
乾貨 | 人工智慧在視訊領域的應用初探

近些年人工智慧的熱度很高,人工智慧在視訊領域的應用已經逐漸走入人們的生活,人臉識別,行為分析,車牌識別等等。
傳統視訊應用的流程:

一、人工智慧對視訊應用的滲透
目前的人工智慧還處於工具階段,能夠滲透包括預處理和後處理,超解析度,機器視覺等等,人們在這些過程中使用人工智慧工具來提升開發效率或者處理效果。

在移動直播的環境下,在編碼前,不影響畫質的前提下,自動檢測是否為弱網環境從而判斷是否選擇性丟幀,以降低編碼環節的功耗開銷。另一方面在弱網環境下頻寬可能出現瓶頸,通過測速可進行動態位元速率切換,以保障網路推流流暢。
在播放前對視訊中的人或物進行檢測並處理,整合自動美顏、渲染等,以達到更好的觀看效果。

近年來網路直播應用的興起,出現了跟以往廣播電視編解碼不太一樣的需求。那就是:
-
編碼端,保證編碼實時性和位元速率的要求的同時,保證儘量高的影象質量;
-
傳送,傳輸,緩衝,延時儘量小;
-
解碼器儘量能輸出最好的質量,最好能超解析度。
業內一直在努力把人工智慧技術跟編解碼做更深的融合,用來解決傳統方法一直很難解決的這幾個問題。
二、人工智慧增強的編碼器
當前編碼器遇到的問題:硬體編碼器效能好,但是影象質量差,位元速率高。軟體編碼器效率較低,遇到複雜視訊,比如物體繁多,較大運動,閃光,旋轉,既不能滿足實時編碼的需求,同時輸出位元速率也出現較大抖動。對於網路應用來說是很大的障礙。
1、動態編碼器
不同場景下編碼保持恆定質量的位元速率:

編碼時間和位元速率是正相關的,在位元速率暴漲的同時,編碼時間也劇烈延長。對於低延時需求強烈的直播應用,會造成嚴重的卡頓。
一般就只好使用絕對不變位元速率ABR. 不同場景下ABR的影象質量:

這樣帶來的結果就是影象質量不穩定。
我們希望是下圖這樣的曲線:
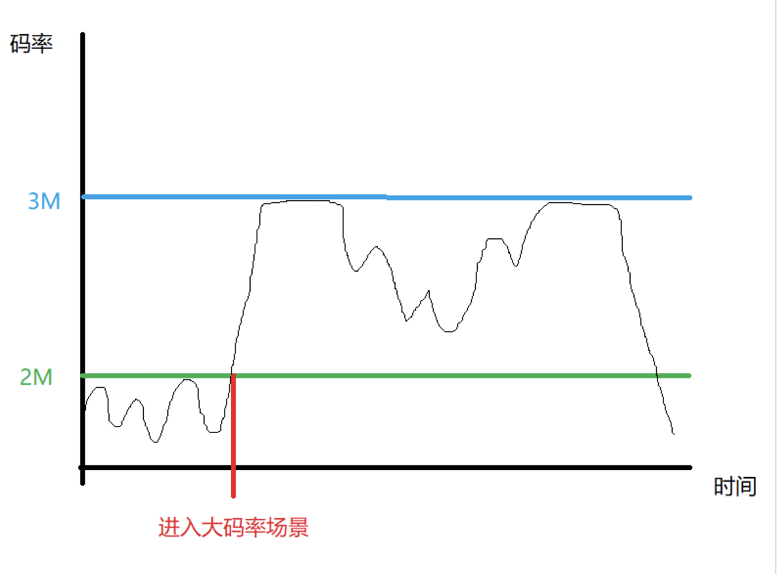
這就需要編碼器能夠提前判定大位元速率場景出現的可能性。需要判定的幾種情況:
-
物體繁多且有攝像機運動;
-
背景不動但是有大量物體的大範圍運動,包括快速運動,旋轉,仿射,蠕變等;
-
出現閃光,風沙,粒子系統。
這就需要開發一種適用於高清晰度直播應用的面向場景的智慧編碼技術。該技術通過監督學習將常見視訊編碼卡頓場景分類並快速識別,提前預判視訊場景的編碼複雜度和位元速率抖動,使用動態引數配置來編碼,保證編碼的實時性和限定位元速率下最好的影象質量。
京東雲基於業界領先的AI技術,提供對單人及多人的姿態預估技術,準確地判斷出圖片或視訊中的人體14個主要關鍵點並給出相應的置信度,可應用於各個領域中的人體動作姿態分析、預估及檢測。演算法效能LIP Dataset(單人)mAP 90%;COCO val 2017(多人)mAP 80%,處於業內領先水平。

