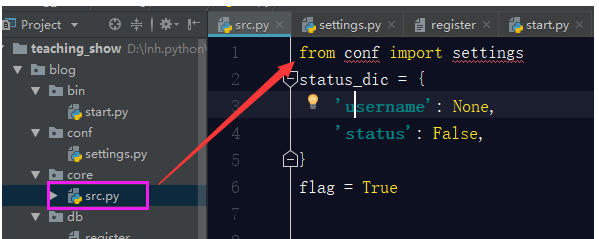
這裡引發一個問題:為什麼你這樣寫就可以直接引用settings檔案呢?我們在starts檔案中已經說了,剛已啟動blog檔案時,我們手動將blog的路徑新增到sys.path中了,這就意味著,我在整個專案中的任何py檔案,都可以引用到blog專案目錄下面的任何目錄:bin,conf,core,db,lib,log這幾個,所以,剛才我們引用settings檔案才是可以的。
- 配置common.py檔案
接下來,我們要配置我們的公共元件檔案,在我們這個專案中,裝飾器就是公共元件的工具,我們要把裝飾器這個工具配置到common.py檔案中。先把裝飾器程式碼剪下到common.py檔案中。這樣直接粘過來,是有各種問題的:
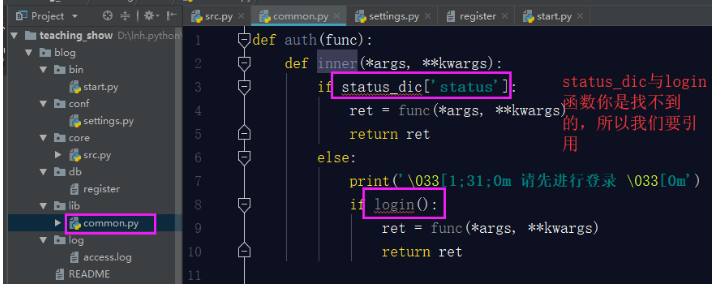

所以我們要在common.py檔案中引入src檔案的這兩個變數。

可是你的src檔案中使用了auth裝飾器,此時你的auth裝飾器已經移動位置了,所以你要在src檔案中引用auth裝飾器,這樣才可以使用上。
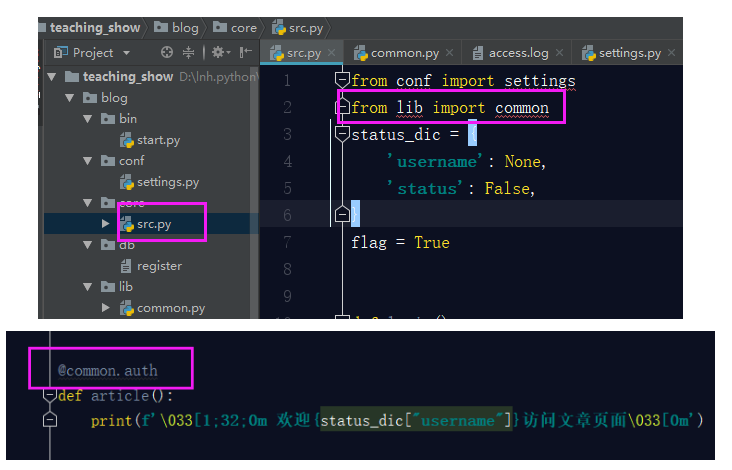
OK,這樣你就算是將你之前寫的模擬部落格園登入的作業按照規範化目錄結構合理的完善完成了,最後還有一個關於README文件的書寫。
關於README的內容
這個我覺得是每個專案都應該有的一個檔案,目的是能簡要描述該專案的資訊,讓讀者快速瞭解這個專案。
它需要說明以下幾個事項:
- 軟體定位,軟體的基本功能。
- 執行程式碼的方法: 安裝環境、啟動命令等。
- 簡要的使用說明。
- 程式碼目錄結構說明,更詳細點可以說明軟體的基本原理。
- 常見問題說明。
我覺得有以上幾點是比較好的一個README。在軟體開發初期,由於開發過程中以上內容可能不明確或者發生變化,並不是一定要在一開始就將所有資訊都補全。但是在專案完結的時候,是需要撰寫這樣的一個文件的。
可以參考Redis原始碼中Readme的寫法,這裡面簡潔但是清晰的描述了Redis功能和原始碼結構