
RDS 5.7三節點企業版時代的資料一致性解決方案
上篇我們看到了在MySQL主備模式下,我們在資料一致性上做了不少事情,但解決方案都有一定的侷限性,適合部分場景或者解決不徹底的問題。隨著以Google Spanner以及Amazon Aruora 為代表的NewSQL的快速發展,為資料庫的資料一致性給出了與以往不同的思路: 基於分散式一致性協議!我們也實現了一個獨立的分散式協議庫X-Paxos,並將這個特性繼承到了RDS 5.7三節點企業版中。(RDS 5.7三節點在7月15日即將開始公測,敬請關注!)
一.分散式一致性協議
說到一致性協議,我們通常就會講到複製狀態機。一般情況下,我們會用複製狀態機加上一致性協議演算法來解決分散式系統中的高可用和容錯。許多分散式系統,都是採用複製狀都是採用複製狀態機來進行副本之間的資料同步,比如HDFS,Chubby和Zookeeper等。
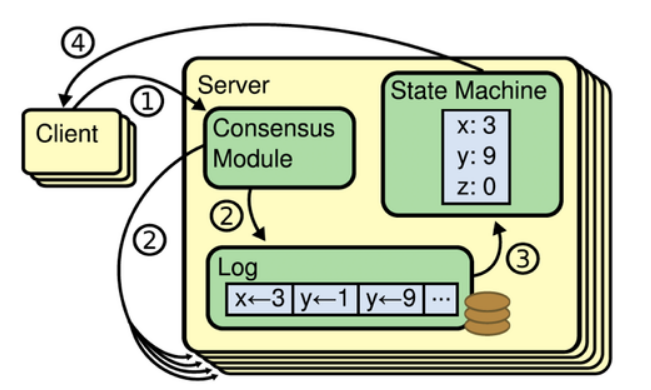
所謂複製狀態機,就是在分散式系統的每一個例項副本中,都維持一個持久化的日誌,然後用一定的一致性協議演算法,保證每個例項的這個log都保持完全一致,例項內部的狀態機按照日誌的順序回放日誌中的每一條命令,這樣客戶端來讀取資料時時,在每個副本上都能讀到一樣的資料。複製狀態機的核心就是圖中的Consensus模組,也就是我們要討論的Paxos,Raft等一致性協議演算法(準確的說,Paxos並不指代一個協議,而是一類協議的統稱,比較常見的paxos類協議有Basic-Paxos 和Multi-Paxos)
1.Basic-Paxos
Basic-Paxos是Lamport最先提出的分散式一致性演算法。要理解Paxos,只要記住一點就好了,Paxos只能為一個值形成共識,一旦Propose被確定,之後值永遠不會變,也就是說整個Paxos Group只會接受一個提案(或者說接受多個提案,但這些提案的值都一樣)。
Paxos協議中有三個角色,Proposer和Acceptor和Learner角色
Prepare階段
Proposer會給出一個ProposeID N(注意,此階段Proposer不會把值傳給Acceptor)給每個Acceptor,如果某個Acceptor發現自己從來沒有接收過大於等於N的Propose,則會回覆Proposer,同時承諾不再接收ProposeID小於等於N的提議的Prepare。如果這個Acceptor已經承諾過比N更大的propose,則不會回覆Proposer。(如果Acceptor之前已經Accept了(完成了第二個階段)一個小於N的Propose,則會把這個Propose的值返回給Proposer,否則會返回一個null值。當Proposer收到大於半數的Acceptor的回覆後,就可以開始第二階段。)
Accept階段
這個階段Propose能夠提出的值是受限的,只有它收到的回覆中不含有之前Propose的值,他才能提出一個新的value,否則只能用回覆中Propose最大的值作為提議的值。Proposer用這個值和ProposeID N對每個Acceptor發起Accept請求。也就是說就算Proposer之前已經得到過acceptor的承諾,但是在accept發起之前,Acceptor可能給了proposeID更高的Propose承諾,導致accept失敗。也就是說由於有多個Proposer的存在,雖然第一階段成功,第二階段仍然可能會被拒絕掉。
2.Multi-Paxos
