
58 集團大規模 Storm 任務平滑遷移至 Flink 的祕密
Flink-Storm 是 Flink 官方提供的用於 Flink 相容 Storm 程式 beta 工具,並且在 Release 1.8 之後去掉相關程式碼。本文主要講述 58 實時計算平臺如何優化 Flink-Storm 以及基於 Flink-Storm 實現真實場景下大規模 Storm 任務平滑遷移 Flink。
背景
58 實時計算平臺旨在為集團業務部門提供穩定高效實時計算服務,主要基於 Storm 和 Spark Streaming 構建,但在使用過程中也面臨一些問題,主要包括 Storm 在吞吐量不足以及多叢集帶來運維問題,Spark Streaming 又無法滿足低延遲的要求。Apache Flink 開源之後,其在架構設計、計算效能和穩定性上體現出的優勢,使我們決定採用 Flink 作為新一代實時計算平臺的計算引擎。同時基於 Flink 開發了一站式高效能實時計算平臺 Wstream,支援 Flink jar,Stream Sql,Flink-Storm 等多樣化任務構建方式。
在完善 Flink 平臺建設的同時,我們也啟動 Storm 任務遷移 Flink 計劃,旨在提升實時計算平臺整體效率,減少機器成本和運維成本。
Storm vs Flink

儘管 Flink 作為高效能運算引擎可以很好相容 Storm,但在業務遷移過程中,我們仍然遇到了一些問題:
1 .使用者對 Flink 的學習成本;
- 重新基於 Flink 開發耗費工作量;
- Stream-SQL 雖然可以滿足快速開發減少學習成本和開發工作量但無法滿足一些複雜場景。
因此我們決定採用 Flink 官方提供的 Flink-Storm 進行遷移,在保障遷移穩定性同時無需使用者修改 Storm 程式碼邏輯。
Flink-Storm 原理
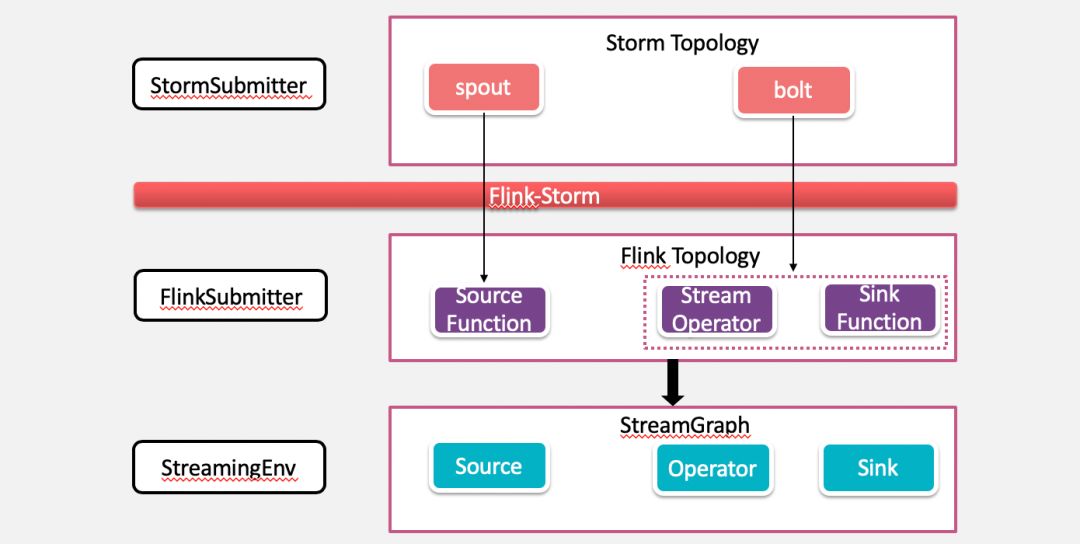
通過 Storm 原生 TopologyBuilder 構建好 Storm topology。
FlinkTopology.createTopology(builder) 將 StormTopology 轉換為 Flink 對應的 Streaming Dataflow。
SpoutWrapper 用於將 spout 轉換為 RichParallelSourceFunction,spout 的OutputFields轉換成 source 的T ypeInformation。
BoltWrapper 用於將 bolt 轉換成對應的 operator,其中 grouping 轉換為對 spout 的 DataStream 的對應操作。
構建完 FlinkTopology 之後,就可以通過 StreamExecutionEnvironment 生成 StreamGraph 獲取 JobGraph,之後將 JobGraph 提交到 Flink 執行時環境。
實踐
Flink-Storm 作為官方提供 Flink 相容 Storm 程式為我們實現無縫遷移提供了可行性,但是作為 beta 版本,在實際使用過程中存在很多無法滿足現實場景的情況,主要包括版本,功能 bug,複雜邏輯相容,無法支援 yarn 等,下面將主要分為平臺層面和使用者層面講述我們的使用和改進。

平臺層面
1. 版本
當前線上使用 Apache Flink 1.6 版本,Flink-Storm 模組基於 Storm 1.0 開發,我們平臺執行 Storm 版本為 0.9.5 和 1.2 。
1.1 對於 Storm 1.2 執行任務,Storm 1.0 API 完全相容 1.2 版本,因此只需切換 Flink-Storm 模組依賴的 storm-core 到 1.2.

