
高併發學習筆記
高併發

併發: 多個執行緒操作相同的資源,保證執行緒安全,合理使用資源
高併發: 服務能同時處理很多請求,提高程式效能
java 記憶體模型
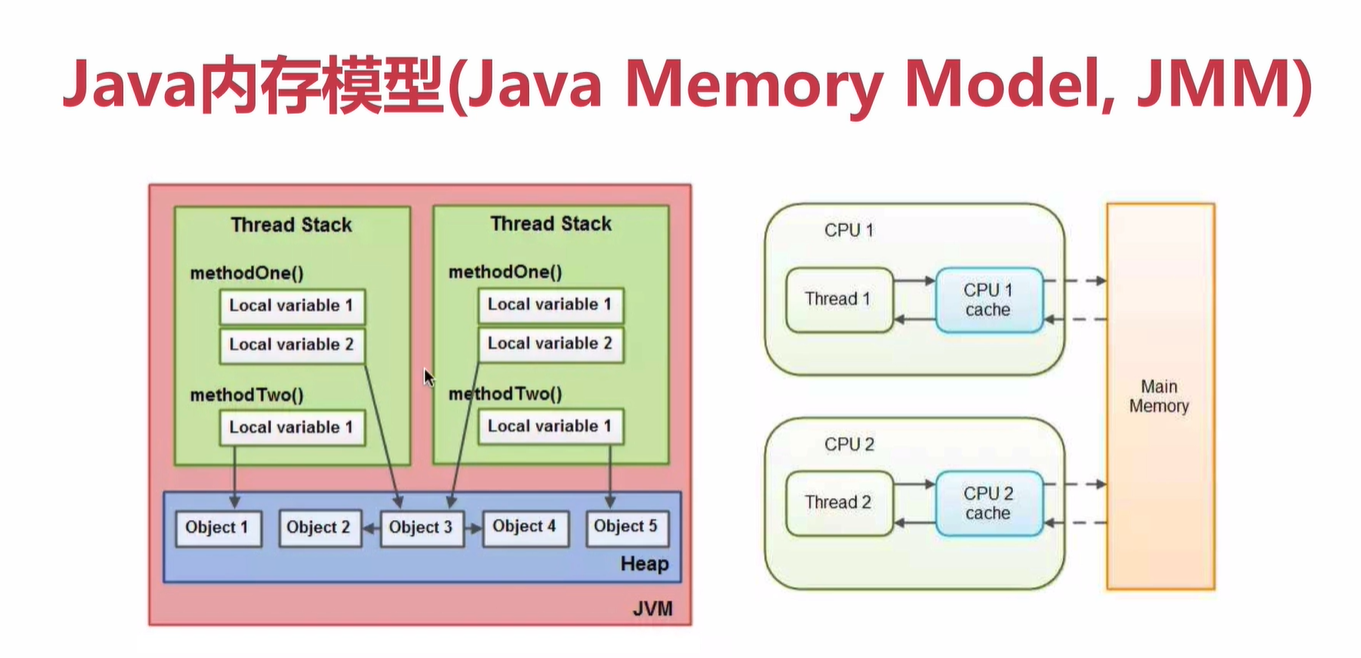
Thread Stack 儲存基本 變數:比如 int , long 等,或者物件控制代碼 或者方法
本地變數存在 棧上即 Thread Stack , 物件存在 堆上即Heap
一個本地變數也可能指向一個 物件引用。即引用儲存在棧上, 物件是 存在堆上,
一個物件的方法和本地變數是儲存在 Thread stack 上的,就算該物件存在 Heap堆上,
一個物件的成員變數 可能會隨著這個物件存在 堆上,不管這個成員變數是 原始型別還是引用型別,
靜態成員變數,跟隨類的定義一起存在堆上,
堆上物件可以被持有該物件引用的執行緒訪問, 一個執行緒可以訪問一個物件,也可以訪問該物件的成員變數
如果兩個執行緒 持有 同一個物件的引用,或者呼叫了同一個物件的方法,執行緒都會持有物件的成員變數,
但是這兩個執行緒都擁有這個物件的成員變數的 私有拷貝(所以併發時候就容易造成資料不一致)
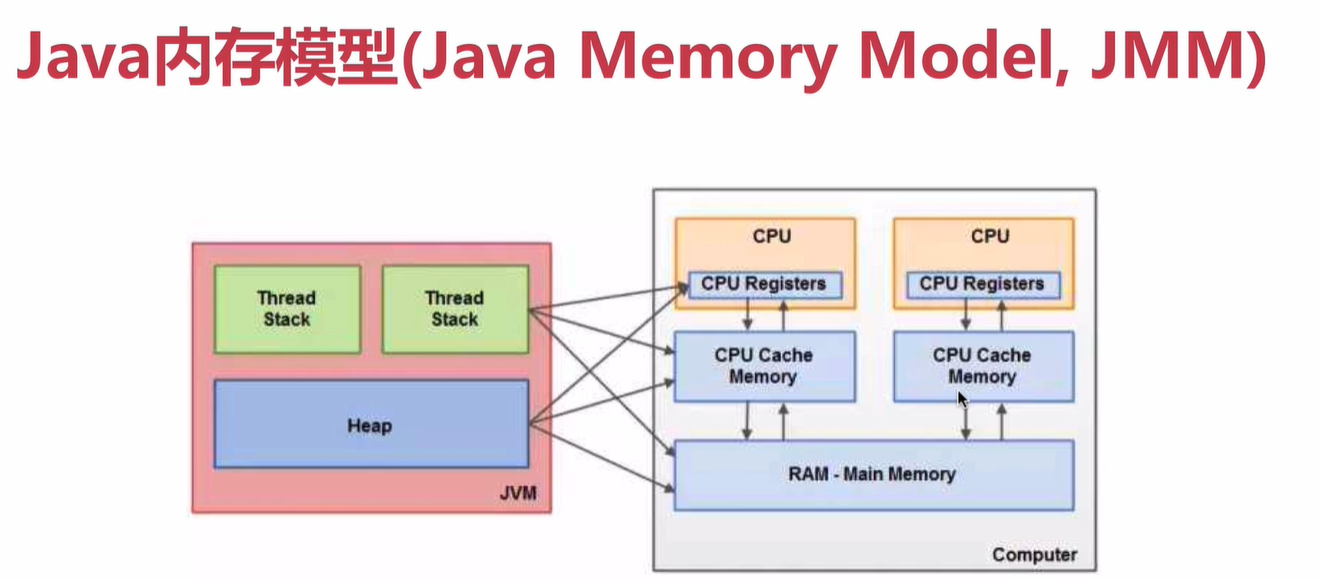
CPU與 Java Memory Model 記憶體模型

