
GC和垃圾回收器其一
什麼是GC
GC(Garbage Collection)垃圾回收,釋放垃圾佔用的空間,對堆中已經死亡或者長時間沒有使用的物件進行清除和回收,防止記憶體洩漏。可以有效使用記憶體空間。
什麼是垃圾
垃圾收集之前需要定義什麼是垃圾,之後才能決定如何回收垃圾。
拋開書面上介紹的幾種垃圾分析演算法,一步到位說下jvm採用的可達性分析法。
可達性分析
基本思路是通過根引用(GC ROOT)作為分析起點,沿著節點向下搜尋,搜尋路徑稱為引用鏈(Reference Chain),當一個物件到GC ROOT沒有任何引用鏈時,證明物件不再使用(GC ROOT到物件節點不可達)。

通過可達性分析演算法可以解決引用計數無法解決的“迴圈依賴”,只要物件和GC ROOT之間無法建立直接或者間接的連結,就可以認定為可回收物件。
GC ROOT
既然GC ROOT在物件可達性分析時如此重要,那麼哪些物件可以作為GC ROOT呢?
在之前需要先了解下JVM的內部結構:

以下四種情況可以認定為GC ROOT:
- 虛擬機器棧(棧幀的本地變量表)中引用的物件
- 方法區中類靜態屬性引用的物件
- 方法區中常量引用的物件
- 本地方法棧中JNI(Native方法)引用的物件
垃圾回收
在確定垃圾之後就可以進行垃圾回收了,回收過程中最重要的一點就是如何高效的回收,這些也都是不同版本回收器進化的主要目標。
常見的垃圾收集演算法:
- 標記清除
- 複製演算法
- 標記整理
標記清除

標記清除(Mark-Sweep)是將記憶體中認定為垃圾的物件進行標記,之後對這些標記的物件進行清理,清理之後的空間可以給新物件使用。
但是這種操作演算法存在的問題會存在大量不連續的清理空間,也就是記憶體碎片。記憶體碎片帶來的問題是,有的時候我們進行物件分配時,需要連續的記憶體(比如陣列這種)但是由於記憶體中沒有足夠的聯絡記憶體,導致碎片記憶體用不了,造成了記憶體空間的浪費。
