
後臺程式設計師如何進階大資料學習?
一、大資料處理流程

上圖是一個簡化的大資料處理流程圖,大資料處理的主要流程包括資料收集、資料儲存、資料處理、資料應用等主要環節。下面我們逐一對各個環節所需要的技術棧進行講解:
1.1 資料收集
大資料處理的第一步是資料的收集。現在的中大型專案通常採用微服務架構進行分散式部署,所以資料的採集需要在多臺伺服器上進行,且採集過程不能影響正常業務的開展。基於這種需求,就衍生了多種日誌收集工具,如 Flume 、Logstash、Kibana 等,它們都能通過簡單的配置完成複雜的資料收集和資料聚合。
1.2 資料儲存
收集到資料後,下一個問題就是:資料該如何進行儲存?通常大家最為熟知是 MySQL、Oracle 等傳統的關係型資料庫,它們的優點是能夠快速儲存結構化的資料,並支援隨機訪問。但大資料的資料結構通常是半結構化(如日誌資料)、甚至是非結構化的(如視訊、音訊資料),為了解決海量半結構化和非結構化資料的儲存,衍生了 Hadoop HDFS 、KFS、GFS 等分散式檔案系統,它們都能夠支援結構化、半結構和非結構化資料的儲存,並可以通過增加機器進行橫向擴充套件。
分散式檔案系統完美地解決了海量資料儲存的問題,但是一個優秀的資料儲存系統需要同時考慮資料儲存和訪問兩方面的問題,比如你希望能夠對資料進行隨機訪問,這是傳統的關係型資料庫所擅長的,但卻不是分散式檔案系統所擅長的,那麼有沒有一種儲存方案能夠同時兼具分散式檔案系統和關係型資料庫的優點,基於這種需求,就產生了 HBase、MongoDB。
1.3 資料分析
大資料處理最重要的環節就是資料分析,資料分析通常分為兩種:批處理和流處理。
- 批處理:對一段時間內海量的離線資料進行統一的處理,對應的處理框架有 Hadoop MapReduce、Spark、Flink 等;
- 流處理:對運動中的資料進行處理,即在接收資料的同時就對其進行處理,對應的處理框架有 Storm、Spark Streaming、Flink Streaming 等。
批處理和流處理各有其適用的場景,時間不敏感或者硬體資源有限,可以採用批處理;時間敏感和及時性要求高就可以採用流處理。隨著伺服器硬體的價格越來越低和大家對及時性的要求越來越高,流處理越來越普遍,如股票價格預測和電商運營資料分析等。
上面的框架都是需要通過程式設計來進行資料分析,那麼如果你不是一個後臺工程師,是不是就不能進行資料的分析了?當然不是,大資料是一個非常完善的生態圈,有需求就有解決方案。為了能夠讓熟悉 SQL 的人員也能夠進行資料的分析,查詢分析框架應運而生,常用的有 Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix 等。這些框架都能夠使用標準的 SQL 或者 類 SQL 語法靈活地進行資料的查詢分析。這些 SQL 經過解析優化後轉換為對應的作業程式來執行,如 Hive 本質上就是將 SQL 轉換為 MapReduce 作業,Spark SQL 將 SQL 轉換為一系列的 RDDs 和轉換關係(transformations),Phoenix 將 SQL 查詢轉換為一個或多個 HBase Scan。
1.4 資料應用
資料分析完成後,接下來就是資料應用的範疇,這取決於你實際的業務需求。比如你可以將資料進行視覺化展現,或者將資料用於優化你的推薦演算法,這種運用現在很普遍,比如短視訊個性化推薦、電商商品推薦、頭條新聞推薦等。當然你也可以將資料用於訓練你的機器學習模型,這些都屬於其他領域的範疇,都有著對應的框架和技術棧進行處理,這裡就不一一贅述。
1.5 其他框架
上面是一個標準的大資料處理流程所用到的技術框架。但是實際的大資料處理流程比上面複雜很多,針對大資料處理中的各種複雜問題分別衍生了各類框架:
- 單機的處理能力都是存在瓶頸的,所以大資料框架都是採用叢集模式進行部署,為了更方便的進行叢集的部署、監控和管理,衍生了 Ambari、Cloudera Manager 等叢集管理工具;
- 想要保證叢集高可用,需要用到 ZooKeeper ,ZooKeeper 是最常用的分散式協調服務,它能夠解決大多數叢集問題,包括首領選舉、失敗恢復、元資料儲存及其一致性保證。同時針對叢集資源管理的需求,又衍生了 Hadoop YARN ;