前面講的Paxos還過於理論,無法直接用到複製狀態機中,總的來說,有以下幾個原因
1).Paxos只能確定一個值,無法用做Log的連續複製
2).由於有多個Proposer,可能會出現活鎖
3).提案的最終結果可能只有部分Acceptor知曉,無法達到複製狀態機每個instance 的log完全一致。 Multi-Paxos,就是為了解決上述三個問題,使Paxos協議能夠實際使用在狀態機中。解決第一個問題其實很簡單:為Log Entry每個index的值都用一個獨立的Paxos instance。解決第二個問題也很簡單,讓一個Paxos group中不要有多個Proposer,在寫入時先用Paxos協議選出一個leader(如我上面的例子),之後只由這個leader寫入,就可以避免活鎖問題。並且,有了單一的leader之後,我們還可以省略掉大部分的prepare過程。只需要在leader當選後做一次prepare,所有Acceptor都沒有接受過其他Leader的prepare請求,那每次寫入,都可以直接進行Accept,除非有Acceptor拒絕,這說明有新的leader在寫入。為了解決第三個問題,Multi-Paxos給每個Server引入了一個firstUnchosenIndex,讓leader能夠向每個Acceptor同步被選中的值。解決這些問題之後Paxos就可以用於實際工程了。
Paxos到目前已經有了很多的補充和變種,實際上,ZAB也好,Raft也好,都可以看做是對Paxos的修改和變種。關於Paxos,還有一句流傳甚廣的話,“世上只有一種一致性演算法,那就是Paxos”。
3.Raft
Raft是斯坦福大學在2014年提出的一種新的一致性協議,協議的內容,網上材料太多,不做過多闡述,這裡僅和Paxos做一下比較:
1).Raft則將Multi-Paxos的功能做了模組劃分,並對每個模組做了詳細的闡述和理論證明:Leader Election、Log Replication、Commit Index Advance、Crash Recovery、Membership Change 等。
2).Multi-Paxos和Raft,最本質的區別在於,是否允許日誌空洞。Raft必須連續,不允許空洞。Multi-Paxos允許日誌空洞存在二.X-Paxos
X-Paxos是一個從阿里業務場景出發、基於分散式一致性協議的實現(嚴格意義來說,X-Paxos的實現同時參考了經典的multi-Paxos和Raft協議),服務於RDS 5.7三節點企業版。同時X-Paxos是一個公共庫,可以應用在更多的系統。下面詳細講一下X-Paxos
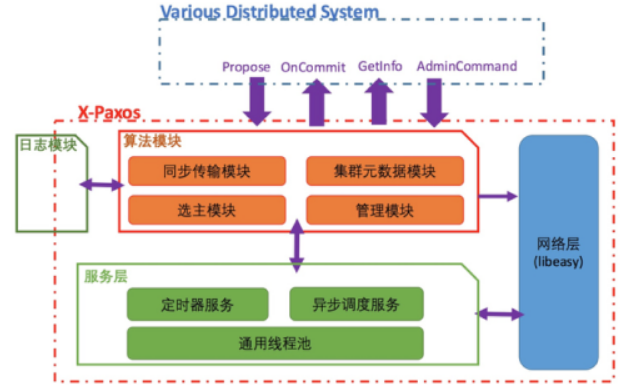
X-Paxos的整體架構如上圖所示,主要可分為網路層、服務層、演算法模組、日誌模組4個部分。
1.網路層
網路層基於阿里內部非常成熟的網路庫libeasy實現。libeasy的非同步框架和執行緒池非常契合我們的整體非同步化設計,同時我們對libeasy的重連等邏輯進行了修改,以適應分散式協議的需求。
2.服務層
服務層是驅動整個Paxos執行的基礎,為Paxos提供了事件驅動,定時回撥等核心的執行功能,每一個Paxos實現都有一個與之緊密相關的驅動層,驅動層的架構與效能和穩定性密切相關。X-Paxos的服務層是一個基於C++11特性實現的多執行緒非同步框架。常見的狀態機/回撥模型存在開發效率較低,可讀性差等問題,一直被開發者所詬病;而協程又因其單執行緒的瓶頸,而使其應用場景受到限制。C++11以後的新版本提供了完美轉發(argument forwarding)、可變模板引數(variadic templates)等特性,藉助C++11的這個特性,我們實現了一種全新的非同步呼叫模型。
