
node爬蟲的幾種簡易實現方式
說到爬蟲大家可能會覺得很NB的東西,可以爬小電影,羞羞圖,沒錯就是這樣的。在node爬蟲方面,我也是個新人,這篇文章主要是給大家分享幾種實現node
爬蟲的方式。第一種方式,採用node,js中的 superagent+request + cheerio。cheerio是必須的,它相當於node版的jQuery,用過jQuery的同學會非常容易上手。它
主要是用來獲取抓取到的頁面元素和其中的資料資訊。superagent是node裡一個非常方便的、輕量的、漸進式的第三方客戶端請求代理模組,用他來請求目標頁面。
node中,http模組也可作為客戶端使用(傳送請求),第三方模組request對其使用方法進行了封裝,操作更方便。以下是三者的引入方法:

接下來我們開始請求要爬取的目標頁面。申明目標頁面比如新浪網首頁:

如新浪首頁部分程式碼
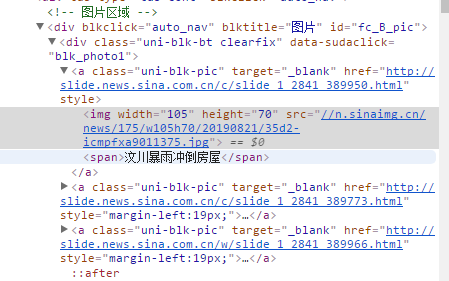
通過superagent請求目標網站,獲取到網站內容,通過cheerio.load方法引入要解析的html
cheerio中的有關DOM操作的方式
此處採用 .each(function(index,element){...})方式遍歷需要的元素
返回結果如下:

若要將文字內容儲存可採用以下方式:
引入fs模組 const fs= require("fs")
引入path模組 const path=require("path")
Node.js 內建的fs模組就是檔案系統模組,負責讀寫檔案。和所有其他JS模組不同的是,fs模組同時提供了非同步和同步的方法。
在上述方法中呼叫儲存文字內容mkdirs方法
//存放資料
mkdirs('./content2',saveContent); (注: content2是新建檔名;saveContent是回撥函式)
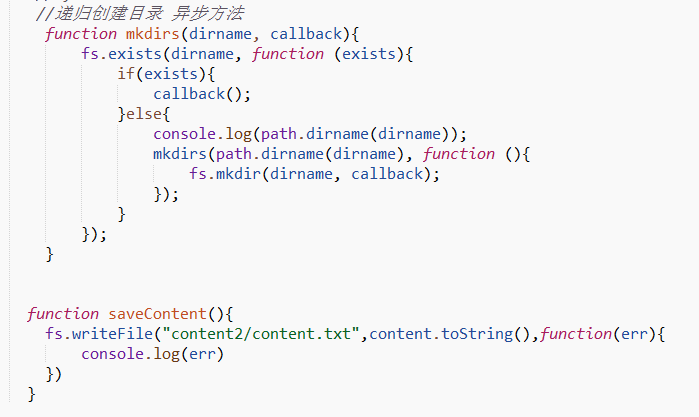
文字內容最終將儲存在content2中的content.txt檔案中
若想儲存圖片可採用以下方式:

第二種方式: 使用Nightmare自動化測試工具。
這裡介紹一下nightmare工具的用途:
Electron可以讓你使用純JavaScript
Chrome豐富的原生的介面來創造桌面應用。你可以把它看作一個專注於桌面應用的Node.js的變體,而不是Web伺服器。
其基於瀏覽器的應用方式可以極方便的做各種響應式的互動
Nightmare是一個基於Electron的框架,針對Web自動化測試和爬蟲,因為其具有跟PlantomJS一樣的自動化測試的功能可以在頁面上模擬使用者的行為觸發一些非同步資料載入,
也可以跟Request庫一樣直接訪問URL來抓取資料,並且可以設定頁面的延遲時間,所以無論是手動觸發指令碼還是行為觸發指令碼都是輕而易舉的。
const Nightmare=require("nightmare") //自動化測試包 ,處理動態頁面
const nightmare=Nightmare({show: true}) show:true時,執行node可以顯示內建模擬瀏覽器

執行結束後,會在image2中儲存下載的圖片。
好了,文章就到這裡了,有什麼問題歡迎小夥伴指正。
&n