CPU Registers 即 CPU 暫存器
Main Memory 即 主存

同步八種操作


同步規則






總結

併發測試工具
postman ,
Apache Bench https://www.cnblogs.com/Ryana/p/6279232.html
Jmeter
CountDownLatch 計數器

即達到某種條件才可以 才可以執行
Semaphore 訊號量
可以阻塞執行緒,控制同一時刻的請求併發量
執行緒安全性


原子性
atomic 包下的類, 通過 CAS 來保障的
LongAdder (jdk 1.8)
在高併發下比 AtomicLong 效能高,因為沒有 使用 while 迴圈做 CAS ,
缺點:如果統計的時候有併發更新,可能會導致誤差
LongAdder類與AtomicLong類的區別在於高併發時前者將對單一變數的CAS操作分散為對陣列cells中多個元素的CAS操作,取值時進行求和;而在併發較低時僅對base變數進行CAS操作,與AtomicLong類原理相同。
AtomicBoolean
compareAndSet 可以用來控制只自執行一次,執行一次之後就執行 compareAndSet(false,true)
設定可以控制只有一個執行緒執行, 判斷 AtomicBoolean 的值進行控制

鎖


可見性


volatile

volatitle 可以用於多執行緒的狀態標記

有序性

比如 volatitle , synchronized , Lock 可以保證有序性




安全釋出物件

物件不安全例子
public class UnsafePublish {
private String[] states = {"a", "b", "c"};
//不安全的,可以通過 getStates 獲取陣列引用,修改陣列的值
public String[] getStates() {
return states;
}
public static void main(String[] args) {
UnsafePublish unsafePublish = new UnsafePublish();
log.info("{}", Arrays.toString(unsafePublish.getStates()));
unsafePublish.getStates()[0] = "d";
log.info("{}", Arrays.toString(unsafePublish.getStates()));
}
}物件 逸出例子
public class Escape {
private int thisCanBeEscape = 10;
public Escape () {
new InnerClass();
}
private class InnerClass {
// Escape 建構函式還沒有完全,就已經 獲取 到 Escape.this 了,this造成逸出,會造成 物件逸出
//物件未完全構造完成之前,不可對其進行釋出
public InnerClass() {
log.info("{}", Escape.this.thisCanBeEscape);
}
}
public static void main(String[] args) {
new Escape();
}
}

