
Kafka 系列(四)—— Kafka 消費者詳解
一、消費者和消費者群組
在 Kafka 中,消費者通常是消費者群組的一部分,多個消費者群組共同讀取同一個主題時,彼此之間互不影響。Kafka 之所以要引入消費者群組這個概念是因為 Kafka 消費者經常會做一些高延遲的操作,比如把資料寫到資料庫或 HDFS ,或者進行耗時的計算,在這些情況下,單個消費者無法跟上資料生成的速度。此時可以增加更多的消費者,讓它們分擔負載,分別處理部分分割槽的訊息,這就是 Kafka 實現橫向伸縮的主要手段。
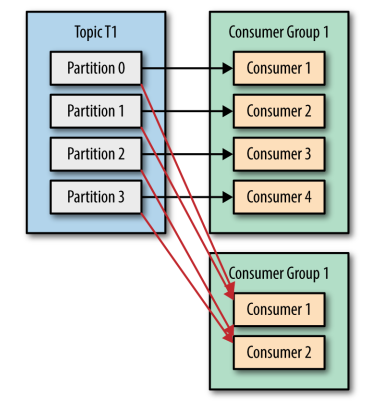
需要注意的是:同一個分割槽只能被同一個消費者群組裡面的一個消費者讀取,不可能存在同一個分割槽被同一個消費者群裡多個消費者共同讀取的情況,如圖:
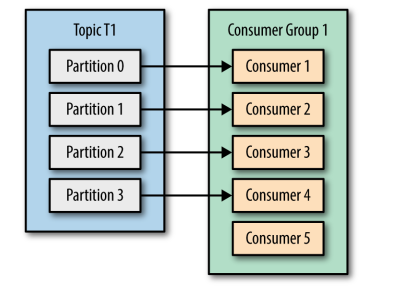
可以看到即便消費者 Consumer5 空閒了,但是也不會去讀取任何一個分割槽的資料,這同時也提醒我們在使用時應該合理設定消費者的數量,以免造成閒置和額外開銷。
二、分割槽再均衡
因為群組裡的消費者共同讀取主題的分割槽,所以當一個消費者被關閉或發生崩潰時,它就離開了群組,原本由它讀取的分割槽將由群組裡的其他消費者來讀取。同時在主題發生變化時 , 比如添加了新的分割槽,也會發生分割槽與消費者的重新分配,分割槽的所有權從一個消費者轉移到另一個消費者,這樣的行為被稱為再均衡。正是因為再均衡,所以消費費者群組才能保證高可用性和伸縮性。
消費者通過向群組協調器所在的 broker 傳送心跳來維持它們和群組的從屬關係以及它們對分割槽的所有權。只要消費者以正常的時間間隔傳送心跳,就被認為是活躍的,說明它還在讀取分割槽裡的訊息。消費者會在輪詢訊息或提交偏移量時傳送心跳。如果消費者停止傳送心跳的時間足夠長,會話就會過期,群組協調器認為它已經死亡,就會觸發再均衡。
三、建立Kafka消費者
在建立消費者的時候以下以下三個選項是必選的:
- bootstrap.servers :指定 broker 的地址清單,清單裡不需要包含所有的 broker 地址,生產者會從給定的 broker 裡查詢 broker 的資訊。不過建議至少要提供兩個 broker 的資訊作為容錯;
- key.deserializer :指定鍵的反序列化器;
- value.deserializer :指定值的反序列化器。
除此之外你還需要指明你需要想訂閱的主題,可以使用如下兩個 API :
- consumer.subscribe(Collection<String> topics) :指明需要訂閱的主題的集合;
- consumer.subscribe(Pattern pattern) :使用正則來匹配需要訂閱的集合。
最後只需要通過輪詢 API(poll) 向伺服器定時請求資料。一旦消費者訂閱了主題,輪詢就會處理所有的細節,包括群組協調、分割槽再均衡、傳送心跳和獲取資料,這使得開發者只需要關注從分割槽返回的資料,然後進行業務處理。 示例如下:
String topic = "Hello-Kafka";
String group = "group1";
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop001:9092");
/*指定分組 ID*/
props.put("group.id", group);
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
/*訂閱主題 (s)*/
consumer.subscribe(Collections.singletonList(topic));
try {
while (true) {
/*輪詢獲取資料*/
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("topic = %s,partition = %d, key = %s, value = %s, offset = %d,\n",
record.topic(), record.partition(), record.key(), record.value(), record.offset());
}
}
} finally {
consumer.close();
}本篇文章的所有示例程式碼可以從 Github 上進行下載:kafka-basis
三、 自動提交偏移量
3.1 偏移量的重要性
Kafka 的每一條訊息都有一個偏移量屬性,記錄了其在分割槽中的位置,偏移量是一個單調遞增的整數。消費者通過往一個叫作 _consumer_offset 的特殊主題傳送訊息,訊息裡包含每個分割槽的偏移量。 如果消費者一直處於執行狀態,那麼偏移量就沒有
