
mysql小白→高手
mysql資料庫
官方網站:https://dev.mysql.com;
MySQL 是最流行的關係型資料庫管理系統,在 WEB 應用方面 MySQL 是最好的 RDBMS(Relational Database Management System:關係資料庫管理系統)應用軟體之一。
什麼是事務
事務:資料庫操作的最小工作單元,是作為單個邏輯工作單元執行的一系列操作; 事務是一組不可再分割的操作集合(工作邏輯單元);
典型事務場景(轉賬):
update user_account set balance = balance - 1000 where userID = 3;
update user_account set balance = balance +1000 where userID = 1;
mysql中如何開啟事務:
begin / start transaction -- 手工
commit / rollback -- 事務提交或回滾
set session autocommit = on/off; -- 設定事務是否自動開啟
JDBC 程式設計事務開啟: connection.setAutoCommit(boolean);
特性:
原子性(Atomicity) 最小的工作單元,整個工作單元要麼一起提交成功,要麼全部失敗回滾;
一致性(Consistency) 事務中操作的資料及狀態改變是一致的,即寫入資料的結果必須完全符合預設的規則,不會因為出現系統意外等原因導致狀態的不一致;
隔離性(Isolation) 一個事務所操作的資料在提交之前,對其他事務的可見性設定(一般設定為不可見);
永續性(Durability) 事務所做的修改就會永久儲存,不會因為系統意外導致資料的丟失;
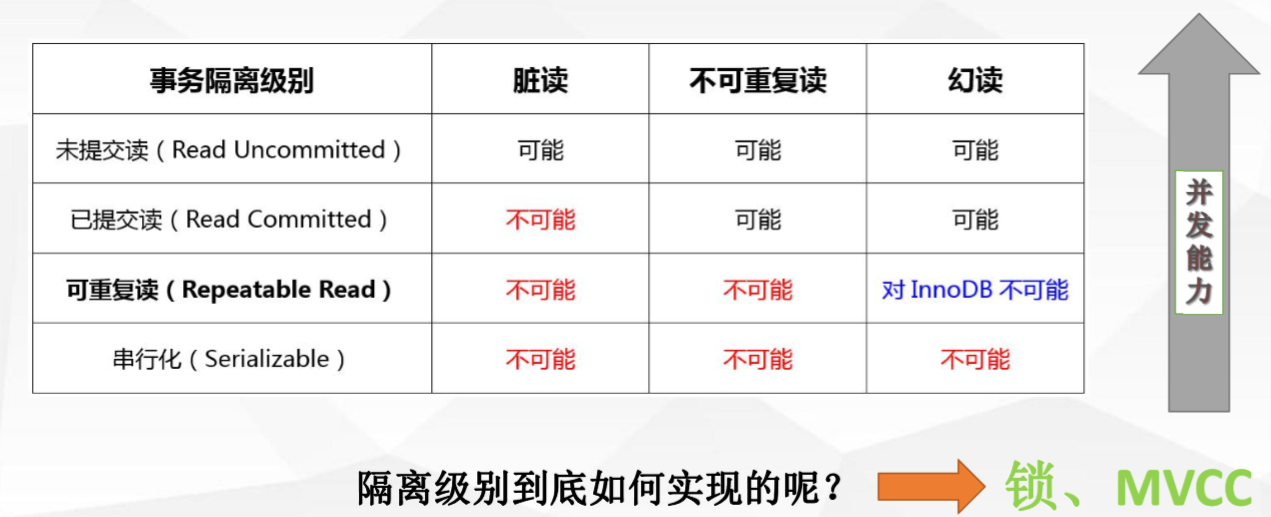
