
一看就懂的K近鄰演算法(KNN),K-D樹,並實現手寫數字識別!
1. 什麼是KNN
1.1 KNN的通俗解釋
何謂K近鄰演算法,即K-Nearest Neighbor algorithm,簡稱KNN演算法,單從名字來猜想,可以簡單粗暴的認為是:K個最近的鄰居,當K=1時,演算法便成了最近鄰演算法,即尋找最近的那個鄰居。
用官方的話來說,所謂K近鄰演算法,即是給定一個訓練資料集,對新的輸入例項,在訓練資料集中找到與該例項最鄰近的K個例項(也就是上面所說的K個鄰居),這K個例項的多數屬於某個類,就把該輸入例項分類到這個類中。
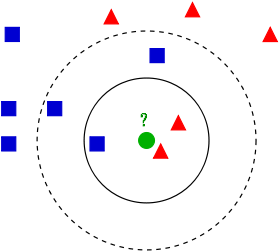
如上圖所示,有兩類不同的樣本資料,分別用藍色的小正方形和紅色的小三角形表示,而圖正中間的那個綠色的圓所標示的資料則是待分類的資料。也就是說,現在,我們不知道中間那個綠色的資料是從屬於哪一類(藍色小正方形or紅色小三角形),KNN就是解決這個問題的。
如果K=3,綠色圓點的最近的3個鄰居是2個紅色小三角形和1個藍色小正方形,少數從屬於多數,基於統計的方法,判定綠色的這個待分類點屬於紅色的三角形一類。
如果K=5,綠色圓點的最近的5個鄰居是2個紅色三角形和3個藍色的正方形,還是少數從屬於多數,基於統計的方法,判定綠色的這個待分類點屬於藍色的正方形一類。
於此我們看到,當無法判定當前待分類點是從屬於已知分類中的哪一類時,我們可以依據統計學的理論看它所處的位置特徵,衡量它周圍鄰居的權重,而把它歸為(或分配)到權重更大的那一類。這就是K近鄰演算法的核心思想。
1.2 近鄰的距離度量
我們看到,K近鄰演算法的核心在於找到例項點的鄰居,這個時候,問題就接踵而至了,如何找到鄰居,鄰居的判定標準是什麼,用什麼來度量。這一系列問題便是下面要講的距離度量表示法。
有哪些距離度量的表示法(普及知識點,可以跳過):
歐氏距離,最常見的兩點之間或多點之間的距離表示法,又稱之為歐幾里得度量,它定義於歐幾里得空間中,如點 x = (x1,...,xn) 和 y = (y1,...,yn) 之間的距離為:
\[d(x,y)=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+...+(x_n-y_n)^2}=\sqrt{\sum_{i=1}^{n}(x_i-y_i)^2}\]
二維平面上兩點a(x1,y1)與b(x2,y2)間的歐氏距離:
\[d_{12}=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}\]
三維空間兩點a(x1,y1,z1)與b(x2,y2,z2)間的歐氏距離:
\[d_{12}=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2+(z_1-z_2)^2}\]
兩個n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的歐氏距離:
\[d_{12}=\sqrt{\sum_{k=1}^{n}(x_{1k}-x_{2k})^2}\]
也可以用表示成向量運算的形式:
\[d_{12}=\sqrt{(a-b)(a-b)^T}\]
曼哈頓距離,我們可以定義曼哈頓距離的正式意義為L1-距離或城市區塊距離,也就是在歐幾里得空間的固定直角座標系上兩點所形成的線段對軸產生的投影的距離總和。例如在平面上,座標(x1, y1)的點P1與座標(x2, y2)的點P2的曼哈頓距離為:\(|x_1-x_2|+|y_1-y_2|\),要注意的是,曼哈頓距離依賴座標系統的轉度,而非系統在座標軸上的平移或對映。
通俗來講,想象你在曼哈頓要從一個十字路口開車到另外一個十字路口,駕駛距離是兩點間的直線距離嗎?顯然不是,除非你能穿越大樓。而實際駕駛距離就是這個“曼哈頓距離”,此即曼哈頓距離名稱的來源, 同時,曼哈頓距離也稱為城市街區距離(City Block distance)。
二維平面兩點a(x1,y1)與b(x2,y2)間的曼哈頓距離
\[d_{12}=|x_1-x_2|+|y_1-y_2|\]
兩個n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的曼哈頓距離
\[d_{12}=\sum_{k=1}^{n}|x_{1k}-x_{2k}|\]
切比雪夫距離,若二個向量或二個點p 、and q,其座標分別為Pi及qi,則兩者之間的切比雪夫距離定義如下:
\[D_{Chebyshev}(p,q)=max_i(|p_i-q_i|)\]
這也等於以下Lp度量的極值:\(\lim_{x \to \infty}(\sum_{i=1}^{n}|p_i-q_i|^k)^{1/k}\),因此切比雪夫距離也稱為L∞度量。
以數學的觀點來看,切比雪夫距離是由一致範數(uniform norm)(或稱為上確界範數)所衍生的度量,也是超凸度量(injective metric space)的一種。
在平面幾何中,若二點p及q的直角座標系座標為(x1,y1)及(x2,y2),則切比雪夫距離為:
\[D_{Chess}=max(|x_2-x_1|,|y_2-y_1|)\]
玩過國際象棋的朋友或許知道,國王走一步能夠移動到相鄰的8個方格中的任意一個。那麼國王從格子(x1,y1)走到格子(x2,y2)最少需要多少步?。你會發現最少步數總是max( | x2-x1 | , | y2-y1 | ) 步 。有一種類似的一種距離度量方法叫切比雪夫距離。
二維平面兩點a(x1,y1)與b(x2,y2)間的切比雪夫距離 :
\[d_{12}=max(|x_2-x_1|,|y_2-y_1|)\]
兩個n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的切比雪夫距離:
\[d_{12}=max_i(|x_{1i}-x_{2i}|)\]
這個公式的另一種等價形式是
