
第十一講:爬取貓眼網站上的前100名電影
本次我們來通過翻頁爬取的方式爬取貓眼電影裡面推薦的前100名電影,並存儲到資料庫。
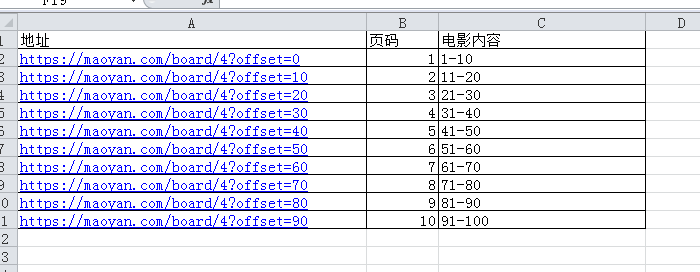
1、我們登入貓眼,看下我們的資料在哪裡
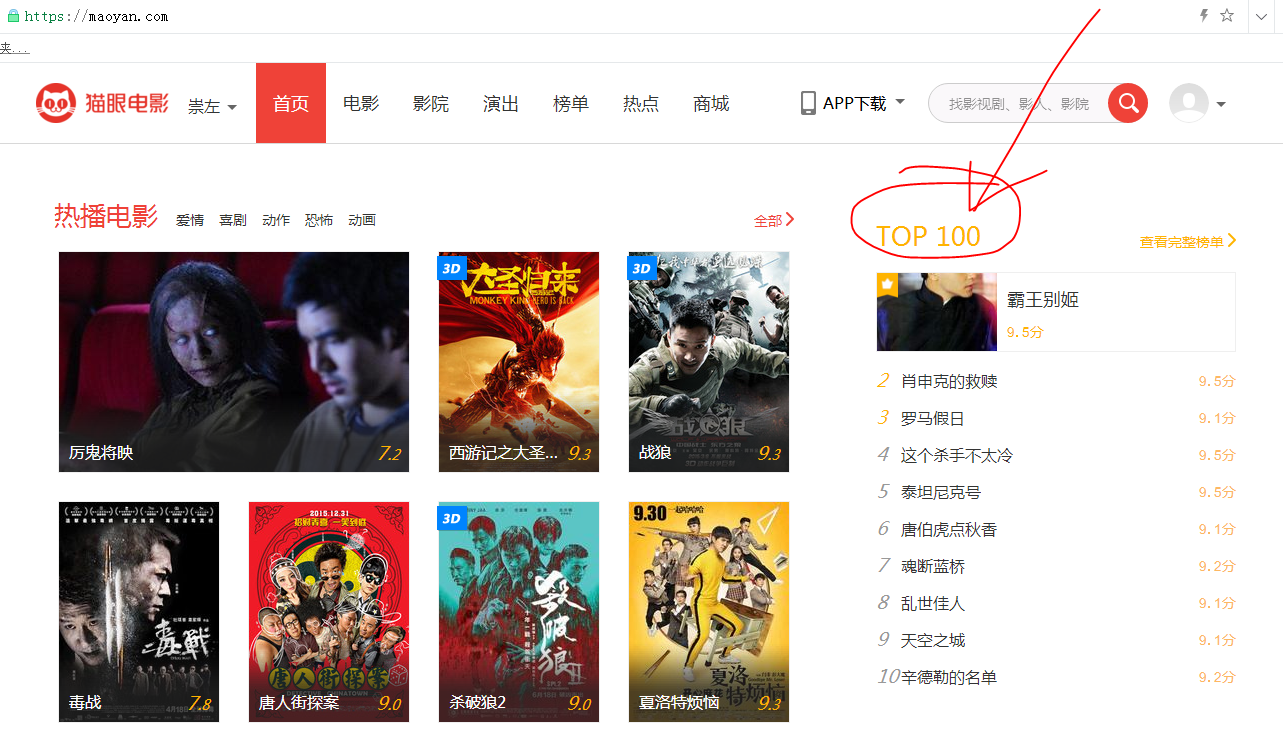
然後點選今日TOP100,看下具體的網頁資料
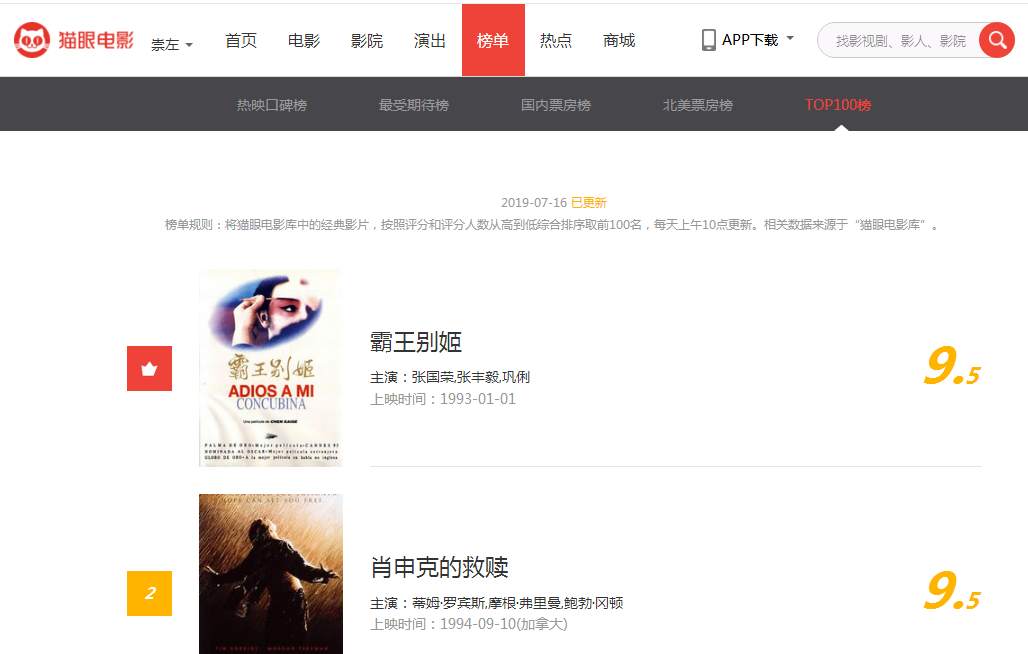