1.2 對於 Storm 0.9.5 任務,由於 Storm 1.0 API 無法相容 0.9.5,需要修改依賴 storm-core 為 0.9.5,同時修改 Flink-Storm 模組中所有與 Storm 相關的 API,主要是切換 package 路徑。
1.3 重新構建 flink-storm 包 mvn clean package -Dmaven.test.skip=true -Dcheckstyle.skip=true
2.功能
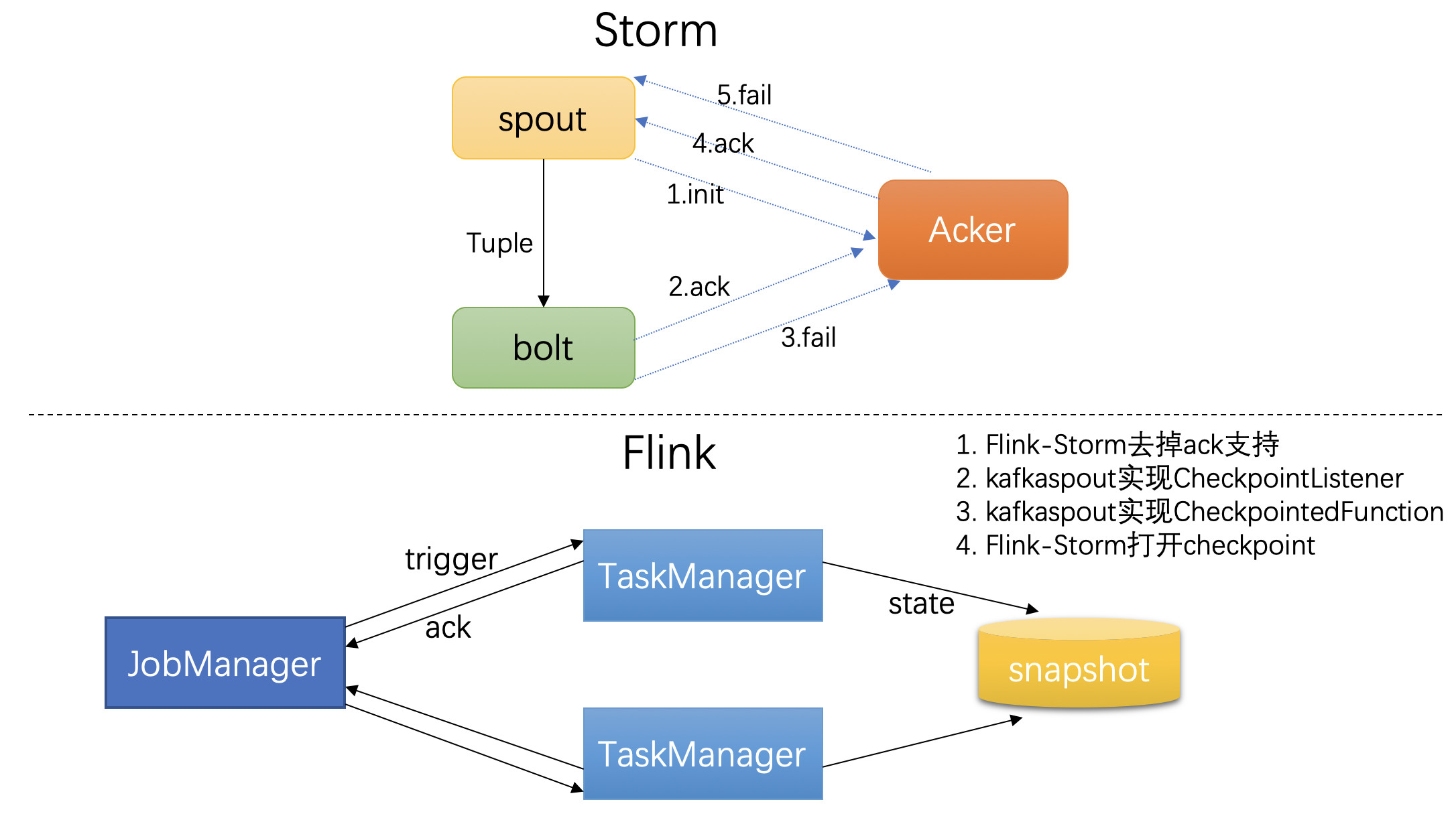
2.1 傳遞語義保證
Storm 使用 ACK 機制來實現傳遞語義保證,我們沒有將 Storm 的 ACK 機制移植到Flink-Storm。因此,某些依賴 ACK 機制的功能會受到限制。比如,Kafka spout 將消費狀態儲存在 ZK,狀態的更新需要依賴 ACK 機制,tuple 樹結束後,spout 才會觸發狀態更新,表示這條訊息已經被完全處理,從而實現 at least once 的傳遞保證。Storm 也提供了at most once 的支援,spout 傳送訊息後,無需等待 tuple 樹結束直接觸發狀態更新。