單例也是安全的釋出
列舉單例
**
* 列舉模式:最安全
*/
public class SingletonExample7 {
// 私有建構函式
private SingletonExample7() {
}
public static SingletonExample7 getInstance() {
return Singleton.INSTANCE.getInstance();
}
private enum Singleton {
INSTANCE;
private SingletonExample7 singleton;
// JVM保證這個方法絕對只調用一次
Singleton() {
singleton = new SingletonExample7();
}
public SingletonExample7 getInstance() {
return singleton;
}
}
}列舉單例,最安全,而且是懶漢模式,不會造成資源的浪費
不可變 物件

final

注意: 一個類的 private 私有方法,會被隱式的 變為 final 方法。 目前最新版的JDK 已經不需要 在方法上面 加上 final來提高效率了,已經沒有這個作用了。
如果是舊版的話,方法太大也是 final 不起效的
final 修飾變數:
基本資料型別,賦值之後就不能再次賦值了
引用型別變數: 賦值之後,就不能再 引用 其他 變數
工具類 提高的不可變 使用

執行緒封閉
即將物件封閉在一個執行緒內,其他執行緒訪問不到它,或者對其不可見


執行緒安全的同步容器

Stack 即棧 ,繼承了 Vector
Vector 也是有可能出現執行緒不安全的,例子:
public class VectorExample2 {
private static Vector<Integer> vector = new Vector<>();
public static void main(String[] args) {
while (true) {
for (int i = 0; i < 10; i++) {
vector.add(i);
}
Thread thread1 = new Thread() {
public void run() {
for (int i = 0; i < vector.size(); i++) {
vector.remove(i);
}
}
};
Thread thread2 = new Thread() {
public void run() {
for (int i = 0; i < vector.size(); i++) {
vector.get(i);
}
}
};
thread1.start();
thread2.start();
}
}
}remove 引起 get 越界
容器操作不當引起的 錯誤
public class VectorExample3 {
// java.util.ConcurrentModificationException
private static void test1(Vector<Integer> v1) { // foreach
for(Integer i : v1) {
if (i.equals(3)) {
v1.remove(i);
}
}
}
// java.util.ConcurrentModificationException
private static void test2(Vector<Integer> v1) { // iterator
Iterator<Integer> iterator = v1.iterator();
while (iterator.hasNext()) {
Integer i = iterator.next();
if (i.equals(3)) {
// iterator.remove(); //這個就沒有問題
v1.remove(i);
}
}
}
// success
private static void test3(Vector<Integer> v1) { // for
for (int i = 0; i < v1.size(); i++) {
if (v1.get(i).equals(3)) {
v1.remove(i);
}
}
}
public static void main(String[] args) {
Vector<Integer> vector = new Vector<>();
vector.add(1);
vector.add(2);
vector.add(3);
test1(vector);
}
}
一般使用併發容器來取代同步容器
併發容器 J.U,C
CopyOnWriteArrayList
1, 寫操作的時候會消耗記憶體,如果集合很多,寫入的時候會導致 Full gc 或者 Minor GC
2,不能用於實時讀取場景, 適合讀多寫少, 因為 copyOnWriteArrayList 寫會可能比較耗時,copyOnWriteArrayList 讀寫分離,能實現最終一致性
3. 不能確定 大小,就儘量不要使用,對於要求高效能的場景不適合
4, 其寫操作時候會加鎖, 讀操作無鎖,讀的是原List .併發時候 會 對 加鎖, 複製一份 資料,寫完之後執行 原來的List 陣列內容

