
時尚電商新賽道:揭祕 FashionAI 技術

阿里妹導讀:雷音是阿里巴巴研究員、淘系技術部 FashionAI 負責人,在淘系技術嘉年華矽谷站,他分享了《時尚電商新賽道— FashionAI 中的技術》 ,旨在揭祕:從面向機器學習的知識重建切入,提出了在 AI 能力的推動下,讓人值得期待的未來。究竟在阿里巴巴研究員眼中,未來是什麼樣的?接下來,我們一起探祕。
1、從推薦技術說起
使用者行為
從推薦技術說起,首先是基於使用者行為的推薦,包括使用者的點選行為、瀏覽行為、購買行為。推薦技術提升了使用者找商品的效率,也帶來了公司收益的增長。當推薦的效率提高到一定程度的時候,會出現瓶頸,比如說你買了一件上衣之後,還繼續給你推上衣,這個問題這些年一直被詬病。如果是基於使用者行為的話,會朝著這個問題的改善方向發展。
使用者畫像
第二個是使用者畫像。很多人在做使用者洞察,描述使用者精準畫像。但我始終對使用者畫像保持懷疑態度,比如說買衣服,你拿的可能都是使用者的行為資料:瀏覽、點選、購買。可是,如果你知道使用者膚色的色號、身高、體重、三圍,這個使用者畫像比前者精準多少呢?所以說,所謂的使用者洞察、使用者畫像,今天來看其實還是非常粗糙的。
知識圖譜
第三個我們還可以做知識圖譜,來幫助做關聯推薦。比如,買魚竿推薦其他的漁具,買了車燈給你推其他的汽車配件。但是到今天為止,關聯推薦的效果還不夠好,還有很多困難。
以上是推薦技術通常會考慮的事。那麼我們用服飾推薦領域來看一下,還有什麼其他的可能。一個服裝的線下店,我們對一個導購員的核心考量指標是什麼?是關聯購買。顧客買了一件衣服,這是不計入導購員貢獻的,而導購員通過讓使用者買另外的關聯衣服才是計入導購員的績效,所以,重要的是關聯購買。關聯購買裡面的重要邏輯是搭配。當我們把推薦做到具體某一個領域的時候,我們就有了專屬於這個領域的一些推薦邏輯,這就是在日常裡面在發生的邏輯。
2、為什麼要做行業知識重建?
接下來,我們看看怎樣才能做好搭配。大部分使用者搭配不好的原因是穿搭需要相當多的知識和經驗。衣服的屬性,設計元素是抓手,它的準確率和豐富性一定要足夠,不夠的話做不出可靠的搭配來。
知識圖譜的典型情況就是通過人的經驗或使用者資料把很多的知識點關聯起來。知識圖譜裡知識點的生成更多是通過常識的方式。比如說我是一個人,我的朋友是誰,我上級是誰。“我”這個知識點是通過常識產生的。
還有一類方法叫專家系統,比如說我們有很多紅人,把他理解成專家,他所沉澱下的專業經驗。每個領域都會有一些專家,比如醫療系統裡就是醫生,專家系統大概是在知識圖譜興起之前人工智慧普遍採用的方式。
除此之外,還有一層是知識點,是更基礎的部分,如果知識點本身有問題的話,在這上面構建出來的知識關係都會有問題。在這個基礎上去做 AI 演算法,效果就不夠好,這可能是人工智慧難以落地的原因之一。要有勇氣去重新構建這個知識點體系。
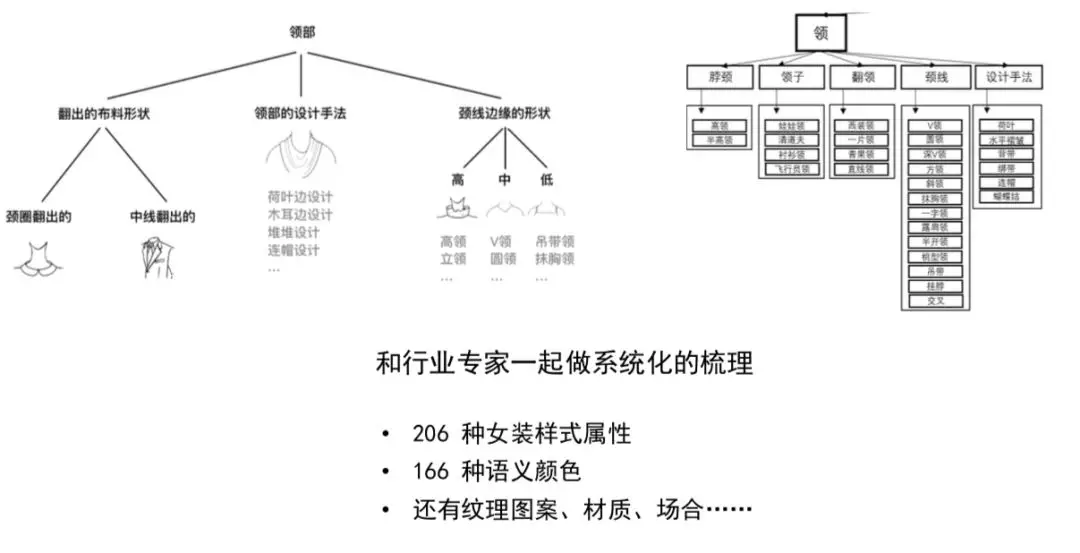