\[d_{12}=lim_{k\to\infin}(\sum_{i=1}^{n}|x_{1i}-x_{2i}|^k)^{1/k}\]
閔可夫斯基距離(Minkowski Distance),閔氏距離不是一種距離,而是一組距離的定義。
兩個n維變數a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的閔可夫斯基距離定義為:
\[d_{12}=\sqrt[p]{\sum_{k=1}^{n}|x_{1k}-x_{2k}|^p}\]
其中p是一個變引數。
當p=1時,就是曼哈頓距離
當p=2時,就是歐氏距離
當p→∞時,就是切比雪夫距離
根據變引數的不同,閔氏距離可以表示一類的距離。標準化歐氏距離,標準化歐氏距離是針對簡單歐氏距離的缺點而作的一種改進方案。標準歐氏距離的思路:既然資料各維分量的分佈不一樣,那先將各個分量都“標準化”到均值、方差相等。至於均值和方差標準化到多少,先複習點統計學知識。
假設樣本集X的數學期望或均值(mean)為m,標準差(standard deviation,方差開根)為s,那麼X的“標準化變數”X*表示為:(X-m)/s,而且標準化變數的數學期望為0,方差為1。
即,樣本集的標準化過程(standardization)用公式描述就是:\[X^*=\frac{X-m}{s}\]
標準化後的值 = ( 標準化前的值 - 分量的均值 ) /分量的標準差
經過簡單的推導就可以得到兩個n維向量a(x11,x12,…,x1n)與 b(x21,x22,…,x2n)間的標準化歐氏距離的公式:\[d_{12}=\sqrt{\sum_{k=1}^{n}(\frac{x_{1k}-x_{2k}}{s_k})^2}\]
馬氏距離
有M個樣本向量X1~Xm,協方差矩陣記為S,均值記為向量μ,則其中樣本向量X到u的馬氏距離表示為:
\[D(X)=\sqrt{(X-u)^TS^{-1}(X_i-X_j)}\]
若協方差矩陣是單位矩陣(各個樣本向量之間獨立同分布),則公式就成了,也就是歐氏距離了:
\[D(X_i,X_j)=\sqrt{(X_i-X_j)^T(X_i-X_j)}\]
若協方差矩陣是對角矩陣,公式變成了標準化歐氏距離。
馬氏距離的優缺點:量綱無關,排除變數之間的相關性的干擾。
巴氏距離
在統計中,巴氏距離距離測量兩個離散或連續概率分佈的相似性。它與衡量兩個統計樣品或種群之間的重疊量的巴氏距離係數密切相關。巴氏距離距離和巴氏距離係數以20世紀30年代曾在印度統計研究所工作的一個統計學家A. Bhattacharya命名。同時,Bhattacharyya係數可以被用來確定兩個樣本被認為相對接近的,它是用來測量中的類分類的可分離性。
對於離散概率分佈 p和q在同一域 X,它被定義為:
\[D_B(p,q)=-ln(BC(p,q))\]
其中:
\[BC(p,q)=\sum_{x\in_{}X}\sqrt{p(x)q(x)}\]
是Bhattacharyya係數。