最下面我們看到底部有頁碼,並分析頁碼與位址列的關係。
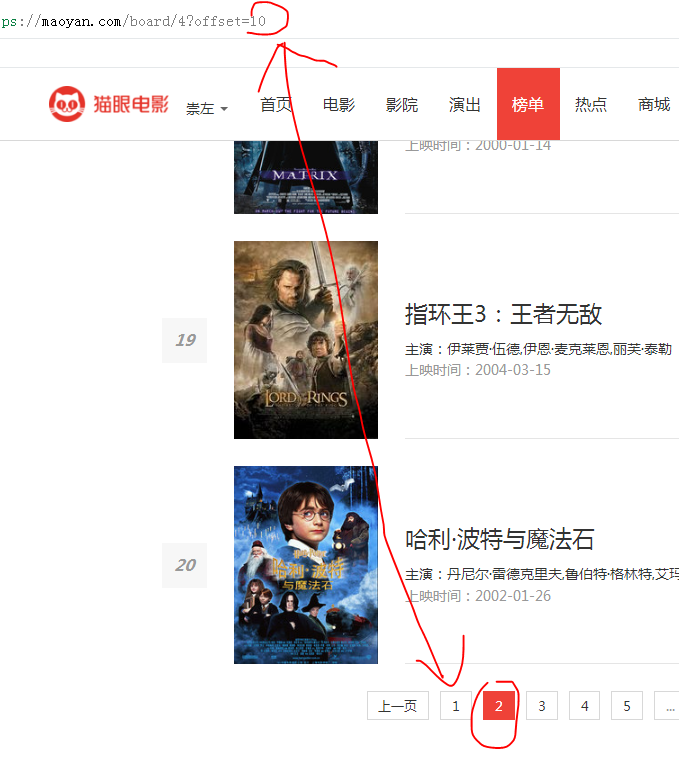
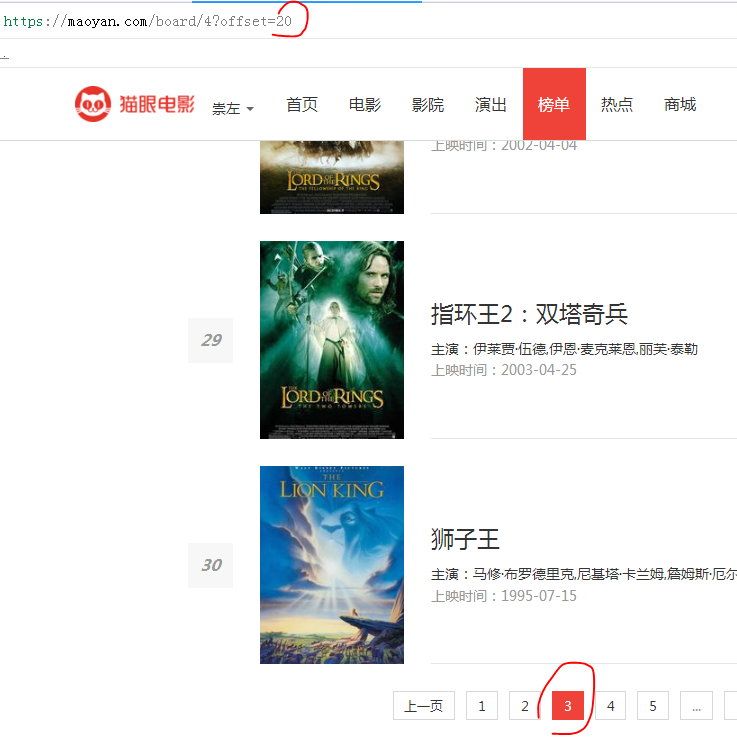

我們可以總結出以下規律:
後續我們通過不斷變化位址列就可以實現翻頁搜尋資訊的效果。
而,我們要獲取的影片內容有哪些?下面這些:排名、影片名稱、主演、上映時間、評分。