四種隔離級別:
Read Uncommitted(未提交讀):--未解決併發問題 事務未提交對其他事務也是可見的,髒讀(dirty read);
Read Committed(提交讀):--解決髒讀問題 一個事務開始之後,只能看到自己提交的事務所做的修改,不可重複讀(nonrepeatable read);
Repeatable Read (可重複讀) :--解決不可重複讀問題 在同一個事務中多次讀取同樣的資料結果是一樣的,這種隔離級別未定義解決幻讀的問題;
Serializable(序列化):--解決所有問題 最高的隔離級別,通過強制事務的序列執行;
inodb引擎對隔離級別的支援程度:
mysql中的鎖
InnoDB中的鎖
InnoDB的行鎖是通過給索引上的索引項加鎖來實現的。
只有通過索引條件進行資料檢索,InnoDB才使用行級鎖,否則,InnoDB 將使用表鎖(鎖住索引的所有記錄)
表鎖:lock tables xx read/write;
共享鎖(行鎖)shared locks
又稱為讀鎖,簡稱S鎖,顧名思義,共享鎖就是多個事務對於同一資料可以共享一把鎖, 都能訪問到資料,但是隻能讀不能修改;
加鎖釋鎖方式: select * from users WHERE id=1 LOCK IN SHARE MODE; commit/rollback
排它鎖(行鎖)exclusive locks
又稱為寫鎖,簡稱X鎖,排他鎖不能與其他鎖並存,如一個事務獲取了一個數據行的排他 鎖,其他事務就不能再獲取該行的鎖(共享鎖、排他鎖),只有該獲取了排他鎖的事務是可以對 資料行進行讀取和修改,(其他事務要讀取資料可來自於快照)。
加鎖釋鎖方式: delete / update / insert 預設加上X鎖 SELECT * FROM table_name WHERE ... FOR UPDATE commit/rollback
