
新東方的Kubernetes實踐:從服務化ES到Kafka和Redis
2017年,新東方開始了利用容器化手段將中介軟體業務服務化的探索,基於Rancher 1.6使用ES;2019年,新東方再次開始了擴大了中介軟體的業務服務化,基於Kubernetes使用Kafka、ES和Redis。在服務化的過程中新東方遇到哪些問題?又有何展望?


新東方資訊管理部平臺架構負責人 姜江

新東方資訊管理部高階運維工程師 陳博暄
2017年,新東方開始了利用容器化手段將中介軟體業務服務化的探索,基於Rancher 1.6使用ES;2019年,新東方再次開始了擴大了中介軟體的業務服務化,基於Kubernetes使用Kafka、ES和Redis。利用容器化手段將中介軟體服務化,有效提升了運維團隊的工作效率,極大地縮短了軟體開發流程。本文將分享新東方在中介軟體服務化上的嘗試。

從幼兒園、小學、中學、大學和出國留學,新東方几乎涉及了每一個教育領域。我們的教育產品線非常長,也非常複雜。那麼,這麼長的教育線,我們是用怎樣的IT能力進行支援的呢?——新東方雲。
我們目前有16個雲資料中心,包括自建、租用IDC,我們還通過雲聯網直接連線了阿里雲和騰訊雲,最終形成了一套橫跨多個雲提供商的混合雲架構。新東方的雲體系很特別,你可以在裡面看到一些相對傳統的部分,比如SQL Server、windows和櫃面服務程式。但也有比較新潮的東西,比如TiDB、容器、微服務等等。除此之外,還能找到視訊雙師、互動直播等偏網際網路應用的部分。一個企業的IT架構和一個企業的業務階段是密切相關的。新東方和萬千從傳統業務走向網際網路+的企業一樣,正處於數字化轉型的關鍵階段。

接下來我們來談一談新東方的容器化之路。新東方做容器也很多年了。2016年,新東方嘗試了基於Docker Swarm的一些商業方案方案,不是很理想。2017年正是容器編排架構風雲變換的一年,我們選擇了Rancher的Cattle引擎開始了容器化的自主建設,同時也在觀望業界動向。到了2018年,新東方的容器建設再次進化,最終全面轉向了K8S。

那麼在新東方是怎麼看待K8S的呢?我們認為K8S是介於PaaS和IaaS層之間的中間層,對下層的IaaS層和上層的PaaS層都制定了介面和規範。但是並不關心功能實現。而我們要做一套完整的容器雲,只有K8S是遠遠不夠的,還需要引入其他開源元件進行補充。

從上圖可以發現,我們利用各種開源組補充K8S生態,組合成目前的新東方的容器雲平臺。
我們的執行時元件基於Docker,Host主機作業系統選擇的是Ubuntu,K8S網路元件用的是Canal,同時採用Mellanox網絡卡加速技術。Rancher 2.0作為我們的k8s管理平臺,提供多租戶管理、視覺化、許可權對接AD域等重要功能,幫助我們避免了大量的後臺整合整合工作,為我們節約了人力的同時提供了一套穩定的圖形化管理平臺。
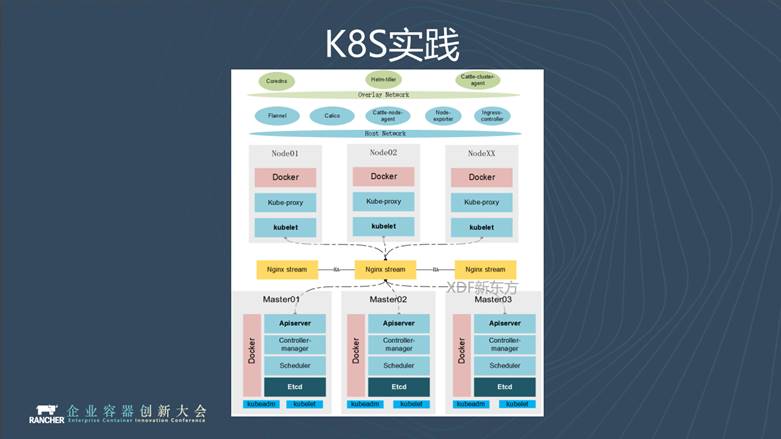
下面介紹一下我們的K8S實踐, 從上圖可以看到,我們完全基於原生社群版本的K8S。通過kubeadm工具和nginx stream負載均衡部署成一個三節點HA架構。
叢集關鍵元件執行在host網路模式。這樣可以減少網路上的資源消耗,獲得更好地效能,比如Ingress元件,通過Flannel構建overlay容器網路,執行上層應用。

使用容器肯定需要涉及到映象管理。新東方是早期Harbor的使用者,我們從1.2版本就開始用Harbor,後端儲存對接ceph物件儲存。目前,我們在嘗試映象分發的功能,使用的是阿里雲開源的Dragonfly。它可以將南北向的下載流量轉換為東西向,使映象在node之間複製成為可能。當叢集規模非常大的時候,減緩拉取映象對Harbor伺服器造成的壓力負載。
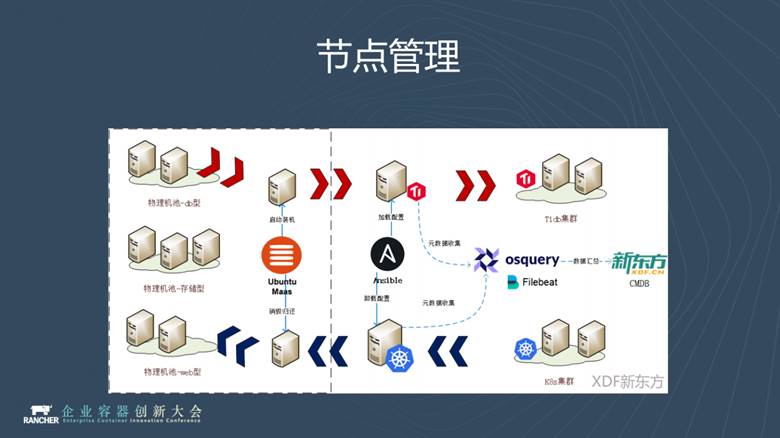
我們的K8S叢集是完全跑在物理機上的,當叢集規模大了之後,物理機增多,我們必須要引用物理機的管理軟體減少我們的運維成本。
在這裡,我們使用的是Ubuntu的Maas,它是個裸機管理平臺,可以將沒有作業系統的物理機,按照模板裝成指定的標準物理機。我們再結合Ansible playbook初始化物理節點,將它變成我們想要的物理機節點,加入到叢集裡邊。
從上圖中可以看到,通過載入TiDB的role把標準物理機變成TiDB的節點,通過K8S的role把標準物理機變成K8S節點,我們會在每一種role裡將Osquery和Filebeat推到物理機上,它們可以收集物理機的機器資訊,推送到CMDB進行資產管理。

