
進階教程:用Python建立全新二層神經結構
全文共5234字,預計學習時長10分鐘

圖片來源:unsplash.com/@alinnnaaaa
本文將介紹如何建立進階神經網路。

輸入資料
本教程唯一使用的資料庫為NumPy。
import numpy as np

啟用函式
在隱藏層中會使用tanh啟用函式,而在輸出層中則會使用sigmod函式。在兩種函式的圖中都很容易找到資訊。下面直接執行函式。
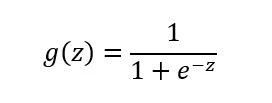
以上為Sigmoid函式。以下為該函式程式碼:
def sigmoid(x): return (1 / (1 + np.exp(-x)))

設定引數
什麼是引數和超引數?引數指權值和偏差。超引數會影響引數,並設定在學習過程開始之前。準確無誤設定超引數並不容易,需要不斷調整數值。超引數包括學習率、迭代次數、校準率等。
想知道如何設定矩陣規模嗎?看看下面的答案吧!

這是什麼意思呢?例如:
(第0層,即L=0),輸入層神經元數量=3
(第1層,即L=1),隱藏層神經元數量=5
(第2層,即L=2),輸出層神經元數量=1
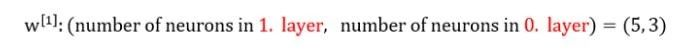
希望以上程式碼都能奏效!現在設定引數。
def setParameters(X, Y, hidden_size):
np.random.seed(3)
input_size = X.shape[0] # number of neurons in input layer
output_size = Y.shape[0] # number of neurons in output layer.
W1 = np.random.randn(hidden_size, input_size)*np.sqrt(2/input_size)
b1 = np.zeros((hidden_size, 1))
W2 = np.random.randn(output_size, hidden_size)*np.sqrt(2/hidden_size)
b2 = np.zeros((output_size, 1))
return {'W1': W1, 'W2': W2, 'b1': b1, 'b2': b2}定義變數W1、b1、W2和b2。變數初始值設為0也無妨。但初始化權值時要格外謹慎。初始值絕不能為0。為什麼?若權值初始值為0,函式Z = Wx + b的值恆為0。多層神經網路中,每層的神經元共同作用。所以應該如何設定初始權值呢?本文使用he初始化。

公式
# Python implementation np.random.randn(output_size, hidden_size)*np.sqrt(2/hidden_size)
除he初始化以外,也可以使用以下方法:
np.random.randn(output_size, hidden_size)*0.01
建議:在引數初始化中,請勿將權值設為0或大數值。

前向傳播

前向傳播
上圖清晰解釋了前向傳播。在Python中的應用為:
def forwardPropagation(X, params):
Z1 = np.dot(params['W1'], X)+params['b1']
A1 = np.tanh(Z1)
Z2 = np.dot(params['W2'], A1)+params['b2']
y = sigmoid(Z2)
return y, {'Z1': Z1, 'Z2': Z2, 'A1': A1, 'y': y}
為什麼要儲存 {‘Z1’: Z1, ‘Z2’: Z2, ‘A1’: A1, ‘y’: y}?因為在反向傳播中會用到這些數值。

成本函式
剛才介紹了前向傳播,得到預測值(y)。這個值由成本函式計算得出。下圖可以說明:
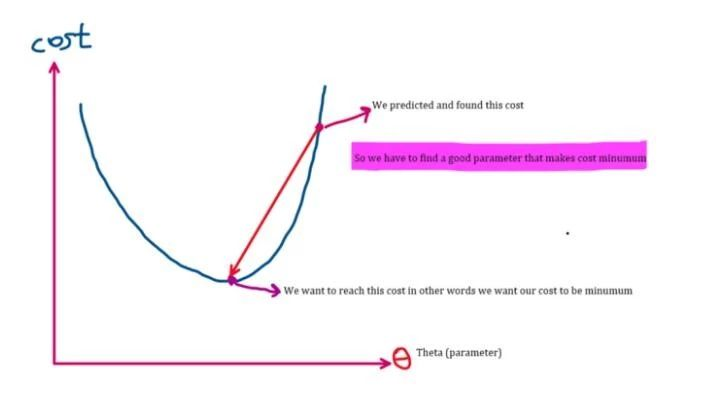
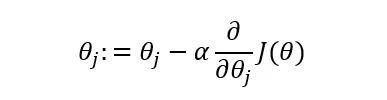
更新引數
更新引數後找到可能最小化成本的最佳引數,本文不會對此再做探討。但在上一段提到,如果數值在拋物線右側,導數(斜率)為正,數值遞減,左移接近最小成本值;若數值在拋物線左側,斜率為負,因此引數會增至預期的最小成本值。
以下為使用的成本函式:
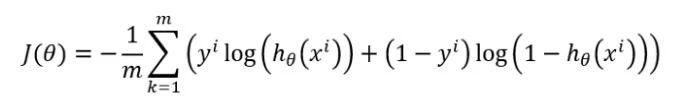
成本函式
此成本函式的Python程式碼:
def cost(predict, actual): m = actual.shape[1] cost__ = -np.sum(np.multiply(np.log(predict), actual) + np.multiply((1 - actual), np.log(1 - predict)))/m return np.squeeze(cost__)

反向傳播
確定成本後,下面返回去求權值和偏差的導數。
def backPropagation(X, Y, params, cache):
m = X.shape[1]
dy = cache['y'] - Y dW2 = (1 / m) * np.dot(dy, np.transpose(cache['A1']))
db2 = (1 / m) * np.sum(dy, axis=1, keepdims=True)
dZ1 = np.dot(np.transpose(params['W2']), dy) * (1-np.power(cache['A1'], 2))
dW1 = (1 / m) * np.dot(dZ1, np.transpose(X))
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
return {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
def backPropagation(X, Y, params,cache)中的parama和cache是什麼?在前向傳播中儲存數值,就是為了用於反向傳播。Params是引數(權值和偏差)。

