
Java程序故障排查(CPU資源佔用高,介面響應超時,功能介面停滯等)
故障分析
# 導致系統不可用情況(頻率較大):
1)程式碼中某個位置讀取資料量較大,導致系統記憶體耗盡,進而出現Full GC次數過多,系統緩慢;
2)程式碼中有比較消耗CPU的操作,導致CPU過高,系統執行緩慢;
# 導致某功能執行緩慢(不至於導致系統不可用):
3)程式碼某個位置有阻塞性的操作,導致呼叫整體比較耗時,但出現比較隨機;
4)某執行緒由於某種原因進入WAITTING狀態,此時該功能整體不可用,但無法復現;
5)由於鎖使用不當,導致多個執行緒進入死鎖狀態,導致系統整體比較緩慢。
# 說明
對於後三種情況而言,是具有一定阻塞性操作,CPU和系統記憶體使用情況都不高,但功能卻很慢,所以通過檢視資源使用情況是無法查看出具體問題的!
應急處理
### 對於線上系統突然產生的執行緩慢問題,如果導致線上系統不可用。首先要做的是匯出jstack和記憶體資訊,重啟伺服器,儘快保證系統的高可用。
### 匯出jstack資訊
為避免重複贅述,此操作將在後面的"排查步驟"章節中體現!
### 匯出記憶體堆疊資訊
# 檢視要匯出的Java專案的pid
# jps -l
or
# ps -ef |grep java
# 匯出記憶體堆疊資訊
jmap -dump:live,format=b,file=heap8 <pid> # heap8是自定義的檔名
# 執行匯出的堆疊檔案
# ls
heap8
# hostname -I
10.2.2.162
# jhat -port 9998 heap8
# 瀏覽器訪問http://10.2.2.162:9998/

排查步驟
# 環境說明
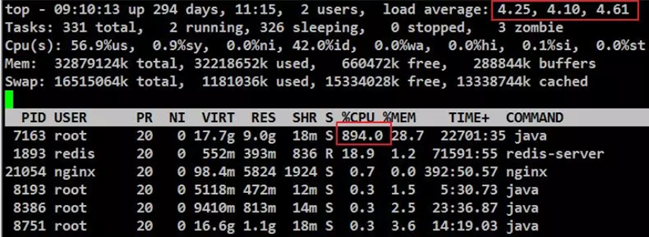
因平臺做了線上推廣,導致管理平臺門戶網頁進統計頁面請求超時,隨進伺服器作業系統檢視負載資訊,load average超過了4,負載較大,PID為7163的程序cpu資源佔用較高。
# 定位故障
# 處理思路:
找出CPU佔用率高的執行緒,再通過執行緒棧資訊找出該執行緒當時正在執行的問題程式碼段。
# 操作如下:
# 檢視高佔用的"程序"中佔用高的"執行緒"
# top -Hbp 7163 | awk '/java/ && $9>50'
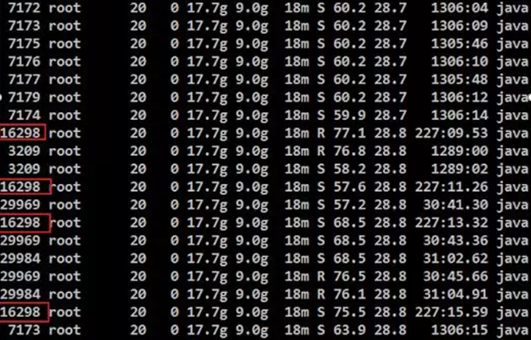
# 將16298的執行緒ID轉換為16進位制的執行緒ID
# printf "%x\n" 16298
3faa
# 通過jvm的jstack檢視程序資訊並儲存以供研發後續分析
# jstack 7163 | grep "3faa" -C 20 > 7163.log
# 重點說明
通過排查步驟,可得排查問題需要掌握的資訊如下:
1)資源佔用高對應的程序a的PID;
2)程序a對應的資源佔用高且最頻繁的執行緒b的ID;
3)將執行緒b的ID轉換為16進位制的ID。
資料庫問題引發的資源佔用過高
## 通過"排查步驟"章節可基本定位問題,後續請見下文!
確認問題及處理
# jstack $pid | grep "3faa" -C 20 # 3faa指的是高佔用程序中的高佔用的執行緒對應的16進位制id;

# 檢視到是資料庫的問題,排查思路:先列印所有在跑的資料庫執行緒,檢查後發現並跟進情況找到問題表;
# 列印MySQL現有程序資訊檔案
# mysql -uroot -p -e "show full processlist" > mysql_full_process.log
# 過濾出查詢最多的表
grep Query mysql_full_process.log
# 統計查詢最多的表的資料量
> use databases_name;
> select count(1) from table_name;
# 結合MySQL日誌資訊,可判斷問題是查詢時間過長導致,排查後發現表未建立索引;
> show create table table_name\G
# 詢問研發,確認資料不重要,檢查欄位由時間欄位,根據時間確認只保留一個月的資料;
> delete from table_name where xxxx_time < '2019-07-01 00:00:00' or xxxx_time is null;
# 建立索引
> alter table table_name add index (device_uuid);
# 確認索引是否建立
> show create table table_name;
總結
處理後進程的CPU佔用降至正常水平,本次排查主要用到了jvm程序檢視及dump程序詳細資訊的操作,確認是由資料庫問題導致的原因,並對資料庫進行了清理並建立了索引。
在處理問題後,又查詢了一下資料庫相關問題的優化,通常的優化方法還是新增索引。該方法新增引數具體如下:
innodb_buffer_pool_size=4G
Full GC次數過多
## 通過"排查步驟"章節可基本定位問題,後續請見下文!
確認問題及處理
# 特徵說明
對於Full GC較多的情況,有以下特徵:
1)程序的多個執行緒的CPU使用率都超過100%,通過jstack命令可看到大部分是垃圾回收執行緒;
2)通過jstat檢視GC情況,可看到Full GC次數非常多,並數值在不斷增加。
# 3faa指的是高佔用程序中的高佔用的執行緒對應的16進位制id;
# jstack $pid | grep "3faa" -C 20