- 複雜大資料處理的另外一個顯著的問題是,如何排程多個複雜的並且彼此之間存在依賴關係的作業?基於這種需求,產生了 Azkaban 和 Oozie 等工作流排程框架;
- 大資料流處理中使用的比較多的另外一個框架是 Kafka,它可以用於消峰,避免在秒殺等場景下併發資料對流處理程式造成衝擊;
- 另一個常用的框架是 Sqoop ,主要是解決了資料遷移的問題,它能夠通過簡單的命令將關係型資料庫中的資料匯入到 HDFS 、Hive 或 HBase 中,或者從 HDFS 、Hive 匯出到關係型資料庫上。
二、學習路線
介紹完大資料框架,接著就可以介紹其對應的學習路線了,主要分為以下幾個方面:
2.1 語言基礎
1. Java
大資料框架大多采用 Java 語言進行開發,並且幾乎全部的框架都會提供 Java API 。Java 是目前比較主流的後臺開發語言,所以網上免費的學習資源也比較多。如果你習慣通過書本進行學習,這裡推薦以下入門書籍:
- 《Java 程式設計的邏輯》:這裡一本國人編寫的系統入門 Java 的書籍,深入淺出,內容全面;
- 《Java 核心技術》:目前最新的是第 10 版,有 卷一 和 卷二 兩冊,卷二可以選擇性閱讀,因為其中很多章節的內容在實際開發中很少用到。
目前大多數框架要求 Java 版本至少是 1.8,這是由於 Java 1.8 提供了函數語言程式設計,使得可以用更精簡的程式碼來實現之前同樣的功能,比如你呼叫 Spark API,使用 1.8 可能比 1.7 少數倍的程式碼,所以這裡額外推薦閱讀 《Java 8 實戰》 這本書籍。
2. Scala
Scala 是一門綜合了面向物件和函數語言程式設計概念的靜態型別的程式語言,它執行在 Java 虛擬機器上,可以與所有的 Java 類庫無縫協作,著名的 Kafka 就是採用 Scala 語言進行開發的。
為什麼需要學習 Scala 語言 ? 這是因為當前最火的計算框架 Flink 和 Spark 都提供了 Scala 語言的介面,使用它進行開發,比使用 Java 8 所需要的程式碼更少,且 Spark 就是使用 Scala 語言進行編寫的,學習 Scala 可以幫助你更深入的理解 Spark。同樣的,對於習慣書本學習的小夥伴,這裡推薦兩本入門書籍:
- 《快學 Scala(第 2 版)》
- 《Scala 程式設計 (第 3 版)》
這裡說明一下,如果你的時間有限,不一定要學完 Scala 才去學習大資料框架。Scala 確實足夠的精簡和靈活,但其在語言複雜度上略大於 Java,例如隱式轉換和隱式引數等概念在初次涉及時會比較難以理解,所以你可以在瞭解 Spark 後再去學習 Scala,因為類似隱式轉換等概念在 Spark 原始碼中有大量的運用。
2.2 Linux 基礎
通常大資料框架都部署在 Linux 伺服器上,所以需要具備一定的 Linux 知識。Linux 書籍當中比較著名的是 《鳥哥私房菜》系列,這個系列很全面也很經典。但如果你希望能夠快速地入門,這裡推薦《Linux 就該這麼學》,其網站上有免費的電子書版本。
2.3 構建工具
這裡需要掌握的自動化構建工具主要是 Maven。Maven 在大資料場景中使用比較普遍,主要在以下三個方面:
- 管理專案 JAR 包,幫助你快速構建大資料應用程式;
- 不論你的專案是使用 Java 語言還是 Scala 語言進行開發,提交到叢集環境執行時,都需要使用 Maven 進行編譯打包;
- 大部分大資料框架使用 Maven 進行原始碼管理,當你需要從其原始碼編譯出安裝包時,就需要使用到 Maven。
2.4 框架學習
1. 框架分類
上面我們介紹了很多大資料框架,這裡進行一下分類總結:
日誌收集框架:Flume 、Logstash、Kibana
分散式檔案儲存系統:Hadoop HDFS
資料庫系統:Mongodb、HBase
分散式計算框架:
- 批處理框架:Hadoop MapReduce
- 流處理框架:Storm
- 混合處理框架:Spark、Flink
