
『深度應用』NLP機器翻譯深度學習實戰課程·零(基礎概念)
0.前言
深度學習用的有一年多了,最近開始NLP自然處理方面的研發。剛好趁著這個機會寫一系列NLP機器翻譯深度學習實戰課程。
本系列課程將從原理講解與資料處理深入到如何動手實踐與應用部署,將包括以下內容:(更新ing)
- NLP機器翻譯深度學習實戰課程·零(基礎概念)
- NLP機器翻譯深度學習實戰課程·壹(RNN base)
- NLP機器翻譯深度學習實戰課程·貳(RNN+Attention base)
- NLP機器翻譯深度學習實戰課程·叄(CNN base)
- NLP機器翻譯深度學習實戰課程·肆(Self-Attention base)
- NLP機器翻譯深度學習實戰課程·伍(應用部署)
本系列教程參考部落格:https://me.csdn.net/chinatelecom08
1.NLP機器翻譯發展現狀
1.1 機器翻譯現狀
1.1.1 什麼是機器翻譯?
什麼是機器翻譯?
說白了就是通過計算機將一種語言轉化成其他語言,就是機器翻譯。
這對我們同學們而言都很熟悉了,那麼機器翻譯背後的理論支援到底是什麼呢?而且幾十年前的機器翻譯和現在我們天天口中說的神經網路到底有什麼區別呢?
首先我們從機器翻譯歷史發展的角度來對它進行大致的講述一下,機器翻譯的歷史大致經歷了三個階段:
- 基於規則的機器翻譯(70年代)
- 基於統計的機器翻譯(1990年)
- 基於神經網路的機器翻譯(2014年)
基於規則的機器翻譯(70年代)
基於規則的機器翻譯的想法第一次出現是在70年代。科學家根據對翻譯者工作的觀察,試圖驅使計算機同樣進行翻譯行為。這些翻譯系統的組成部分包括:
雙語詞典(俄語->英文)
針對每種語言制定一套語言規則(例如,名詞以特定的字尾-heit、-keit、-ung等結尾)
如此而已。如果有必要,系統還可以補充各種技巧性的規則,如名字、拼寫糾正、以及音譯詞等。
感興趣的同學可以去網上仔細檢視一下相關的資料,這裡就貼上一個大致的流程圖,來表示基於規則的機器翻譯的實現流程。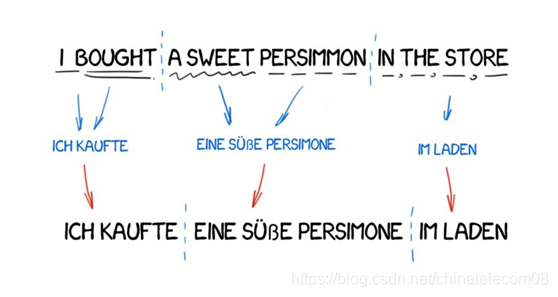

根據規則調整句子結構,然後去字典中查詢對應的詞片段的意思,重新組成新的句子,最後利用一些方法來對生成的句子進行語法調整。
基於統計的機器翻譯(1990年)
在1990年早期,IBM研究中心的一臺機器翻譯系統首次問世。它並不瞭解整體的規則和語言學,而是分析兩種語言中的相似文字,並試圖理解其中的模式。
統計模型的思路是把翻譯當成機率問題。原則上是需要利用平行語料,然後逐字進行統計。例如,機器雖然不知道“知識”的英文是什麼,但是在大多數的語料統計後,會發現只要有知識出現的句子,對應的英文例句就會出現“Knowledge”這個字。如此一來,即使不用人工維護詞典與文法規則,也能讓機器理解單詞的意思。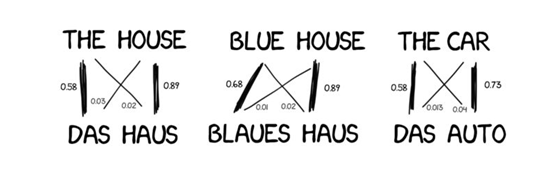
這個概念並不新,因為最早Warren Weave就提出過類似的概念,只不過那時並沒有足夠的平行語料以及限於當時計算機的能力太弱,因此沒有付諸實行。現代的統計機器翻譯要從哪裡去找來“現代的羅賽塔石碑”呢?最主要的來源其實是聯合國,因為聯合國的決議以及公告都會有各個會員國的語言版本,但除此之外,要自己製作平行語料,以現在人工翻譯的成本換算一下就會知道這成本高到驚人。
現在我們自己的系統使用的2000萬語料有一大部分是來自聯合國的平行語料。
https://cms.unov.org/UNCorpus/zh#format