什麼用處。不過,如果有消費者退出或者新分割槽加入,此時就會觸發再均衡。完成再均衡之後,每個消費者可能分配到新的分割槽,而不是之前處理的那個。為了能夠繼續之前的工作,消費者需要讀取每個分割槽最後一次提交的偏移量,然後從偏移量指定的地方繼續處理。 因為這個原因,所以如果不能正確提交偏移量,就可能會導致資料丟失或者重複出現消費,比如下面情況:
- 如果提交的偏移量小於客戶端處理的最後一個訊息的偏移量 ,那麼處於兩個偏移量之間的訊息就會被重複消費;
- 如果提交的偏移量大於客戶端處理的最後一個訊息的偏移量,那麼處於兩個偏移量之間的訊息將會丟失。
3.2 自動提交偏移量
Kafka 支援自動提交和手動提交偏移量兩種方式。這裡先介紹比較簡單的自動提交:
只需要將消費者的 enable.auto.commit 屬性配置為 true 即可完成自動提交的配置。 此時每隔固定的時間,消費者就會把 poll() 方法接收到的最大偏移量進行提交,提交間隔由 auto.commit.interval.ms 屬性進行配置,預設值是 5s。
使用自動提交是存在隱患的,假設我們使用預設的 5s 提交時間間隔,在最近一次提交之後的 3s 發生了再均衡,再均衡之後,消費者從最後一次提交的偏移量位置開始讀取訊息。這個時候偏移量已經落後了 3s ,所以在這 3s 內到達的訊息會被重複處理。可以通過修改提交時間間隔來更頻繁地提交偏移量,減小可能出現重複訊息的時間窗,不過這種情況是無法完全避免的。基於這個原因,Kafka 也提供了手動提交偏移量的 API,使得使用者可以更為靈活的提交偏移量。
四、手動提交偏移量
使用者可以通過將 enable.auto.commit 設為 false,然後手動提交偏移量。基於使用者需求手動提交偏移量可以分為兩大類:
- 手動提交當前偏移量:即手動提交當前輪詢的最大偏移量;
- 手動提交固定偏移量:即按照業務需求,提交某一個固定的偏移量。
而按照 Kafka API,手動提交偏移量又可以分為同步提交和非同步提交。
4.1 同步提交
通過呼叫 consumer.commitSync() 來進行同步提交,不傳遞任何引數時提交的是當前輪詢的最大偏移量。
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
}
/*同步提交*/
consumer.commitSync();
}如果某個提交失敗,同步提交還會進行重試,這可以保證資料能夠最大限度提交成功,但是同時也會降低程式的吞吐量。基於這個原因,Kafka 還提供了非同步提交的 API。
4.2 非同步提交
非同步提交可以提高程式的吞吐量,因為此時你可以儘管請求資料,而不用等待 Broker 的響應。程式碼如下:
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
}
/*非同步提交併定義回撥*/
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
System.out.println("錯誤處理");
offsets.forEach((x, y) -> System.out.printf("topic = %s,partition = %d, offset = %s \n",
x.topic(), x.partition(), y.offset()));
}
}
});
}非同步提交存在的問題是,在提交失敗的時候不會進行自動重試,實際上也不能進行自動重試。假設程式同時提交了 200 和 300 的偏移量,此時 200 的偏移量失敗的,但是緊隨其後的 300 的偏移量成功了,此時如果重試就會存在 200 覆蓋 300 偏移量的可能。同步提交就不存在這個問題,因為在同步提交的情況下,300 的提交請求必須等待伺服器返回 200 提交請求的成功反饋後才會發出。基於這個原因,某些情況下,需要同時組合同步和非同步兩種提交方式。
注:雖然程式不能在失敗時候進行自動重試,但是我們是可以手動進行重試的,你可以通過一個 Map<TopicPartition, Integer> offsets 來維護你提交的每個分割槽的偏移量,然後當失敗時候,你可以判斷失敗的偏移量是否小於你維護的同主題同分區的最後提交的偏移量,如果小於則代表你已經提交了更大的偏移量請求,此時不需要重試,否則就可以進行手動重試。
4.3 同步加非同步提交
下面這種情況,在正常的輪詢中使用非同步提交來保證吞吐量,但是因為在最後即將要關閉消費者了,所以此時需要用同步提交來保證最大限度的提交成功。
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
}
// 非同步提交
consumer.commitAsync();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
// 因為即將要關閉消費者,所以要用同步提交保證提交成功
consumer.commitSync();
} finally {
consumer.close();
}
}4.4 提交特定偏移量