查詢分析框架:Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix
叢集資源管理器:Hadoop YARN
分散式協調服務:Zookeeper
資料遷移工具:Sqoop
任務排程框架:Azkaban、Oozie
叢集部署和監控:Ambari、Cloudera Manager
上面列出的都是比較主流的大資料框架,社群都很活躍,學習資源也比較豐富。建議從 Hadoop 開始入門學習,因為它是整個大資料生態圈的基石,其它框架都直接或者間接依賴於 Hadoop 。接著就可以學習計算框架,Spark 和 Flink 都是比較主流的混合處理框架,Spark 出現得較早,所以其應用也比較廣泛。 Flink 是當下最火熱的新一代的混合處理框架,其憑藉眾多優異的特性得到了眾多公司的青睞。兩者可以按照你個人喜好或者實際工作需要進行學習。
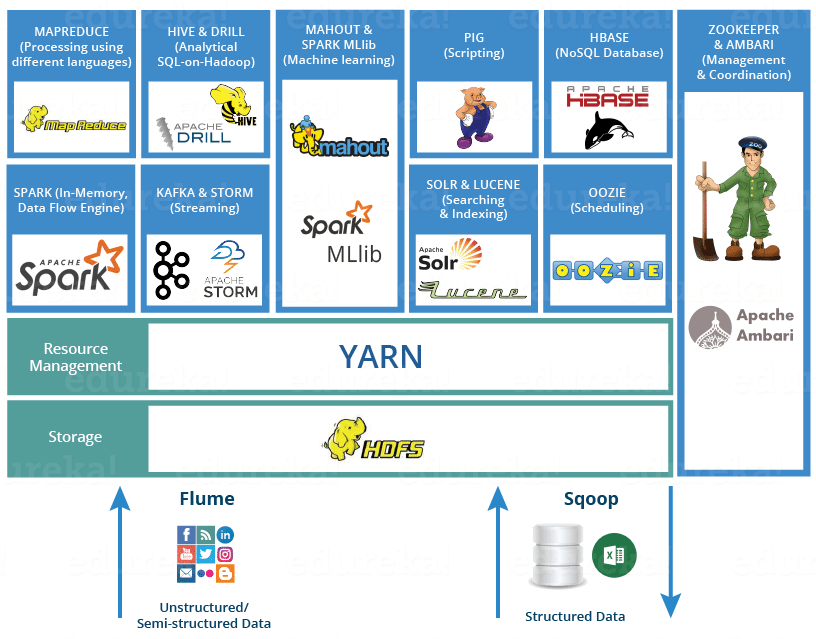
圖片引用自 :https://www.edureka.co/blog/hadoop-ecosystem
至於其它框架,在學習上並沒有特定的先後順序,如果你的學習時間有限,建議初次學習時候,同一型別的框架掌握一種即可,比如日誌收集框架就有很多種,初次學習時候只需要掌握一種,能夠完成日誌收集的任務即可,之後工作上有需要可以再進行鍼對性地學習。
2. 學習資料
大資料最權威和最全面的學習資料就是官方文件。熱門的大資料框架社群都比較活躍、版本更新迭代也比較快,所以其出版物都明顯滯後於其實際版本,基於這個原因採用書本學習不是一個最好的方案。比較慶幸的是,大資料框架的官方文件都寫的比較好,內容完善,重點突出,同時都採用了大量配圖進行輔助講解。當然也有一些優秀的書籍歷經時間的檢驗,至今依然很經典,這裡列出部分個人閱讀過的經典書籍:
- 《hadoop 權威指南 (第四版)》 2017 年
- 《Kafka 權威指南》 2017 年
- 《從 Paxos 到 Zookeeper 分散式一致性原理與實踐》 2015 年
- 《Spark 技術內幕 深入解析 Spark 核心架構設計與實現原理》 2015 年
- 《Spark.The.Definitive.Guide》 2018 年
- 《HBase 權威指南》 2012 年
- 《Hive 程式設計指南》 2013 年
關於文字學習資料,這裡額外安利一下個人的 GitHub 專案: 大資料入門指南
3. 視訊學習資料
上面我推薦的都是書籍學習資料,很少推薦視訊學習資料,這裡說明一下原因:因為書籍歷經時間的考驗,能夠再版的或者豆瓣等平臺評價高的證明都是被大眾所認可的,從概率的角度上來說,其必然更加優秀,不容易浪費大家的學習時間和精力,所以我個人更傾向於官方文件或者書本的學習方式,而不是視訊。因為視訊學習資料,缺少一個公共的評價平臺和完善的評價機制,所以其質量良莠不齊。但是視訊任然有其不可替代的好處,學習起來更直觀、印象也更深刻,所以對於習慣視訊學習的小夥伴,這裡我推薦一個免費的學習資源: 下載連結 線上觀看連結
三、開發工具
這裡推薦一些大資料常用的開發工具:
Java IDE:IDEA 和 Eclipse 都可以。從個人使用習慣而言,更傾向於 IDEA ;
VirtualBox:在學習過程中,你可能經常要在虛擬機器上搭建服務和叢集。VirtualBox 是一款開源、免費的虛擬機器管理軟體,雖然是輕量級軟體,但功能很豐富,基本能夠滿足日常的使用需求;
MobaXterm:大資料的框架通常都部署在伺服器上,這裡推薦使用 MobaXterm 進行連線。同樣是免費開源的,支援多種連線協議,支援拖拽上傳檔案,支援使用外掛擴充套件;
Translate Man:一款瀏覽器上免費的翻譯外掛 (谷歌和火狐均支援)。它採用谷歌的翻譯介面,準確性非常高,支援劃詞翻譯,可以輔助進行官方文件的閱讀。
四、結語
以上就是個人關於大資料的學習心得和路線推薦。本片文章對大資料技術棧做了比較狹義的限定,隨著學習的深入,大家也可以把 Python 語言、推薦系統、機器學習等逐步加入到自己的大資料技術棧中。
最後附上個人總結的大資料常用技術棧思維導圖,更多大資料系列文章可以參見個人 GitHub 開源專案: 大資料入門指南