複製演算法
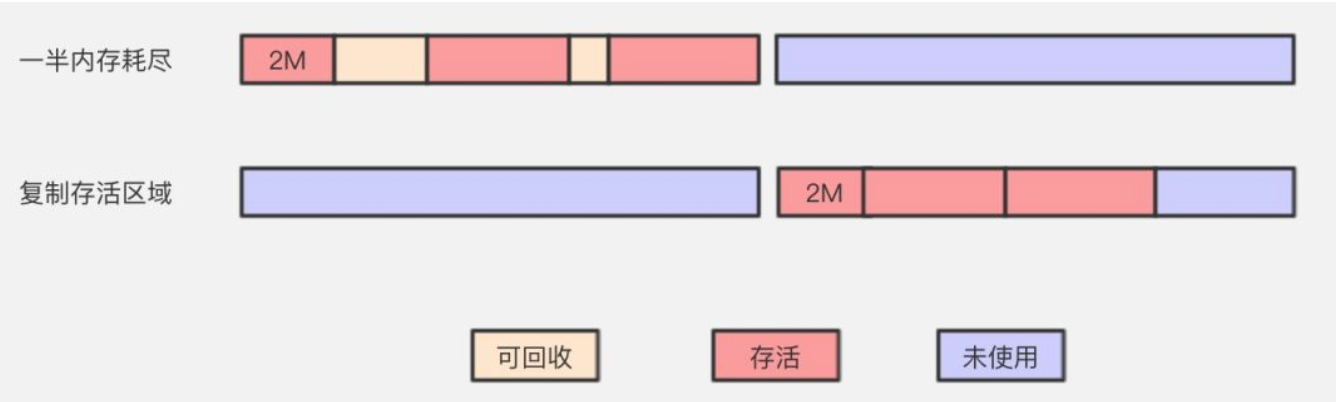
複製(Copying)是在標記清除之上演進而來的,主要目的是解決記憶體碎片問題,將可用記憶體空間按照容量進行劃分成大小相等的兩塊,每次只是用其中一塊,當這部分記憶體使用完成之後,可以把存活物件複製到另一塊上面,把之前使用的記憶體進行一次性清理,保證記憶體空間連續可用,複製演算法我們可以不考慮記憶體碎片等問題,分配過程更簡單高效。
但是複製演算法帶來的就是空間的代價更大。
標記整理
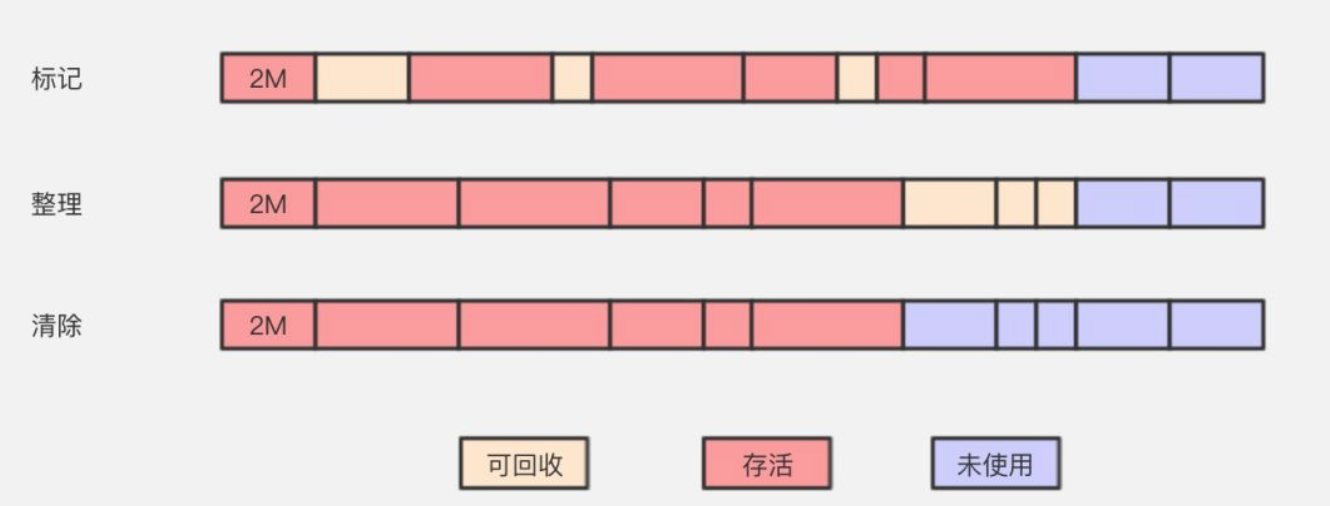
既然標記清除,複製演算法都存在一些明確的短板,是否可以針對這些短板設計一個回收演算法呢?於是就有了標記整理演算法(Mark-Compact)。
標記整理過程和標記清除演算法一樣,但是後續整理方式是將存活物件統一移動到記憶體到一側,在進行邊界外的物件清除。
這種演算法屬於標記清除演算法的升級版本,可以解決記憶體碎片問題,也避免了複製演算法存在一半空間浪費的問題,但是也不是沒有問題。首先他會造成更多的記憶體變動,比如需要判斷存活物件,整理存活物件地址,效率上對於複製演算法來說要差很多。
分代回收
我們瞭解了三種收集演算法,JVM記憶體回收就可以根據自己特點進行演算法選擇了。
比如JVM根據物件存活週期不同將記憶體劃分成不同的幾部分。比如堆中針對於快生快消特點分出了新生代,存活較久物件分出了老年代。於是針對不同代物件特點可以選擇不同的回收演算法,比如年輕代物件生命週期比較短,可選擇複製演算法減少標記整理的代價。老年代存活物件較多,空間利用率上相對要求較高,需要使用標記清理或者標識整理演算法。
JVM記憶體模型
那麼JVM中物件具體是怎麼分配的呢?從記憶體模型講起。
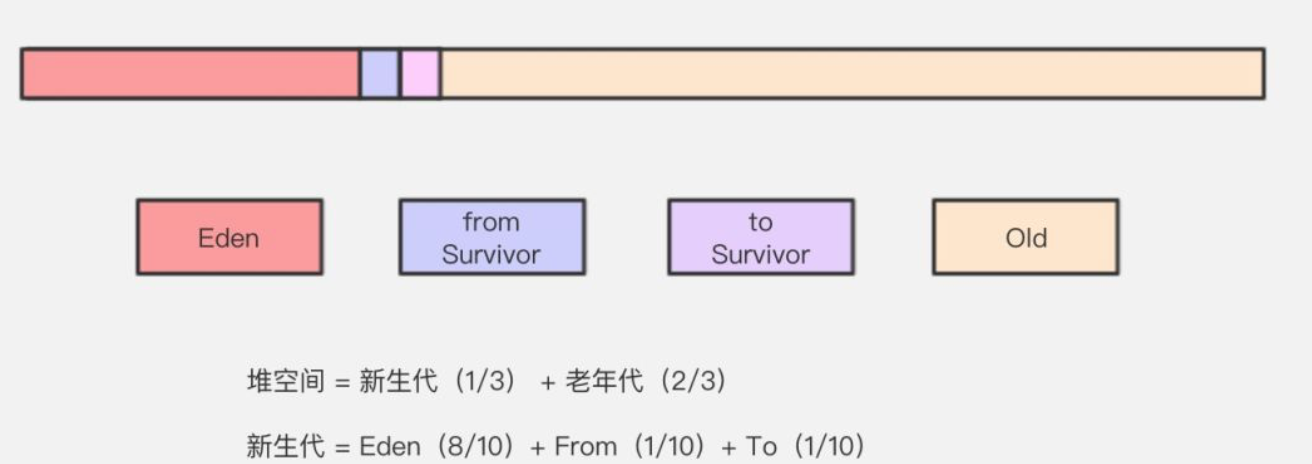
堆是記憶體中最大的一塊,也是垃圾回收的主要戰場。