我們的CI/CD是基於業務來區分的,有一部分我們直接對接新東方自己的Jenkins,另一部分業務直接對接Rancher Pipeline功能來實現CI/CD。
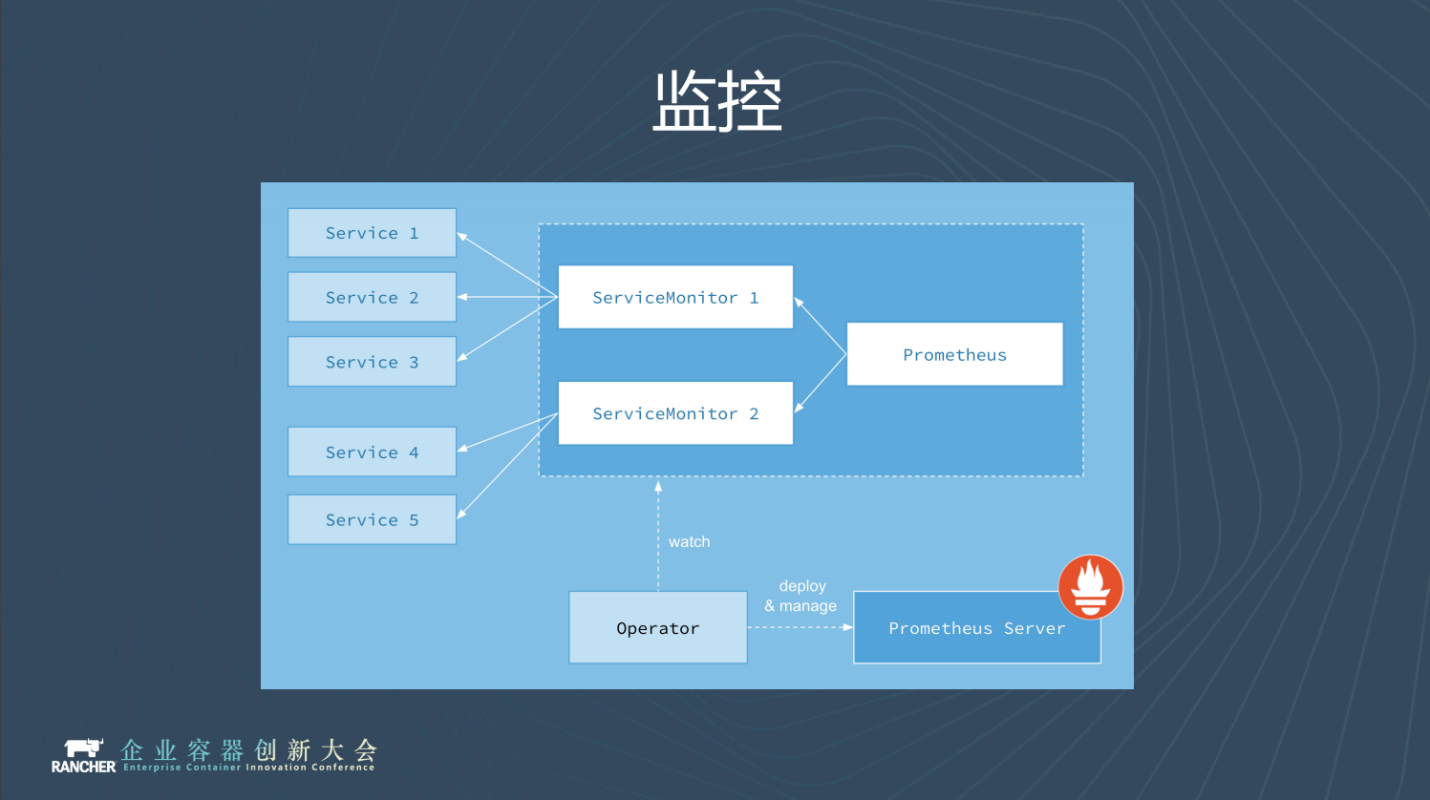
叢集監控方面,我們現在用的是開源社群Prometheus的Operator。一開始我們用的是原生的Prometheus,但是原生的Prometheus在配置告警發現和告警規則上特別麻煩。
引用了Operator以後,Operator幫我們簡化了配置的過程,比較好用,推薦大家使用。
值得一提的是,Rancher 2.2版本之後的叢集監控都是基於Prometheus Operator,大家感興趣的話,可以回去下一個新版本的Rancher體驗一下。
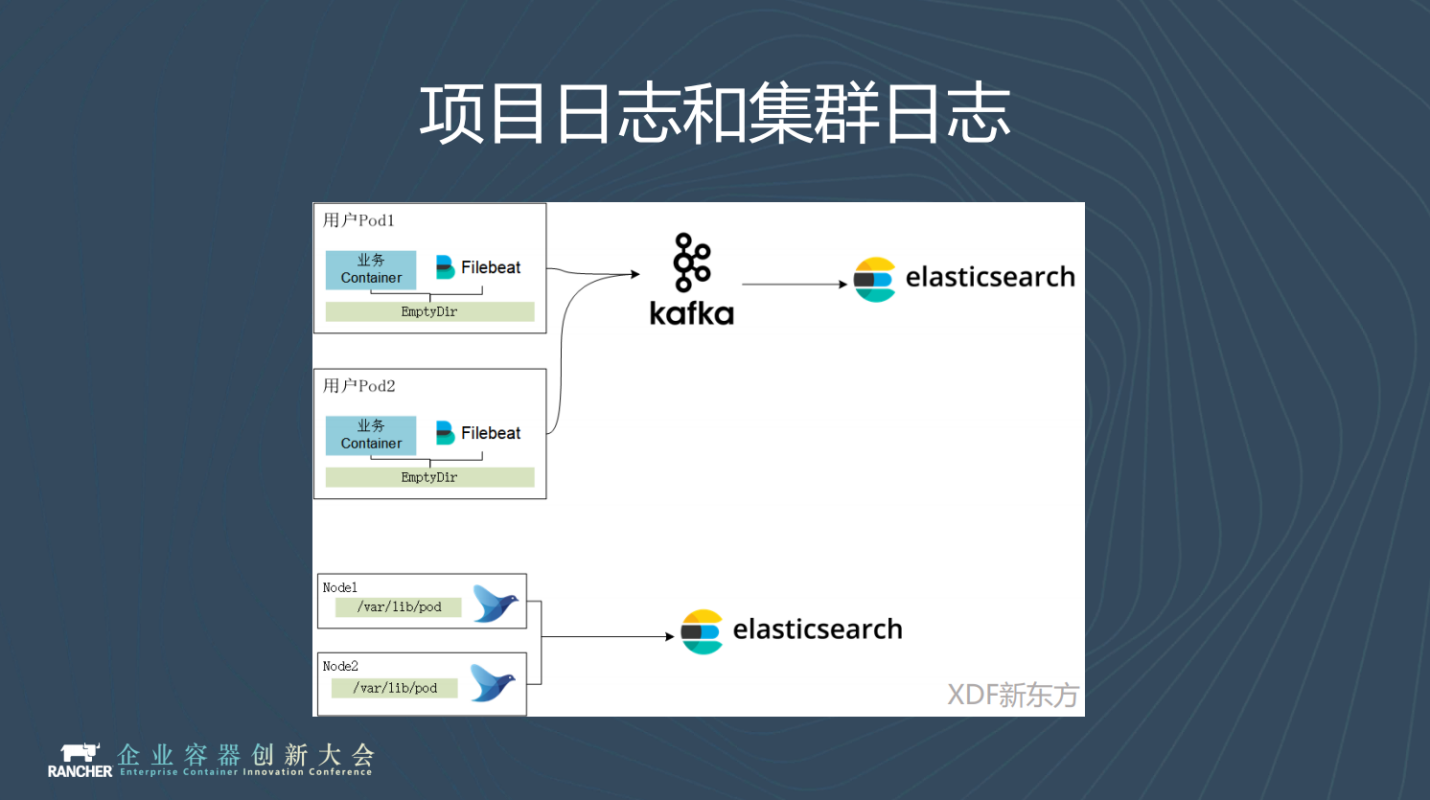
我們的日誌是針對兩個級別來設定的。業務日誌通過sidecar的方式執行filebeat,把資料收集到kafka叢集裡面,再由logstash消費到ES,可以減輕ES的壓力負載。
另一方面是叢集層面,叢集層面的日誌通過Rancher 2.2提供日誌收集功能,用fluentd收集到ES叢集當中。
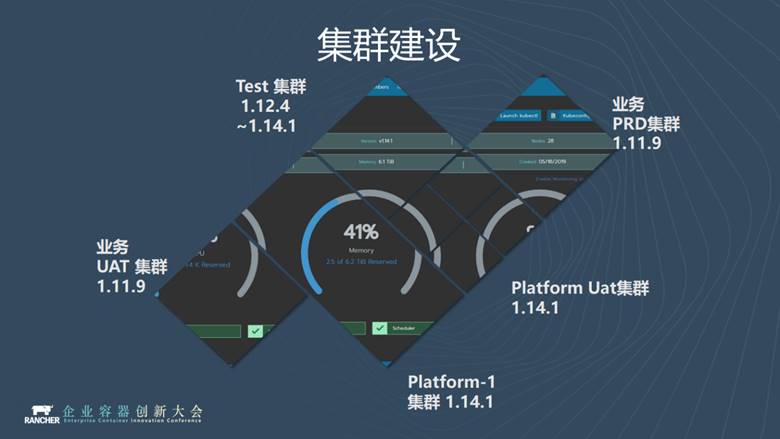
我們一共有五套叢集,一個是跑線上業務的,生產和測試兩套;一個是Platform1叢集,跑中介軟體類應用,比如ES、Redis、Kafka,也是分生產和測試兩套;還有一個是測試叢集,它是測試功能的,K8S叢集升級迭代、測試新的元件、測試新的功能都是在這個叢集上完成的。
可能細心的朋友發現我們的叢集是1.14.1版本的,版本非常新,為什麼?因為Kubernetes 1.14有一個非常重要的功能,叫local PV,目前已經GA,我們非常看中這個功能,因此將叢集一路升級到1.14。

目前,業務應用主要是兩個方面:
-
掌上泡泡APP以及新東方APP後端服務都跑在容器雲架構上。
-
中介軟體的服務化,比如Kafka、Redis、ES叢集級別的中介軟體服務都跑在我們的容器雲架構上。
為什麼要將中介軟體服務化?
那麼,我們為什麼要將中介軟體服務化呢?

