
Java併發程式設計筆記——J.U.C之executors框架:ThreadPoolExecutor

一、ThreadPoolExecutor簡介
在J.U.C之executors框架:executors框架設計理念的章節中,我們已經簡要介紹過ThreadPoolExecutor了,通過Executors工廠,使用者可以建立自己需要的執行器物件。ThreadPoolExecutor,它是J.U.C在JDK1.5時提供的一種實現了ExecutorService介面的執行器,或者說執行緒池。
public class ThreadPoolExecutor extends AbstractExecutorService {
ThreadPoolExecutor並沒有自己直接實現ExecutorService介面,因為它只是其中一種Executor的實現而已,所以Doug Lea把一些通用部分封裝成一個抽象父類——AbstractExecutorService
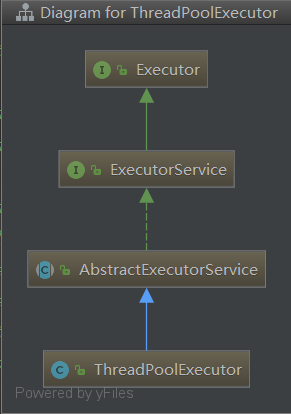
AbstractExecutorService
AbstractExecutorService提供了 ExecutorService 介面的預設實現——主要實現了 submit、invokeAny 、invokeAll這三類方法;
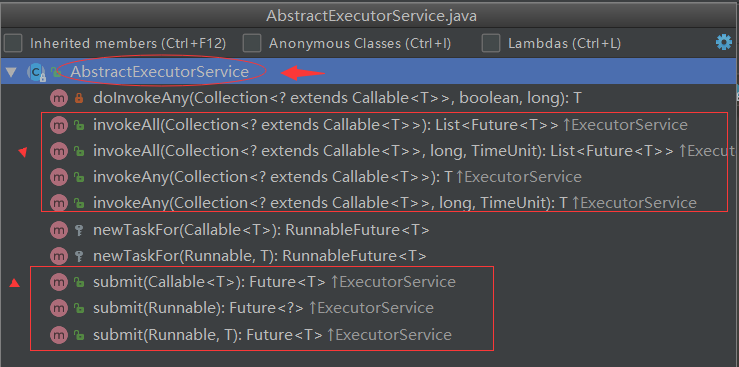
如果讀者看過上一篇綜述文章,就應該知道,ExecutorService的這三類方法幾乎都是返回一個Future物件。而Future是一個介面,AbstractExecutorService既然實現了這些方法,必然要實現該Future介面,我們來看下AbstractExecutorService實現的submit
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}可以看到,上述方法首先對Runnable和返回值value進行了封裝,通過newTaskFor
這裡其實是 模板方法模式的運用,execute是抽象方法,需要由繼承AbstractExecutorService的子類來實現。
上述需要注意的是newTaskFor方法,該方法建立了一個Future物件:
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}FutureTask其實就是Future介面的實現類:
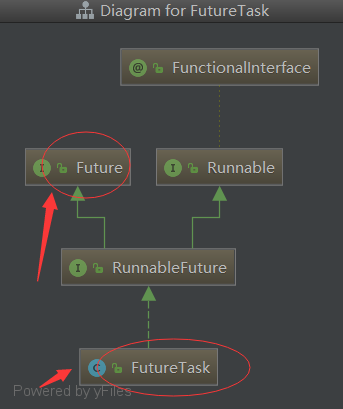
我們之前講過,J.U.C中的Future介面是“Future模式”的 多執行緒設計模式的實現,可以讓呼叫方以 非同步方式獲取任務的執行結果。而FutureTask便是這樣一類支援非同步返回結果的任務,既然是任務就需要實現Runnable介面,同時又要支援非同步功能,所以又需要實現Future介面。J.U.C為了方便,新定義了一個介面—— RunnableFuture,該介面同時繼承Runnable和Future,代表支援非同步處理的任務,而FutureTask便是它的預設實現。
本節不會在Futrure模式上花費太多筆墨,以後我們會專門講解J.U.C對Future模式的支援。
執行緒池簡介
回到ThreadPoolExecutor,從該類的命名也可以看出,這是一種執行緒池執行器。執行緒池大家應該並不陌生,應用開發中經常需要用到資料庫連線池,資料庫連線池裡維護著一些資料庫連線,當應用需要連線資料庫時,並不是自己建立連線,而是從連線池中獲取可用連線;當關閉資料庫連線時,只是將該連線還給連線池,以供複用。
而執行緒池也是類似的概念,當有任務需要執行時,執行緒池會給該任務分配執行緒,如果當前沒有可用執行緒,一般會將任務放進一個佇列中,當有執行緒可用時,再從佇列中取出任務並執行,如下圖:
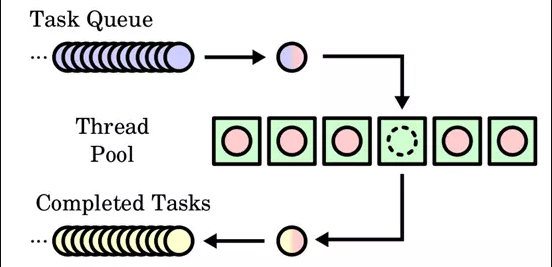
執行緒池的引入,主要解決以下問題:
- 減少系統因為頻繁建立和銷燬執行緒所帶來的開銷;
- 自動管理執行緒,對使用方透明,使其可以專注於任務的構建。
二、ThreadPoolExecutor基本原理
瞭解了執行緒池和ThreadPoolExecutor的繼承體系,接下來,我們來看下J.U.C是如何實現一個普通執行緒池的。
構造執行緒池
我們先來看下ThreadPoolExecutor的構造器,其實之前在講Executors時已經接觸過了,Executors工廠方法建立的三種執行緒池:newFixedThreadPool、newSingleThreadExecutor、newCachedThreadPool,內部都是通過ThreadPoolExecutor的下面這個構造器例項化了ThreadPoolExecutor物件:
/**
* 使用給定的引數建立ThreadPoolExecutor.
