
使用EMR-Kafka Connect進行資料遷移
1.背景
流式處理中經常會遇到Kafka與其他系統進行資料同步或者Kafka叢集間資料遷移的情景。使用EMR Kafka Connect可以方便快速的實現資料同步或者資料遷移。
Kafka Connect是一種可擴充套件的、可靠的,用於在Kafka和其他系統之間快速地進行流式資料傳輸的工具。例如可以使用Kafka Connect獲取資料庫的binglog資料,將資料庫的資料遷入Kafka叢集,以同步資料庫的資料,或者對接下游的流式處理系統。同時,Kafka Connect提供的REST API介面可以方便的進行Kafka Connect的建立和管理。
Kafka Connect分為standalone和distributed兩種執行模式。standalone模式下,所有的worker都在一個程序中執行;相比之下,distributed模式更具擴充套件性和容錯性,是最常用的方式,也是生產環境推薦使用的模式。
本文介紹使用EMR Kafka Connect的REST API介面在Kafka叢集間進行資料遷移,使用distributed模式。
2.環境準備
建立兩個EMR叢集,叢集型別為Kafka。EMR Kafka Connect安裝在task節點上,進行資料遷移的目的Kafka叢集需要建立task節點。叢集建立好後,task節點上EMR Kafka Connect服務會預設啟動,埠號為8083。
注意要保證兩個叢集的網路互通,詳細的建立流程見建立叢集。
3.資料遷移
3.1準備工作
EMR Kafka Connect的配置檔案路徑為/etc/ecm/kafka-conf/connect-distributed.properties。
在源Kafka叢集建立需要同步的topic,例如

另外,Kafka Connect會將offsets, configs和任務狀態儲存在topic中,topic名對應配置檔案中的offset.storage.topic、config.storage.topic 和status.storage.topic三個配置項。預設的,Kafka Connect會自動的使用預設的partition和replication factor建立這三個topic。
3.2建立Kafka Connect
在目的Kafka叢集的task節點(例如emr-worker-3節點),使用curl命令通過json資料建立一個Kafka Connect。
json資料中,name欄位代表建立的connect的名稱,此處為connect-test;config欄位需要根據實際情況進行配置,其中的變數說明如下表
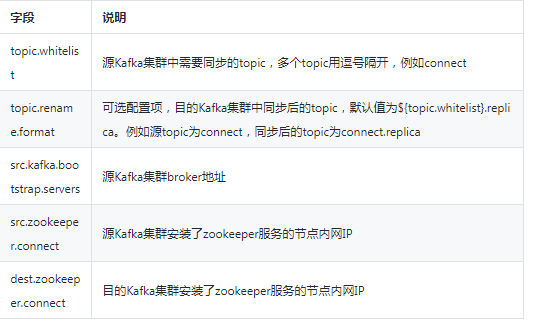
3.3檢視Kafka Connect
檢視所有的Kafka Connect

檢視建立的connect-test的狀態

檢視task的資訊

3.4資料同步
在源Kafka叢集建立需要同步的資料。

3.5檢視同步結果
在目的Kafka叢集消費同步的資料。

可以看到,在源Kafka叢集傳送的100000條資料已經遷移到了目的Kafka叢集。
4.小結
本文介紹並演示了使用EMR kafka Connect在Kafka叢集間進行資料遷移的方法,關於Kafka Connect更詳細的使用請參考Kafka官網資料和REST API使用。
本文作者:雲魄
本文為雲棲社群原創內容,未經