注意 addAll 類似的 方法 不是執行緒安全的
ConcurrentSkipListMap 原理參考 https://blog.csdn.net/chenssy/article/details/75000701
ConcurrentSkipListMap 相比 ConcurrenthashMap :
1, key 有序
2. 支援更高的併發
3, 存取時間 與執行緒數關係不大: 資料量一樣下, 併發越大 ConcurrentSkipListMap 越優
安全共享物件策略


AQS

Sync queue 同步佇列
Condition queue 單向連結串列,可能有多個

繼承,即使用的模板方法, int 就是 state 狀態

countDownLatch

同步輔助類 , 它的計數器是不能重置的, 計數為0的時候,才會執行 await 的對應的執行緒
場景: 平行計算(將任務拆為小任務,然後彙總結果)
也可以進行時間控制 , 超過時間沒完成就算了
countDownLatch.await(10, TimeUnit.MILLISECONDS);
Semaphore 訊號量
場景: 常用語僅能提交有限資源的場景:比如資料庫連線數
併發訪問控制
CyclicBarrier

可重用,也叫迴圈屏障, 可以用於多執行緒去並行執行,彙總結果
即多個執行緒迴圈等待,都 準備好之後才會一起執行
ReentrantLock 與鎖

效能都差不多,功能性上, Lock 粒度更細, 推薦使用 同步鎖

ReentrantReadWriteLock 讀寫鎖,在沒有任何讀寫鎖的情況下,才可以獲取 寫鎖。 如果讀多寫少的情況下, 可能會導致寫入的執行緒 遲遲寫入不了,而陷入飢餓狀態, 因為讀的情況太多了
StampedLock 三種鎖模式: 寫、讀、樂觀讀。 由版本與模式 兩個部分組成。 1.8 才新增的,因此比ReentrantReadWriteLock 效能高
所獲取方法,返回的是一個數字,代表 stamp 票據,用響應的鎖狀態來控制和表示相關的訪問,
0 表示沒有寫鎖被授權訪問,讀鎖上 又分為 悲觀讀,與樂觀讀。
樂觀讀,認為讀多寫少,樂觀認為寫入與讀取傳送的機率很少,不悲觀使用完全的讀寫鎖定,
程式可以 在讀取之後,檢視是否遭到寫入的變更,再採取後續的措施,可以提高程式的吞吐量
參考 https://segmentfault.com/a/1190000015808032?utm_source=tag-newest
總結
1.競爭少,用 同步鎖 syc
2. 競爭不少, 執行緒增長的趨勢是可以預估的,用ReentrantReadWriteLock
Condition
public class LockExample6 {
public static void main(String[] args) {
ReentrantLock reentrantLock = new ReentrantLock();
Condition condition = reentrantLock.newCondition();
new Thread(() -> {
try {
reentrantLock.lock();//執行緒加入等待佇列 aqs
log.info("wait signal"); // 1
condition.await();// 執行緒從佇列 移除 , 鎖的釋放,然後馬上加入 condition 等待佇列裡面
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("get signal"); // 4 被喚醒,繼續執行
reentrantLock.unlock(); //釋放鎖
}).start();
new Thread(() -> {
reentrantLock.lock();
log.info("get lock"); // 2 獲取鎖 ,加入 asq 等待佇列
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
condition.signalAll(); //給condition傳送訊號, condition 等待佇列 會放入 AQS 等待佇列
log.info("send signal ~ "); // 3
reentrantLock.unlock(); // 釋放鎖, 之前的第一個執行緒就被喚醒去執行了
}).start();
}
}類似 object 的 wait 與 notify
FutureTask
可以在 執行緒執行完任務之後,獲取到結果
Callable 與 Runnalbe 介面對比, callable 返回一個 值,並且可以丟擲異常
Future 介面 ,futrue 會監聽 執行緒的 call 的 返回值
FutrueTask 類 , 父類是 RunnableFuture
RunnableFuture extends Runnable, Future
FutrueTask 最終執行的就是 callable 執行的任務。
如果建構函式引數是 runable 會轉換成 callable 型別。
所以 FutrueTask 即可以被執行緒執行執行, 也可以 得到 callable 返回值
以上組合,可以非同步去執行任務,然後需要結果的時候,就可以去獲得。
Fork/Join 框架
用於並行執行的框架, 大任務,分為小任務並行執行
join 合併結果,原理使用 工作竊取演算法
參考 https://blog.csdn.net/pange1991/article/details/80944797
任務有一定的侷限性,只能使用 Fork/Join 的同步機制,如果使用其他同步機制,工作執行緒就不能執行任務了
任務不能執行IO操作,任務不能丟擲檢查異常,
BlockingQueue 阻塞佇列,執行緒安全
以下情況會阻塞:
1, 佇列滿的時候,一個執行緒,入隊
2 , 當佇列空,一個執行緒, 出隊、