*
* @param corePoolSize 核心執行緒池中的最大執行緒數
* @param maximumPoolSize 匯流排程池中的最大執行緒數
* @param keepAliveTime 空閒執行緒的存活時間
* @param unit keepAliveTime的單位
* @param workQueue 任務佇列, 儲存已經提交但尚未被執行的執行緒
* @param threadFactory 執行緒工廠(用於指定如果建立一個執行緒)
* @param handler 拒絕策略 (當任務太多導致工作佇列滿時的處理策略)
*/
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime); // 使用納秒儲存存活時間
this.threadFactory = threadFactory;
this.handler = handler;
}為了使用者使用方便,ThreadPoolExecutor一共提供了4種構造器,但其它三種內部其實都呼叫了上面的構造器。
正是通過上述引數的組合變換,使得Executors工廠可以建立不同型別的執行緒池。這裡先簡要講一下corePoolSize和maximumPoolSize這兩個引數:
ThreadPoolExecutor在邏輯上將自身管理的執行緒池劃分為兩部分:核心執行緒池(大小對應為corePoolSize)、非核心執行緒池(大小對應為maximumPoolSize-corePoolSize)。
當我們向執行緒池提交一個任務時,將建立一個工作執行緒——我們稱之為Worker,Worker在邏輯上從屬於下圖中的【核心執行緒池】或【非核心執行緒池】,具體屬於哪一種,要根據corePoolSize、maximumPoolSize、Worker總數進行判斷:
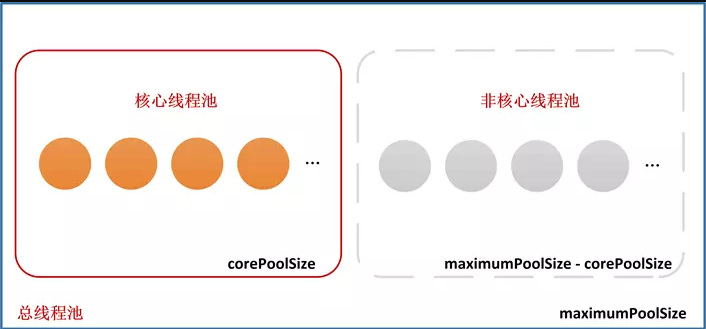
注意:我們上面一直在提【工作執行緒】、【核心執行緒池】、【非核心執行緒池】,讀者可能都看暈了,包括我自己第一次學習ThreadPoolExecutor時也被網上和垃圾國產技術書籍的錯誤描述給誤導了。我這裡先提一下,後面我們分析執行緒池的任務排程流程時會再詳細說明:
- ThreadPoolExecutor中只有一種型別的執行緒,名叫Worker,它是ThreadPoolExecutor定義的內部類,同時封裝著Runnable任務和執行該任務的Thread物件,我們稱它為【工作執行緒】,它也是ThreadPoolExecutor唯一需要進行維護的執行緒;
- 【核心執行緒池】【非核心執行緒池】都是邏輯上的概念,ThreadPoolExecutor在任務排程過程中會根據
corePoolSize和maximumPoolSize的大小,判斷應該如何排程任務.
執行緒池狀態和執行緒管理
到這裡,讀者可能會思考一個問題:既然是執行緒池,那麼必然有執行緒池狀態,同時也涉及對其中的工作執行緒(Worker)的管理,ThreadPoolExecutor是如何做的呢?
ThreadPoolExecutor內部定義了一個AtomicInteger變數——ctl,通過按位劃分的方式,在一個變數中記錄執行緒池狀態和工作執行緒數——低29位儲存執行緒數,高3位儲存執行緒池狀態:
/**
* 儲存執行緒池狀態和工作執行緒數:
* 低29位: 工作執行緒數
* 高3位 : 執行緒池狀態
*/
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
// 最大執行緒數: 2^29-1
private static final int CAPACITY = (1 << COUNT_BITS) - 1; // 00011111 11111111 11111111 11111111
// 執行緒池狀態
private static final int RUNNING = -1 << COUNT_BITS; // 11100000 00000000 00000000 00000000
private static final int SHUTDOWN = 0 << COUNT_BITS; // 00000000 00000000 00000000 00000000
private static final int STOP = 1 << COUNT_BITS; // 00100000 00000000 00000000 00000000
private static final int TIDYING = 2 << COUNT_BITS; // 01000000 00000000 00000000 00000000
private static final int TERMINATED = 3 << COUNT_BITS; // 01100000 00000000 00000000 00000000可以看到,ThreadPoolExecutor一共定義了5種執行緒池狀態:
- RUNNING : 接受新任務, 且處理已經進入阻塞佇列的任務
- SHUTDOWN : 不接受新任務, 但處理已經進入阻塞佇列的任務
- STOP : 不接受新任務, 且不處理已經進入阻塞佇列的任務, 同時中斷正在執行的任務
- TIDYING : 所有任務都已終止, 工作執行緒數為0, 執行緒轉化為TIDYING狀態並準備呼叫terminated方法
- TERMINATED : terminated方法已經執行完成
各個狀態之間的流轉圖:

另外,我們剛才也提到工作執行緒(Worker),Worker被定義為ThreadPoolExecutor的內部類,實現了AQS框架,ThreadPoolExecutor通過一個HashSet來儲存工作執行緒:
/**
* 工作執行緒集合.