引用一個淘寶的例子,下圖的上半部分是我們運營或者設計師的知識體系,這是個“領型”的例子,有圓領、斜領、海軍領,可以看出結構是平鋪的、散亂的。以前知識是在人和人之間傳播的。尤其是在小的圈子裡,像設計師群體,知識可能非常含混,只要能溝通就行。再比如醫生寫的草書,醫生之間可以看的懂,但是病人都看不懂。很多知識用於人和人的溝通,有大量的二義性,不完備性。比如說服裝風格,一個標籤叫做“職場風”,另一個叫“中性風”。職場風跟中性風從視覺上無法區分,如果人類視覺都難以區分,而機器識別準確率超過80%,那肯定哪裡出錯了。

還有一類,打標籤的人可能本身理解就有問題。舉個極端的例子,曾經有一段時間,淘寶商家給衣服打標籤,有一半的女裝上都被商家打上了韓版的標籤。然而,它根本不是韓版,只是因為韓版賣的好,這說明商家打的標籤不是完全正確,有必要通過影象直接得出判斷。
3、面向機器學習的知識重建
前幾年我們找了淘寶、天貓的服飾運營,綜合了幾版的運營知識做了規整,不過還是不夠好。去年我們做 FashionAI 大賽,和港理工的服裝系合作,後來和北京服裝學院、浙理工都有合作。其實直接由服飾專家們給出的知識體系是不行的,因為我們需要的是一個面向機器學習的知識體系,機器是要分0和1,完備性、二義性問題、視覺不可分等這幾個我們總結出來的原則,這些都要儘量滿足。
我們把曾經散落的知識,按照劃分邏輯去組織,比如說領部,我們會根據它布料去分、設計手法去分、頸線邊緣去分,從幾個維度總結散落的知識點。原先是一盤散沙,最終會看到樹狀知識。我們把常用的女裝屬性整理出來,一共有206種,這還不包括“流行的設計手法”這種開放性的,不斷擴充變化的屬性。這個“整理”比大家想象的複雜得多,花了3到4年時間,除了考慮知識本身,還要進一步考察知識點所對應的資料收集難度,必要性。比如說女裝的西裝領還可以再細分9種,接近視覺不可分,這時停留在女裝西裝領這個粒度就夠了,就不再做細分。
有時很難事先判斷一個屬性是否能學出好的模型來,這時屬性的定義還要做多輪的迭代。我發現我的屬性定義有問題,我倒回去重新定義,然後再重新收集資料、訓練模型,直到模型可以達到要求。等做完知識重建,曾經十幾個屬性識別準確率普遍提高了20%,這個提升是非常大的。
我們現在有206種女裝樣式,有166種語義顏色,還有材質、場景、溫度等知識體系。怎麼定義顏色?在時尚行業裡,黃色幾乎是沒有意義的,講“檸檬黃”是有意義的,去年女裝就流行檸檬黃。我們知道RGB顏色256256256,在潘通色表裡跟服飾相關的一共有2310種顏色,但這個色表裡都是色號,消費者沒法理解,我們在上面再建了一層560種有語義對應的顏色,這是跟北京服裝學院一起定的,用來做按顏色給衣服聚類又顯得過細,就又再建一個166種的,就是大家看到類似於“檸檬黃”、“芥末綠”這種語義顏色,到這個階段消費者才能理解。
還有很多的技術細節,比如說怎麼處理光照問題、色差問題等等,也有很多的難的地方,在這裡我會主要講面向機器學習的知識重建。
4、AI 使知識重建的大工程變得可行
接下來問題就來了,我有206種女裝樣式,收集資料訓練模型的話,怎樣才能做得完呢,更何況一個定義還可能要多輪迭代修正?