在上面同步和非同步提交的 API 中,實際上我們都沒有對 commit 方法傳遞引數,此時預設提交的是當前輪詢的最大偏移量,如果你需要提交特定的偏移量,可以呼叫它們的過載方法。
/*同步提交特定偏移量*/
commitSync(Map<TopicPartition, OffsetAndMetadata> offsets)
/*非同步提交特定偏移量*/
commitAsync(Map<TopicPartition, OffsetAndMetadata> offsets, OffsetCommitCallback callback)需要注意的是,因為你可以訂閱多個主題,所以 offsets 中必須要包含所有主題的每個分割槽的偏移量,示例程式碼如下:
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
/*記錄每個主題的每個分割槽的偏移量*/
TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(record.offset()+1, "no metaData");
/*TopicPartition 重寫過 hashCode 和 equals 方法,所以能夠保證同一主題和分割槽的例項不會被重複新增*/
offsets.put(topicPartition, offsetAndMetadata);
}
/*提交特定偏移量*/
consumer.commitAsync(offsets, null);
}
} finally {
consumer.close();
}五、監聽分割槽再均衡
因為分割槽再均衡會導致分割槽與消費者的重新劃分,有時候你可能希望在再均衡前執行一些操作:比如提交已經處理但是尚未提交的偏移量,關閉資料庫連線等。此時可以在訂閱主題時候,呼叫 subscribe 的過載方法傳入自定義的分割槽再均衡監聽器。
/*訂閱指定集合內的所有主題*/
subscribe(Collection<String> topics, ConsumerRebalanceListener listener)
/*使用正則匹配需要訂閱的主題*/
subscribe(Pattern pattern, ConsumerRebalanceListener listener) 程式碼示例如下:
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
consumer.subscribe(Collections.singletonList(topic), new ConsumerRebalanceListener() {
/*該方法會在消費者停止讀取訊息之後,再均衡開始之前就呼叫*/
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("再均衡即將觸發");
// 提交已經處理的偏移量
consumer.commitSync(offsets);
}
/*該方法會在重新分配分割槽之後,消費者開始讀取訊息之前被呼叫*/
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
}
});
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(record.offset() + 1, "no metaData");
/*TopicPartition 重寫過 hashCode 和 equals 方法,所以能夠保證同一主題和分割槽的例項不會被重複新增*/
offsets.put(topicPartition, offsetAndMetadata);
}
consumer.commitAsync(offsets, null);
}
} finally {
consumer.close();
}六 、退出輪詢
Kafka 提供了 consumer.wakeup() 方法用於退出輪詢,它通過丟擲 WakeupException 異常來跳出迴圈。需要注意的是,在退出執行緒時最好顯示的呼叫 consumer.close() , 此時消費者會提交任何還沒有提交的東西,並向群組協調器傳送訊息,告知自己要離開群組,接下來就會觸發再均衡 ,而不需要等待會話超時。
下面的示例程式碼為監聽控制檯輸出,當輸入 exit 時結束輪詢,關閉消費者並退出程式:
/*呼叫 wakeup 優雅的退出*/
final Thread mainThread = Thread.currentThread();
new Thread(() -> {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
if ("exit".equals(sc.next())) {
consumer.wakeup();
try {
/*等待主執行緒完成提交偏移量、關閉消費者等操作*/
mainThread.join();