漢明距離
兩個等長字串s1與s2之間的漢明距離定義為將其中一個變為另外一個所需要作的最小替換次數。例如字串“1111”與“1001”之間的漢明距離為2。應用:資訊編碼(為了增強容錯性,應使得編碼間的最小漢明距離儘可能大)。
夾角餘弦
幾何中夾角餘弦可用來衡量兩個向量方向的差異,機器學習中借用這一概念來衡量樣本向量之間的差異。
在二維空間中向量A(x1,y1)與向量B(x2,y2)的夾角餘弦公式:
\[cos\theta=\frac{x_1x_2+y_1y_2}{\sqrt{x_1^2+y_1^2}\sqrt{x_2^2+y_2^2}}\]
兩個n維樣本點a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夾角餘弦:
\[cos\theta=\frac{a*b}{|a||b|}\]
夾角餘弦取值範圍為[-1,1]。夾角餘弦越大表示兩個向量的夾角越小,夾角餘弦越小表示兩向量的夾角越大。當兩個向量的方向重合時夾角餘弦取最大值1,當兩個向量的方向完全相反夾角餘弦取最小值-1。
傑卡德相似係數
兩個集合A和B的交集元素在A,B的並集中所佔的比例,稱為兩個集合的傑卡德相似係數,用符號J(A,B)表示。傑卡德相似係數是衡量兩個集合的相似度一種指標。
\[J(A,B)=\frac{|A\cap_{}B|}{|A\cup_{}B|}\]
與傑卡德相似係數相反的概念是傑卡德距離:
\[J_{\delta}(A,B)=1-J(A,B)=\frac{|A\cup_{}B|-|A\cap_{}B|}{|A\cup_{}B|}\]
皮爾遜係數
在統計學中,皮爾遜積矩相關係數用於度量兩個變數X和Y之間的相關(線性相關),其值介於-1與1之間。通常情況下通過以下取值範圍判斷變數的相關強度:
0.8-1.0 極強相關
0.6-0.8 強相關
0.4-0.6 中等程度相關
0.2-0.4 弱相關
0.0-0.2 極弱相關或無相關
簡單說來,各種“距離”的應用場景簡單概括為,
- 空間:歐氏距離,
- 路徑:曼哈頓距離,國際象棋國王:切比雪夫距離,
- 以上三種的統一形式:閔可夫斯基距離,
- 加權:標準化歐氏距離,
- 排除量綱和依存:馬氏距離,
- 向量差距:夾角餘弦,
- 編碼差別:漢明距離,
- 集合近似度:傑卡德類似係數與距離,
- 相關:相關係數與相關距離。
1.3 K值選擇
- 如果選擇較小的K值,就相當於用較小的領域中的訓練例項進行預測,“學習”近似誤差會減小,只有與輸入例項較近或相似的訓練例項才會對預測結果起作用,與此同時帶來的問題是“學習”的估計誤差會增大,換句話說,K值的減小就意味著整體模型變得複雜,容易發生過擬合;
- 如果選擇較大的K值,就相當於用較大領域中的訓練例項進行預測,其優點是可以減少學習的估計誤差,但缺點是學習的近似誤差會增大。這時候,與輸入例項較遠(不相似的)訓練例項也會對預測器作用,使預測發生錯誤,且K值的增大就意味著整體的模型變得簡單。