我們使用了 Storm 的實現 at most once 的方式,在 Kafka spout 實現 at most once 的基礎上,通過實現 Flink Checkpoint 的狀態機制,實現了 Flink-storm 任務的 at least once。Storm 任務遷移到 Flink,傳遞保證不變。
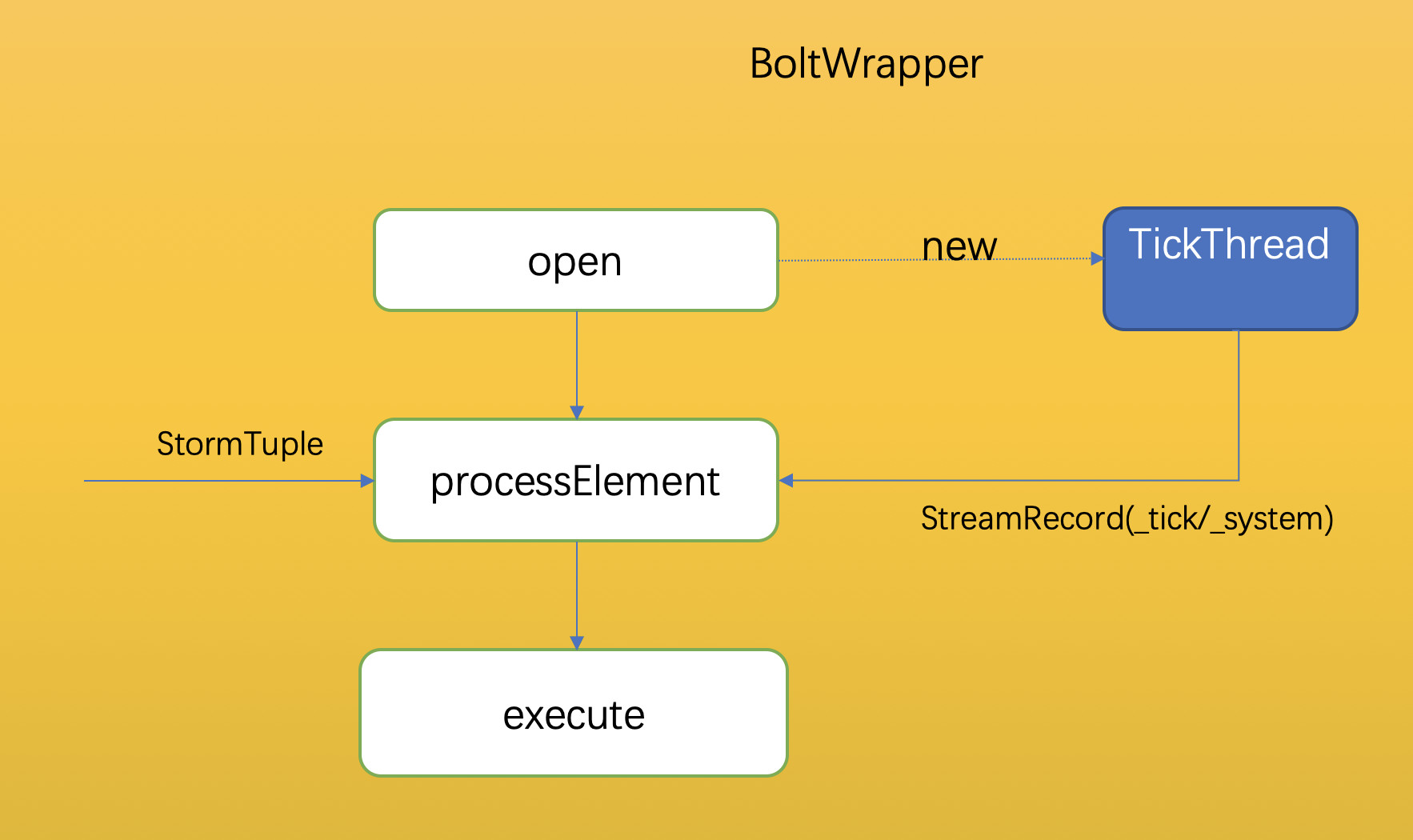
2.2 tick tuple 機制
Storm 使用 tick tuple 機制實現定時功能,訊息超時重發、Bolt 定時觸發等功能都要依賴 tick tuple 機制。Storm 0.9.5 版本沒有實現視窗功能,使用者可以使用 tick tuple 機制簡單實現視窗功能。我們同樣為 Flink-Storm 增加了 tick tuple 機制的支援,使用方式也和 Storm 中使用方式一樣,配置 topology.tick.tuple. freq.secs 引數,即開啟了 tick tuple 功能。
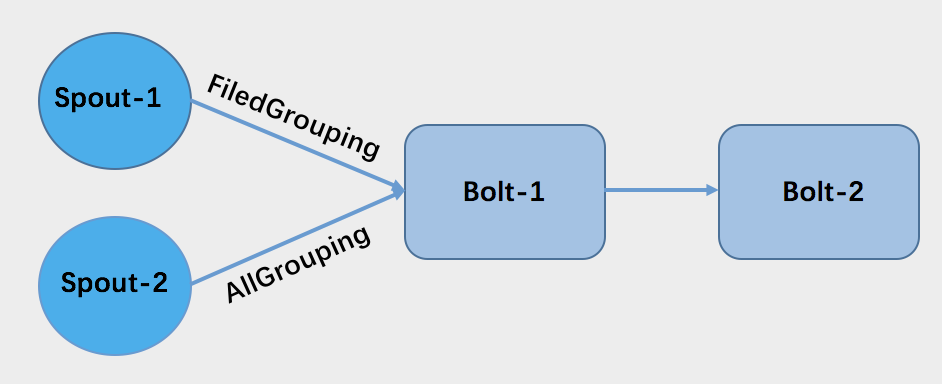
2.3 多輸入下 AllGrouping 支援