意向鎖共享鎖(表鎖)intention shared locks
表示事務準備給資料行加入共享鎖,即一個數據行加共享鎖前必須先取得該表的IS(意向鎖共享鎖)鎖, 意向共享鎖之間是可以相互相容的。
意向鎖排它鎖(表鎖)intention exclusive locks
表示事務準備給資料行加入排他鎖,即一個數據行加排他鎖前必須先取得該表的IX(意向鎖排它鎖)鎖, 意向排它鎖之間是可以相互相容的。
意向鎖(IS、IX)是InnoDB資料操作之前自動加的,不需要使用者干預
意義:當事務想去進行鎖表時,可以先判斷意向鎖是否存在,存在時則可快速返回該表不能 啟用表鎖。
自增鎖 AUTO-INC Locks
針對自增列自增長的一個特殊的表級別鎖;
show variables like 'innodb_autoinc_lock_mode';
預設取值1,代表連續,事務未提交ID永久丟失;
行鎖的演算法
記錄鎖Record locks
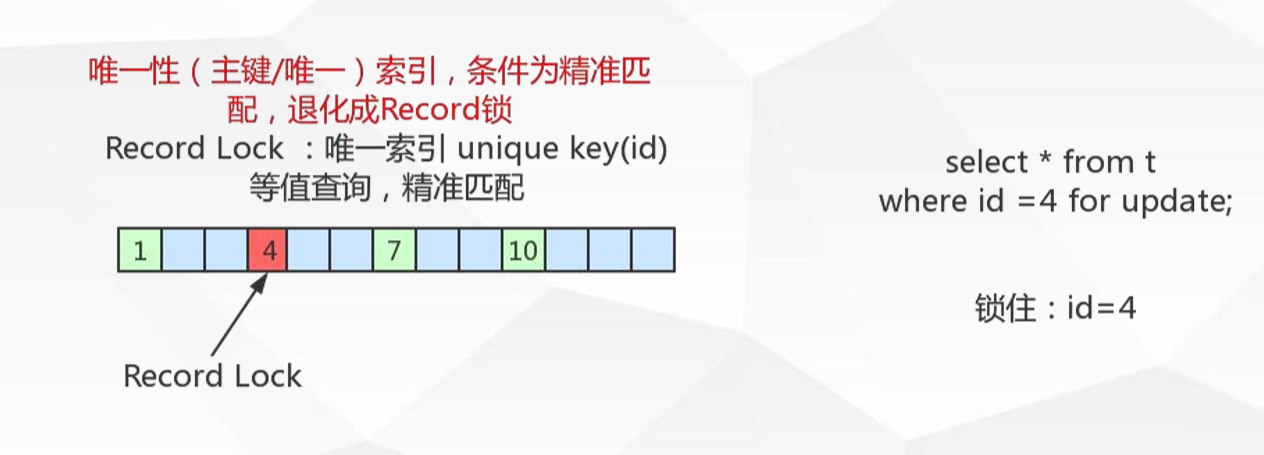
鎖住具體的索引項:當sql執行按照唯一性(Primary key、Unique key)索引進行資料的檢索時,查詢條件等值匹 配且查詢的資料是存在,這時SQL語句加上的鎖即為記錄鎖Record locks,鎖住具體的索引項。
臨鍵鎖Next-key locks
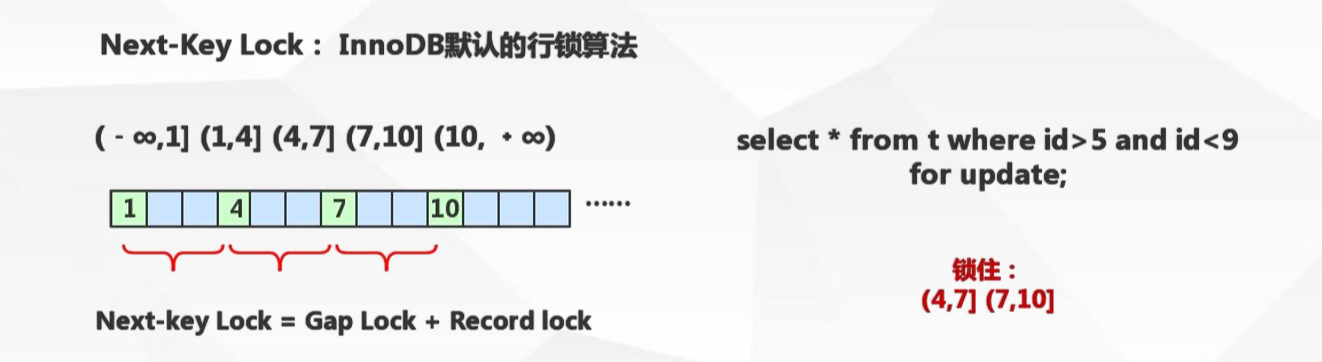
鎖住記錄+區間(左開右閉):當sql執行按照索引進行資料的檢索時,查詢條件為範圍查詢(between and、<、>等)並有資料命中則此時SQL語句加上的鎖為Next-key locks,鎖住索引的記錄+區間(左開右閉)。