3.演算法模組
X-Paxos當前的演算法基於強leadership的multi-paxos[3]實現,大量理論和實踐已經證明了強leadership的multi-paxos,效能好於multi-paxos/basic paxos,當前成熟的基於Paxos的系統,都採用了這種方式。
演算法模組的基礎功能部分本文不再重複,感興趣的同學可以參考相關論文。在基礎演算法的基礎上,結合阿里業務的場景以及高效能和生態的需求,X-Paxos做了很多的創新性的功能和效能的優化,使其相對於基礎的multi-paxos,功能變的更加豐富,效能也有明顯的提升。下一章中,將對這些優化進行詳細的介
4.日誌模組
日誌模組本是演算法模組的一部分,但是出於對極致效能要求的考慮,我們把日誌模組獨立出來,並實現了一個預設的高效能的日誌模組;有極致效能以及成本需求的使用者,可以結合已有的日誌系統,對接日誌模組介面,以獲取更高的效能和更低的成本。這也是X-Paxos作為高效能獨立庫特有的優勢,後面也會對這塊進行詳細介紹。
三. RDS 5.7三節點企業版的資料一致性解決方案
RDS 5.7三節點企業版是第一個接入X-Paxos生態的重要產品,它是一個自封閉、高可靠、強一致、高效能的資料庫系統,可以憑藉核心本身徹底解決資料質量的問題,無需外部介入。同時RDS 5.7三節點企業版也是基於MySQL生態,相容最新版本的MySQL 5.7,對於MySQL的使用者來說,可以無縫遷移到RDS 5.7三節點企業版。
1.整體架構
先來看一下RDS 5.7三節點企業版的基本架構
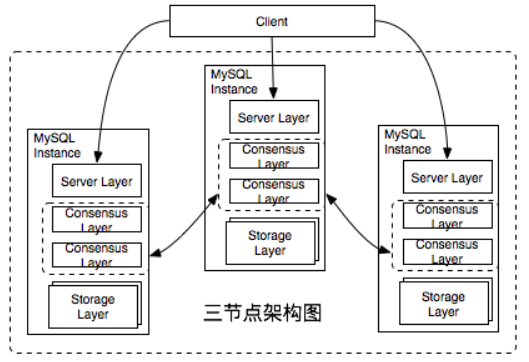
上圖展示的是一個部署三個例項的RDS 5.7三節點企業版叢集。RDS 5.7三節點企業版是一個單點寫入,多點可讀的集群系統。在同一時刻,整個叢集中至多會有一個Leader節點來承擔資料寫入的任務。相比多點寫入,單點寫入不需要處理資料集衝突的問題,可以達到更好的效能與吞吐率。
RDS 5.7三節點企業版的每個例項都是一個單程序的系統,X-Paxos被深度整合到了資料庫核心之中,替換了原有的複製模組。叢集節點之間的增量資料同步完全是通過X-Paxos來自驅動,不再需要外部手動指定複製位點。 RDS 5.7三節點企業版為了追求最高的效能,選擇了自己實現Consensus日誌這種接入X-Paxos的方式,在MySQL Binlog的基礎上實現了一系列X-Paxos日誌介面,賦予X-Paxos操縱Binlog的能力。
使用者在訪問RDS 5.7三節點企業版時可以直接使用MySQL原生的客戶端進行訪問,完美相容MySQL生態的周邊系統,包括中介軟體、備份恢復、DTS等等。
2.複製流程
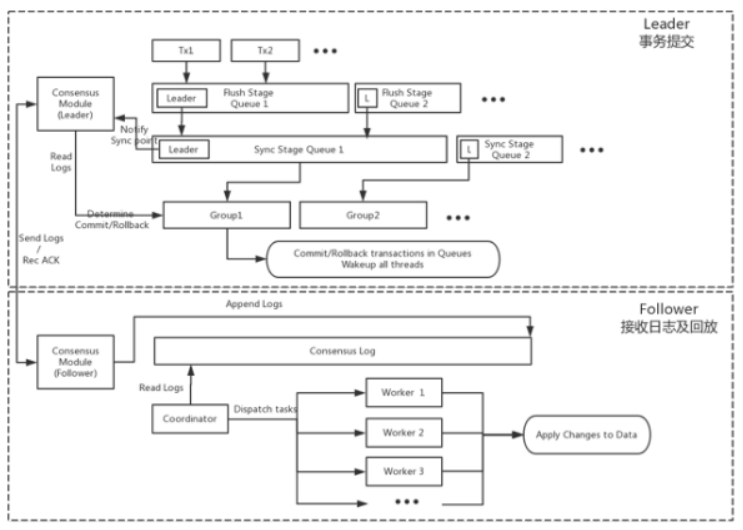
RDS 5.7三節點企業版的複製流程是基於X-Paxos驅動Consensus日誌進行復制,Leader節點在事務prepare階段會將事務產生的日誌收集起來,傳遞給X-Paxos協議層後進入等待。X-Paxos協議層會將Consensus日誌高效地轉發給叢集內其他節點,相比原生MySQL,日誌傳送採用了Batch,Pipeline等優化手段,特別是在長傳鏈路的場景中,效率提升明顯。當日志在超過叢集半數例項上落盤後 X-Paxos會通知事務可以進入提交步驟,否則通知事務回滾。