在我們看來,中介軟體比如ES、佇列、Redis快取等都有幾個共同的特點,就像圖中的怪獸一樣,體型很大。
我舉個例子做個比較: 比如我啟動一個業務的虛機,4C8G比較常見,起10個就是40C 80G。作為對比, 40C80G是否能啟動一個elasticsearch的節點呢? 40C 80G啟動一個es節點是很緊張的。實際生產中, 一個高吞吐的ES節點一般需要100G以上的記憶體。從這個例子我們就可以體會到中介軟體類負載的單體資源消費非常的大。
另外,中介軟體在專案中應用非常廣,隨便一個應用,肯定會使用Redis、MQ等元件。隨便一個元件單獨部署就要佔用佔多臺虛機。各個專案又都希望自己能有個小灶,希望自己能獨佔一個環境。而小灶對資源的耗費就更多,加上中介軟體不可避免的各種版本、各種配置不一樣,我們需要僱傭非常多的人來維護中介軟體,這就是一個很大的問題。
當然,如果整個公司一共也就有十來個專案的話,完全使用虛機也可以。但是新東方現在有三四百個專案,中介軟體消耗了相當大的資源。如果全部用虛機資源的話,成本還是很高的。

那我們怎麼解決這個問題呢?我們祭出三箭:容器化、自動化、服務化。
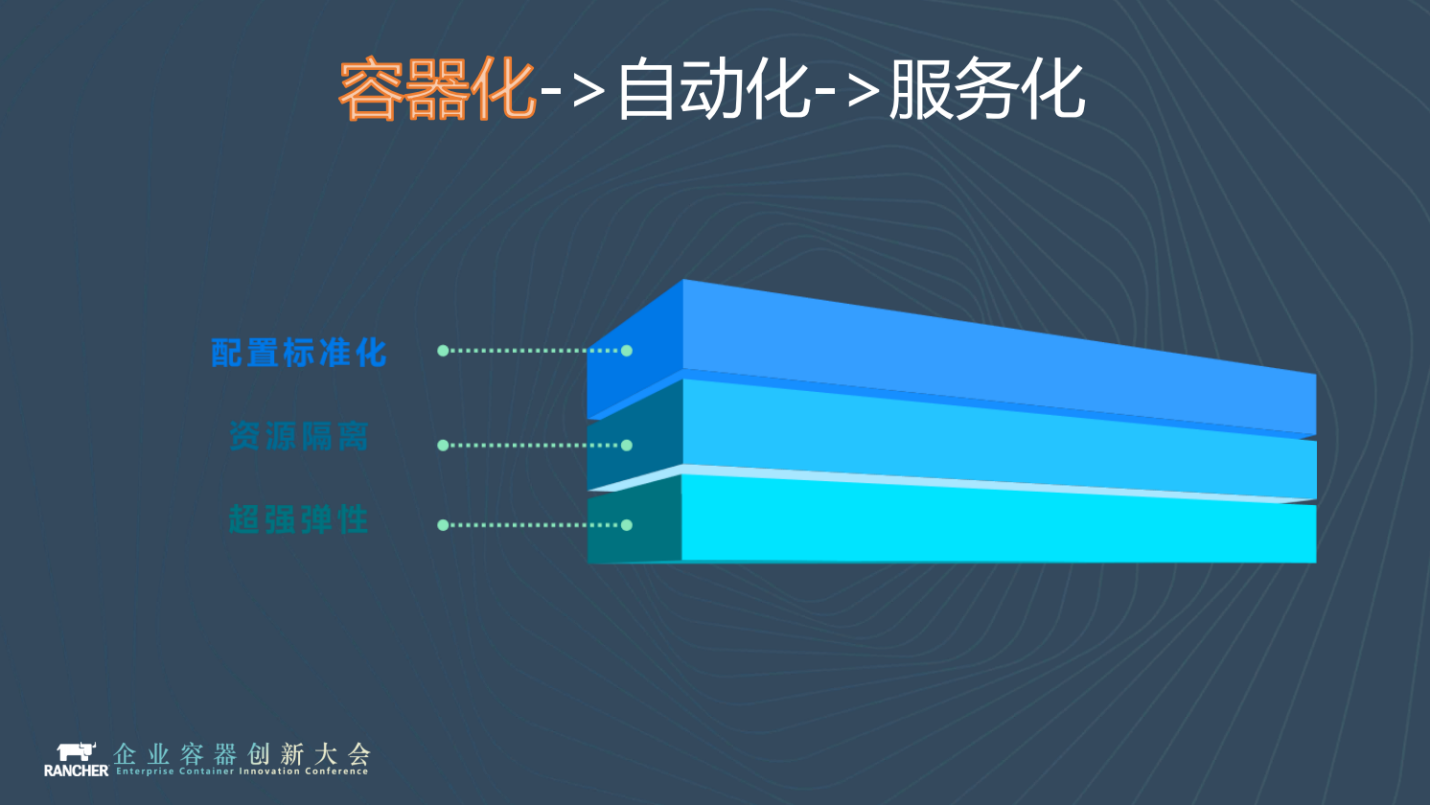
容器化最好理解,剛才提到了雜七雜八的各種配置,通通用容器來統一,你必須按我的標準來。直接將容器部署到物理機,以獲得更好的效能和彈性。

容器化的下一步是自動化,自動化更精確地說其實是程式碼化。就是將基礎設施程式碼化,以程式碼上線迭代的方式管理基礎設施。我們使用Helm和Ansible來實現程式碼化和自動化。

前面兩步都做好之後,我們就可以進入到第三步。如果我們拿自己的管理規範和最佳實踐去約束大家,可能作用並不大。最簡單的辦法就是服務輸出,讓大家來用我們的服務。
逐漸地將小灶合併成大鍋飯,削峰填谷,也避免了資源的浪費。每個公司多少多有一些超級VIP的專案. 這種業務就變成了大鍋飯裡面單獨的小灶。同樣是大鍋飯的機制,但我單獨為你提供資源隔離、許可權隔離。
在服務化之前,我們對運維人員更多的理解是專案的勞務輸出。每天都很忙,但也看不到做太多成果。服務化之後,我們將勞務輸出轉變為對服務平臺的建設,賦能一線人員,讓二線人員做更有意義的事。
我們的實踐:ELK/ES
接下來,我們來逐一講解新東方各個中介軟體編排的方式。

Elastic公司有個產品叫做ECE,是業內第一個容器化管理ES的平臺,ECE基於K8S的1.7(也可能是1.8)實現。通過容器的方式、用物理機為使用者提供各個版本的ES例項。但是它也存一些侷限性:只能管ES,其他的中介軟體管不了。
這對我們啟發很大,我們就想能不能用Rancher+Docker的方式,模仿製作一個我們自己服務平臺。於是誕生了我們的第一版平臺,來使用Rancher 1.6管理ELK。

上圖就是我們的ELK叢集,它是橫跨Rancher 1.6和k8s和混合體,目前處於向k8s遷移的中間狀態。

ELK的編排方式我們有兩個版本:UAT環境的編排和生產編排。在UAT環境我們採用rook(ceph)的方案, ES節點用Statefulset方式啟動。這種方案的好處是萬一哪個節點掛了,儲存計算完全分離,你想漂移到哪裡就可以漂移到哪裡。

我們的生產環境會比較不一樣,我們將每個ES節點都做成一個deployment,我們不讓它漂移,用Taint和label將deployment限定在某一主機上。POD的儲存不再使用RBD,直接寫入本地磁碟hostpath, 網路使用host網路獲取最好的效能。
如果掛了怎麼辦呢?掛了就等待就地復活,機器掛了就地重啟,換盤或者換硬體。如果還不能復活怎麼辦呢?我們有個機器的管理,機器幹掉,直接從池裡面重新拉一臺新機器出來,上線,利用ES的複製功能把資料複製過去。