*/
private final HashSet<Worker> workers = new HashSet<Worker>();工作執行緒的定義如下:
/**
* Worker表示執行緒池中的一個工作執行緒, 可以與任務相關聯.
* 由於實現了AQS框架, 其同步狀態值的定義如下:
* -1: 初始狀態
* 0: 無鎖狀態
* 1: 加鎖狀態
*/
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
/**
* 與該Worker關聯的執行緒.
*/
final Thread thread;
/**
* Initial task to run. Possibly null.
*/
Runnable firstTask;
/**
* Per-thread task counter
*/
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1); // 初始的同步狀態值
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/**
* 執行任務
*/
public void run() {
runWorker(this);
}
/**
* 是否加鎖
*/
protected boolean isHeldExclusively() {
return getState() != 0;
}
/**
* 嘗試獲取鎖
*/
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
/**
* 嘗試釋放鎖
*/
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() {
acquire(1);
}
public boolean tryLock() {
return tryAcquire(1);
}
public void unlock() {
release(1);
}
public boolean isLocked() {
return isHeldExclusively();
}
/**
* 中斷執行緒(僅任務非初始狀態)
*/
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}通過Worker的定義可以看到,每個Worker物件都有一個Thread執行緒物件與它相對應,當任務需要執行的時候,實際是呼叫內部Thread物件的start方法,而Thread物件是在Worker的構造器中通過getThreadFactory().newThread(this)方法建立的,建立的Thread將Worker自身作為任務,所以當呼叫Thread的start方法時,最終實際是呼叫了Worker.run()方法,該方法內部委託給runWorker方法執行任務,這個方法我們後面會詳細介紹。
執行緒工廠
ThreadFactory用來建立單個執行緒,當執行緒池需要建立一個執行緒時,就要呼叫該類的newThread(Runnable r)方法建立執行緒(ThreadPoolExecutor中實際建立執行緒的時刻是在將任務包裝成工作執行緒Worker時)。
ThreadPoolExecutor在構造時如果使用者不指定ThreadFactory,則預設使用Executors.defaultThreadFactory()建立一個ThreadFactory,即Executors.DefaultThreadFactory:
public static ThreadFactory defaultThreadFactory() {
return new DefaultThreadFactory();
}
/**
* 預設的執行緒工廠.
*/
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);//用於統計執行緒工廠個數
private final ThreadGroup group;
//用來統計每個執行緒工廠建立了多少執行緒
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup();
namePrefix = "pool-" + poolNumber.getAndIncrement() + "-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r, namePrefix + threadNumber.getAndIncrement(), 0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}這裡的關鍵是要明白為什麼需要用ThreadFactory來建立執行緒,而不是直接通過new Thread()的方式。這個問題在executors框架概述中已經談過了,這樣做的好處是: 一來解耦物件的建立與使用,二來可以 批量配置執行緒資訊(優先順序、執行緒名稱、是否守護執行緒等),以自由設定池子中所有執行緒的狀態。
三、執行緒池的排程流程
ExecutorService的核心方法是submit方法——用於提交一個待執行的任務,如果讀者閱讀ThreadPoolExecutor的原始碼,會發現它並沒有覆寫submit方法,而是沿用了父類AbstractExecutorService的模板,然後自己實現了execute方法:
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}ThreadPoolExecutor的execute方法定義如下:
public void execute(Runnable command) {
//【1】如果任務為null,則丟擲NPE異常
if (command == null)
throw new NullPointerException();
//【2】獲取當前執行緒池的狀態+執行緒個數變數的組合值
int c = ctl.get();
【3】當前執行緒池中執行緒個數是否小於corePoolSize,小於則開啟新執行緒執行
if (workerCountOf(c) < corePoolSize) { // CASE1: 工作執行緒數 < 核心執行緒池上限
if (addWorker(command, true)) // 新增工作執行緒並執行
return;
c = ctl.get();
}
//【4】如果執行緒池處於RUNNING狀態,則新增任務到阻塞佇列
if (isRunning(c) && workQueue.offer(command)) { // CASE2: 插入任務至佇列
// 【4.1】二次檢查
int recheck = ctl.get();
//【4.2】如果當前執行緒池狀態不是RUNNING則從佇列中刪除任務,並執行拒絕策略
if (!isRunning(recheck) && remove(command))
reject(command);
//【4.3】否則如果當前執行緒池為空,則新增一個執行緒
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
//【5】如果佇列滿了,則新增執行緒,新增失敗則執行拒絕策略
} else if (!addWorker(command, false)) // CASE3: 插入佇列失敗, 判斷工作執行緒數 < 匯流排程池上限
reject(command); // 執行拒絕策略
}說明:ThreadPoolExecutor的實現實際上是一個生產消費模型,當用戶新增任務到執行緒池時,相當於生產者生產元素,workers執行緒工作集中的執行緒直接執行任務或者從任務佇列裡面獲取任務時,則相當於消費者消費元素。
上述execute的執行流程可以用下圖描述:
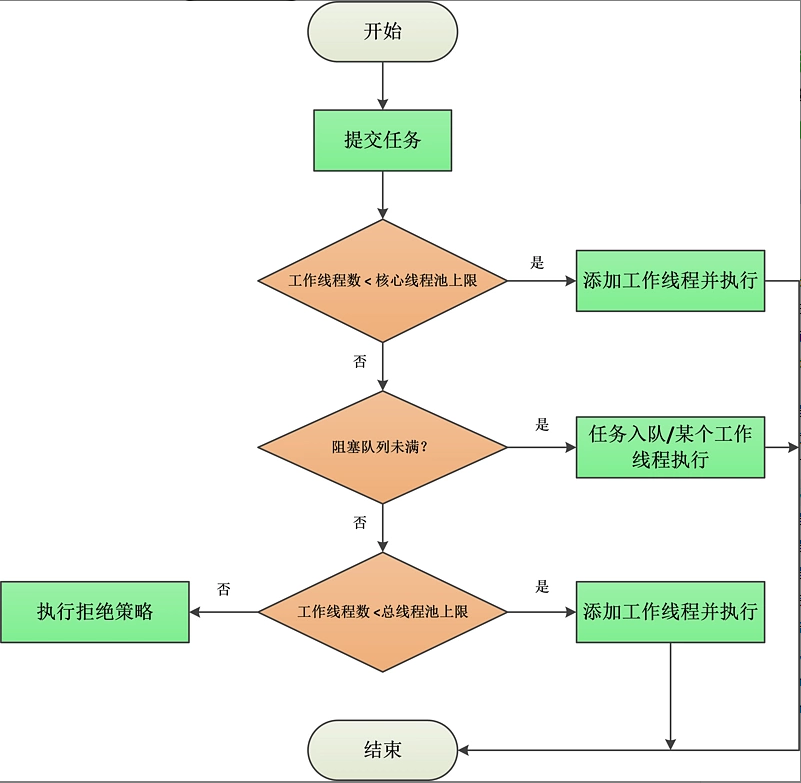
這裡需要特別注意的是 CASE2中的addWorker(null, false),當將任務成功新增到佇列後,如果此時的工作執行緒數為0,就會執行這段程式碼。
一般來講每個工作執行緒(Worker)都有一個Runnable任務和一個對應的執行執行緒Thread,當我們呼叫addWorker方法時,如果不傳入相應的任務,那麼就只是新建了一個沒有任務的工作執行緒(Worker),該Worker就會從工作佇列中取任務來執行(因為自己沒有繫結任務)。如果傳入了任務,新建的工作執行緒就會執行該任務。
所以execute方法的CASE2中,將任務新增到佇列後,需要判斷工作執行緒數是否為0,如果是0那麼就必須新建一個空任務的工作執行緒,將來在某一時刻它會去佇列取任務執行,否則沒有工作執行緒的話,該佇列中的任務永遠不會被執行。
另外,這裡又要回到【工作執行緒】、【核心執行緒池】、【非核心執行緒池】、【匯流排程池】的概念上了。
再強調一遍,maximumPoolSize限定了整個執行緒池的大小,corePoolSize限定了核心執行緒池的大小,corePoolSize≤maximumPoolSize(當相等時表示為固定執行緒池);maximumPoolSize-corePoolSize表示非核心執行緒池。
execute的整個執行流程關鍵是下面兩點:
- 如果工作執行緒數小於核心執行緒池上限(CorePoolSize),則直接新建一個工作執行緒並執行任務;
- 如果工作執行緒數大於等於CorePoolSize,則嘗試將任務加入到佇列等待以後執行。如果加入佇列失敗了(比如佇列已滿的情況),則在匯流排程池未滿的情況下(
CorePoolSize ≤ 工作執行緒數 < maximumPoolSize)新建一個工作執行緒立即執行任務,否則執行拒絕策略。
工作執行緒的建立
瞭解了ThreadPoolExecutor的整個執行流程,我們來看下它是如何新增工作執行緒並執行任務的,execute方法內部呼叫了addWorker方法來新增工作執行緒並執行任務:
/**
* 新增工作執行緒並執行任務
*
* @param firstTask 如果指定了該引數, 表示將立即建立一個新工作執行緒執行該firstTask任務; 否則複用已有的工作執行緒,從工作佇列中獲取任務並執行
* @param core 執行任務的工作執行緒歸屬於哪個執行緒池: true-核心執行緒池 false-非核心執行緒池
*/
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (; ; ) {
int c = ctl.get();
int rs = runStateOf(c); // 獲取執行緒池狀態