2、內容自動植入

這裡說的廣告的自動植入問題。一種是在編碼前合成到視訊裡面,這個過程跟編碼關係不大。但是直接合成到視訊之後,所有的觀眾看到的內容就都一樣。
要做到個性化,精準的廣告投放,就只有在播放端解碼後合成。要做到這點,伺服器不僅要傳送原始視訊流,還要傳送後期合成物體的定位方法和影象資料,以便客戶端按照需求進行動態合成。
首先,自動植入的廣告跟前貼片比起來優勢很明顯,可以植入的廣告數量非常巨大,效果也更自然,使用者也不會產生明顯的反感。
其次,個性化精準投放,又進一步擴大了廣告投放的總容量和效率。
京東雲視訊直播平臺擁有領先的合成技術,除了字幕、廣告外,還可以提供水印、靜態或動態logo等功能,以增強視訊的宣傳力度和版權保護。

3、互動式視訊
目前基本做法是影象識別後,與搜尋引擎連線,產生一個內容連結。

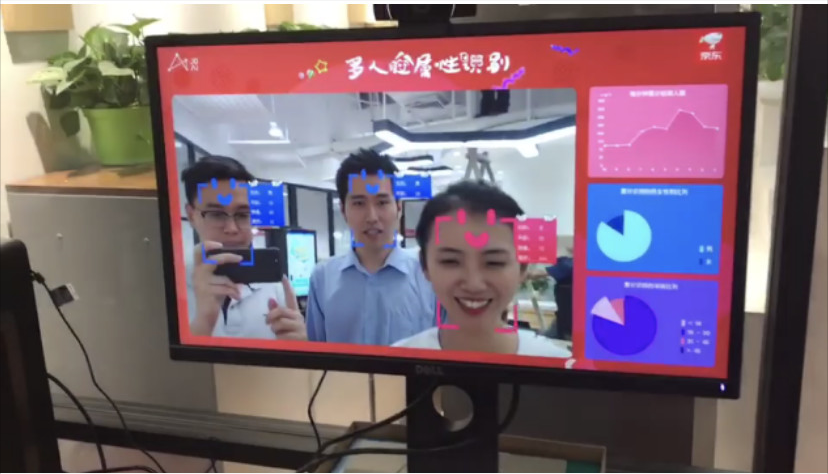
針對視訊和影象中的人物,京東雲提供的AI能力可對人臉進行搜尋和比對實現企業、商業、住宅等多種場景的刷臉進門等功能,提升安全性、效率和使用者體驗用。
同時還可快速檢測並定位人臉,返回高精度的人臉框座標,五官與輪廓關鍵點和三維座標,並且可識別多達9種人臉自然屬性和5種情緒屬性。
三、人工智慧增強的解碼器
當前解碼器需要增強的點:大家都在構想能不能應用超解析度技術,把較低解析度的視訊的播放質量提升一大塊。目前有很多演算法顯示出巨大的潛力,比如谷歌的RAISR,處理影象時候效果很好。能不能實時用到視訊上,或者硬體化,或者採用更快的能實時執行的演算法。我們在後面會討論一種折中方案,在犧牲一點質量的前提下,能夠實時執行的超解析度演算法。
1、單個影象的超解析度
自然影象基本上是平滑的紋理填充和較明顯的邊緣組合形成。
常規拉伸演算法有雙線性插值和雙三次樣條曲線差值。一般說來,三次曲線要比線性插值效果好。但實際簡單的雙線性插值的目視效果要好過三次曲線。
原因有以下幾個:
1、低解析度下線條會變得模糊。
2、低解析度影象在拉伸到高解析度時候會線上條上引入額外的模糊。
3、噪音的存在。
第1點不用過多解釋,解析度低了自然會模糊
第2點:比如B樣條,三次樣條曲線有一個應用條件,那就是樣本資料本身應該是光滑的,至少是分段光滑。但是在影象裡面,物體的邊界和背景的結合處,就不滿足這個條件了。普通的三次樣條曲線插值並沒有考慮影象內部各個物體的不同,簡單的把整個影象作為一個整體來計算。這樣必然就在邊界處引入了嚴重的模糊。
因此超解析度主要從以上幾個方面進行處理。
那麼如何降低線條的拉伸效應,也就是線條的銳度保持。
比如一個4x4的畫素塊,比較常見的是如下的形態:

普通的三次b樣條的濾波器引數矩陣為:

加入在4x4畫素塊中心插入一個點
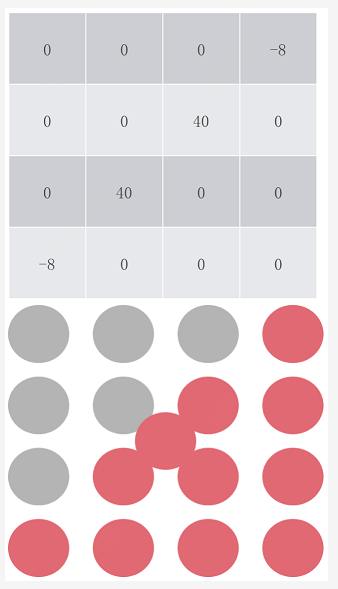
第一種情況,插入點在邊界上:

使用標準濾波器:

使用改進濾波器:
第二種情況,插入點在邊界內:

標準濾波:

第三種情況,插入點在邊界外:

使用標準濾波器:

使用改進濾波器:
第三種情況與第一種一樣。所以只需要考慮插入點在邊界上的情況。
由於每個畫素是8位的,所以一個4x4畫素塊可能的組合是大致128位整數。而現實中常出現的種類一般少於理論上限,因此需要考慮的組合往往不需要這麼多。這種情況就需要使用統計方法,也就是通過機器學習來獲得一個比較好的濾波器引數表。
機器學習過程通常是準備一些原始 HR 圖象(2x2)和從取樣生成的 LR(1x1)圖象,作為配對資料。然後採用一些優化操作:
第一步,將複雜 4x4 梯度圖象點陣處理成為簡單的碼本圖象(HASH);
第二步,針對這個碼本圖象,使用考慮臨近畫素梯度權重的方法重構B樣條濾波器引數,每次都和原始的 2x2 倍圖象進行 SAD (COST函式)計算,尋找最接近的擬合曲線引數(下山法);
第三步,對上一步獲得的大量引數計算概率分佈,取最大概率的引數作為該碼本的最優解;
第四步,對近似的碼本進行合併處理,以減小碼本的數量。
關於低分影象對邊界造成的模糊,我們可以嘗試使用一個梯度變換的方法:
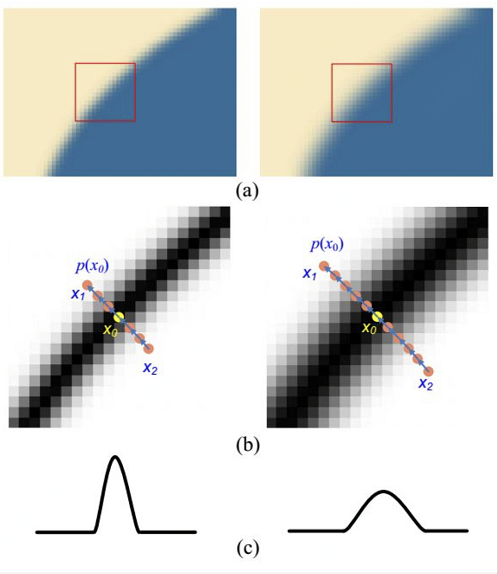
這種演算法的思路就是計算出梯度的分佈,然後適當把梯度收窄。不考慮實現速度的話,這個方法取得效果也是很驚人的。