大家可能會很奇怪,你們怎麼搞兩套方案,而且生產編排還那麼醜?
我們認為簡約架構才是最美架構,中間環節的元件越少,故障點也越少,也就越可靠。本地磁碟的效能要優於RBD,本地網路要優於K8s網路棧。最重要的是:我們編排的這些中介軟體應用,實際上全部都是分散式的(或者內建HA架構),他們都有內建的副本機制,我們完全不用考慮在K8S這一層做保護機制。
我們也實驗對比過這兩種方案,如果節點掛掉,本地重啟的時間要遠低於漂移的時間,RBD有時候還會出現漂移不過去的問題。物理節完全掛掉的機率還是很小的。所以我們最終在線上環境選擇了稍微保守一點的方案。
我們的實踐:Redis
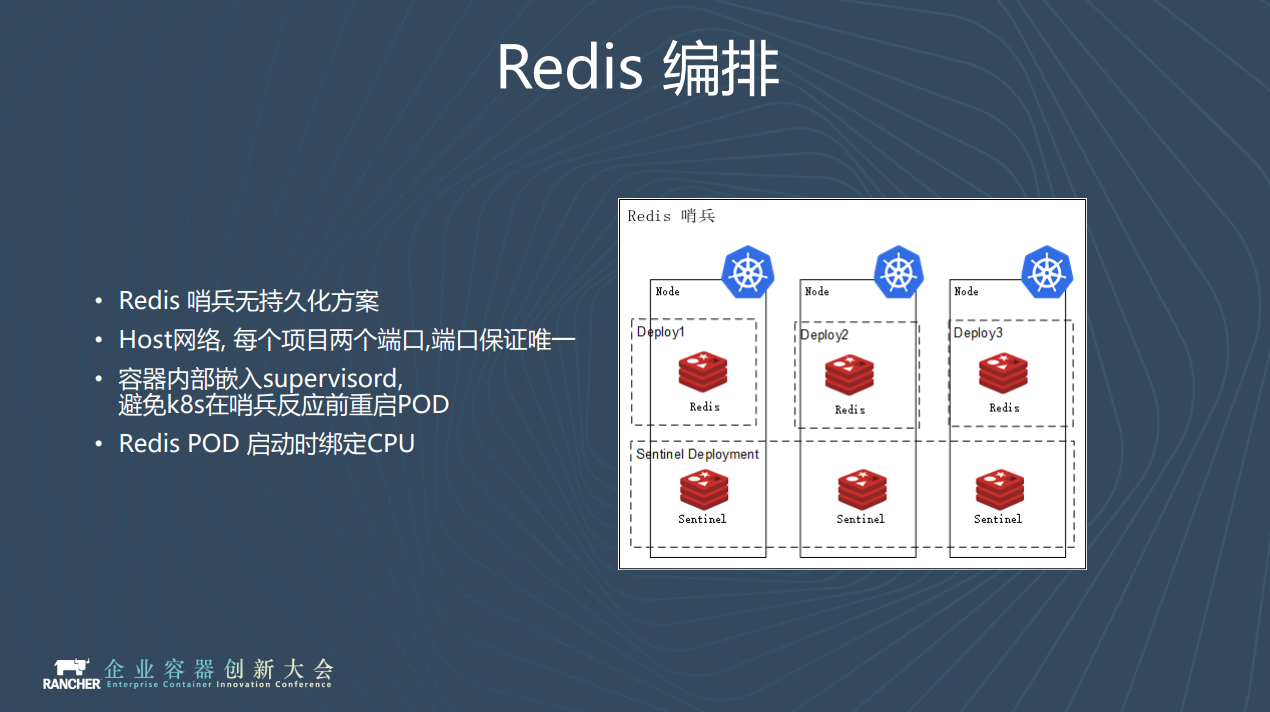
我們現在的Redis主要是哨兵的方案,同樣採用deployment限定到特定節點的方式編排。我們的Redis不做任何持久化,純作為cache使用。這就會帶來一個問題:假如master掛了,那麼K8S就會馬上重啟,這個重啟時間是一定小於哨兵發現它掛了的時間。它起來之後還是master,是個空空的master,隨後剩下的slave中的資料也會全部丟掉,這是不可接受的。
我們先前也做了很多調研,參考攜程的做法, 在容器啟動的時候用Supervisord來啟動Redis,即使POD中的Redis掛掉也不會馬上重啟POD,從而給哨兵充分的時間進行主從切換,然後再通過人工干預的方式恢復叢集。
在Redis的優化上,我們為每個Redis例項繫結CPU。我們知道 Redis程序會受到CPU上下文切換或者網絡卡軟中斷的影響。因此我們在Redis例項所在node上做了一些限制,並打上了taint。我們把作業系統所需要的程序全部要綁到前N個CPU上,空出來後面的CPU用來跑Redis。在啟動Redis 的時候會將程序和CPU一一對應,獲得更佳的效能。
我們的實踐:Kafka

眾所周知,Kafka是一種高吞吐量的分散式釋出訂閱訊息,對比其他中介軟體,具有吞吐量高、資料可持久化、分散式架構等特點。

那麼,新東方是怎樣使用Kafka的?對Kafka叢集有什麼特殊的要求呢?
我們按照業務應用場景來分組,會劃分為三類:第一類是使用Kafka作為交易類系統的訊息佇列;第二類是使用Kafka作為業務日誌的中介軟體;第三類是Kafka作為交易類系統的訊息佇列。
如果想滿足這三類應用場景,我們的Kafka就必須滿足安全要求。比如不能明文傳輸交易資料,所以一定要進行安全加密。
下面,我們來講解一下Kafka原生的安全加密,我們是怎麼做的?又是如何選擇的?

除了金融行業以外,其他行業使用Kafka一般不會使用它們的安全協議。在不使用安全協議情況下,Kafka叢集的效能非常好,但是它明顯不符合新東方對Kafka叢集的要求,所以我們開啟了資料加密。
我們使用Kafka原生支援,通過SSL對Kafka進行通道加密,使明文傳輸變成密文傳輸,通過SASL進行使用者驗證,通過ACL控制它的使用者許可權。
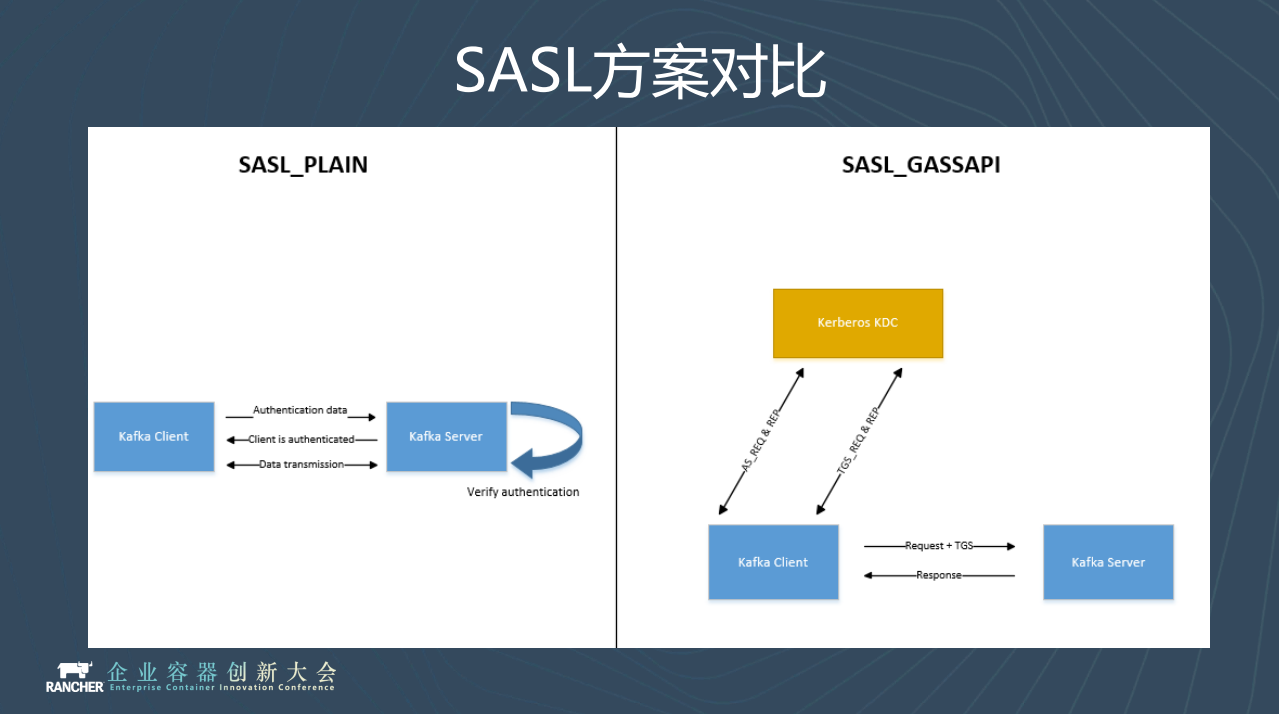
我們簡單看一下兩種SASL使用者認證的區別。SASL_PLAIN是將使用者名稱密碼以明文的方式寫在jaas檔案裡面,然後將jaas檔案以啟動引數的形式載入到Kafka程序裡面,這樣Kafka的client端訪問伺服器的時候會帶著jaas檔案去認證,就啟動了使用者認證。
SASL_GASSAPI是基於Kerberos KDC網路安全協議,熟悉AD域的朋友肯定了解kerberos,AD域也用到了Kerberos網路安全協議,客戶端直接請求KDC伺服器和KDC伺服器互動,實現使用者認證。
兩種方法各有利弊,最終新東方選擇的是第一個SASL_PLAIN的方式,原因很簡單,這樣我們可以避免單獨維護KDC服務,減少運維部署成本。但是這種方法有一個問題,因為Kafka使用者名稱和密碼都是通過這個程序載入進去的,你想改檔案比如新增使用者、修改使用者密碼,那你就必須重啟Kafka叢集。
重啟Kafka叢集勢必對業務造成影響,這是不能接受的。因此我們採用變通的方法, 按照許可權分組,總共在jaas檔案裡面預先設定了150個使用者,管理員為專案分配不同的使用者.這樣就避免了增加專案重啟叢集的尷尬。