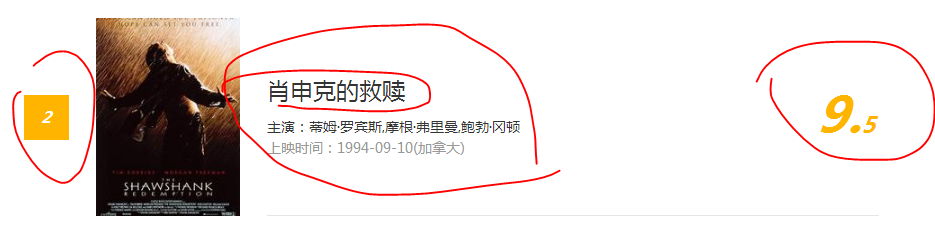
對於我們要獲取的資訊,我們要檢視原始碼,看下對應的資訊的通用格式是怎樣的。
按F12鍵,在除錯模式裡面點選小箭頭,選中對應的頁面元素就可以看到元素的原始碼了。
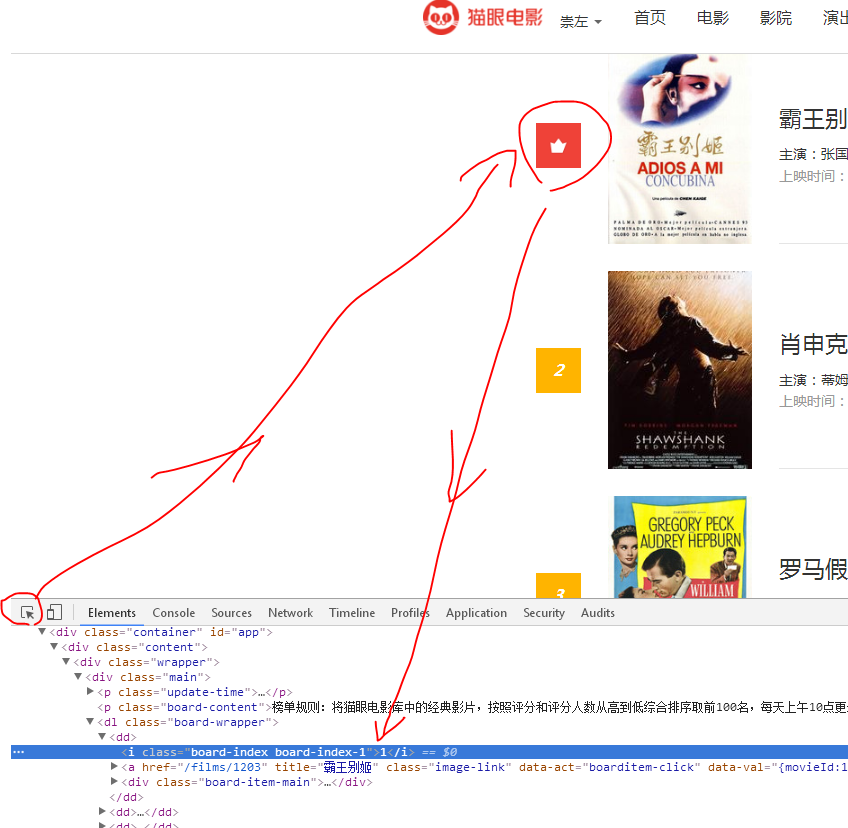
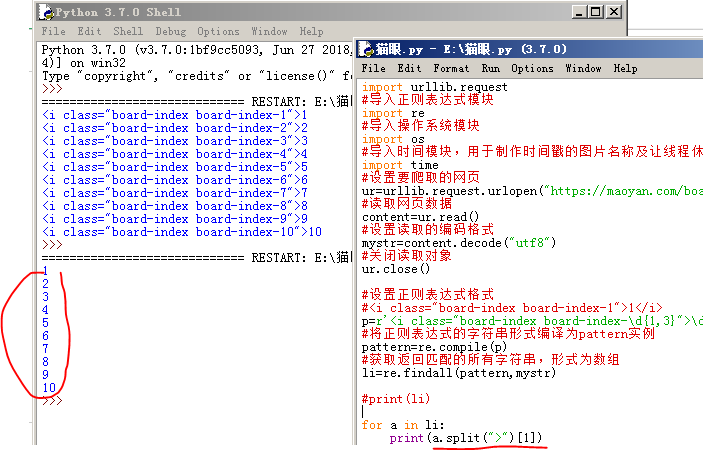
1、排名:
元素格式:<i class="board-index board-index-1">1</i>
上面格式中的紅色字型是可以改變的,比如第二名就是:<i class="board-index board-index-2">2</i>
我們可以用\d{1,3} 代替1-100的數字,那麼對應的正則表示式可以寫成:
p=r'<i class="board-index board-index-\d{1,3}">\d{1,3}'
所以,我們獲取排名的程式碼如下:
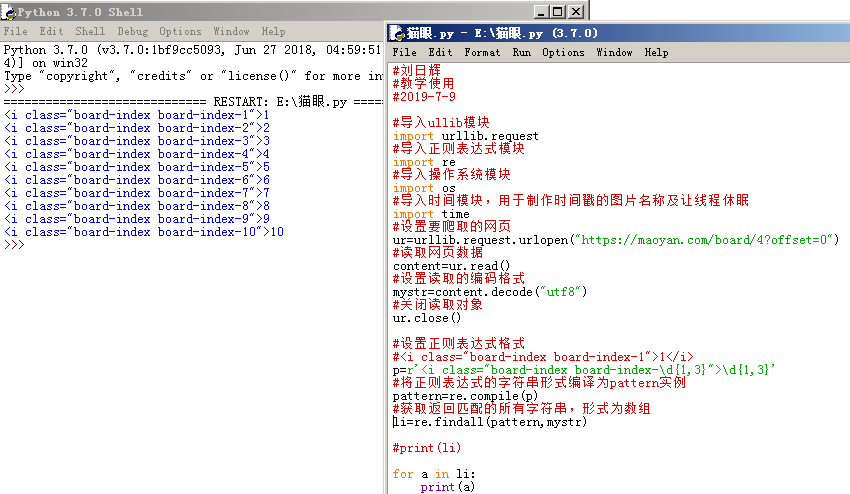
最後在修改一下,把數字提取出來,用split()函式:
2、電影名稱:
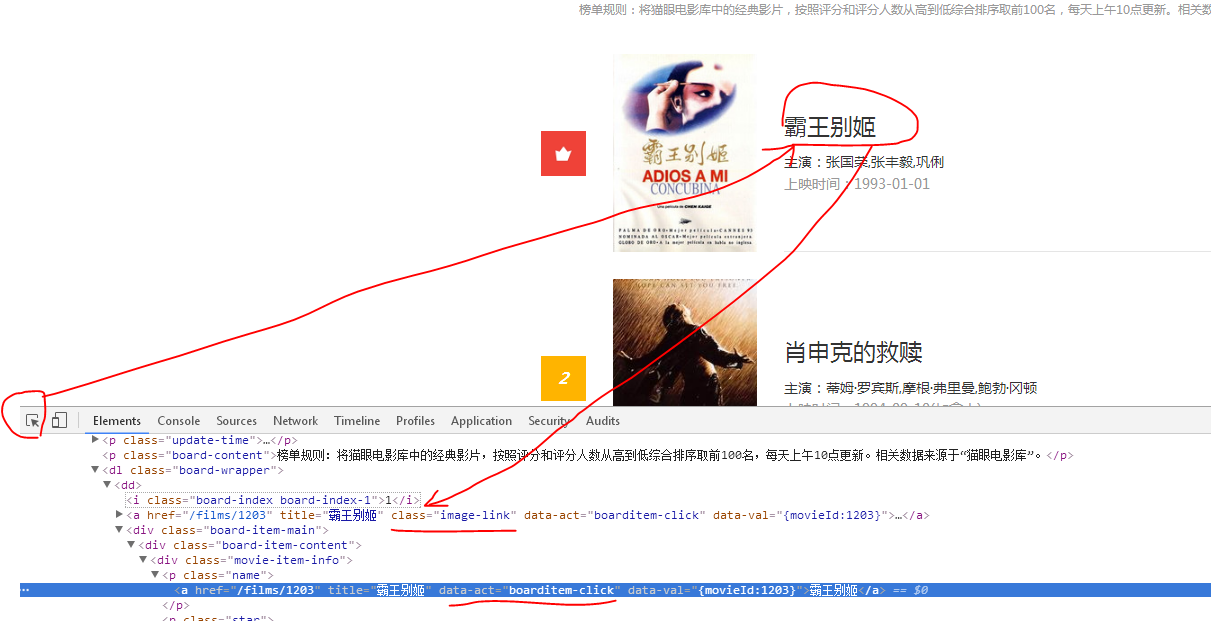
有兩條,我們只取一條就可以了。
元素格式:<a href="/films/1203" title="霸王別姬" class="image-link"