- K=N,則完全不足取,因為此時無論輸入例項是什麼,都只是簡單的預測它屬於在訓練例項中最多的累,模型過於簡單,忽略了訓練例項中大量有用資訊。
在實際應用中,K值一般取一個比較小的數值,例如採用交叉驗證法(簡單來說,就是一部分樣本做訓練集,一部分做測試集)來選擇最優的K值。
1.4 KNN最近鄰分類演算法的過程
- 計算測試樣本和訓練樣本中每個樣本點的距離(常見的距離度量有歐式距離,馬氏距離等);
- 對上面所有的距離值進行排序;
- 選前 k 個最小距離的樣本;
- 根據這 k 個樣本的標籤進行投票,得到最後的分類類別;
2. KDD的實現:KD樹
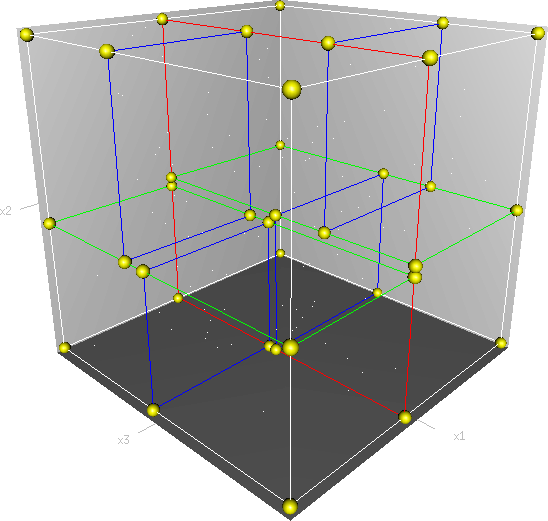
Kd-樹是K-dimension tree的縮寫,是對資料點在k維空間(如二維(x,y),三維(x,y,z),k維(x1,y,z..))中劃分的一種資料結構,主要應用於多維空間關鍵資料的搜尋(如:範圍搜尋和最近鄰搜尋)。本質上說,Kd-樹就是一種平衡二叉樹。
首先必須搞清楚的是,k-d樹是一種空間劃分樹,說白了,就是把整個空間劃分為特定的幾個部分,然後在特定空間的部分內進行相關搜尋操作。想像一個三維(多維有點為難你的想象力了)空間,kd樹按照一定的劃分規則把這個三維空間劃分了多個空間,如下圖所示:
2.1 構建KD樹
kd樹構建的虛擬碼如下圖所示:

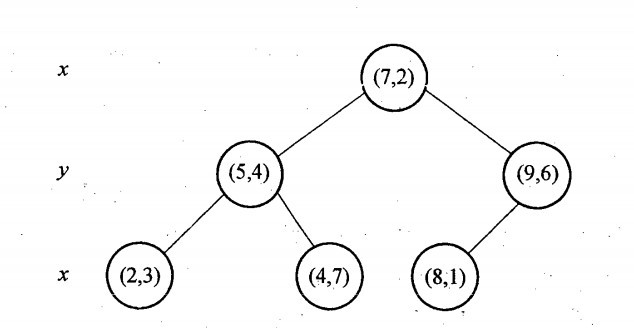
再舉一個簡單直觀的例項來介紹k-d樹構建演算法。假設有6個二維資料點{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},資料點位於二維空間內,如下圖所示。為了能有效的找到最近鄰,k-d樹採用分而治之的思想,即將整個空間劃分為幾個小部分,首先,粗黑線將空間一分為二,然後在兩個子空間中,細黑直線又將整個空間劃分為四部分,最後虛黑直線將這四部分進一步劃分。
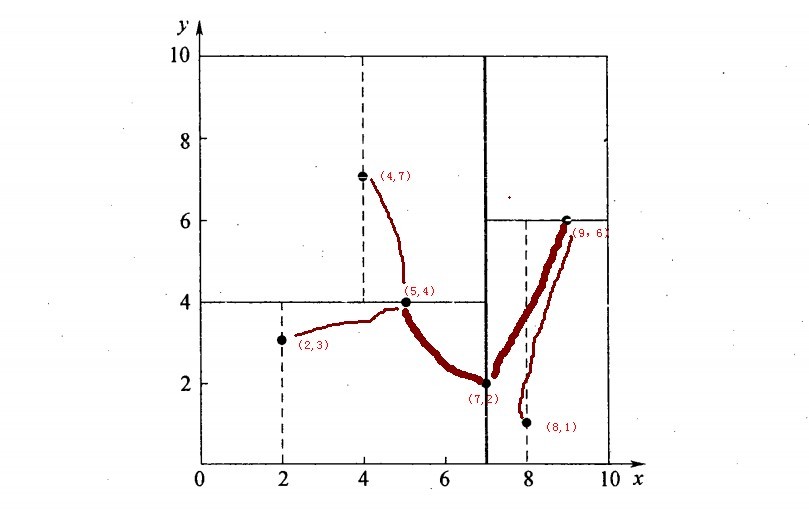
6個二維資料點{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}構建kd樹的具體步驟為:
- 確定:split域=x。具體是:6個數據點在x,y維度上的資料方差分別為39,28.63,所以在x軸上方差更大,故split域值為x;
- 確定:Node-data = (7,2)。具體是:根據x維上的值將資料排序,6個數據的中值(所謂中值,即中間大小的值)為7,所以Node-data域位資料點(7,2)。這樣,該節點的分割超平面就是通過(7,2)並垂直於:split=x軸的直線x=7;
- 確定:左子空間和右子空間。具體是:分割超平面x=7將整個空間分為兩部分:x<=7的部分為左子空間,包含3個節點={(2,3),(5,4),(4,7)};另一部分為右子空間,包含2個節點={(9,6),(8,1)};