場景: 生產者,消費者
以下不能馬上執行的時候 出現的表現

比如 add(0) 不能馬上執行,丟擲異常, poll 就會返回一個特殊值, take() 阻塞, poll(timeout,timenunit) 超時之後,還不能執行,就返回一個特殊值
ArrayBlockingQueue
有界的,內部是一個 陣列實現
DelayQueue
阻塞內部元素 ,內部使用的 是 鎖和排序
LinkedBlockingQueue
初始化 沒有指定值就是無界,否則就是有界
內部是一個 連結串列
PriorityBlockingQueue
具有優先順序的阻塞佇列 ,無邊界,具有排序規則,可以插入空物件
SynchronousQueue
同步佇列,無解,非快取的佇列。放入元素之後,只有取走之後才可以再放入
總結: BlockingQueue 不僅實現了一個完整佇列所具有的基本功能,同時在多執行緒下,還可以 管理多執行緒直接的 自動等待,喚醒功能
從而開發人員可以忽略這些細節
執行緒池


ThreadPoolExecutor

如果當前執行緒數小於 corePoolSize ,執行時候會新建新的執行緒,即使 執行緒池裡面的執行緒是空閒的
如果當前執行緒數大於 corePoolSize , 且小於 maxmumPoolSize , 且 workQueue滿了的時候,才會新建執行緒 去執行
如果 corePoolSize=maxmumPoolSize ,且 workQueue 沒有滿,則把 請求放入 workQueue 裡面,等待有空閒的執行緒去執行
如果 當前執行緒數=maxmumPoolSize ,且workQueue 滿,則根據拒絕策略去處理
workQueue
儲存等待佇列的 阻塞佇列,當 一個任務提交時候,會根據執行緒池的情況響應處理
1, 直接切換使用 無界佇列(此時能夠建立的最大執行緒數就是 corePoolSize,maxmumPoolSize 無效),或者使用有界佇列
2. 當執行緒池中所有的執行緒都在執行中時候,一個新任務提交就會放在等待佇列裡面
如果想降級系統的消耗,CPU使用率,作業系統資源的消耗,上下文環境的切換開銷等等,可以設定一個較大的佇列容量或者較小的執行緒池容量,
這樣會減低 處理任務的吞吐量。 如果 執行的任務經常阻塞,可以增加 maxmumPoolSize,
如果 佇列 容量較小,就要將 corePoosize 設定大一些,這樣CPU使用率會增加
如果 maxmumPoolSize 比較大,佇列也比較大, 這樣併發量會比較高,執行緒之間的排程就是一個要考慮的問題,反而可能減低處理任務的吞吐量


stop 將 中斷正在執行的執行緒,而shudown 會讓正在執行的執行緒繼續執行,直到完成




即 IO 是 cpu的 2倍, 否則就是 CPU+1
死鎖
死鎖必要條件
1, 互斥條件
鎖對獲取的資源具有排他性,某段時間內,只有一個程序佔用
2, 請求和保持條件
程序已經保持了至少一個資源,但又提出了新的資源 請求,而該資源以被其他程序佔用,
此時程序阻塞,而又對自己佔有的資源保持不放
3. 不剝奪條件
程序已獲得資源,在未使用完之前不能被剝奪,只能自己釋放
4. 環路等待條件
存在資源的環型的鏈
如何避免死鎖?
1. 死鎖檢查,比如 執行緒獲取一個鎖加記錄下來,然後 檢查 是否存在 迴圈 等待鏈路,環路等待
2. 死鎖之後,可以回退 ,然後重新開始,也可以 給執行緒隨機的 執行級別,避免 資源的互相等待
併發最佳實踐
1, 使用本地變數或者方法內定義變數
2, 使用不可變類, 可以減低程式碼中 的同步數量
3。 最小化鎖的作用域範圍
安達爾定理: S=1/(1-a + a/n)
4, 使用執行緒池的 Executor, 而不是直接 new Thread 執行
5. 寧可使用同步,也不要使用執行緒的 wait 和 notify 方法
6. 使用 BlockingQueue實現生產-消費模式
7, 使用併發集合,而不是加了鎖的同步集合
8. 使用Semahpore 建立有界的訪問
9, 寧可使用同步程式碼塊,也不使用 同步的方法
10, 避免使用靜態變數(併發下容易出現問題,除非變為 final 變數)
spring 與執行緒安全
無狀態的物件 都是執行緒安全的