在14年之前,大家所熟悉的Google翻譯都是基於統計機器翻譯。聽到這,應該大家就清楚統計翻譯模型是無法成就通天塔大業的。在各位的印像中,機器翻譯還只停留在“堪用”而非是“有用”的程度。
基於神經網路的機器翻譯(2014年)
神經網路並不是新東西,事實上神經網路發明已經距今80多年了,但是自從2006年Geoffrey Hinton(深度學習三尊大神之首)改善了神經網路優化過於緩慢的致命缺點後,深度學習就不斷地伴隨各種奇蹟似的成果頻繁出現在我們的生活中。在2015年,機器首次實現影象識別超越人類;2016年,Alpha Go戰勝世界棋王;2017年,語音識別超過人類速記員;2018年,機器英文閱讀理解首次超越人類。當然機器翻譯這個領域也因為有了深度學習這個超級肥料而開始枝繁葉茂。
Yoshua Bengio在2014年的論文中,首次奠定了深度學習技術用於機器翻譯的基本架構。他主要是使用基於序列的遞迴神經網路(RNN),讓機器可以自動捕捉句子間的單詞特徵,進而能夠自動書寫為另一種語言的翻譯結果。此文一出,Google如獲至寶。很快地,在Google供應充足火藥以及大神的加持之下,Google於2016年正式宣佈將所有統計機器翻譯下架,神經網路機器翻譯上位,成為現代機器翻譯的絕對主流。
簡單介紹一下基於神經網路的機器翻譯的通用框架:編碼器-解碼器結構。
用通俗的話來講,編碼器是將資訊壓縮的過程,解碼器就是將資訊解碼回人能夠理解的過程,這種過程資訊的損失越少越好。
結構如下圖所示:
圖1 gnmt機器翻譯框架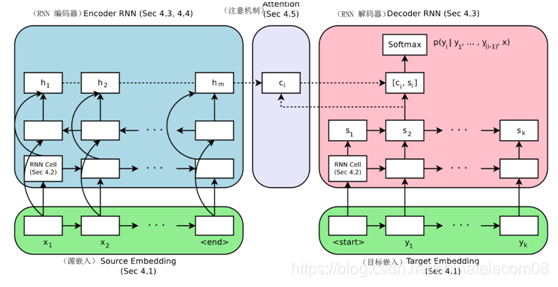
這個是16年穀歌發表的gnmt框架的結構,使用lstm+attention的機制實現,感興趣的同學可以去檢視論文或者百度相關的部落格。
圖2 transformer機器翻譯框架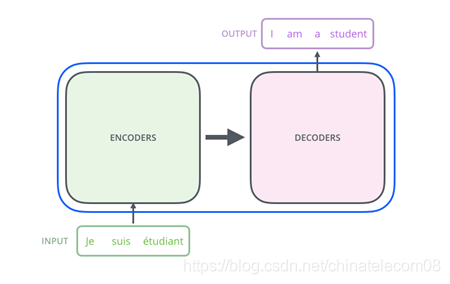
Transformer是谷歌在17年的一篇論文https://arxiv.org/pdf/1706.03762.pdf提出的具有開創性的架構,這個結構不同於之前所有的機器翻譯網路結構,僅僅依靠模型的優勢,就取得了state of the art的結果,優於以往任何方法的機器翻譯結果。
1.1.2 相關論文
如果想更深入的瞭解其中的原理,還是需要閱讀一些理論性的文章。如果僅僅想搭建這樣一個系統,按照下一篇實踐的內容,一步步的進行操作,你就可以擁有搭建基於世界上最先進模型的機器翻譯系統的能力了。
這裡整理了一些機器翻譯中做需要的理論性介紹,包括以下一些內容:
詞嵌入向量簡單介紹:https://blog.csdn.net/u012052268/article/details/77170517
機器翻譯相關論文:
Sequence to Sequence Learning with Neural Networks(2014)
Attention機制的提出(2016)
谷歌基於attention的gnmt(2016)
自注意力機制:transformer(2017)
1.1.3 相關會議
機器翻譯最著名的頂級會議也是比賽就是WMT,世界上所有著名的具有機器翻譯引擎技術的巨頭公司都在該比賽中取得過名次,該比賽從17年開始,所有取得前幾名的隊伍都是通過搭建transformer模型來進行優化迭代的。
其中一些隊伍提出的方法和技巧,也被各個具有機器翻譯技術的公司蒐集整理,嘗試在自己的翻譯引擎中去。
除此之外,國內外一些重要比賽解決方案,也是我們要需要參考的一些點。
http://www.statmt.org/wmt18/