比如,下圖中的袖子款式叫風鈴袖,一個合格的資料集大概需要3000到4000張圖片。收集足夠多的,高質量的圖片是一個很大的挑戰,在2016年為了做一個3000到4000張圖片的高質量資料集,大概需要標註超過十萬張圖片,當時的標註留存率只有1.5%。當時的方法就類似學術界做的,先用一個詞去搜回很多圖,然後找人標註。更可能是始終找不到足夠多的圖片旁邊寫著風鈴袖,它都沒有標註,所以你是搜不到的。因此,知識重建確實是一個巨大的挑戰。以前根本沒有人有勇氣去做,因為你根本做不了。
2016年我們完成一項屬性識別要200天,這個時間包括了定義迭代花的時間。2017年我們用40天,2018年我們用2.5天,現在,我們大概用15個小時,到2019年底,我們計劃是縮減到0.5天。這是一個巨大的改變,我們提出“少樣本學習”。大概是在三年前,當時學術界還沒很多人提這個問題,但是我們已經看到了,因為我們痛苦的就是這個,不得不開始上手解決它了。
學術界提到“few-short learing”、小資料學習,更多是偏重如何從少量樣本直接得到一個好的模型,我們選的路不大一樣,我們是從旁邊繞路。

今天,我們把常用的96種女裝屬性完成了,就是利用我們的少樣本學習工具SECT(Small、Enough、Comprehensive),從“少”到“足夠多”到“足夠好”,最重要的是 SECT 不僅在 FashionAI 業務裡發生了作用,它還可以做泛內容識別,講得嚴謹一點,在“簡單內容分類”這類任務上表現得不錯。
在泛內容識別上,我們利用 SECT 系統已經完成70多個標籤識別,例如:“插畫、陽臺、上腳”等標籤,我們已經開始改變業務人員和演算法人員的工作模式,大家知道在深度學習出來之前,那時候我們的業務人員都不大敢提讓演算法人員給出個識別模型,因為開發週期太長了,為了去識別一個東西我要找演算法人員跟他商量,然後演算法人員手工去設計特徵。為了做一個能夠上線的、工業界能用的一個模型,最少花上半年、一年的時間,這是以前的模式。2013年深度學習開始流行之後,這個問題發生了轉化。演算法人員會說今天有了深度學習,業務人員你收集足夠多圖片就行了,我給你設計個好模型出來。如果這個模型不好的話,那是你收集的資料質量不行。這時候運營想去收集5000張圖片,發現還是成本很高。
我們今天還很難用 SECT 去解決機器視覺中的“檢測”問題,或者說檢測任務在我們的理解裡不是一個“少樣本”的問題,在檢測任務下應該叫做“弱監督”問題,弱監督跟少樣本也有所不同。

5、對未來的展望
我理解大資料應該分兩種,一種是說,你的商業洞察也好,模式分析也好,只有在大規模的資料上才能完成,這是真的大資料;還有一種是說今天的機器學習能力不行,必須有那麼多的資料才能出來一個模型,這個叫做偽大資料,因為隨著 AI 的能力越來越強,需要的樣本肯定越來越少。
以前有公司標榜自己有特別多的資料,比如說人臉資料或什麼的,把資料看成了資產。這個說法一定會慢慢落下去,因為 AI 能力越來越強,我們需要的資料量越來越少。SECT 再演變下去,會到什麼程度?可能中層的跟淺層的演算法人員不再需要了,業務人員直接上去提供十幾張圖(不會超過50張圖)交給系統,很快模型就會返回來,你再測試一下是否好用,如果不行,就再迭代學習,直到模型好用為止。它已經不是以前的,標註階段、訓練階段、測試階段,間隔得那麼遠。今天,整個迭代越來越快,如果說迭代可以減少到小時級、分鐘級的話,這實際上已經變成了一個人機互動的學習系統,這是未來會帶來巨大改變的東西。
淘寶內容平臺的運營人員說,過去兩個月產出了比之前三年還多的模型。我們自己組的演算法同學自己也用來解決屬性識別之外的各類問題,比如說我來矽谷之前,組裡同學想識別照片裡的人是正身還是背身的,是站姿還是坐姿,是一個深色人種還是一個黃面板等等,我們需要在很短的時間裡出6個判別模型。今天,我們可以一兩週內讓模型上線,準確率、召回率、泛化能力全都能達到要求。放在以前,這個事情沒有一年半載是不可能的。
業界裡有很多人總結深度學習的侷限,比如需要大資料、缺乏可解釋性,我覺得在未來幾年,我們對於什麼叫“樣本”、什麼叫“可解釋性”,會有一個新的理解。我們去年在朱鬆純老師主編的《視覺探索》上發了一篇文章,叫《如何做一個實用的影象資料集》,今年我們有計劃寫個續篇,就是《如何做一個實用的影象資料集(二)》,會重點聊一聊我們在少樣本學習上的體會和展望。
作者:阿里技術
原文連結
本文為雲棲社群原創內容,未經