如圖,一個表的id為主鍵索引,id分別是1、4、7、10這四條記錄,當進行 select * from t where id>5 and id<9 for update 查詢時,會將這些記錄分成五個區間,然後鎖住(4,7]和(7,10]區間,此時如果對7進行修改操作或者插入id=5,6,8,9的資料時都會面臨鎖等待。
間隙鎖Gap Locks
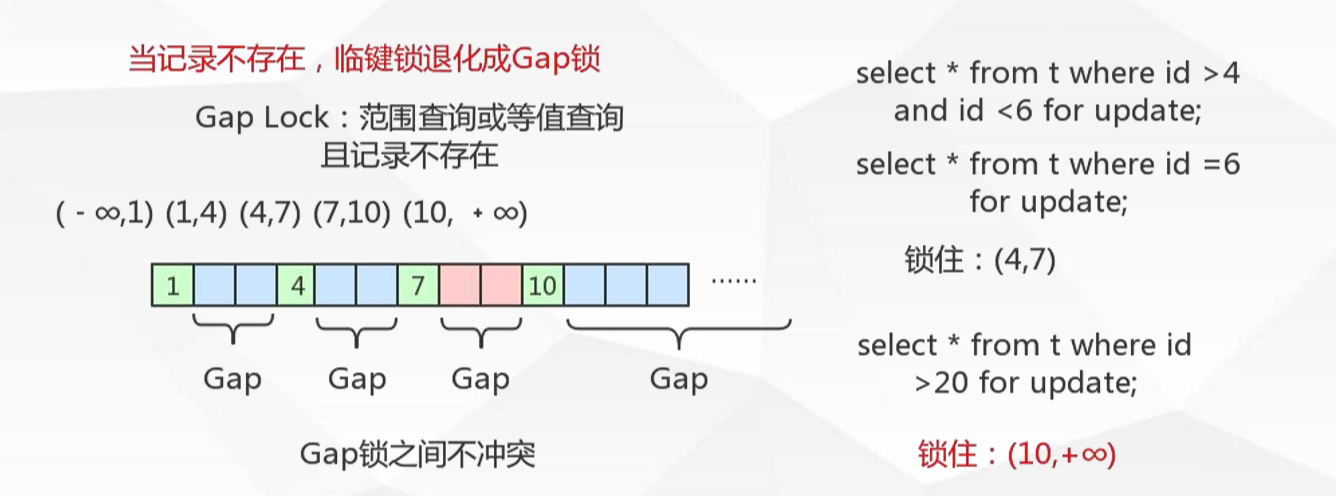
鎖住資料不存在的區間(左開右開):當sql執行按照索引進行資料的檢索時,查詢條件的資料不存在,這時SQL語句加上的鎖即為 Gap locks,鎖住索引不存在的區間(左開右開)。
Gap只在RR事務隔離級別存在。
MVCC(Multiversion concurrencu control)—多版本併發控制
InnoDB引擎中才有MVCC——併發訪問(讀或寫)資料庫時,對正在事務內處理的資料做多版本的管理。以達到用來避免寫操作的堵塞,從而引發讀操作的併發問題。
當我們建立一個表格時,InnoDB會自動在表格上加上兩個列,一個DB_TRX_ID,一個DB_ROLL_PT。如下:

當資料插入時:DB_TRX_ID會記錄事務id
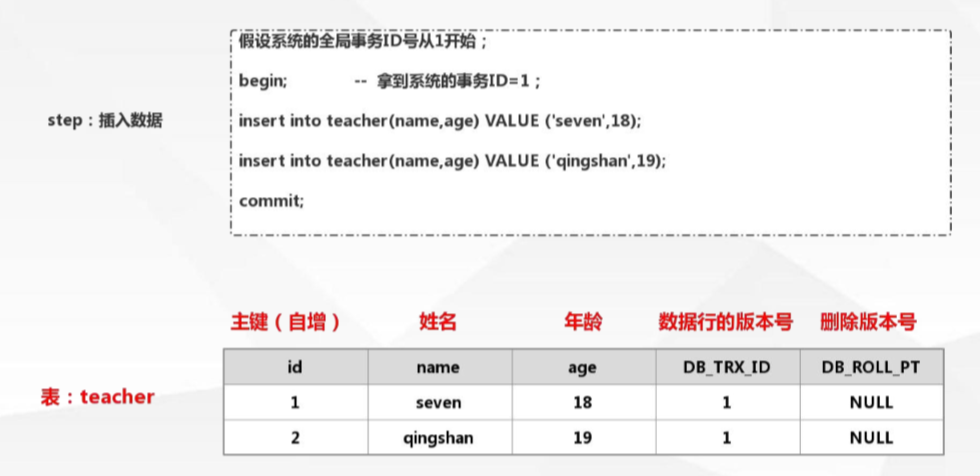
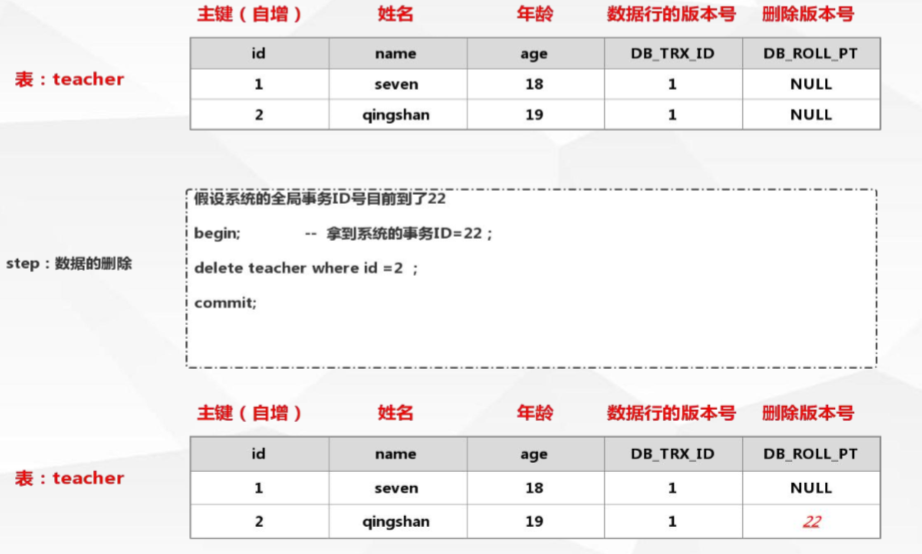
當刪除資料時:DB_ROLL_PT列會記錄此時的事務id
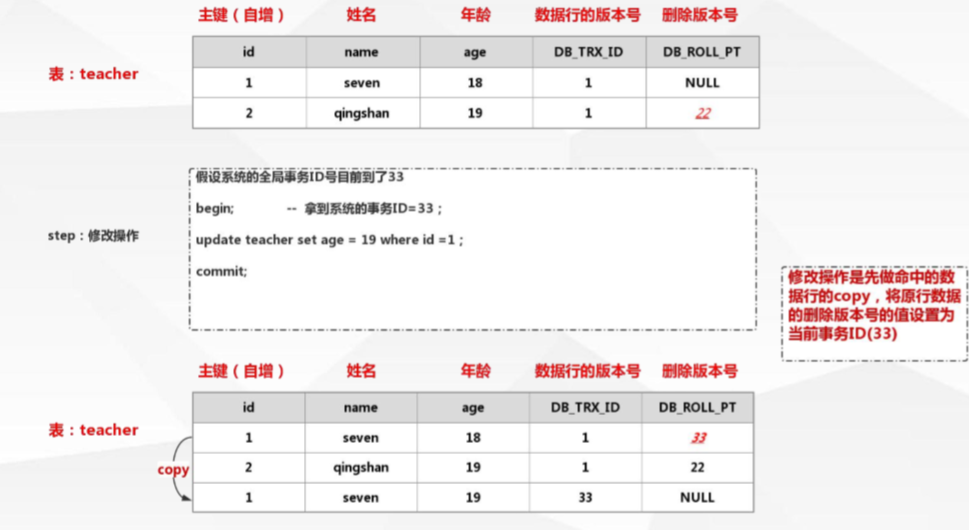
當修改資料時:copy一條資料並且把原來資料的DB_ROLL_PT列加上此時版本號
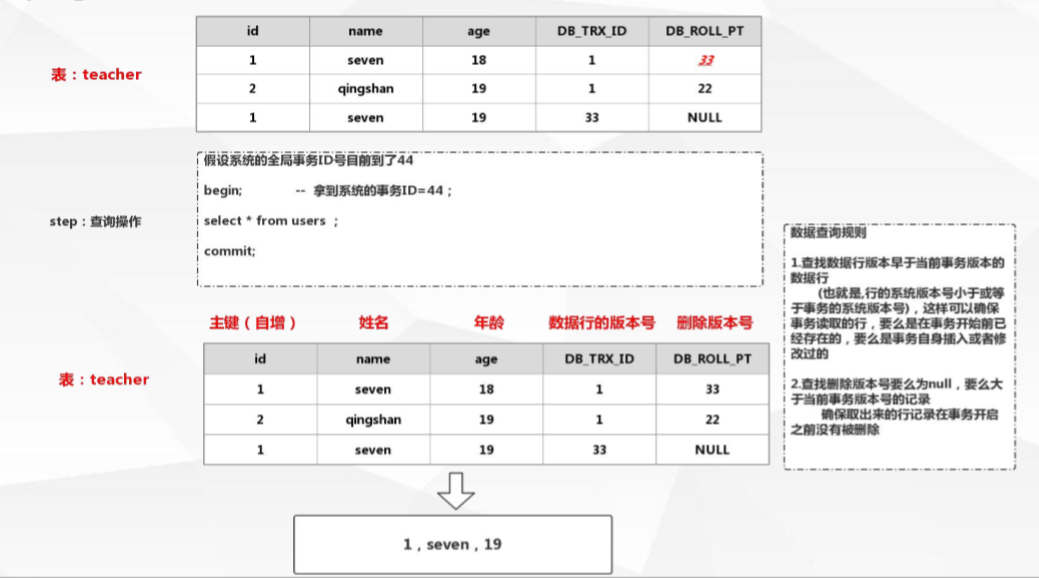
當進行查詢時:根據查詢規則查詢出資料
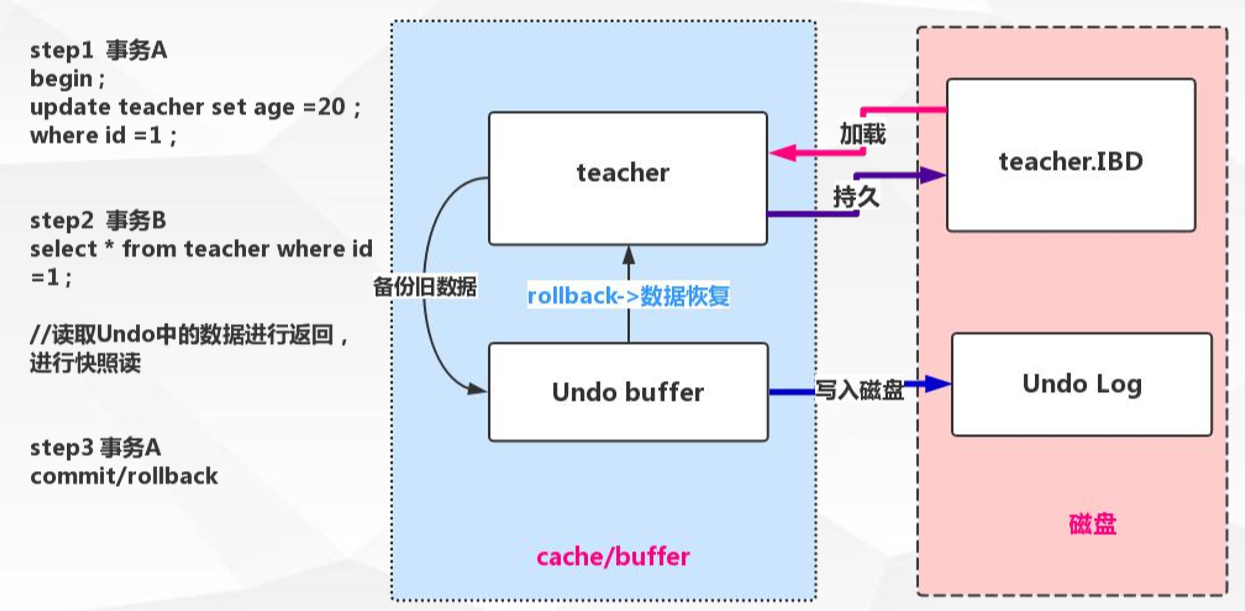