/**
* 這個if主要是判斷哪些情況下, 執行緒池不再接受新任務執行, 而是直接返回.總結下, 有以下幾種情況:
* 1. 執行緒池狀態為 STOP 或 TIDYING 或 TERMINATED: 執行緒池狀態為上述任一一種時, 都不會再接受任務,所以直接返回
* 2. 執行緒池狀態≥ SHUTDOWN 且 firstTask != null: 因為當執行緒池狀態≥ SHUTDOWN時, 不再接受新任務的提交,所以直接返回
* 3. 執行緒池狀態≥ SHUTDOWN 且 佇列為空: 佇列中已經沒有任務了, 所以也就不需要執行任何任務了,可以直接返回
*/
if (rs >= SHUTDOWN &&
!(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty()))
return false;
//迴圈CAS增加執行緒數
for (; ; ) {
int wc = workerCountOf(c); // 獲取工作執行緒數
/**
* 這個if主要是判斷工作執行緒數是否超限, 以下任一情況屬於屬於超限, 直接返回:
* 1. 工作執行緒數超過最大工作執行緒數(2^29-1)
* 2. 工作執行緒數超過核心執行緒池上限(入參core為true, 表示歸屬核心執行緒池)
* 3. 工作執行緒數超過匯流排程池上限(入參core為false, 表示歸屬非核心執行緒池)
*/
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c)) // 工作執行緒數加1
break retry; // 跳出最外層迴圈
c = ctl.get();
if (runStateOf(c) != rs) // 執行緒池狀態發生變化, 重新自旋判斷
continue retry;
}
}
//到這裡說明CAS自旋成功了
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask); // 將任務包裝成工作執行緒
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock(); //加入獨佔鎖,為了實現workers同步,因為可能多個執行緒呼叫了執行緒池的execute方法
try {
// 重新檢查執行緒池狀態,以避免在獲取鎖前呼叫了shutdown介面
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
workers.add(w); // 加入工作執行緒集合
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//新增成功後,則啟動任務
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (!workerStarted) // 建立/啟動工作執行緒失敗, 需要執行回滾操作
addWorkerFailed(w);
}
return workerStarted;
}整個addWorker的邏輯並不複雜,分為兩部分:
第一部分雙重迴圈的目的是通過CAS操作增加執行緒數;第二部分主要把併發安全的任務新增到workers裡面,並啟動任務執行。
首先將Runnable任務包裝成一個Worker物件,然後加入到一個工作執行緒集合中(名為workers的HashSet),最後呼叫工作執行緒中的Thread物件的start方法執行任務,其實最終是委託到Worker的下面方法執行:
/**
* 執行任務
*/
public void run() {
runWorker(this);
}工作執行緒的執行
runWoker用於執行任務,整體流程如下:
- while迴圈不斷地通過
getTask()方法從佇列中獲取任務(如果工作執行緒自身攜帶著任務,則執行攜帶的任務); - 控制執行執行緒的中斷狀態,保證如果執行緒池正在停止,則執行緒必須是中斷狀態,否則執行緒必須不是中斷狀態;
- 呼叫
task.run()執行任務; - 處理工作執行緒的退出工作。
final void runWorker(Worker w) {
Thread wt = Thread.currentThread(); // 執行任務的執行緒
Runnable task = w.firstTask; // 任務, 如果是null則從佇列取任務
w.firstTask = null;
w.unlock(); // 允許執行執行緒被中斷
boolean completedAbruptly = true; // 表示是否因為中斷而導致退出
try {
while (task != null || (task = getTask()) != null) { // 當task==null時會通過getTask從佇列取任務
w.lock();
/**
* 下面這個if判斷的作用如下:
* 1.保證當執行緒池狀態為STOP/TIDYING/TERMINATED時,當前執行任務的執行緒wt是中斷狀態(因為執行緒池處於上述任一狀態時,均不能再執行新任務)
* 2.保證當執行緒池狀態為RUNNING/SHUTDOWN時,當前執行任務的執行緒wt不是中斷狀態
*/