spring 執行緒安全,是因為無狀態的設計
HashMap 與 ConcurrentHashMap
https://www.cnblogs.com/wang-meng/p/9b6c35c4b2ef7e5b398db9211733292d.html
https://blog.csdn.net/visant/article/details/80045154
1.7 圖

1.8 圖

https://www.jianshu.com/p/f9b3e76951c2
高併發擴容


多機房,防止單一機房出問題 , 多機房,異地多活(最大情況的容災)

快取

快取特徵

FIFO: 先進去的資料,不夠記憶體,先清空。(舊的資料先清空)
LFU: 清空最少使用次數的資料 , 保留高頻使用資料 比較合適
LRU: 根據元素最後一次被使用的時間來進行 清空, 熱點資料 比較合適
命中率
讀多寫少適合快取,

同時 併發越高,快取的收益就越高
考慮 如何提高快取的命中率
快取分類和場景

Guava Cache

思想來源 ConcurrenHahMap
memcache

redis

redis 讀寫非常高效, 所有操作都具有原子性,或者組合操作原子
應用場景: 計數器, 排行榜, 最新N個數據, 過期時間應用,做唯一性檢查, 實時訊息系統,佇列系統,快取
高併發快取問題

快取一致性
依賴快取過期時間與更新策略

快取併發問題

使用鎖機制, 當 沒有快取時候,去查詢資料時候,就加上 locke 數,防止很多併發去查詢DB
其他請求只需要犧牲一定的等待時間即可
快取穿透
即查詢 某個 key ,但是該key 沒有, 然後去查詢資料庫,而且資料庫也沒有這個資料
那麼很多併發請求都跑去資料庫查詢了
1. 因此沒有資料, 如果快取的是集合,就給 空物件,如果是 單個數據型別,就給標識。
避免 這個問題
2. 對可能為 null 的 key進行統一的存放, 並在請求資料時候做攔截,避免過多請求跑到資料
快取雪崩
快取抖動(類似快取雪崩,一般過段時間就好了), 快取節點故障 ,一般是採用 一致性hash 解決
雪崩: 即大量快取資料不存在,都跑去查詢資料,而系統掛了
比如 很多資料 快取過期時間 一樣,都集中失效了, 可以 給 資料不同的過期時間
或者 加上 熔斷或者 限流去做 這個
可以做 二級快取, 一級快取是 java 做的快取, redis 做分散式快取,
定時將java的 快取 輸入 redis 裡面,這樣取資料直接從redis 取 計算好的資料即可。
訊息佇列MQ