- 如上演算法所述,kd樹的構建是一個遞迴過程,我們對左子空間和右子空間內的資料重複根節點的過程就可以得到一級子節點(5,4)和(9,6),同時將空間和資料集進一步細分,如此往復直到空間中只包含一個數據點。
與此同時,經過對上面所示的空間劃分之後,我們可以看出,點(7,2)可以為根結點,從根結點出發的兩條紅粗斜線指向的(5,4)和(9,6)則為根結點的左右子結點,而(2,3),(4,7)則為(5,4)的左右孩子(通過兩條細紅斜線相連),最後,(8,1)為(9,6)的左孩子(通過細紅斜線相連)。如此,便形成了下面這樣一棵k-d樹:
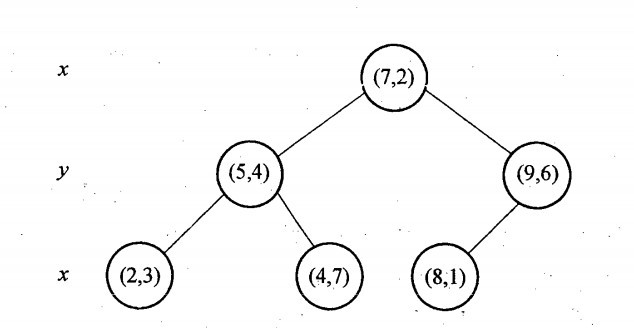
對於n個例項的k維資料來說,建立kd-tree的時間複雜度為O(knlogn)。
k-d樹演算法可以分為兩大部分,除了上部分有關k-d樹本身這種資料結構建立的演算法,另一部分是在建立的k-d樹上各種諸如插入,刪除,查詢(最鄰近查詢)等操作涉及的演算法。下面,咱們依次來看kd樹的插入、刪除、查詢操作。
2.2 KD樹的插入
元素插入到一個K-D樹的方法和二叉檢索樹類似。本質上,在偶數層比較x座標值,而在奇數層比較y座標值。當我們到達了樹的底部,(也就是當一個空指標出現),我們也就找到了結點將要插入的位置。生成的K-D樹的形狀依賴於結點插入時的順序。給定N個點,其中一個結點插入和檢索的平均代價是O(log2N)。
插入的過程如下:
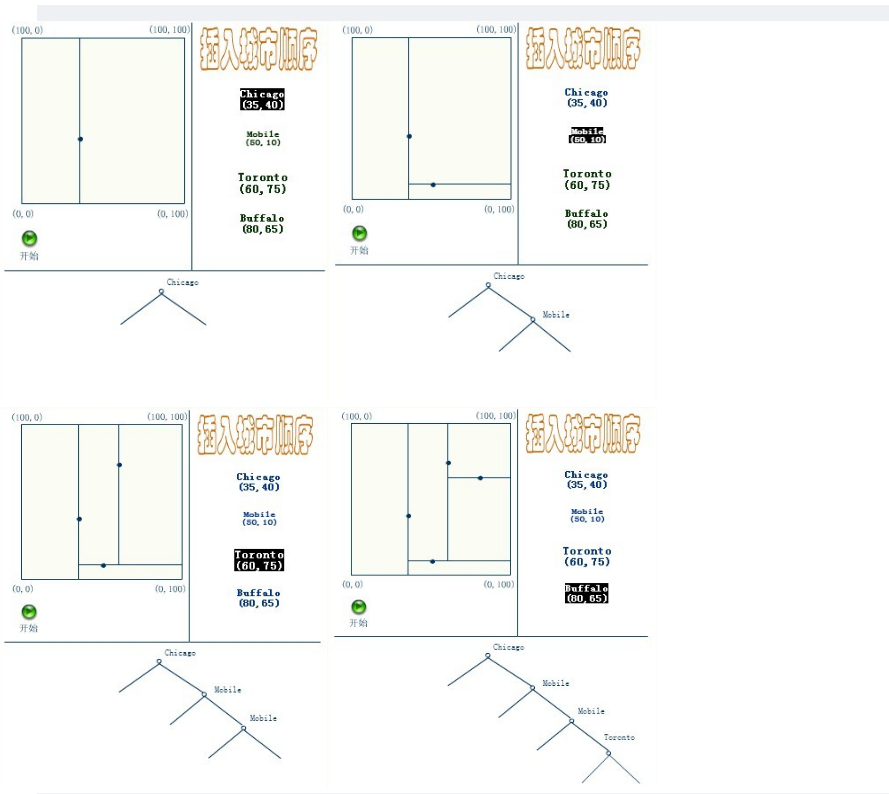
應該清楚,這裡描述的插入過程中,每個結點將其所在的平面分割成兩部分。因比,Chicago 將平面上所有結點分成兩部分,一部分所有的結點x座標值小於35,另一部分結點的x座標值大於或等於35。同樣Mobile將所有x座標值大於35的結點以分成兩部分,一部分結點的Y座標值是小於10,另一部分結點的Y座標值大於或等於10。後面的Toronto、Buffalo也按照一分為二的規則繼續劃分。
2.3 KD樹的刪除
KD樹的刪除可以用遞迴程式來實現。我們假設希望從K-D樹中刪除結點(a,b)。如果(a,b)的兩個子樹都為空,則用空樹來代替(a,b)。否則,在(a,b)的子樹中尋找一個合適的結點來代替它,譬如(c,d),則遞迴地從K-D樹中刪除(c,d)。一旦(c,d)已經被刪除,則用(c,d)代替(a,b)。假設(a,b)是一個X識別器,那麼,它得替代節點要麼是(a,b)左子樹中的X座標最大值的結點,要麼是(a,b)右子樹中x座標最小值的結點。
下面來舉一個實際的例子(來源:中國地質大學電子課件,原課件錯誤已經在下文中訂正),如下圖所示,原始影象及對應的kd樹,現在要刪除圖中的A結點,請看一系列刪除步驟:
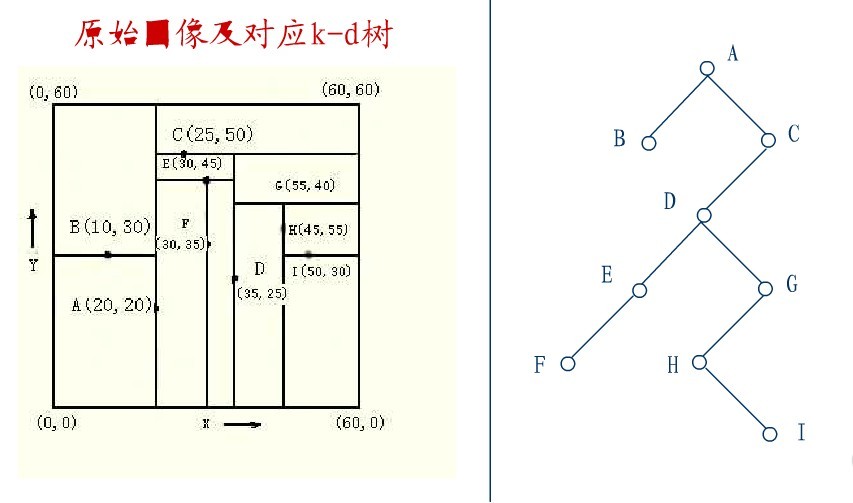
要刪除上圖中結點A,選擇結點A的右子樹中X座標值最小的結點,這裡是C,C成為根,如下圖:
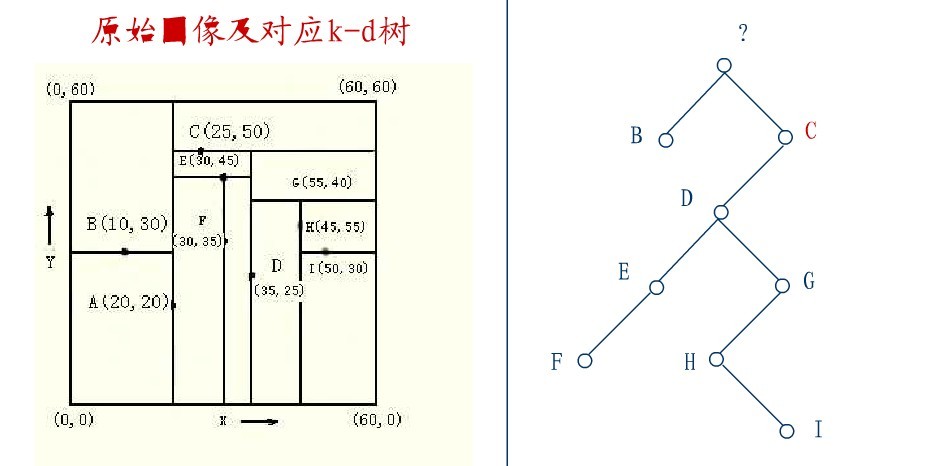
