
Hive 系列(五)—— Hive 分割槽表和分桶表
一、分割槽表
1.1 概念
Hive 中的表對應為 HDFS 上的指定目錄,在查詢資料時候,預設會對全表進行掃描,這樣時間和效能的消耗都非常大。
分割槽為 HDFS 上表目錄的子目錄,資料按照分割槽儲存在子目錄中。如果查詢的 where 字句的中包含分割槽條件,則直接從該分割槽去查詢,而不是掃描整個表目錄,合理的分割槽設計可以極大提高查詢速度和效能。
這裡說明一下分割槽表並 Hive 獨有的概念,實際上這個概念非常常見。比如在我們常用的 Oracle 資料庫中,當表中的資料量不斷增大,查詢資料的速度就會下降,這時也可以對錶進行分割槽。表進行分割槽後,邏輯上表仍然是一張完整的表,只是將表中的資料存放到多個表空間(物理檔案上),這樣查詢資料時,就不必要每次都掃描整張表,從而提升查詢效能。
1.2 使用場景
通常,在管理大規模資料集的時候都需要進行分割槽,比如將日誌檔案按天進行分割槽,從而保證資料細粒度的劃分,使得查詢效能得到提升。
1.3 建立分割槽表
在 Hive 中可以使用 PARTITIONED BY 子句建立分割槽表。表可以包含一個或多個分割槽列,程式會為分割槽列中的每個不同值組合建立單獨的資料目錄。下面的我們建立一張僱員表作為測試:
CREATE EXTERNAL TABLE emp_partition( empno INT, ename STRING, job STRING, mgr INT, hiredate TIMESTAMP, sal DECIMAL(7,2), comm DECIMAL(7,2) ) PARTITIONED BY (deptno INT) -- 按照部門編號進行分割槽 ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t" LOCATION '/hive/emp_partition';
1.4 載入資料到分割槽表
載入資料到分割槽表時候必須要指定資料所處的分割槽:
# 載入部門編號為20的資料到表中
LOAD DATA LOCAL INPATH "/usr/file/emp20.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=20)
# 載入部門編號為30的資料到表中
LOAD DATA LOCAL INPATH "/usr/file/emp30.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=30)1.5 檢視分割槽目錄
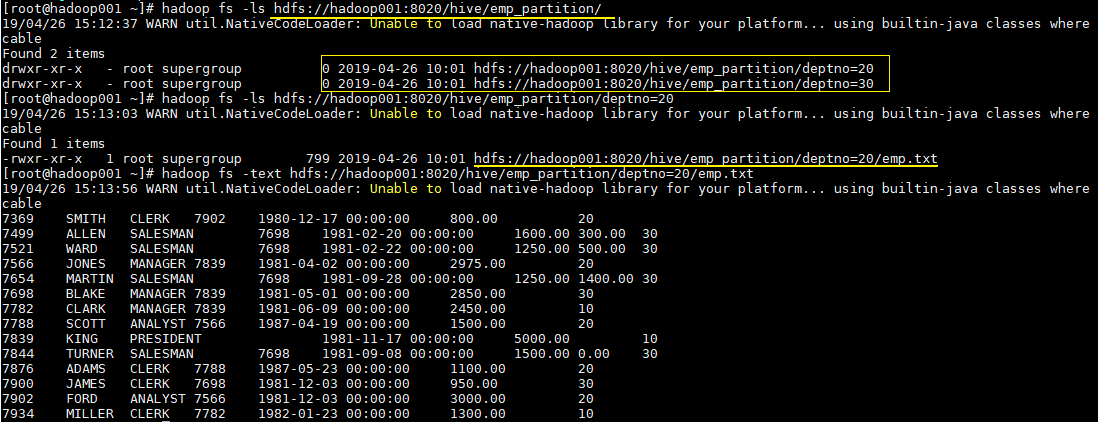
這時候我們直接查看錶目錄,可以看到表目錄下存在兩個子目錄,分別是 deptno=20 和 deptno=30,這就是分割槽目錄,分割槽目錄下才是我們載入的資料檔案。
# hadoop fs -ls hdfs://hadoop001:8020/hive/emp_partition/這時候當你的查詢語句的 where 包含 deptno=20,則就去對應的分割槽目錄下進行查詢,而不用掃描全表。
二、分桶表
1.1 簡介
分割槽提供了一個隔離資料和優化查詢的可行方案,但是並非所有的資料集都可以形成合理的分割槽,分割槽的數量也不是越多越好,過多的分割槽條件可能會導致很多分割槽上沒有資料。同時 Hive 會限制動態分割槽可以建立的最大分割槽數,用來避免過多分割槽檔案對檔案系統產生負擔。鑑於以上原因,Hive 還提供了一種更加細粒度的資料拆分方案:分桶表 (bucket Table)。
分桶表會將指定列的值進行雜湊雜湊,並對 bucket(桶數量)取餘,然後儲存到對應的 bucket(桶)中。
1.2 理解分桶表
單從概念上理解分桶表可能會比較晦澀,其實和分割槽一樣,分桶這個概念同樣不是 Hive 獨有的,對於 Java 開發人員而言,這可能是一個每天都會用到的概念,因為 Hive 中的分桶概念和 Java 資料結構中的 HashMap 的分桶概念是一致的。