根據上面,我們可以寫正則表示式為:p2=r'<a href="/films/\d{1,}" title="\S{1,}" class="image-link"
程式碼如下:

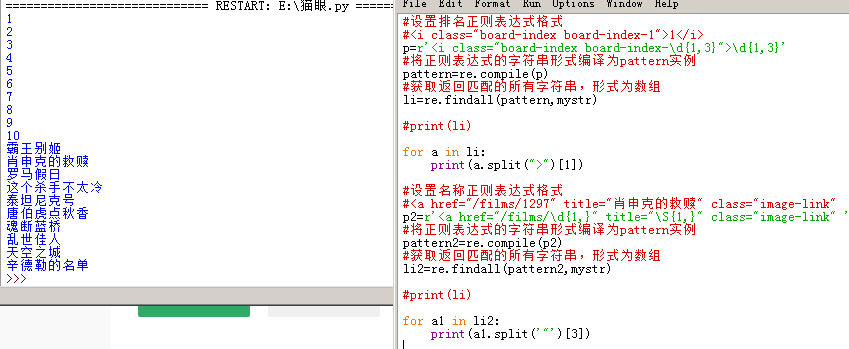
最後,我們要修改下,只過濾電影名稱,採用split()函式
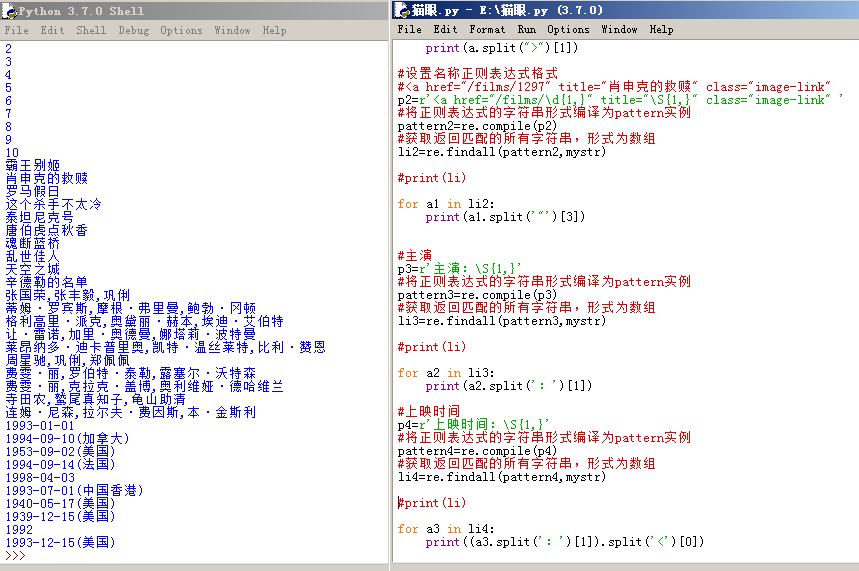
3、主演與上映時間:
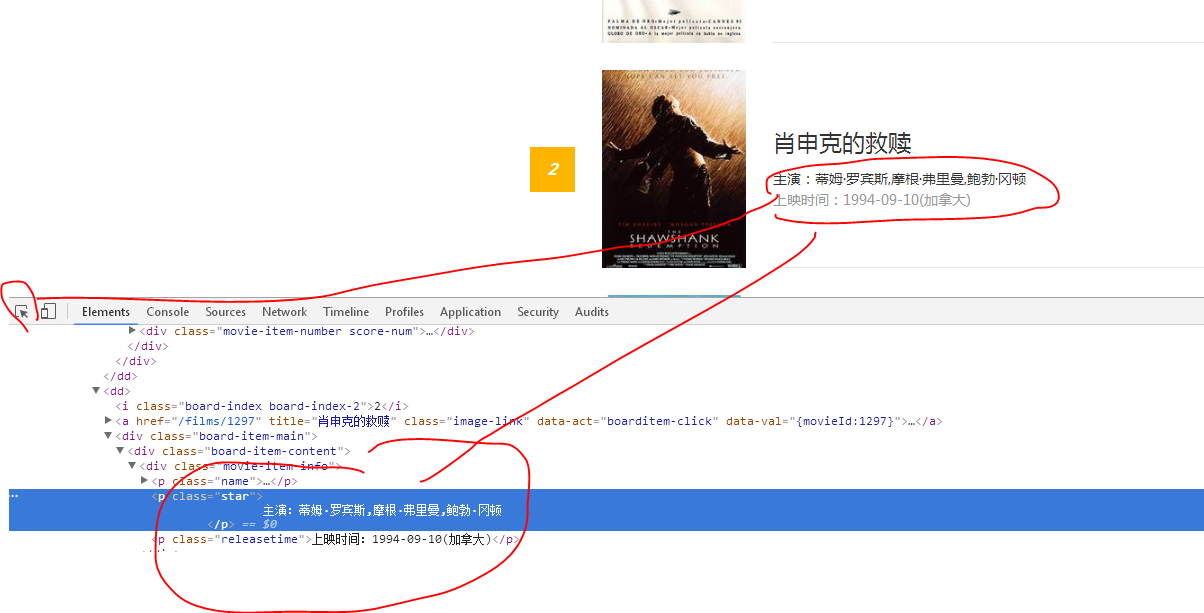