AllGrouping 分組方式對應於 Flink 是 Broadcast。如圖,bolt-1 有兩個輸入,這種情況下,原 flink-storm 的實現,spout-2 到 bolt-1 的資料分割槽的表現形式和Rebalance(Flink 術語)一樣,而不是 Broadcast。我們優化了這種場景,使其資料分組表現和 Storm 中是一樣的。
3.Runtime
Flink-Storm 預設支援 local 和 standalong 模式任務提交,無法將任務提交到 yarn 叢集,我們在建設 Flink 叢集一開始就選擇了 yarn 模式,便於叢集資源管理和統一實時計算平臺,因此需要自行實現支援 yarn 的 runtime 功能,這裡主要涉及 yarn client 端設計。
YARN Client 實現機制
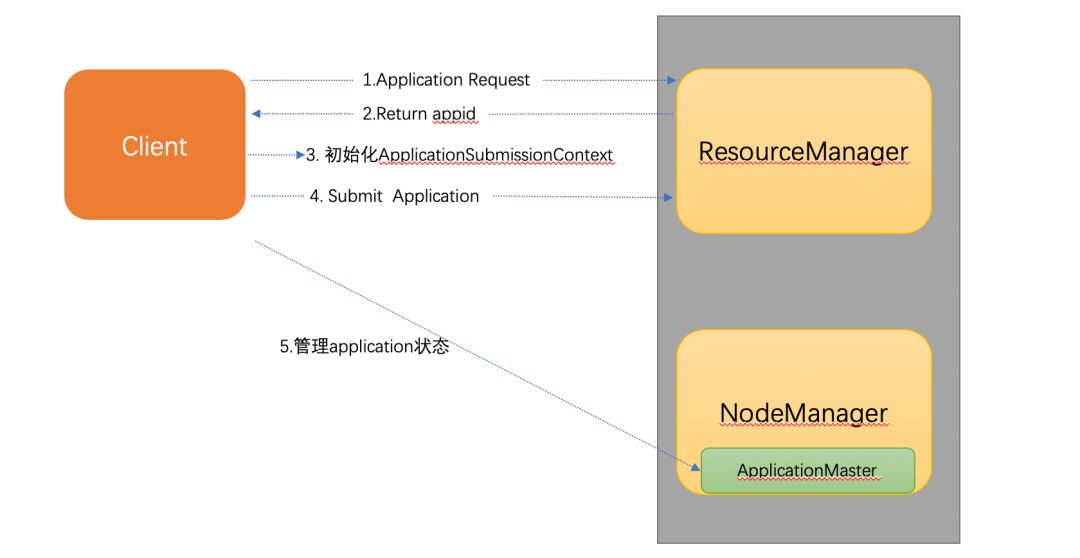
整個模組主要分為四個部分,其中 client 用於呼叫 Flink-Storm 程式轉化介面,得到 Flink jobGraph。配置引數用於初始化 Flink 及 yarn 相關配置,構建執行時環境,命令列工具主要用於更加靈活的管理。yarnClient 主要實現 ApplicationClientProtocol 介面,完成與 ResourceManager 與 ApplicationMaster 的互動,實現 Flink job 提交和監控。