如上圖, 我們在Kafka叢集上我們開放了兩個埠,一個是帶使用者認證並且帶SSL加密的埠,另一個是沒有SSL加密,只啟用了使用者認證的SASL_PLAIN埠。連線Kafka的客戶端根據自己的需求選擇埠進行訪問。
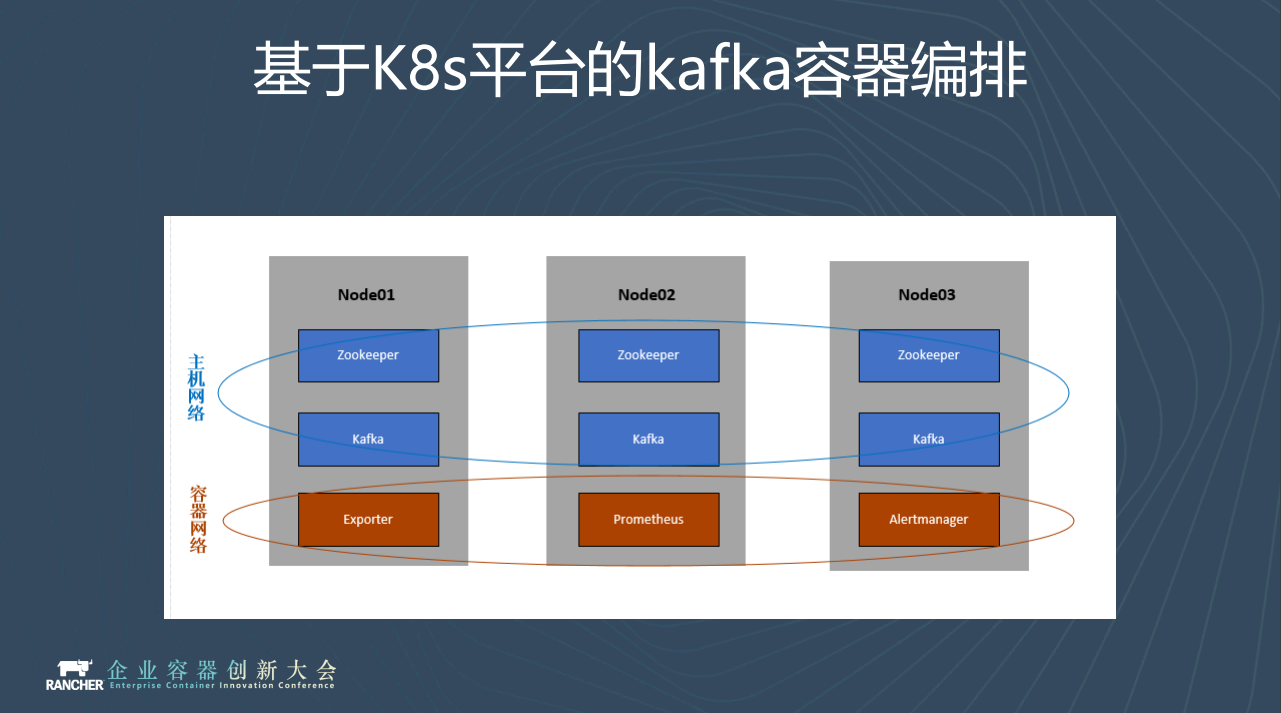
說完架構,我們來說說kafka的編排。我們kafka和zk叢集都通過host網路部署,資料卷通過hostpath方式落到本地物理機,以獲取更好地效能。
Kafka和zk都是單個deployment部署,固定在節點上,即使出現問題我們也讓他在原機器上重新啟動,不讓容器隨意遷移。
監控方面採用exporter+Prometheus方案,執行在overlay的容器網路。
我們的實踐:服務化平臺
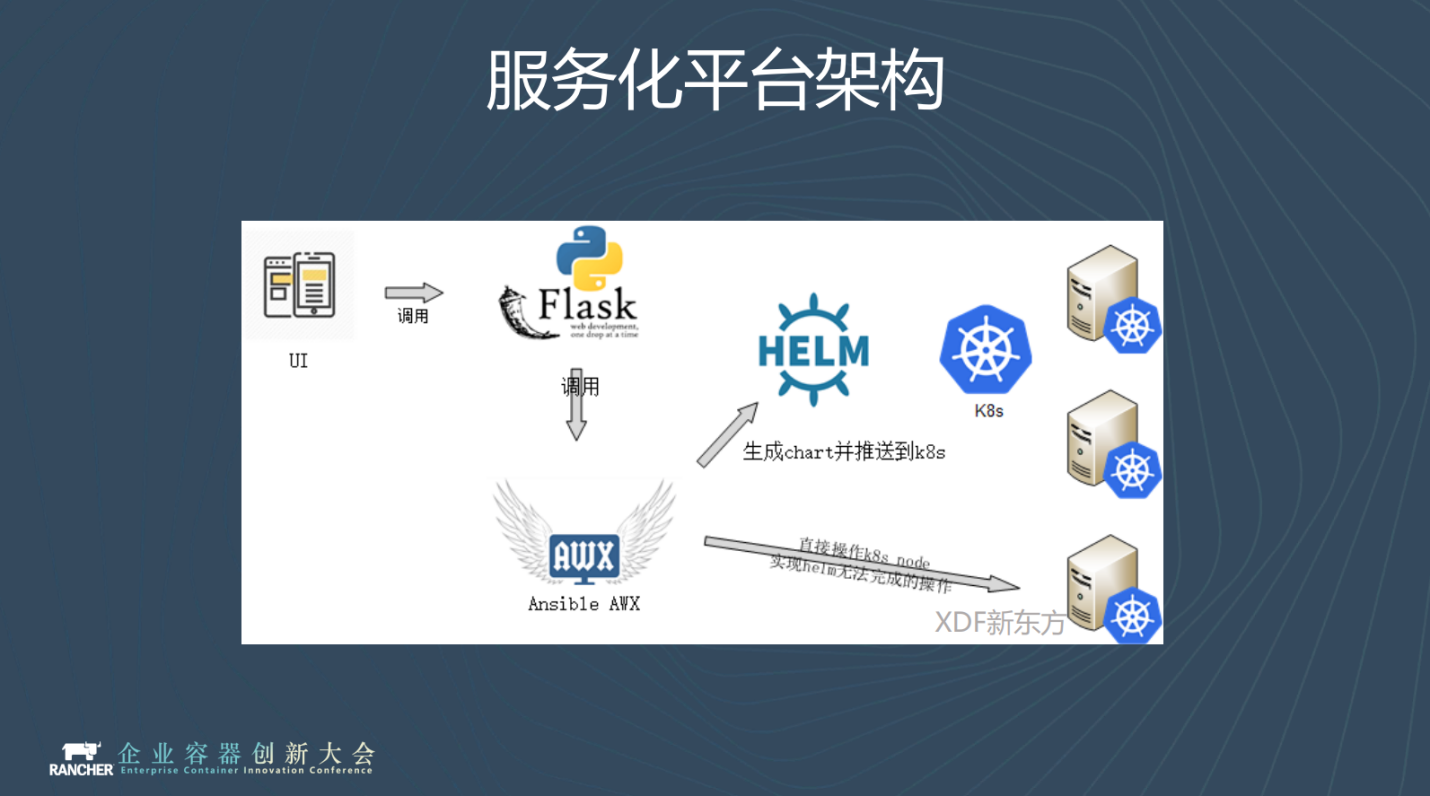
我們在做這個服務化平臺時想法很簡單:不要重複發明輪子,儘量利用已有技術棧,組合helm、ansible、k8s。
以kafka為例, ansible 會根據環境生成helm chart , 像ssl證書,預埋使用者配置等是由ansible按照使用者輸入進行生成,生成的結果插入到helm chart中,隨後helm根據chart建立對應例項。
以下是我們平臺1.0 Demo的一些截圖。
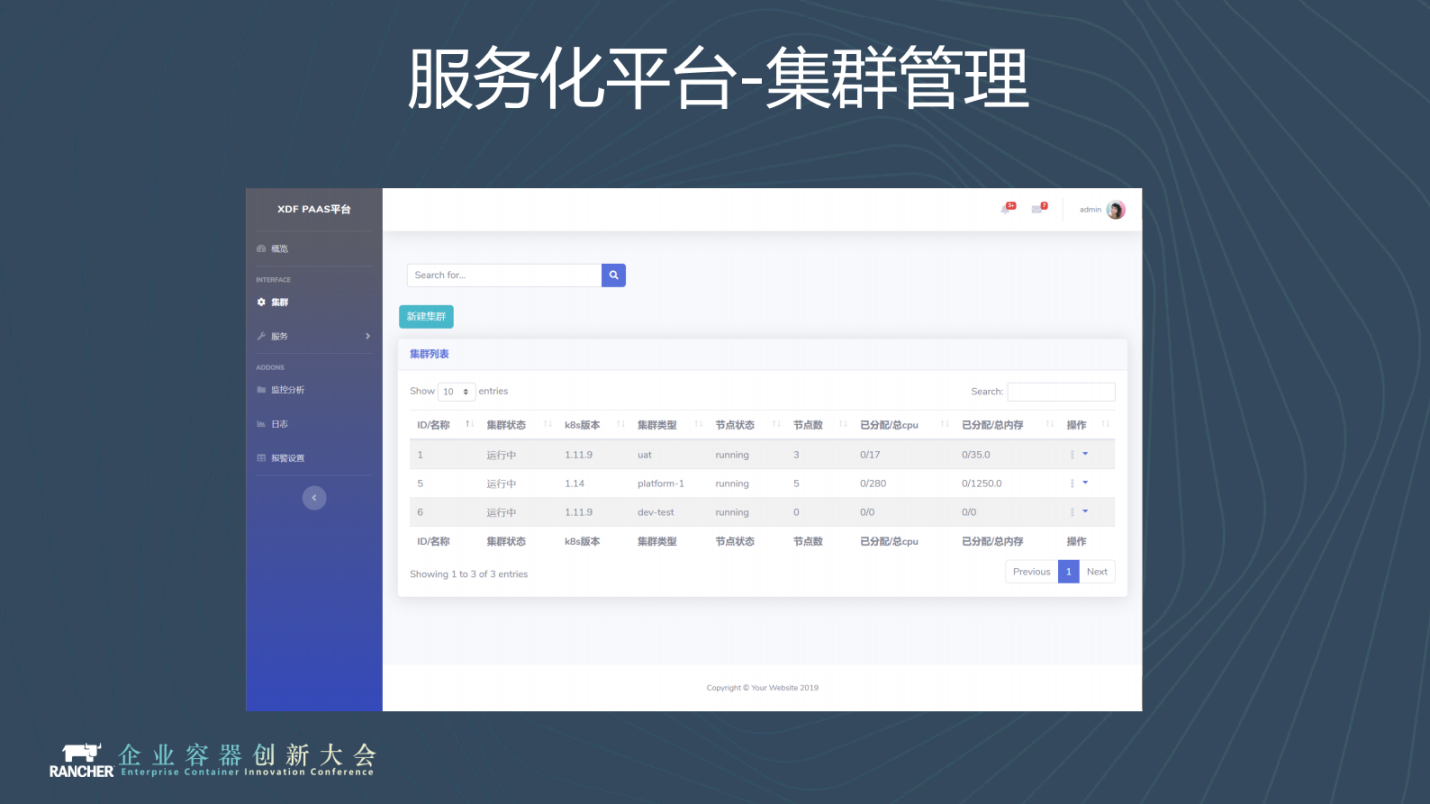
這是叢集管理,部署到不同的叢集上會有不同叢集的入口維護它的狀態。