說明:VM Thread指垃圾回收的執行緒。故基本可確定,當前系統緩慢的原因主要是垃圾回收過於頻繁,導致GC停頓時間較長。
# 檢視GC情況(1000指間隔1000ms,4指查詢次數)
# jstat -gcutil $pid 1000 4

說明:FGC指Full GC數量,其值一直在增加,圖中顯現高達6783,進一步證實是由於記憶體溢位導致的系統緩慢。
# 因筆者是運維,故確認了問題後,Dump記憶體日誌後交由研發解決程式碼層面問題!
總結
# 對於Full GC次數過大,主要有以下兩種原因:
1)程式碼中一次性獲取大量物件,導致記憶體溢位(可用Eclipse的Mat工具排查);
2)記憶體佔用不高,但Full GC數值較大,可能是顯示的System.gc()呼叫GC次數過多,可通過新增 -XX:+DisableExplicitGC 來禁用JVM 對顯示 GC 的響應。
服務不定期出現介面響應緩慢
情況說明
某個介面訪問經常需要3~4s甚至更長時間才能返回。一般而言,其消耗的CPU和記憶體資源不多,通過上述方式排查問題無法行通。
由於介面耗時較長問題不定時出現,導致通過jstack命令得到執行緒訪問的堆疊資訊,根據其資訊也不一定能定位到導致耗時操作的執行緒(概率事件)。
定位思路
在排除網路因素後,通過壓測工具對問題介面不斷加大訪問力度。當該介面中有某個位置是比較耗時的,由於訪問的頻率高,將導致大多數的執行緒都阻塞於該阻塞點。
通過分析多個執行緒日誌,能得到相同的TIMED_WAITING堆疊日誌,基本上就可定位到該介面中較耗時的程式碼的位置。
# 示例
# 程式碼中有比較耗時的阻塞操作,通過壓測工具得到的執行緒堆疊日誌,如下:
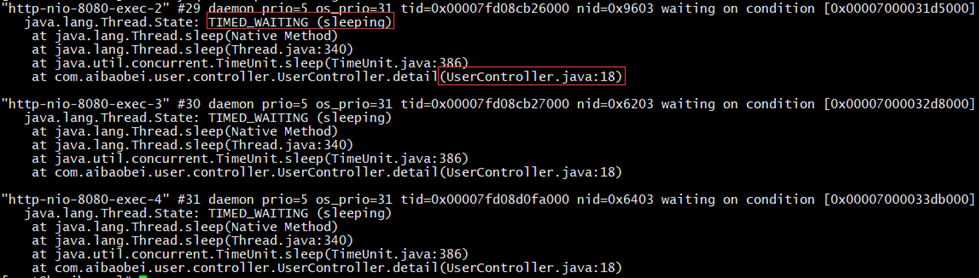
說明:由圖可得,多個執行緒都阻塞在了UserController的第18行,說明此時一個阻塞點,也是導致該介面較緩慢的原因。
大總結
# 總體性的分析思路
當Java應用出現問題時,處理步驟如下:
通過 top 命令定位CPU資源佔用較高的程序pid,再 top -Hp <pid> 命令定位出CPU資源佔用較高的執行緒的id,並將其執行緒id轉換為十六進位制的表現形式,再通過 jstack <pid> | grep <id> 命令檢視日誌資訊,定位具體問題。
# 此處根據日誌資訊分析,可分為兩種情況,如下:
# A情況
A.a)若使用者執行緒正常,則通過該執行緒的堆疊資訊檢視比較消耗CPU的具體程式碼區域;
A.b)若是VM Thread,則通過 jstat -gcutil <pid> <interval> <times> 命令檢視當前GC狀態,然後通過 jmap -dump:live,format=b,file=<filepath> <pid> 匯出當前系統記憶體資料,用Eclipse的Mat工具進行分析,進而針對比較消耗記憶體的程式碼區進行相關優化。
# B情況
若通過top命令檢視到CPU和記憶體使用率不高,則可考慮以下三種情況。
B.a)若是不定時出現介面耗時過長,則可通過壓測方式增大阻塞點出現的概率,從而通過jstack命令檢視堆疊資訊,找到阻塞點;
B.b)若是某功能訪問時突然出現停滯(異常)狀況,重啟後又正常了,同時也無法復現。此時可通過多次匯出jstack日誌的方式,對比並定位出較長時間處於等待狀態的使用者執行緒,再從中篩選出問題執行緒;
B.c)若通過jstack命令檢視到死鎖狀態,則可檢查產生死鎖的執行緒的具體阻塞點,進而相應處理。