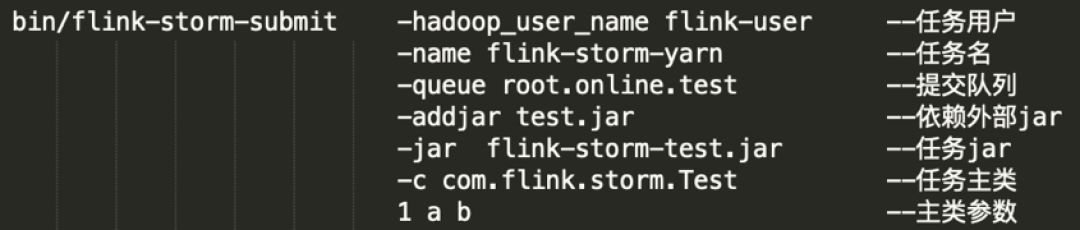
4.任務部署
為便於任務提交和整合到 Wstream 平臺,提供類似 Flink 命令列提交方式:
使用者層面
1.maven 依賴
平臺將編譯好的包上傳到公司 maven 私服供使用者下載對應版本 Flink-Storm 依賴包:

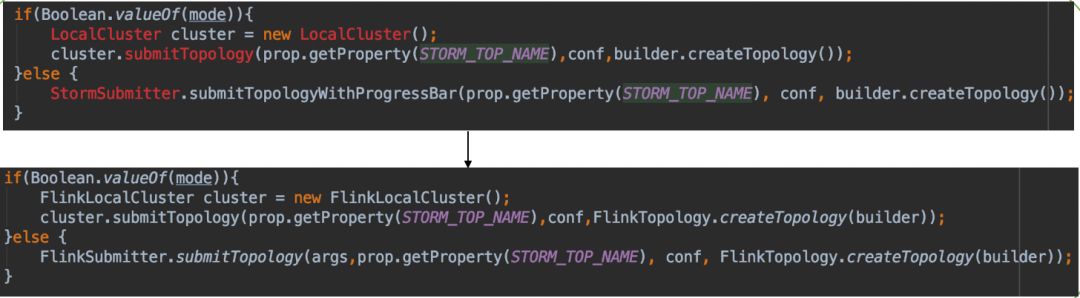
2.程式碼改動
使用者需要將 Storm 提交任務的方式改成 Flink 提交,其他無需變動。
總結
通過對 Fink-Storm 的優化和使用,我們已經順利完成多個 Storm 叢集任務遷移和下線,在保障實時性及吞吐量的基礎上可以節約計算資源 40% 以上,同時藉助 yarn 統一管理實時計算平臺無需維護多套 Storm 叢集,整體提升了平臺資源利用率,減輕平臺運維工作量。
作者介紹:
萬石康,來自 58 集團 TEG,後端高階工程師,專注於大資料實時計算架構設計。
原文連結
本文為雲棲社群原創內容,未經