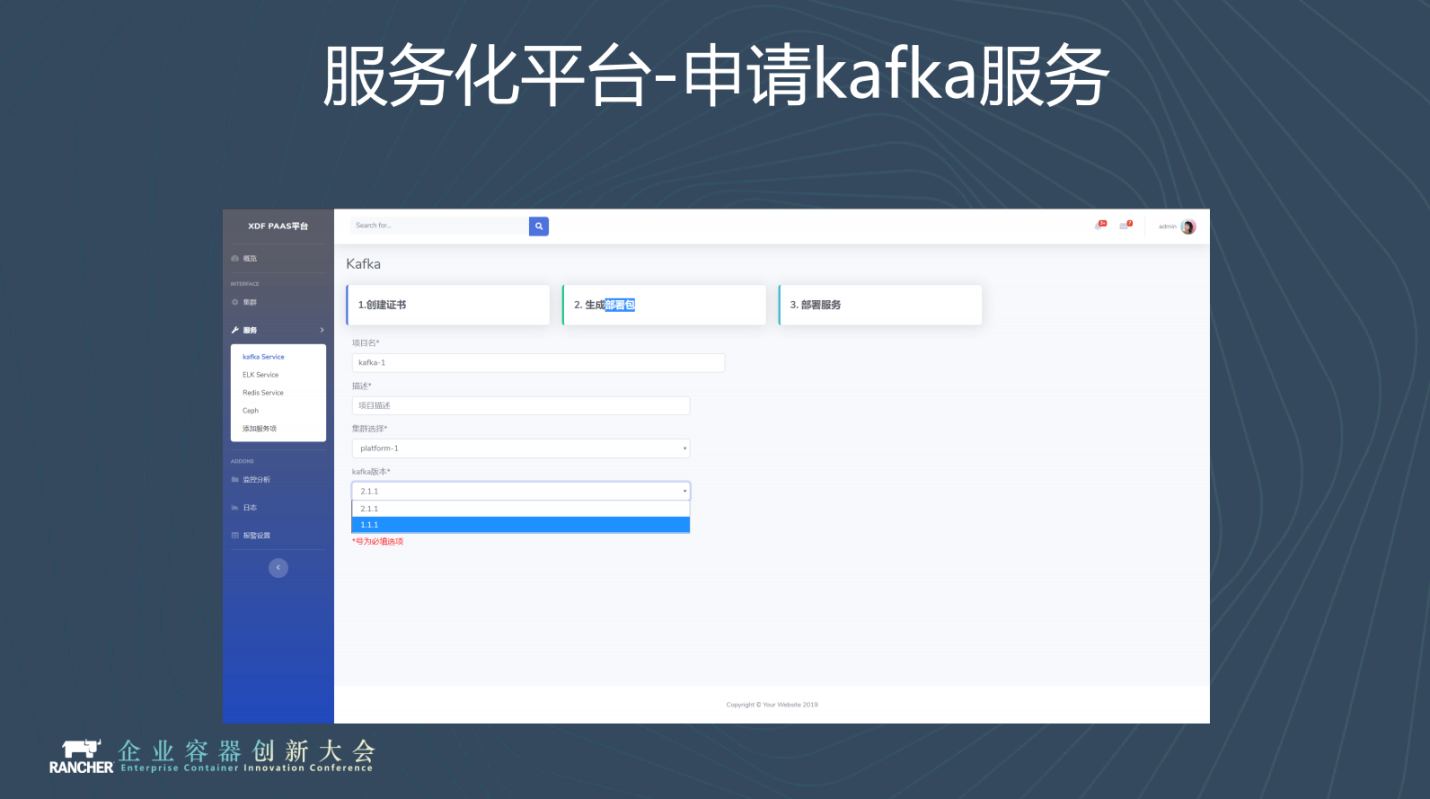
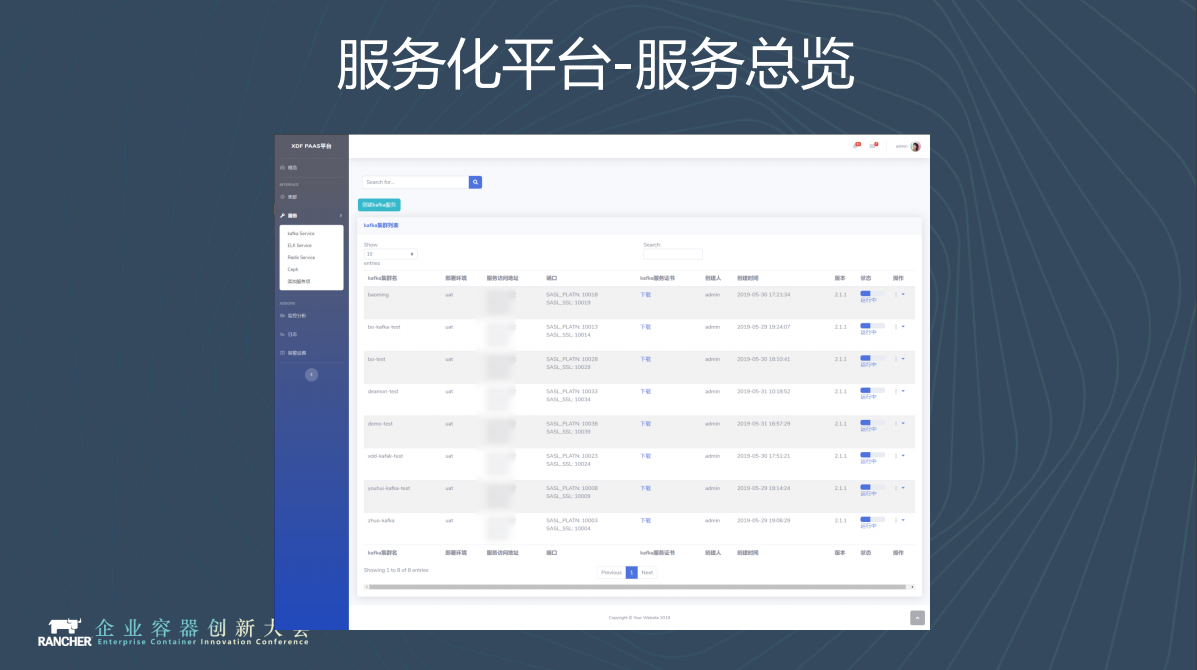
上面展示的是申請服務的步驟。整個步驟非常簡單,選中叢集和想要的版本就可以了。
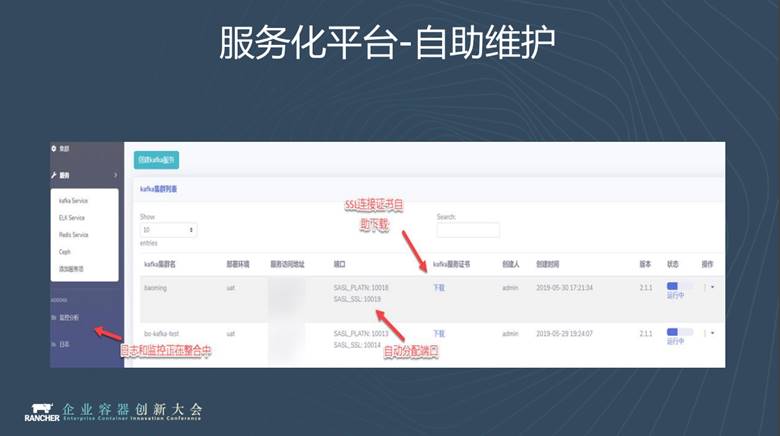
在這個管理介面,你可以看到你的IP、訪問入口、你的例項使用的埠(埠是平臺自動分配的)。如果是SSL連線,你還可以得到你的證書,可以在頁面上直接下載。我們後期還會將叢集的日誌都接入到平臺中。