那問題又來了?開啟兩個事物A和B,在事物A中先進行update語句沒有手動提交,事物B中進行select 查詢。如果按照mvcc原則那麼事物B中就會查詢事物A中沒有修改的資料。那麼mysql會用Undo log日誌檔案解決這個問題,undo log有兩個作用:
Undo Log實現事務原子性: 事務處理過程中如果出現了錯誤或者使用者執行了 ROLLBACK語句,Mysql可以利用Undo Log中的備份將資料恢復到事務開始之前的狀態。
Undo log實現多版本併發控制: 事務未提交之前,Undo儲存了未提交之前的版本資料,Undo中的資料可作為資料舊版本快照供其他併發事務進行快照讀。
mysql的經驗總結
1.索引列的資料長度能少則少。
2.索引一定不是越多越好,越全越好,一定是建合適的。
3.匹配列字首可用到索引 like 9998%,like %999%、like %999用不到索引。
4.where條件中not in和 <> 不等於號無法用到索引。
5.匹配範圍值,order by 也可用到索引。
6.多用指定列查詢,只返回自己想到的資料列,少用select *。
7.聯合索引中如果不是按照索引最左列開始查詢,無法使用索引。
8.聯合索引中精確匹配最左前列並範圍匹配另外一列可以用到的索引。
9.聯合索引中如果有某列的範圍查詢,則其右邊的所有列都無法使用索引。
58同城30條軍規
一、基礎規範
(1)必須使用InnoDB儲存引擎 解讀:支援事務、行級鎖、併發效能更好、CPU及記憶體快取頁優化使得資源利用率更高
(2)必須使用UTF8字符集 UTF-8MB4 解讀:萬國碼,無需轉碼,無亂碼風險,節省空間
(3)資料表、資料欄位必須加入中文註釋 解讀:N年後誰tm知道這個r1,r2,r3欄位是幹嘛的