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task); // 鉤子方法,由子類自定義實現
Throwable thrown = null;
try {
task.run(); // 執行任務
} catch (RuntimeException x) {
thrown = x;
throw x;
} catch (Error x) {
thrown = x;
throw x;
} catch (Throwable x) {
thrown = x;
throw new Error(x);
} finally {
afterExecute(task, thrown); // 鉤子方法,由子類自定義實現
}
} finally {
task = null;
w.completedTasks++; // 完成任務數+1
w.unlock();
}
}
// 執行到此處, 說明該工作執行緒自身既沒有攜帶任務, 也沒從任務佇列中獲取到任務
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly); // 處理工作執行緒的退出工作
}
}這裡要特別注意第一個IF方法,該方法的核心作用,用一句話概括就是:
確保正在停止的執行緒池(STOP/TIDYING/TERMINATED)不再接受新任務,如果有新任務那麼該任務的工作執行緒一定是中斷狀態;確保正常狀態的執行緒池(RUNNING/SHUTDOWN),其所執行的任務都是不能被中斷的。
另外,getTask方法用於從任務佇列中獲取一個任務,如果獲取不到任務,會跳出while迴圈,最終會通過processWorkerExit方法清理工作執行緒。注意這裡的completedAbruptly欄位,它表示該工作執行緒是否是因為中斷而退出,while迴圈的退出有以下幾種可能:
- 正常情況下,工作執行緒會存活著,不斷從任務佇列獲取任務執行,如果獲取不到任務了(getTask返回null),會置completedAbruptly 為false,然後執行清理工作——
processWorkerExit(worker,false); - 異常情況下,工作執行緒在執行過程中被中斷或出現其它異常,會置completedAbruptly 為true,也會執行清理工作——
processWorkerExit(worker,true);
工作執行緒的清理
通過上面的討論,我們知道工作執行緒是在processWorkerExit中被清理的,來看下定義:
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // 工作執行緒因異常情況而退出
decrementWorkerCount(); // 工作執行緒數減1(如果工作執行緒執行時沒有出現異常, 在getTask()方法中已經對執行緒數減1了)
//統計整個執行緒池完成的任務個數,並從工作集中刪除當前worker
final ReentrantLock mainLock = this.mainLock; //全域性鎖
mainLock.lock();
try {
completedTaskCount += w.completedTasks; // completedTaskCount記錄執行緒池完成的總任務數
workers.remove(w); // 從工作執行緒集合中移除(該工作執行緒會自動被GC回收)
} finally {
mainLock.unlock();
}
tryTerminate(); // 根據執行緒池狀態, 判斷是否需要終止執行緒池
int c = ctl.get();
if (runStateLessThan(c, STOP)) { // 如果執行緒池狀態為RUNNING/SHUTDOWN
if (!completedAbruptly) { // 工作執行緒為正常退出
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && !workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false); // 新建一個工作執行緒
}
}processWorkerExit的作用就是將該退出的工作執行緒清理掉,然後看下執行緒池是否需要終止。
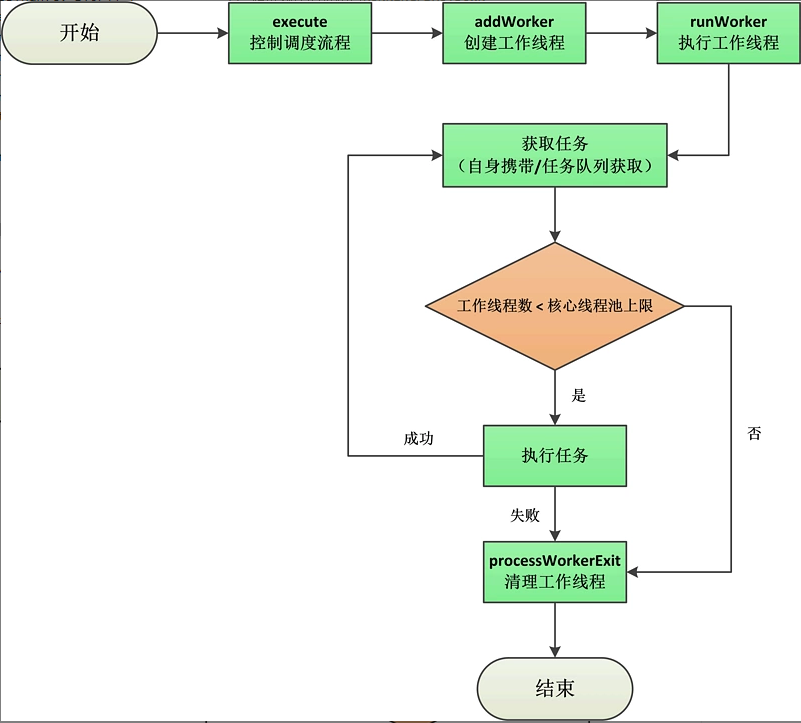
processWorkerExit執行完之後,整個工作執行緒的生命週期也結束了,我們可以通過下圖來回顧下它的整個生命週期:
任務的獲取
最後,我們來看下任務的獲取,也就是runWorker中使用的getTask方法:
private Runnable getTask() {
boolean timedOut = false; // 表示上次從阻塞佇列中取任務時是否超時
for (; ; ) {
int c = ctl.get();
int rs = runStateOf(c); // 獲取執行緒池狀態
/**
* 以下IF用於判斷哪些情況下不允許再從佇列獲取任務:
* 1. 執行緒池進入停止狀態(STOP/TIDYING/TERMINATED), 此時即使佇列中還有任務未執行, 也不再執行
* 2. 執行緒池非RUNNING狀態, 且佇列為空
*/