我們的後臺還是挺複雜的。後臺使用ansible 的AWX平臺。這裡可以看到建立一個叢集其實需要很多的輸入項,只不過這些輸入項我們在前臺介面中就直接幫使用者生成出來了。


這是部署出來的完整的Kafka叢集,有Zookeeper,有Kafka,有監控用的exporter等。我們為每個叢集都配置了一個kafka Manager,這是一套圖形化的管理控制檯,你可以直接在manager中管理kafka。
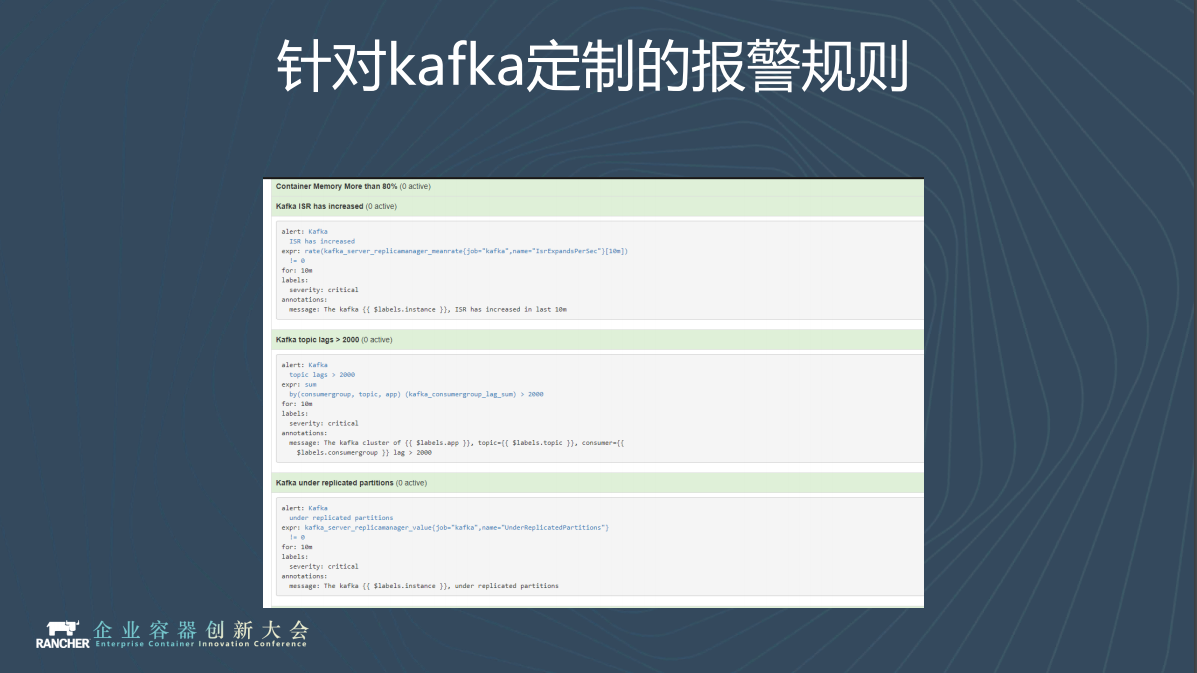
監控報警是必不可少的,我們基於Prometheus Operator做了一些預置的報警規則。比如topic是否有延遲。當叢集生成後,Operator會自動發現你的端點,也就是我們剛看的exporter,operator發現端點後就開始自動加入報警,完全不需要人工接入。
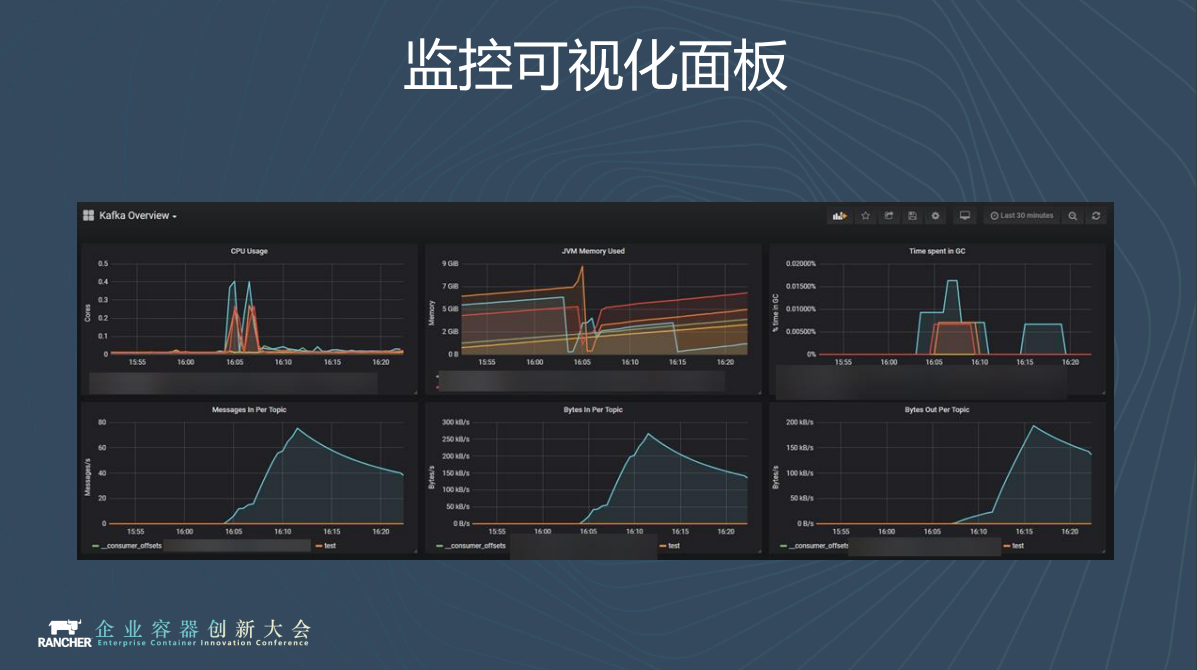
我們為每個專案生成了視覺化面板,需要監控的時候可以直接登入Grafana檢視。
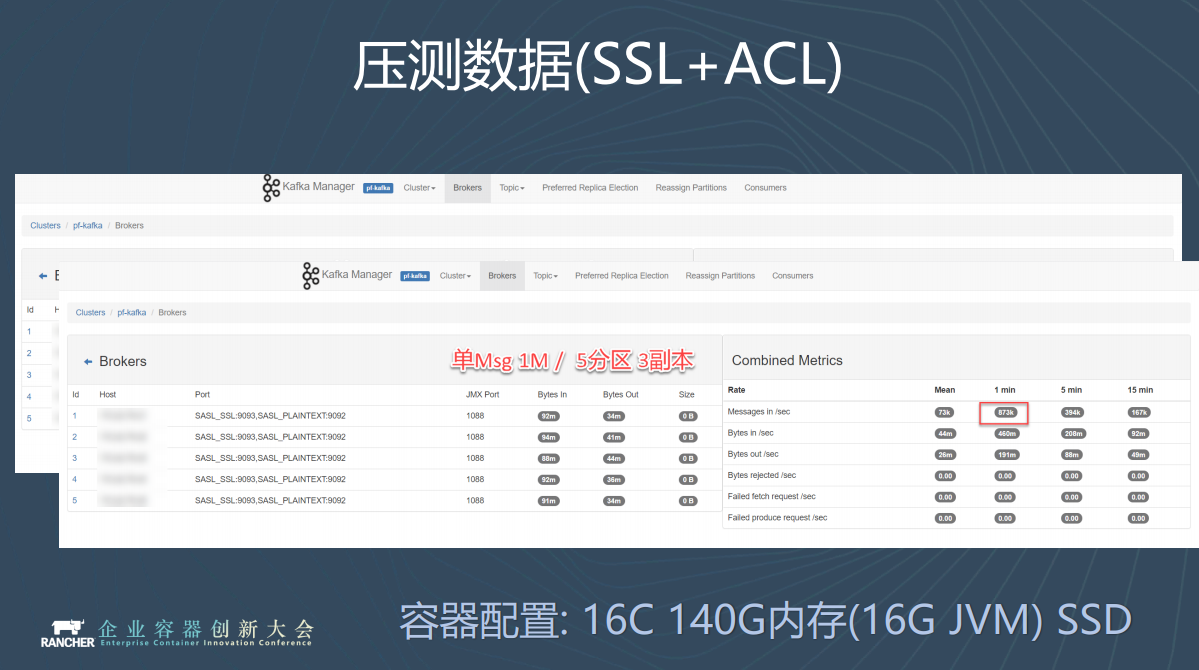
上圖是簡單的壓測結果。512K的Message,SSL+ACL的配置五分割槽三副本,約為100萬訊息每秒, 配置是五個16C 140G記憶體的容器,SSD硬碟。我們發現隨著Message體積變大,效能也會隨之下降。
服務化平臺路線展望
剛才講了我們今年的一些工作,那麼我們明年想做什麼呢?
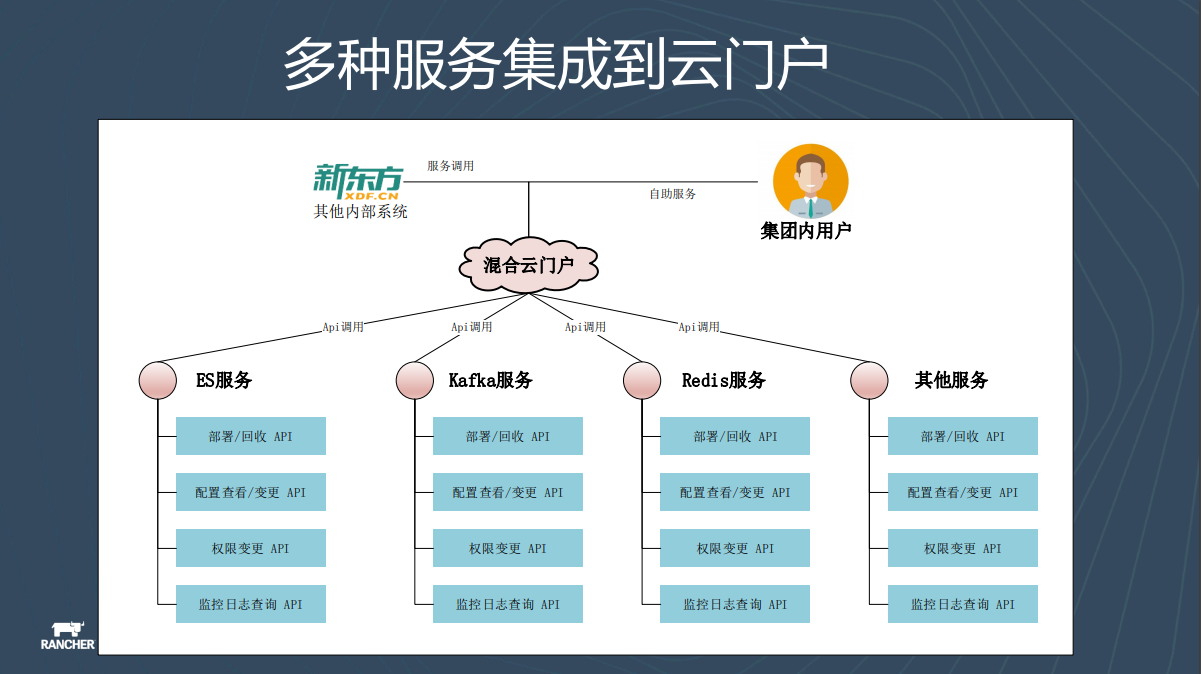
2020財年開始,新東方計劃將Redis、ES這些服務也全部服務化,並將這些暴露出來的API最終整合到雲門戶裡,給集團內的使用者或者是第三方系統呼叫。