(4)禁止使用儲存過程、檢視、觸發器、Event 解讀:高併發大資料的網際網路業務,架構設計思路是“解放資料庫CPU,將計算轉移到服務 層”,併發量大的情況下,這些功能很可能將資料庫拖死,業務邏輯放到服務層具備更好的 擴充套件性,能夠輕易實現“增機器就加效能”。資料庫擅長儲存與索引,CPU計算還是上移吧
(5)禁止儲存大檔案或者大照片 解讀:為何要讓資料庫做它不擅長的事情?大檔案和照片儲存在檔案系統,資料庫裡存URI 多好
二、命名規範
(6)只允許使用內網域名,而不是ip連線資料庫
(7)線上環境、開發環境、測試環境資料庫內網域名遵循命名規範 業務名稱:xxx 線上環境:dj.xxx.db 開發環境:dj.xxx.rdb 測試環境:dj.xxx.tdb 從庫在名稱後加-s標識,備庫在名稱後加-ss標識 線上從庫:dj.xxx-s.db 線上備庫:dj.xxx-sss.db
(8)庫名、表名、欄位名:小寫,下劃線風格,不超過32個字元,必須見名知意,禁止 拼音英文混用
(9)表名t_xxx,非唯一索引名idx_xxx,唯一索引名uniq_xxx
三、表設計規範
(10)單例項表數目必須小於500
(11)單表列數目必須小於30
(12)表必須有主鍵,例如自增主鍵 解讀: a)主鍵遞增,資料行寫入可以提高插入效能,可以避免page分裂,減少表碎片提升空間和 記憶體的使用 b)主鍵要選擇較短的資料型別, Innodb引擎普通索引都會儲存主鍵的值,較短的資料類 型可以有效的減少索引的磁碟空間,提高索引的快取效率 c) 無主鍵的表刪除,在row模式的主從架構,會導致備庫夯住
(13)禁止使用外來鍵,如果有外來鍵完整性約束,需要應用程式控制 解讀:外來鍵會導致表與表之間耦合,update與delete操作都會涉及相關聯的表,十分影響 sql 的效能,甚至會造成死鎖。高併發情況下容易造成資料庫效能,大資料高併發業務場景 資料庫使用以效能優先