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount(); // 工作執行緒數減1
return null;
}
int wc = workerCountOf(c); // 獲取工作執行緒數
/**
* timed變數用於判斷是否需要進行超時控制:
* 對於核心執行緒池中的工作執行緒, 除非設定了allowCoreThreadTimeOut==true, 否則不會超時回收;
* 對於非核心執行緒池中的工作執行緒, 都需要超時控制
*/
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 這裡主要是當外部通過setMaximumPoolSize方法重新設定了最大執行緒數時,需要回收多出的工作執行緒
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true; // 超時仍未獲取到任務
} catch (InterruptedException retry) {
timedOut = false;
}
}
}getTask方法的主要作用就是:通過自旋,不斷地嘗試從阻塞佇列中獲取一個任務,如果獲取失敗則返回null。
阻塞佇列就是在我們構建ThreadPoolExecutor物件時,在構造器中指定的。由於佇列是外部指定的,所以根據阻塞佇列的特性不同,getTask方法的執行情況也不同。
| 佇列特性 | 有界佇列 | 近似無界佇列 | 無界佇列 | 特殊佇列 |
|---|---|---|---|---|
| 有鎖演算法 | ArrayBlockingQueue | LinkedBlockingQueue、LinkedBlockingDeque | / | PriorityBlockingQueue、DelayQueue |
| 無鎖演算法 | / | / | LinkedTransferQueue | SynchronousQueue |
我們可以根據業務需求、任務特點等選擇上表中的某一種阻塞佇列,根據Oracle官方文件的提示,任務在阻塞佇列中排隊一共有三種情況:
1.直接提交
即直接將任務提交給等待的工作執行緒,這時可以選擇SynchronousQueue。因為SynchronousQueue是沒有容量的,而且採用了無鎖演算法,所以效能較好,但是每個入隊操作都要等待一個出隊操作,反之亦然。
使用SynchronousQueue時,當核心執行緒池滿了以後,如果不存在空閒的工作執行緒,則試圖把任務加入佇列將立即失敗(execute方法中使用了佇列的offer方法進行入隊操作,而SynchronousQueue在呼叫offer時如果沒有另一個執行緒等待出隊操作,則會立即返回false),因此會構造一個新的工作執行緒(未超出最大執行緒池容量時)。
由於,核心執行緒池是很容易滿的,所以當使用SynchronousQueue時,一般需要將maximumPoolSizes設定得比較大,否則入隊很容易失敗,最終導致執行拒絕策略,這也是為什麼Executors工作預設提供的快取執行緒池使用SynchronousQueue作為任務佇列的原因。
2.無界任務佇列
無界任務佇列我們的選擇主要有LinkedTransferQueue、LinkedBlockingQueue(近似無界,構造時不指定容量即可),從效能角度來說LinkedTransferQueue採用了無鎖演算法,高併發環境下效能相對更好,但如果只是做任務佇列使用相差並不大。
使用無界佇列需要特別注意系統資源的消耗情況,因為當核心執行緒池滿了以後,會首先嚐試將任務放入佇列,由於是無界佇列所以幾乎一定會成功,那麼系統瓶頸其實就是硬體了。如果任務的建立速度遠快於工作執行緒處理任務的速度,那麼最終會導致系統資源耗盡。Executors工廠中建立固定執行緒池的方法內部就是用了LinkedBlockingQueue。
3.有界任務佇列
有界任務佇列,比如ArrayBlockingQueue ,可以防止資源耗盡的情況。當核心執行緒池滿了以後,如果佇列也滿了,則會建立歸屬於非核心執行緒池的工作執行緒,如果非核心執行緒池也滿了 ,才會執行拒絕策略。
拒絕策略
ThreadPoolExecutor在以下兩種情況下會執行拒絕策略:
- 當核心執行緒池滿了以後,如果任務佇列也滿了,首先判斷非核心執行緒池有沒滿,沒有滿就建立一個工作執行緒(歸屬非核心執行緒池), 否則就會執行拒絕策略;
- 提交任務時,ThreadPoolExecutor已經關閉了。
所謂拒絕策略,就是在構造ThreadPoolExecutor時,傳入的RejectedExecutionHandler物件:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}ThreadPoolExecutor一共提供了4種拒絕策略:
1.AbortPolicy(預設)
AbortPolicy策略其實就是丟擲一個RejectedExecutionException異常:
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() {
}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}2.DiscardPolicy