break;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<String, String> rd : records) {
System.out.printf("topic = %s,partition = %d, key = %s, value = %s, offset = %d,\n",
rd.topic(), rd.partition(), rd.key(), rd.value(), rd.offset());
}
}
} catch (WakeupException e) {
//對於 wakeup() 呼叫引起的 WakeupException 異常可以不必處理
} finally {
consumer.close();
System.out.println("consumer 關閉");
}七、獨立的消費者
因為 Kafka 的設計目標是高吞吐和低延遲,所以在 Kafka 中,消費者通常都是從屬於某個群組的,這是因為單個消費者的處理能力是有限的。但是某些時候你的需求可能很簡單,比如可能只需要一個消費者從一個主題的所有分割槽或者某個特定的分割槽讀取資料,這個時候就不需要消費者群組和再均衡了, 只需要把主題或者分割槽分配給消費者,然後開始讀取訊息井提交偏移量即可。
在這種情況下,就不需要訂閱主題, 取而代之的是消費者為自己分配分割槽。 一個消費者可以訂閱主題(井加入消費者群組),或者為自己分配分割槽,但不能同時做這兩件事情。 分配分割槽的示例程式碼如下:
List<TopicPartition> partitions = new ArrayList<>();
List<PartitionInfo> partitionInfos = consumer.partitionsFor(topic);
/*可以指定讀取哪些分割槽 如這裡假設只讀取主題的 0 分割槽*/
for (PartitionInfo partition : partitionInfos) {
if (partition.partition()==0){
partitions.add(new TopicPartition(partition.topic(), partition.partition()));
}
}
// 為消費者指定分割槽
consumer.assign(partitions);
while (true) {
ConsumerRecords<Integer, String> records = consumer.poll(Duration.of(100, ChronoUnit.MILLIS));
for (ConsumerRecord<Integer, String> record : records) {
System.out.printf("partition = %s, key = %d, value = %s\n",
record.partition(), record.key(), record.value());
}
consumer.commitSync();
}附錄 : Kafka消費者可選屬性
1. fetch.min.byte
消費者從伺服器獲取記錄的最小位元組數。如果可用的資料量小於設定值,broker 會等待有足夠的可用資料時才會把它返回給消費者。
2. fetch.max.wait.ms
broker 返回給消費者資料的等待時間,預設是 500ms。
3. max.partition.fetch.bytes
該屬性指定了伺服器從每個分割槽返回給消費者的最大位元組數,預設為 1MB。
4. session.timeout.ms
消費者在被認為死亡之前可以與伺服器斷開連線的時間,預設是 3s。
5. auto.offset.reset
該屬性指定了消費者在讀取一個沒有偏移量的分割槽或者偏移量無效的情況下該作何處理:
- latest (預設值) :在偏移量無效的情況下,消費者將從最新的記錄開始讀取資料(在消費者啟動之後生成的最新記錄);
- earliest :在偏移量無效的情況下,消費者將從起始位置讀取分割槽的記錄。
6. enable.auto.commit
是否自動提交偏移量,預設值是 true。為了避免出現重複消費和資料丟失,可以把它設定為 false。
7. client.id
客戶端 id,伺服器用來識別訊息的來源。
8. max.poll.records
單次呼叫 poll() 方法能夠返回的記錄數量。
9. receive.buffer.bytes & send.buffer.byte
這兩個引數分別指定 TCP socket 接收和傳送資料包緩衝區的大小,-1 代表使用作業系統的預設值。
參考資料
- Neha Narkhede, Gwen Shapira ,Todd Palino(著) , 薛命燈 (譯) . Kafka 權威指南 . 人民郵電出版社 . 2017-12-26
更多大資料系列文章可以參見 GitHub 開源專案: 大資料入門指南