另外一個不得不提的就是Operator,上週Elastic又釋出了一個新專案叫ECK,ECK就是ES的官方Operator。
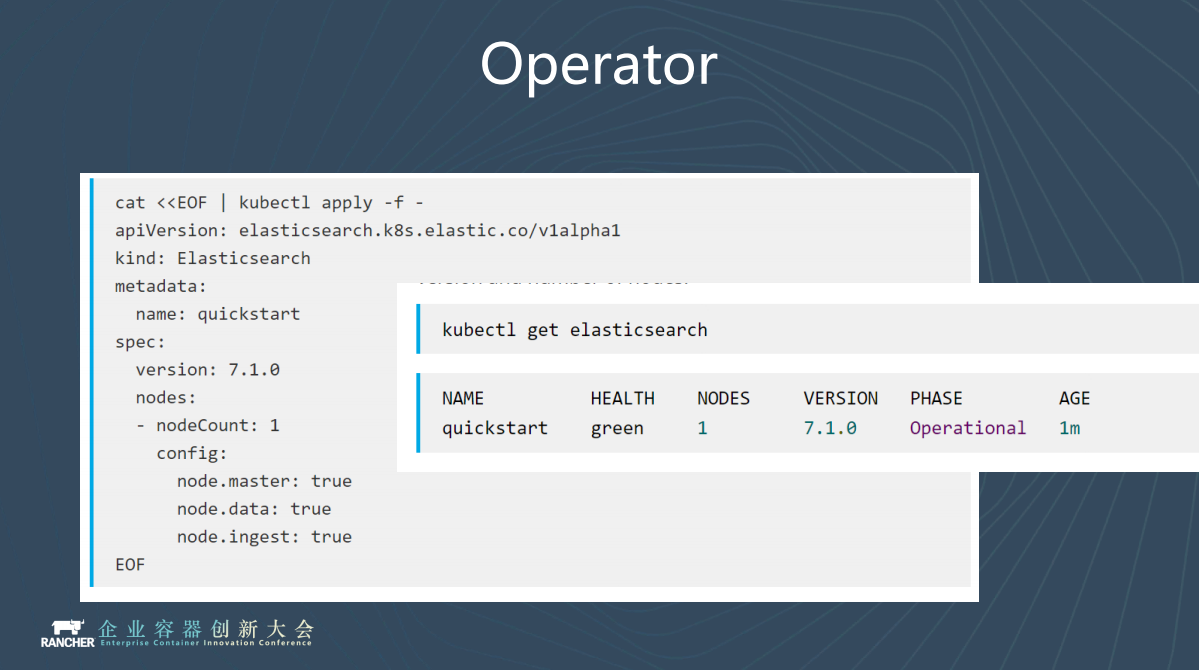
通過Operator,你只需要簡單地輸入CRD,Operator就會自動生成你需要的叢集。
我們認為基於Helm的方式,雖然能極大地簡化Yaml的工作,但它還不是終點,我們相信這個終點是Operator。

編者按: 本文是根據新東方姜江和陳博暄在Rancher於2019年6月20日在北京舉辦的第三屆企業容器創新大會(Enterprise Container Innovation Conference,簡稱ECIC)上的演講整理而成。本屆ECIC規模巨集大,全天共設定了17場主題演講,吸引了近千名容器技術愛好者參加,超過10000名觀眾線上觀看。您可在Rancher公眾號中閱讀更多大會演講實錄的