可以控制發現訊息的 頻率, 解耦,非同步
特性


好處: 解耦,最終一致性,廣播, 錯峰與流控
最終一致性與分散式事務:
1, 先記錄不確定 事件訊息
2, 如果操作失敗,或者不確定 ,則可以使用定時器 重複 加入訊息佇列裡面,重複去處理直到成功
3, 如果操作成功,則將訊息 給去掉即可
4. 做好冪等
對於要求實時資料,資料一致性下, RPC 是比訊息處理高效的
kafka
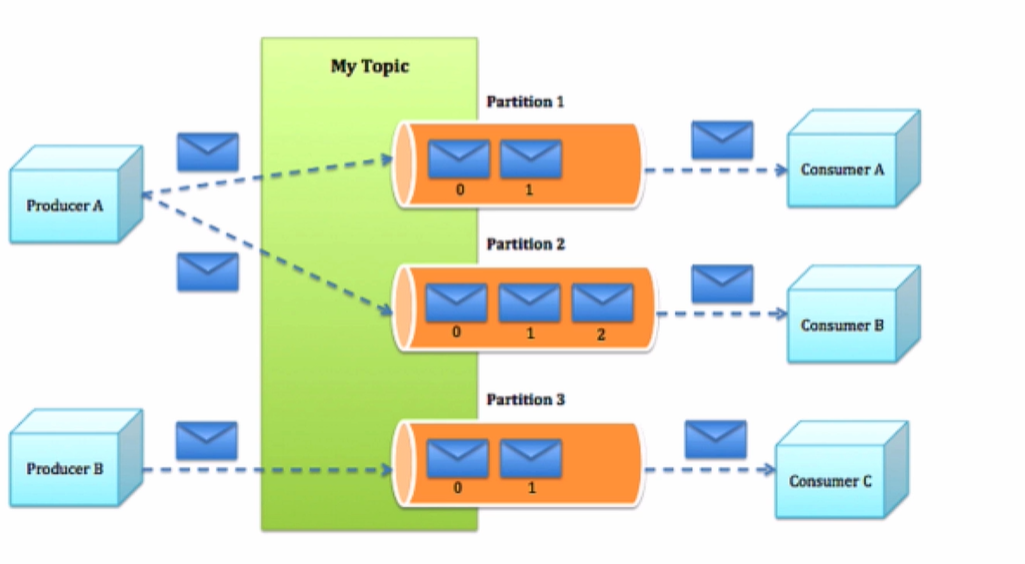
高吞吐量,高效,但是有可能丟資料
rabbitMQ

根據 exchange type 有不同的使用場景
應用拆分

拆分原則
1, 業務優先, 每個業務,模組拆解
2, 循序漸進(邊拆變測,小步前進)
3, 兼顧技術: 重構,分層
4, 可靠測試
思考
應用直接通訊: RPC(dubbo), 訊息佇列
應用直接資料庫設計:每個應用都有獨立的資料庫,如果有公用的部分,可以考慮一起 連一個 comment 公用資料庫
避免事務操作跨應用:分散式事務很消耗資源
技術

spring cloud

限流
比如控制一段時間內,某段程式碼的執行次數

限流演算法
計數器法, 滑動視窗,漏桶演算法,令牌桶演算法

有臨界突發請求問題


參考https://blog.csdn.net/weixin_34283445/article/details/87050922
https://www.jianshu.com/p/9f7df2ebbb82
計數器法 VS 滑動視窗 : 滑動視窗更穩定,但是也比較耗空間
漏桶演算法 VS 令牌桶演算法: 令牌桶允許一定的突發請求,對使用者更友好,實現更簡單,用得更多
限流實戰
Guava RateLimiter 做到是 單機版的限流
分散式限流: 只要大概的限制即可,比如 如果單臺不能大於400請求每秒,
如果換成了分散式多臺的話,比如有2臺,2臺都可以負載均衡,那麼每臺限流為200請求每秒,大概限制即可。
如果要精準限流: 使用 Redis: incrby key num
即每次 來一個請求,就 執行一次,根據當前時間秒 生成一個 key ,得到返回的值,
然後看看 返回值是否大於 允許的每秒最大值就可以進行控制了,大於這個值就阻塞或者丟棄。
如果是 每秒 幾萬,十幾萬W請求,還是使用 Guava RateLimiter ,否則 會導致 redis 壓力太大了。
服務降級與服務熔斷

以上是動態配置架構 圖,
比如 降級時候,不讀資料庫的主庫了,而是讀從庫,可以在配置裡面修改,這樣就可以動態生效了


Hystrix



資料庫切庫,分庫,分表

切庫
主庫: 寫, 實時資料的檢視, 從庫 : 非實時資料的查詢

參考 https://www.imooc.com/article/22556
分庫

即 服務沒有拆分, 但是分庫了, 所以要多資料來源
參考 https://www.imooc.com/article/22609
分表
當一個表資料很大,就是做了SQL優化和索引之後還是 影響了插入 速度時候,影響使用的時候,
就應該考慮分表了,也可以提取考慮 好,做分表處理。到了千萬級別資料時候,做什麼操作都會慢很多的。
好處: 單表併發提高,讀寫和磁碟IO 都會提高,同時讀寫影響的資料量變小,插入效能提高

垂直分表,一般按照活躍資料或者欄位進行處理,提高單表處理速度
參考http://www.imooc.com/article/25256
高可用的一些手段

https://www.imooc.com/article/20891