四、欄位設計規範
(14)必須把欄位定義為NOT NULL並且提供預設值 解讀: a)null的列使索引/索引統計/值比較都更加複雜,對MySQL來說更難優化 b)null 這種型別MySQL內部需要進行特殊處理,增加資料庫處理記錄的複雜性;同等條 件下,表中有較多空欄位的時候,資料庫的處理效能會降低很多 c)null值需要更多的儲存空,無論是表還是索引中每行中的null的列都需要額外的空間來標 識 d)對null 的處理時候,只能採用is null或is not null,而不能採用=、in、<、<>、!=、 not in這些操作符號。如:where name!=’shenjian’,如果存在name為null值的記 錄,查詢結果就不會包含name為null值的記錄
(15)禁止使用TEXT、BLOB型別 解讀:會浪費更多的磁碟和記憶體空間,非必要的大量的大欄位查詢會淘汰掉熱資料,導致內
存命中率急劇降低,影響資料庫效能
(16)禁止使用小數儲存貨幣 解讀:使用整數吧,小數容易導致錢對不上
(17)必須使用varchar(20)儲存手機號 解讀: a)涉及到區號或者國家代號,可能出現+-() b)手機號會去做數學運算麼? c)varchar可以支援模糊查詢,例如:like“138%”
(18)禁止使用ENUM,可使用TINYINT代替 解讀: a)增加新的ENUM值要做DDL操作 b)ENUM的內部實際儲存就是整數,你以為自己定義的是字串?
五、索引設計規範
(19)單表索引建議控制在5個以內
(20)單索引欄位數不允許超過5個 解讀:欄位超過5個時,實際已經起不到有效過濾資料的作用了
(21)禁止在更新十分頻繁、區分度不高的屬性上建立索引 解讀: a)更新會變更B+樹,更新頻繁的欄位建立索引會大大降低資料庫效能 b)“性別”這種區分度不大的屬性,建立索引是沒有什麼意義的,不能有效過濾資料,性 能與全表掃描類似