堆主要分為兩個區域:年輕代和老年代,年輕代又分為Eden,s1,s2區。
Eden
新生物件優先在Eden中分配,當Eden中沒有足夠空間後,會觸發一次YGC(比較討厭用Minor GC和Major GC的說法),YGC之後Eden區被回收,無需回收的物件進入S1區,如果S1區容不下則直接進入老年代。
S區
S區主要作用是作為Eden和Old之間的緩衝帶,因為之前說過Eden大部分物件都是短生命的,所以為了避免YGC之後直接進入老年代,引入S區也是有必要的,緩衝了因為頻繁YGC使得老年代被填滿的風險。
因為一而再再而三之後大部分物件還是在新生代消亡了,所以設定一個S區是明智的。
一般物件需要經過15(預設)YGC之後才進入老年代。
而兩個S區的目的就是為了採用複製演算法,來解決碎片問題。如果一個區域的話你就只能採取標記整理或標記清除演算法了,為了降低YGC期間(因為YGC太頻繁了)對於程式的影響,用複製演算法這種簡單可依賴的方式還有有必要的。
如果分成好幾個S區會有什麼問題呢?頻繁的複製是個問題,過多的S區空間造成整體空間利用率更低也是個問題,相信這個2的閾值也是經過多次實驗得來的,所以GC的很多預設演算法其實是很優的配置,除非結合自己業務特點,否則比建議進行修改。
Old區
預設老年代佔用整個區的2/3,只有發生Full GC(這個說法也不準確,我們用CMS回收器,所以就稱為CMS GC吧)時才進行整理,Full GC會造成STW,記憶體越大STW肯定時間就越長(這個也是我們調優JVM引數一個很重要的參考點),所以記憶體並不是越大越好。上面說了老年代存在大量長期物件,所以採用標記演算法更合適。
哪些物件會進入老年代?
- 記憶體擔保,無法放置物件直接進入老年代
- 大物件直接進入老年代,可配置
- 長期存活物件進入老年代,比如age=15
- 動態物件年齡進入老年代,主要是s區空間不足了,某一個年齡及以上物件大小總和大於整個S區一半,這些年齡的物件直接