但是這個演算法的運算量非常龐大。因此需要把這個過程融合到尋找濾波器引數矩陣的過程中。
2、視訊的超解析度
上面是單個影象的超解析度。視訊的超解析度和單個影象不同。單個影象的超解析度演算法可以融合到視訊超解析度裡面來。
視訊的超解析度是從連續的視訊序列中重新建立高解析度的影象,涉及到影象配準和子畫素提取。研究方法和評價方法也存在很大差異。有些人用影象的超解析度方法來套用的話就會出現一些疑惑:
首先視訊編碼是一個有失真壓縮過程,不同解析度的序列壓縮退化過程是不同的,因此找不到合適的HR/LR配對。視訊質量的評估也是遠比影象質量評估要複雜。因此目視質量是一個比較簡易的評估標準。當然尋找一個HR/LR配對來計算PSNR(峰值信噪比)也是可以的,但是說服力遠不如影象配對的情況。
評估模型:
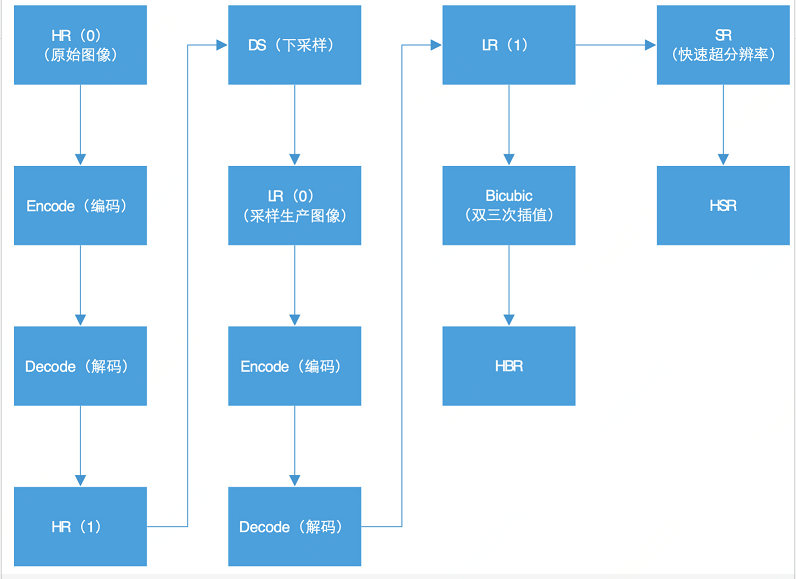
在這個過程中,因為原始視訊(未經壓縮)影象較大,所以HR(0)不適合用來做原始解析度參照。我們可以選取HR(1)和HSR來比較獲取一個PSNR(0), 然後選取HR(1)和普通拉伸獲得的HBR來比較獲取一個PSNR(1). 如果PSNR(0)比PSNR(1)要高的話,就說明超分辨取得了效果。
在視訊直播和人工智慧的結合方面,京東雲一直在不斷探索,我們希望可以基於京東雲平臺優質底層資源和領先的實施轉碼技術,為客戶提供更加專業的一站式服務。
點選"京東雲"瞭解更多詳情