(22)建立組合索引,必須把區分度高的欄位放在前面 解讀:能夠更加有效的過濾資料
六、SQL使用規範
(23)禁止使用SELECT *,只獲取必要的欄位,需要顯示說明列屬性 解讀: a)讀取不需要的列會增加CPU、IO、NET消耗 b)不能有效的利用覆蓋索引
(24)禁止使用INSERT INTO t_xxx VALUES(xxx),必須顯示指定插入的列屬性 解讀:容易在增加或者刪除欄位後出現程式BUG
(25)禁止使用屬性隱式轉換 解讀:SELECT uid FROM t_user WHERE phone=13812345678 會導致全表掃描,而不 能命中phone索引
(26)禁止在WHERE條件的屬性上使用函式或者表示式 解讀:SELECT uid FROM t_user WHERE from_unixtime(day)>='2017-02-15' 會導致全 表掃描 正確的寫法是:SELECT uid FROM t_user WHERE day>= unix_timestamp('2017-02-15 00:00:00')
(27)禁止負向查詢,以及%開頭的模糊查詢 解讀: a)負向查詢條件:NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等,會導致全表掃描 b)%開頭的模糊查詢,會導致全表掃描
(28)禁止大表使用JOIN查詢,禁止大表使用子查詢 解讀:會產生臨時表,消耗較多記憶體與CPU,極大影響資料庫效能
(29)禁止使用OR條件,必須改為IN查詢 解讀:舊版本Mysql的OR查詢是不能命中索引的,即使能命中索引,為何要讓資料庫耗費 更多的CPU幫助實施查詢優化呢?
(30)應用程式必須捕獲SQL異常,並有相應處理
此內容參考咕泡學院老師講解的內容,感謝學院分享!