DiscardPolicy策略其實就是無為而治,什麼都不做,等任務自己被回收:
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() {
}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}3.DiscardOldestPolicy
DiscardOldestPolicy策略是丟棄任務佇列中的最近一個任務,並執行當前任務:
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() {
}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) { // 執行緒池未關閉(RUNNING)
e.getQueue().poll(); // 丟棄任務佇列中的最近任務
e.execute(r); // 執行當前任務
}
}
}4.CallerRunsPolicy
CallerRunsPolicy策略相當於以自身執行緒來執行任務,這樣可以減緩新任務提交的速度。
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() {
}
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) { // 執行緒池未關閉(RUNNING)
r.run(); // 執行當前任務
}
}
}四、執行緒池的關閉
ExecutorService介面提供兩種方法來關閉執行緒池,這兩種方法的區別主要在於是否會繼續處理已經新增到任務佇列中的任務。
shutdown
shutdown方法將執行緒池切換到SHUTDOWN狀態(如果已經停止,則不用切換),並呼叫interruptIdleWorkers方法中斷所有空閒的工作執行緒,最後呼叫tryTerminate嘗試結束執行緒池:
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN); // 如果執行緒池為RUNNING狀態, 則切換為SHUTDOWN狀態
interruptIdleWorkers(); // 中斷所有空閒執行緒
onShutdown(); // 鉤子方法, 由子類實現
} finally {
mainLock.unlock();
}
tryTerminate();
}這裡要注意,如果執行Runnable任務的執行緒本身不響應中斷,那麼也就沒有辦法終止任務。
shutdownNow
shutdownNow方法的主要不同之處就是,它會將執行緒池的狀態至少置為STOP,同時中斷所有工作執行緒(無論該執行緒是空閒還是執行中),同時返回任務佇列中的所有任務。
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP); // 如果執行緒池為RUNNING或SHUTDOWN狀態, 則切換為STOP狀態
interruptWorkers(); // 中斷所有工作執行緒
tasks = drainQueue(); // 抽空任務佇列中的所有任務
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}五、總結
最後,我們來回顧下ThreadPoolExecutor的整體結構,ThreadPoolExecutor的核心方法是execute,控制著工作執行緒的建立和任務的執行,如下圖:
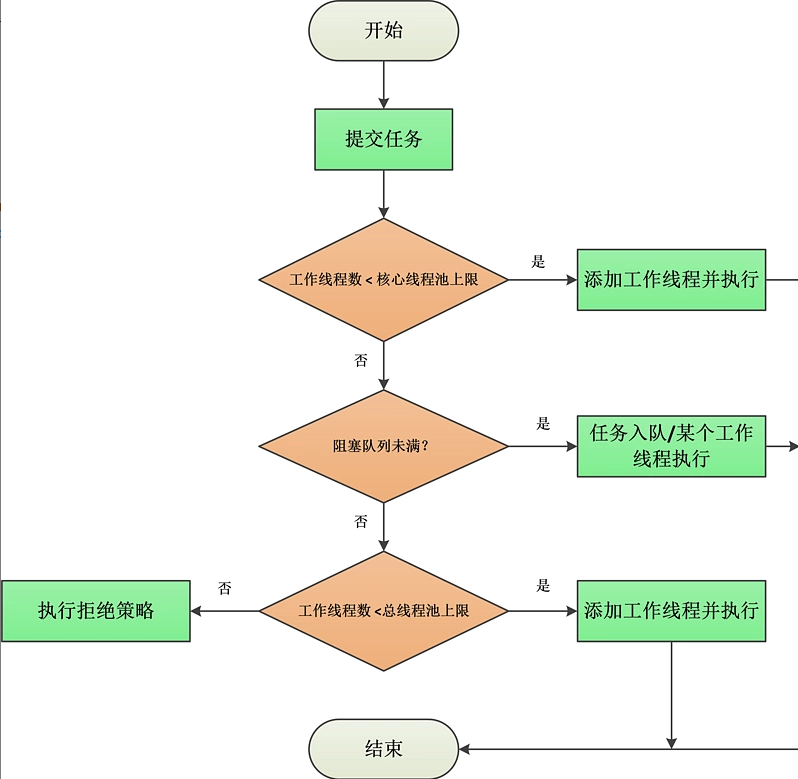
同時,ThreadPoolExecutor中有幾個比較重要的元件:阻塞佇列、核心執行緒池、拒絕策略,它們的關係如下圖,圖中的序號表示execute的執行順序,可以配合上面的流程圖來理解:
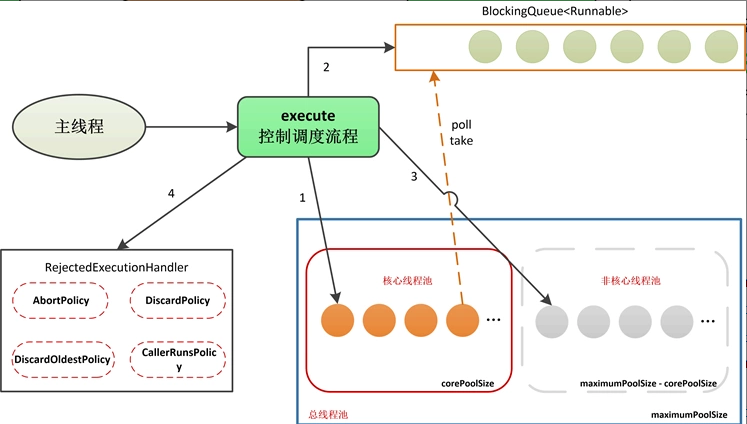
關於ThreadPoolExecutor這個執行緒池,最重要的是根據系統實際情況,合理進行執行緒池引數的設定以及阻塞佇列的選擇。現實情況下,一般會自己通過ThreadPoolExecutor的構造器去構建執行緒池,而非直接使用Executors工廠建立,因為這樣更利於對引數的控制和調優。
另外,根據任務的特點,要有選擇的配置核心執行緒池的大小:
- 如果任務是 CPU 密集型(需要進行大量計算、處理),則應該配置儘量少的執行緒,比如 CPU 個數 + 1,這樣可以避免出現每個執行緒都需要使用很長時間但是有太多執行緒爭搶資源的情況;
- 如果任務是 IO密集型(主要時間都在 I/O,CPU 空閒時間比較多),則應該配置多一些執行緒,比如 CPU 數的兩倍,這樣可以更高地壓榨 CPU。
ThreadPoolExecutor到此就介紹完了,下一節我們將介紹一種可控制任務執行週期的執行緒池——ScheduledThreadPoolExecutor,其實我們之前講ScheduledExecutorService介面的時候已經接觸過了,下一節會深入它的實現原理。
說明:
執行緒池巧妙地使用一個Integer型別地原子變數來記錄執行緒池狀態和執行緒池中地執行緒個數。通過執行緒池狀態來控制任務地執行,每個worker執行緒可以處理多個任務。執行緒池通過執行緒地複用減少了執行緒地建立和銷燬地開銷。
參考書籍
Java併發程式設計之美
本文參考