Follower節點收到Leader傳遞過來的日誌以後將日誌內容Append到Consensus Log末尾,由協調者負責讀取並解析日誌後傳遞給各個回放工作執行緒進行資料更新。由於Consensus日誌是基於Binlog開發,回放可以利用MySQL-5.7的Logic clock並行複製特性。 相比MySQL-5.6中回放並行度受到表數目限制,MySQL-5.7可以做到依賴主庫Group Commit的事務數進行併發回放,進一步提升回放的速度。
3.Failover
RDS 5.7三節點企業版只要半數以上的節點存活就能保證叢集正常對外服務。 當Leader節點故障時會觸發重新選主的流程。 選主流程由X-Paxos驅動,在Paxos協議的基礎上,結合優先順序進行新主的選舉。
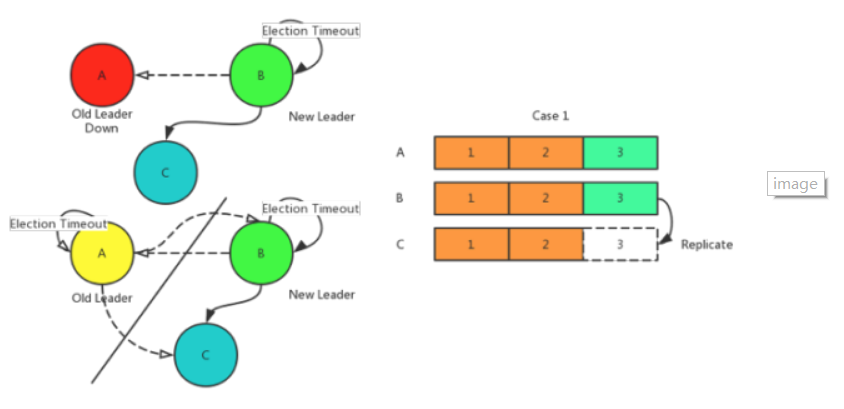
如上圖所示,左上的Case是原Leader A節點宕機,此時在選舉超時後,B節點開始嘗試選自己為Leader, 並且C節點同意, 那麼B成為新的主節點,叢集正常執行。
左下的Case 是原Leader A節點發生網路分割槽,此時在選舉超時後,BC兩個節點的行為和之間的Case類似。 A節點由於無法將心跳和日誌傳送給BC兩個節點在超時後會降級,然後不斷嘗試選自己為Leader,但是因為沒有其他節點的同意,達不成多數派,一直都不會成功。
再看日誌資料,RDS 5.7三節點企業版 承諾在failover的情況下不會丟失提交的資料。Paxos協議保證了不管叢集發生什麼樣的變故,在恢復後一定能保證日誌的一致性。那麼只要資料是按照日誌進行回放,就能保證所有節點的資料一致。如右上所示,假設A節點宕機或者分割槽前已經把3號日誌複製到了B節點,那麼在重新選舉後,B節點會嘗試將3號日誌再複製到C節點。
4.效能對比
Group Replication是MySQL 官方出品的叢集方案。它借鑑了Galera的思想,同樣支援多主多點寫入。Group Replication實現了一個X-COM的通訊層,其新版本中已經使用了Paxos演算法。目前一個GR叢集中最多可以有9個節點,響應延時相對穩定,在節點同步日誌層面, GR使用binlog,相比Galera更加的通用。
Group Replication 為了保證能夠多點寫入,會傳遞WriteSet的資訊,其他節點收到WriteSet後需要進行合法性驗證,確保正確處理衝突事務。在測試中,我們發現為了支援多點寫入而做合法性驗證是一個非常明顯的效能瓶頸點,除此之外,Group Replication還是著重解決區域網或者是同城下一致性問題,長傳鏈路下基本沒有做任何優化。我們在跨城場景下,使用官方5.7.17與RDS 5.7三節點企業版做了對比測試,GR的效能劣勢非常明顯,純寫入的效能只有RDS 5.7三節點企業版的五分之一,OLTP的效能也不足RDS 5.7三節點企業版的40%。

RDS 5.7三節點企業版是對阿里業務場景非常有效的資料庫解決方案。RDS 5.7三節點企業版不僅能夠享受到開源社群帶來的紅利,關鍵的技術也能夠做到完全的自主、可控,能夠針對業務的需求進行靈活的變更。未來 RDS 5.7三節點企業版會在此基礎上做更多的優化、例如支援多分片的Paxos, Follower提供強一致讀等功能。關於RDS 5.7三節點企業版在阿里集團內的應用,我們會在下一篇文章中詳細展開。
原文連結
本文為雲棲社群原創內容,未經