從C的右子樹中找出一個結點代替先前C的位置,
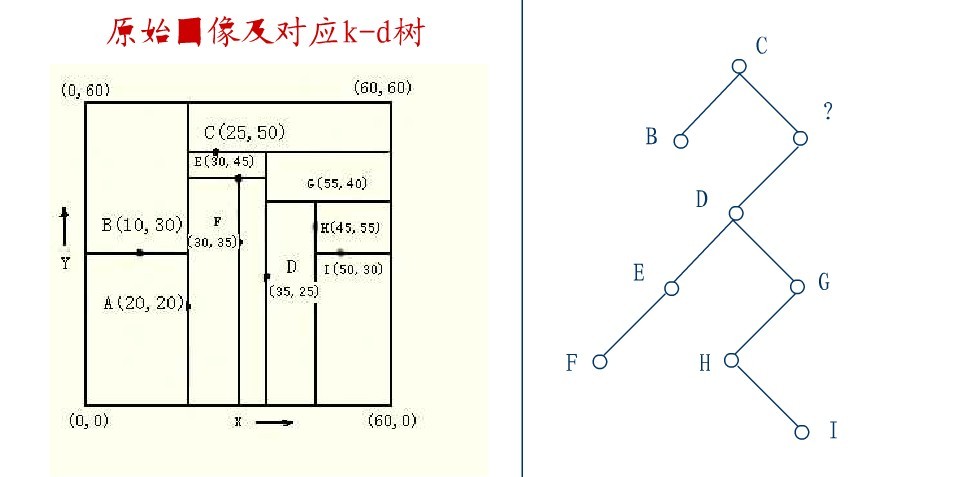
這裡是D,並將D的左子樹轉為它的右子樹,D代替先前C的位置,如下圖:
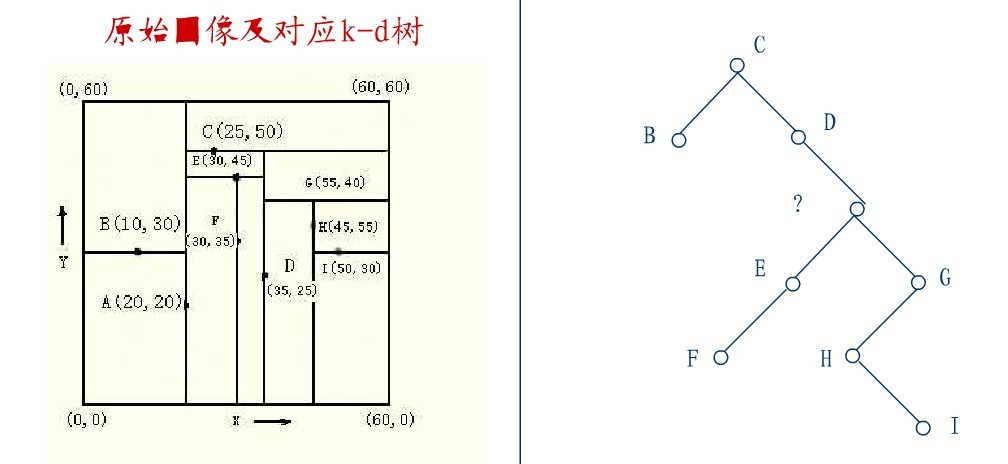
在D的新右子樹中,找X座標最小的結點,這裡為H,H代替D的位置,
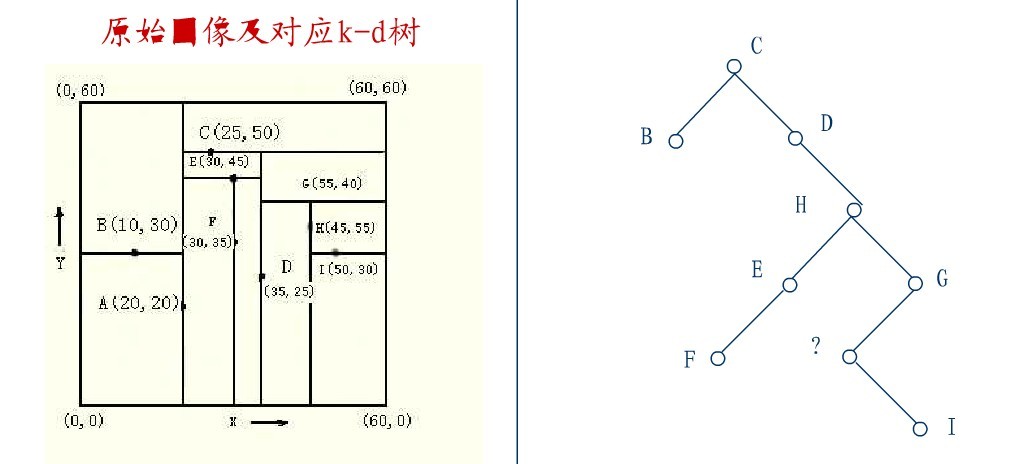
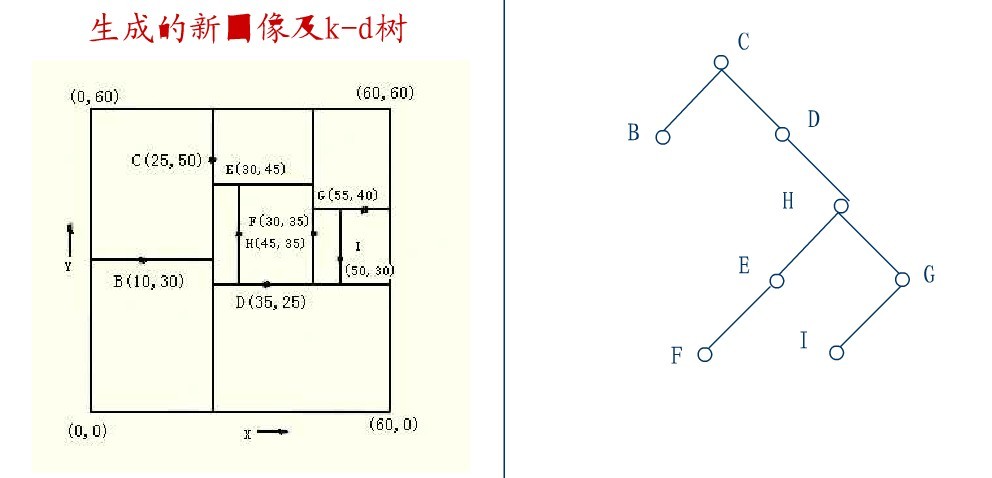
在D的右子樹中找到一個Y座標最小的值,這裡是I,將I代替原先H的位置,從而A結點從圖中順利刪除,如下圖所示:
從K-D樹中刪除一個結點是代價很高的,很清楚刪除子樹的根受到子樹中結點個數的限制。用TPL(T)表示樹T總的路徑長度。可看出樹中子樹大小的總和為TPL(T)+N。 以隨機方式插入N個點形成樹的TPL是O(N*log2N),這就意味著從一個隨機形成的K-D樹中刪除一個隨機選取的結點平均代價的上界是O(log2N) 。
2.4 KD樹的最近鄰搜尋演算法
k-d樹查詢演算法的虛擬碼如下所示:
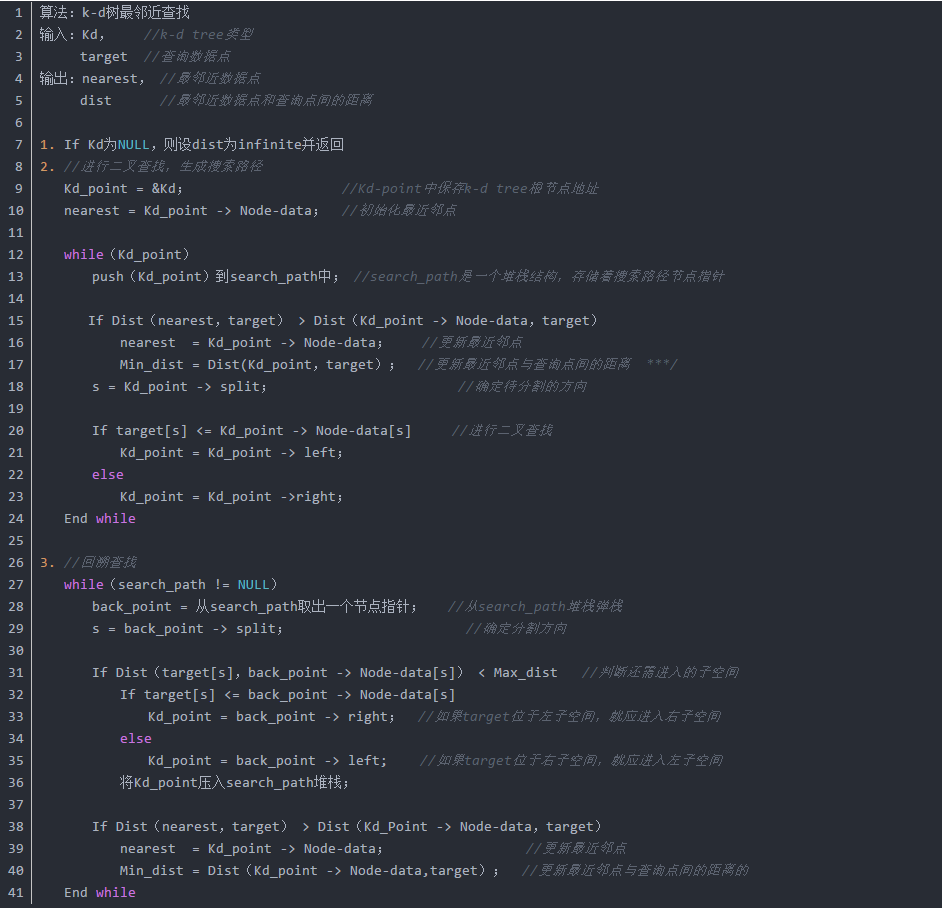
我寫了一個遞迴版本的二維kd tree的搜尋函式你對比的看看:
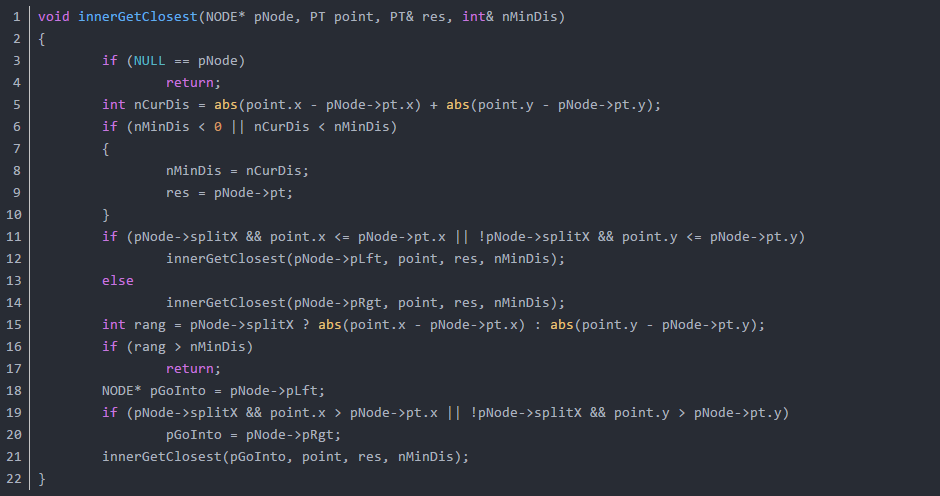
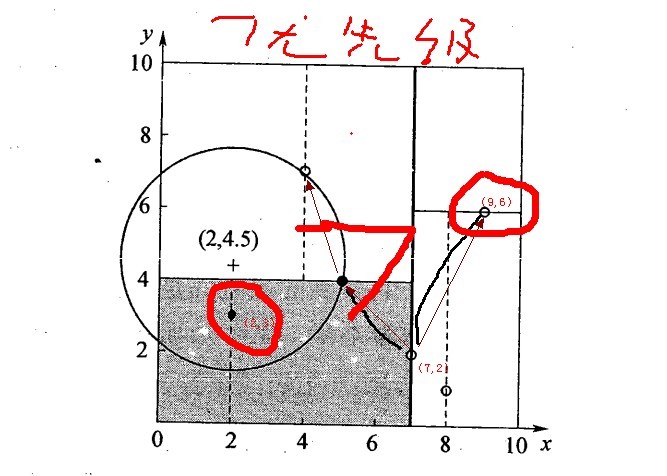
舉例
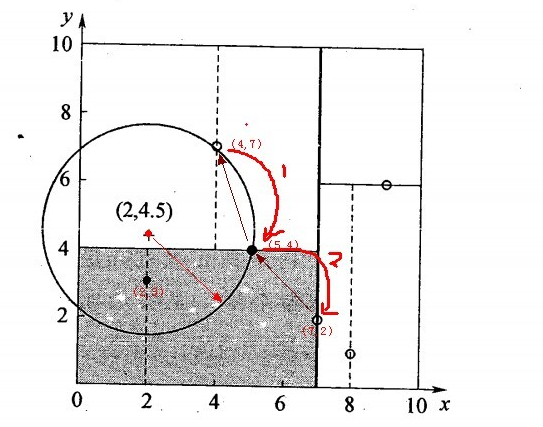
星號表示要查詢的點查詢點(2,4.5)。通過二叉搜尋,順著搜尋路徑很快就能找到最鄰近的近似點。而找到的葉子節點並不一定就是最鄰近的,最鄰近肯定距離查詢點更近,應該位於以查詢點為圓心且通過葉子節點的圓域內。為了找到真正的最近鄰,還需要進行相關的‘回溯'操作。也就是說,演算法首先沿搜尋路徑反向查詢是否有距離查詢點更近的資料點。
- 二叉樹搜尋:先從(7,2)查詢到(5,4)節點,在進行查詢時是由y = 4為分割超平面的,由於查詢點為y值為4.5,因此進入右子空間查詢到(4,7),形成搜尋路徑<(7,2),(5,4),(4,7)>,但(4,7)與目標查詢點的距離為3.202,而(5,4)與查詢點之間的距離為3.041,所以(5,4)為查詢點的最近點;
- 回溯查詢:以(2,4.5)為圓心,以3.041為半徑作圓,如下圖所示。可見該圓和y = 4超平面交割,所以需要進入(5,4)左子空間進行查詢,也就是將(2,3)節點加入搜尋路徑中得<(7,2),(2,3)>;於是接著搜尋至(2,3)葉子節點,(2,3)距離(2,4.5)比(5,4)要近,所以最近鄰點更新為(2,3),最近距離更新為1.5;
- 回溯查詢至(5,4),直到最後回溯到根結點(7,2)的時候,以(2,4.5)為圓心1.5為半徑作圓,並不和x = 7分割超平面交割,如下圖所示。至此,搜尋路徑回溯完,返回最近鄰點(2,3),最近距離1.5。