當呼叫 HashMap 的 put() 方法儲存資料時,程式會先對 key 值呼叫 hashCode() 方法計算出 hashcode,然後對陣列長度取模計算出 index,最後將資料儲存在陣列 index 位置的連結串列上,連結串列達到一定閾值後會轉換為紅黑樹 (JDK1.8+)。下圖為 HashMap 的資料結構圖:
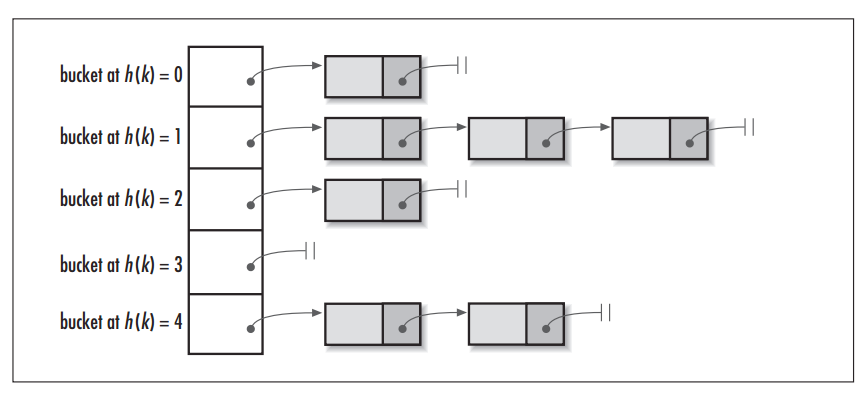
圖片引用自:HashMap vs. Hashtable
1.3 建立分桶表
在 Hive 中,我們可以通過 CLUSTERED BY 指定分桶列,並通過 SORTED BY 指定桶中資料的排序參考列。下面為分桶表建表語句示例:
CREATE EXTERNAL TABLE emp_bucket(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS --按照員工編號雜湊到四個 bucket 中
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_bucket';1.4 載入資料到分桶表
這裡直接使用 Load 語句向分桶表載入資料,資料時可以載入成功的,但是資料並不會分桶。
這是由於分桶的實質是對指定欄位做了 hash 雜湊然後存放到對應檔案中,這意味著向分桶表中插入資料是必然要通過 MapReduce,且 Reducer 的數量必須等於分桶的數量。由於以上原因,分桶表的資料通常只能使用 CTAS(CREATE TABLE AS SELECT) 方式插入,因為 CTAS 操作會觸發 MapReduce。載入資料步驟如下:
1. 設定強制分桶
set hive.enforce.bucketing = true; --Hive 2.x 不需要這一步在 Hive 0.x and 1.x 版本,必須使用設定 hive.enforce.bucketing = true,表示強制分桶,允許程式根據表結構自動選擇正確數量的 Reducer 和 cluster by column 來進行分桶。
2. CTAS匯入資料
INSERT INTO TABLE emp_bucket SELECT * FROM emp; --這裡的 emp 表就是一張普通的僱員表可以從執行日誌看到 CTAS 觸發 MapReduce 操作,且 Reducer 數量和建表時候指定 bucket 數量一致:

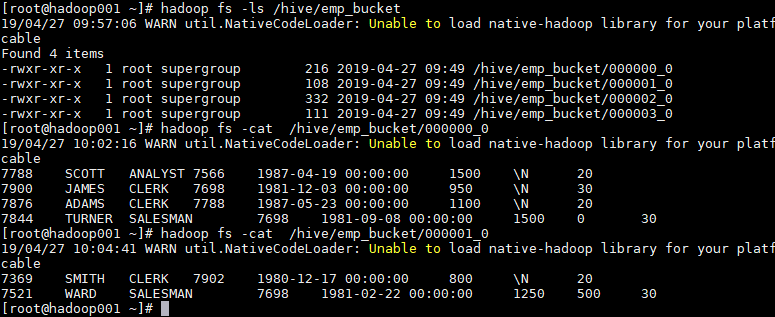
1.5 檢視分桶檔案
bucket(桶) 本質上就是表目錄下的具體檔案:
三、分割槽表和分桶表結合使用
分割槽表和分桶表的本質都是將資料按照不同粒度進行拆分,從而使得在查詢時候不必掃描全表,只需要掃描對應的分割槽或分桶,從而提升查詢效率。兩者可以結合起來使用,從而保證表資料在不同粒度上都能得到合理的拆分。下面是 Hive 官方給出的示例:
CREATE TABLE page_view_bucketed(
viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING )
PARTITIONED BY(dt STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;此時匯入資料時需要指定分割槽:
INSERT OVERWRITE page_view_bucketed
PARTITION (dt='2009-02-25')
SELECT * FROM page_view WHERE dt='2009-02-25';參考資料
- LanguageManual DDL BucketedTables
更多大資料系列文章可以參見 GitHub 開源專案: 大資料入門指南