更新引數
得到引數後,代入以下公式:

公式中alpha (α)是超引數的學習率。在學習開始前需要設定數值。在學習率右側的數值為導數。alpha和導數已知,可以更新引數。
def updateParameters(gradients, params, learning_rate = 1.2):
W1 = params['W1'] - learning_rate * gradients['dW1']
b1 = params['b1'] - learning_rate * gradients['db1']
W2 = params['W2'] - learning_rate * gradients['dW2']
b2 = params['b2'] - learning_rate * gradients['db2']
return {'W1': W1, 'W2': W2, 'b1': b1, 'b2': b2}

迴圈是關鍵
需要多次迭代才能找到迴歸最低成本的引數。現在開始迴圈!
def fit(X, Y, learning_rate, hidden_size, number_of_iterations = 5000): params = setParameters(X, Y, hidden_size) cost_ = [] for j in range(number_of_iterations): y, cache = forwardPropagation(X, params) costit = cost(y, Y) gradients = backPropagation(X, Y, params, cache) params = updateParameters(gradients, params, learning_rate) cost_.append(costit) return params, cost_
Hidden_size指隱藏層中神經元數量。由於在學習開始前設定,它類似於超引數。return params, cost_指找到的最佳引數。cost_為每次迭代預估的成本。

執行程式碼!
使用sklearn建立資料集。
import sklearn.datasets X, Y = sklearn.datasets.make_moons(n_samples=500, noise=.2)X, Y = X.T, Y.reshape(1, Y.shape[0])
X為輸入值,Y為實際輸出值。
params, cost_ = fit(X, Y, 0.3, 5, 5000)
本文中學習率設定為0.3,隱藏層神經元數量為5,迭代次數為5000.當然也可設定不同數值嘗試。
下面畫圖以說明每次迭代中成本函式的變化。
import matplotlib.pyplot as pltplt.plot(cost_)
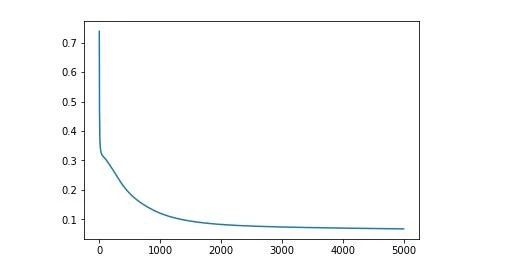
結果正確!
first_cost = 0.7383781203733911last_cost = 0.06791109327547613
完整程式碼:
import numpy as np
def sigmoid(x):
return (1 / (1 + np.exp(-x)))def setParameters(X, Y, hidden_size):
np.random.seed(3)
input_size = X.shape[0] # number of neurons in
input layer
output_size = Y.shape[0] # number of neurons in
output layer.
W1 = np.random.randn(hidden_size, input_size)*np.sqrt(2/input_size)
b1 = np.zeros((hidden_size, 1))
W2 = np.random.randn(output_size, hidden_size)*np.sqrt(2/hidden_size)
b2 = np.zeros((output_size, 1))
return {'W1': W1, 'W2': W2, 'b1': b1, 'b2': b2}def forwardPropagation(X, params):
Z1 = np.dot(params['W1'], X)+params['b1']
A1 = np.tanh(Z1)
Z2 = np.dot(params['W2'], A1)+params['b2'] y = sigmoid(Z2)
return y, {'Z1': Z1, 'Z2': Z2, 'A1': A1, 'y': y}
def cost(predict, actual): m = actual.shape[1]
cost__ = -np.sum(np.multiply(np.log(predict),
actual) + np.multiply((1 - actual),
np.log(1 - predict)))/m
return np.squeeze(cost__)
def backPropagation(X, Y, params, cache): m = X.shape[1]
dy = cache['y'] - Y
dW2 = (1 / m) * np.dot(dy, np.transpose(cache['A1']))
db2 = (1 / m) * np.sum(dy, axis=1, keepdims=True)
dZ1 = np.dot(np.transpose(params['W2']), dy) * (1-np.power(cache['A1'], 2))
dW1 = (1 / m) * np.dot(dZ1, np.transpose(X))
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
return {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}def
updateParameters(gradients, params, learning_rate = 1.2):
W1 = params['W1'] - learning_rate * gradients['dW1']
b1 = params['b1'] - learning_rate * gradients['db1']
W2 = params['W2'] - learning_rate * gradients['dW2']
b2 = params['b2'] - learning_rate * gradients['db2']
return {'W1': W1, 'W2': W2, 'b1': b1, 'b2': b2}
def fit(X, Y, learning_rate, hidden_size, number_of_iterations = 5000):
params = setParameters(X, Y, hidden_size)
cost_ = [] for j in range(number_of_iterations):
y, cache = forwardPropagation(X, params)
costit = cost(y, Y)
gradients = backPropagation(X, Y, params, cache)
params = updateParameters(gradients, params, learning_rate)
cost_.append(costit)
return params,
cost_# Testing the codeimport sklearn.datasetsX,
Y = sklearn.datasets.make_moons(n_samples=500, noise=.2)X,
Y = X.T, Y.reshape(1, Y.shape[0])params, cost_ = fit(X, Y, 0.3, 5, 5000)
import matplotlib.pyplot as pltplt.plot(cost_)
留言 點贊 關注
我們一起分享AI學習與發展的乾貨
歡迎關注全平臺AI垂類自媒體 “讀芯術”
(新增小編微信:dxsxbb,加入讀者圈,一起討論最新鮮的人工