2.5 kd樹近鄰搜尋演算法的改進:BBF演算法
例項點是隨機分佈的,那麼kd樹搜尋的平均計算複雜度是O(logN),這裡的N是訓練例項樹。所以說,kd樹更適用於訓練例項數遠大於空間維數時的k近鄰搜尋,當空間維數接近訓練例項數時,它的效率會迅速下降,一降降到“解放前”:線性掃描的速度。
也正因為上述k最近鄰搜尋演算法的第4個步驟中的所述:“回退到根結點時,搜尋結束”,每個最近鄰點的查詢比較完成過程最終都要回退到根結點而結束,而導致了許多不必要回溯訪問和比較到的結點,這些多餘的損耗在高維度資料查詢的時候,搜尋效率將變得相當之地下,那有什麼辦法可以改進這個原始的kd樹最近鄰搜尋演算法呢?
從上述標準的kd樹查詢過程可以看出其搜尋過程中的“回溯”是由“查詢路徑”決定的,並沒有考慮查詢路徑上一些資料點本身的一些性質。一個簡單的改進思路就是將“查詢路徑”上的結點進行排序,如按各自分割超平面(也稱bin)與查詢點的距離排序,也就是說,回溯檢查總是從優先順序最高(Best Bin)的樹結點開始。
還是以上面的查詢(2,4.5)為例,搜尋的演算法流程為:
- 將(7,2)壓人優先佇列中;
- 提取優先佇列中的(7,2),由於(2,4.5)位於(7,2)分割超平面的左側,所以檢索其左子結點(5,4)。
- 同時,根據BBF機制”搜尋左/右子樹,就把對應這一層的兄弟結點即右/左結點存進佇列”,將其(5,4)對應的兄弟結點即右子結點(9,6)壓人優先佇列中
- 此時優先佇列為{(9,6)},最佳點為(7,2);然後一直檢索到葉子結點(4,7),此時優先佇列為{(2,3),(9,6)},“最佳點”則為(5,4);
- 提取優先順序最高的結點(2,3),重複步驟2,直到優先佇列為空。
2.6 KD樹的應用
SIFT+KD_BBF搜尋演算法,詳細參考文末的參考文獻。
3. 關於KNN的一些問題
在k-means或kNN,我們是用歐氏距離來計算最近的鄰居之間的距離。為什麼不用曼哈頓距離?
答:我們不用曼哈頓距離,因為它只計算水平或垂直距離,有維度的限制。另一方面,歐式距離可用於任何空間的距離計算問題。因為,資料點可以存在於任何空間,歐氏距離是更可行的選擇。例如:想象一下國際象棋棋盤,象或車所做的移動是由曼哈頓距離計算的,因為它們是在各自的水平和垂直方向的運動。
KD-Tree相比KNN來進行快速影象特徵比對的好處在哪裡?
答:極大的節約了時間成本.點線距離如果 > 最小點,無需回溯上一層,如果<,則再上一層尋找。
4. 參考文獻
從K近鄰演算法、距離度量談到KD樹、SIFT+BBF演算法
5. 手寫數字識別案例
KNN手寫數字識別系統
【機器學習通俗易懂系列文章】
作者:@mantchs
GitHub:https://github.com/NLP-LOVE/ML-NLP
歡迎大家加入討論!共同完善此專案!群號:【541954936】