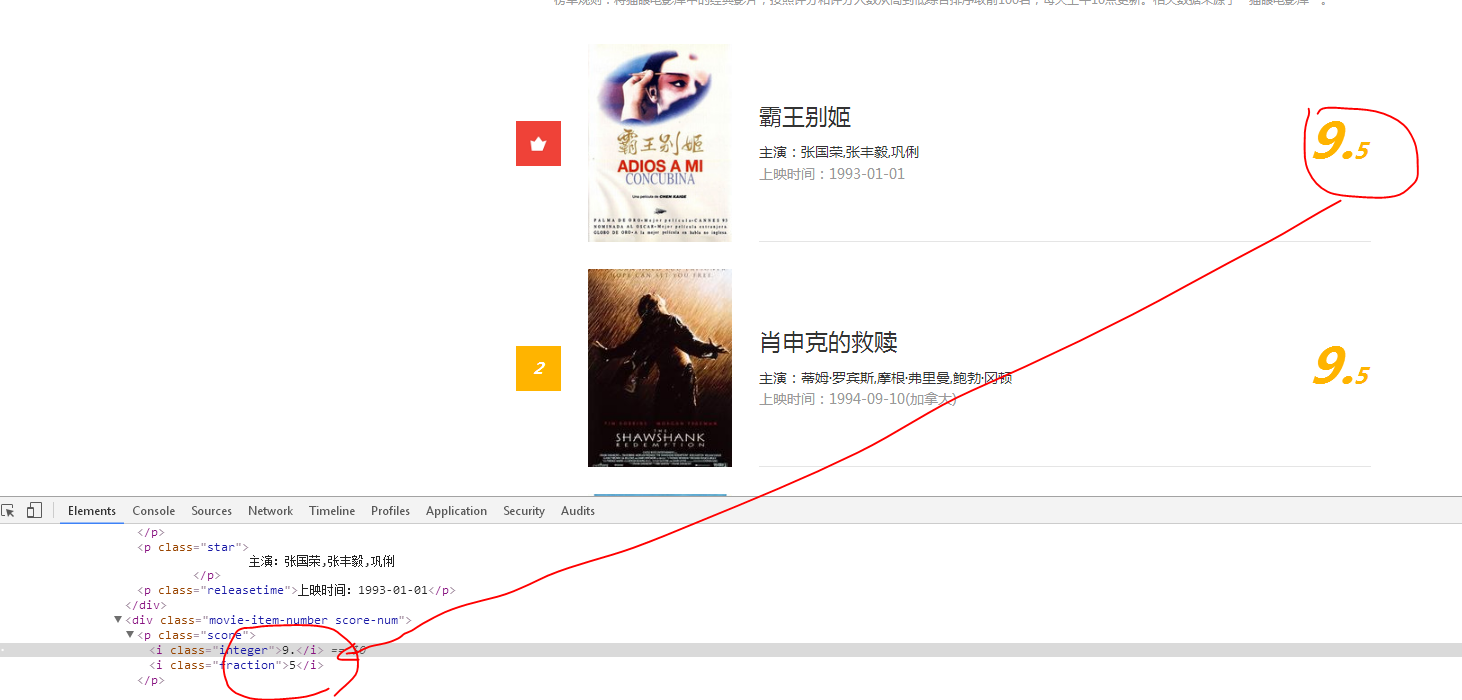
4、最後是評分
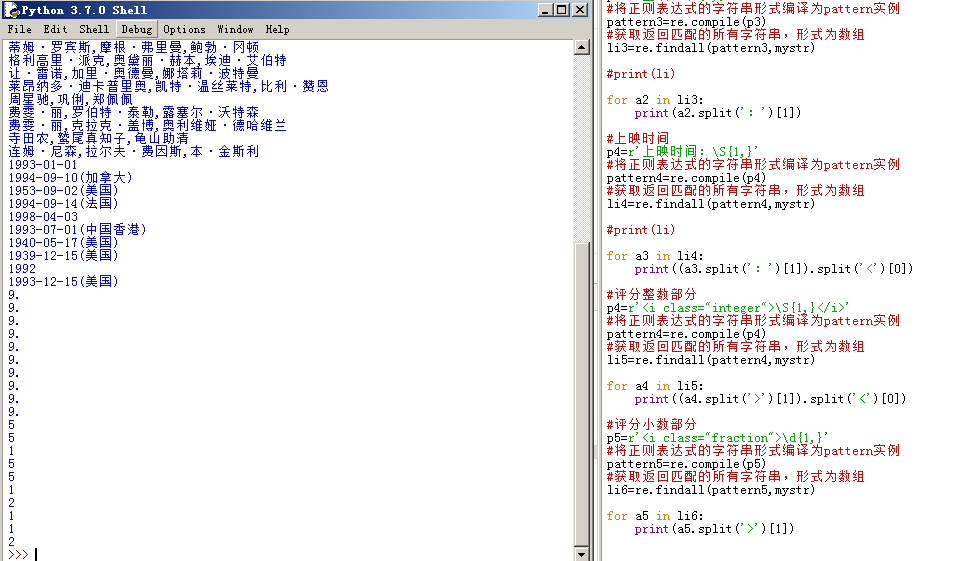
最後,我們要做的是:
1、分值合併。
2、以上各個值的組裝。
3、寫入資料庫。
4、翻頁
先寫到這裡,同學們思考上面兩個,答案下面一講再公佈。
注:其實我們的正則表示式更加精準的話,就不用擷取那麼多次。後續再重點講正則表