
巨杉Tech|SequoiaDB 巨杉資料庫高可用容災測試
資料庫的高可用是指最大程度地為使用者提供服務,避免伺服器宕機等故障帶來的服務中斷。資料庫的高可用性不僅僅體現在資料庫能否持續提供服務,而且也體現在能否保證資料的一致性。
SequoiaDB 巨杉資料庫作為一款100%相容 MySQL 的國產開源分散式資料庫,它在高可用方面的表現如何?它的高可用性是如何實現的?本文將詳細描述SequoiaDB巨杉資料庫的高可用性原理,並進行測試驗證。
01 巨杉分散式叢集架構
SequoiaDB 巨杉資料庫採用計算與儲存分離架構,SequoiaSQL-MySQL 是 SQL 計算層,儲存層由協調節點、編目節點和資料節點組成。
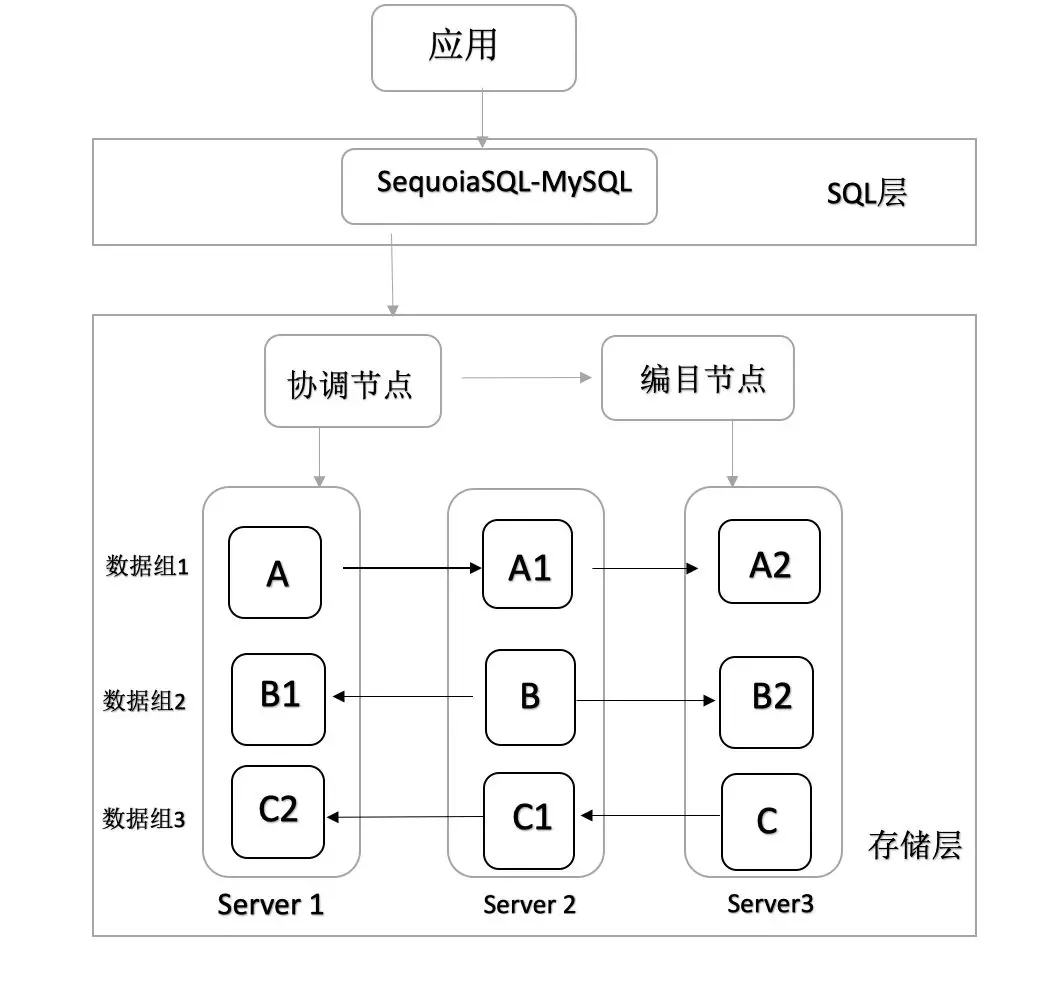
圖1 SequoiaDB分散式架構
如圖1所示是最簡單的 SequoiaDB 分散式資料庫叢集架構圖,由1個協調節點,1個編目節點,3個數據節點和 SequoiaSQL-MySQL 構成。其中資料節點在三個伺服器上,包括三個資料複製組1、2、3,每個資料複製組由3個完全相同的資料副本組成,資料副本之間通過日誌同步保持資料一致。
A, A1, A2組成資料複製組1,三者是完全相同資料副本。資料複製組2、3類似於資料複製組1。在 SequoiaDB 分散式叢集中,每個複製組最多支援 7 個數據副本。
本文的高可用測試環境採用圖1所示的分散式叢集架構,其中主節點有讀寫功能,兩個備副本可以執行讀操作或備份。
02 巨杉資料庫高可用實現
SequoiaDB 高可用採用 Raft 演算法實現,多副本之間通過日誌同步保持資料一致性。
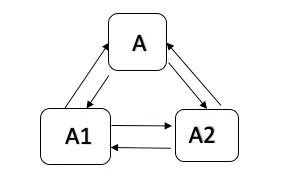
圖2 三個節點之間保持連線
如圖2所示,SequoiaDB 叢集三個副本之間通過心跳保持連線。
資料組副本之間通過共享心跳資訊 sharing-beat 進行狀態共享。如圖3所示,sharing-beat 心跳資訊結構包括心跳 ID、自身開始LSN、自身終止LSN、時間戳、資料組版本號、自身當前的角色和同步狀態。
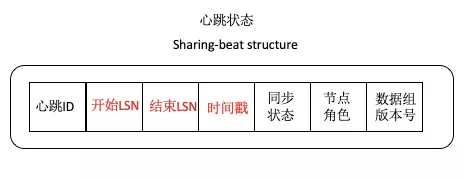
圖3 心跳狀態資訊結構
每個節點都維護一張 status-sharing table 表,用來記錄節點狀態。sharing-beat 每2秒傳送一次,採集應答資訊,若連續N秒未收到應答資訊,則認為節點宕機。
叢集中只有一個節點作為主節點,其他節點為備節點。如果出現多主或者雙主,需要根據 LSN 對比進行降備,保證叢集中只有一個主節點。
Note:
1)當主節點宕機時,需要從備節點中選舉出一個新的節點作為新的主節點。
2)當備節點宕機時,主節點不受影響,等備節點恢復後,通過日誌同步繼續與主節點保持資料一致即可。
下面介紹當主節點宕機時,選舉新主節點的過程。
選舉條件
滿足下面2個條件可以被選舉成為主節點:
1. 多數備節點投票通過
2. 該節點LSN最大
選舉過程
1)當主節點A宕機時,A自動降為備節點,關閉協調節點的業務連線。
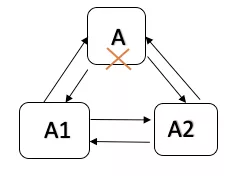
圖4 叢集中主節點掛掉
2)A1和A2都會判斷自身是否具備升為主節點的條件,若符合即發起選舉請求。
條件內容:
自己不是主節點
剩下的備節點佔半數以上
自己的LSN比其它備節點的LSN新
3)其它備節點會把被投票節點的 LSN 與自己的 LSN 做對比,若比自己的 LSN 新,則投贊成票,否則投反對票。
4)若贊成票超過(n/2+1),則支援該節點為主節點,選舉成功。否則保持備節點角色,選舉失敗。
5)選舉成功後,通過心跳狀態資訊共享資料組資訊給其它節點。
03 高可用容災驗證
一般分散式資料庫 POC 測試包含功能測試、效能測試、分散式事務測試、高可用容災測試和相容性測試等。下面將對 SequoiaDB 巨杉資料庫的高可用性進行驗證測試。
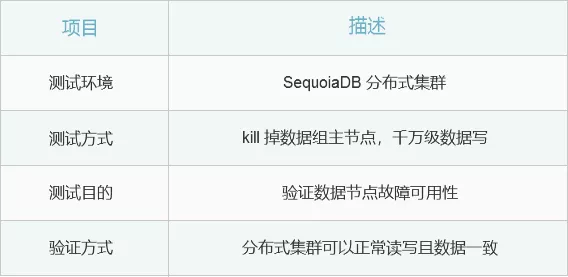
測試環境說明
本文測試環境採用分散式叢集,包含1個 SequoiaSQL-MySQL,3個數據節點,1個編目節點,1個協調節點,搭建叢集方式具體可參考巨杉官網虛擬機器映象搭建教程。在 kill 掉主節點程序之後,我們對分散式資料庫叢集進行讀寫操作,來驗證高可用性。
檢視伺服器叢集狀態
# service sdbcm status
.....
Main PID: 803 (sdbcm)
Tasks: 205 (limit: 2319)
CGroup: /system.slice/sdbcm.service
├─ 779 sdbcmd
├─ 803 sdbcm(11790)
├─1166 sequoiadb(11840) D
├─1169 sequoiadb(11810) S
├─1172 sequoiadb(11830) D
├─1175 sdbom(11780)
├─1178 sequoiadb(11820) D
├─1181 sequoiadb(11800) C
1369 /opt/sequoiadb/plugins/SequoiaSQL/bin/../../../java/jdk/bin/java -jar /opt/sequoiadb/plugins/SequoiaSQL
.....
SequoiaDB 分散式叢集中資料節點埠在11820,11830,11840;編目節點11800,協調節點在11810
sdbadmin@sequoiadb:~$ ps -ef|grep sequoiadb
sdbadmin 1166 1 0 Aug20 ? 00:02:23 sequoiadb(11840) D
sdbadmin 1169 1 0 Aug20 ? 00:01:43 sequoiadb(11810) S
sdbadmin 1172 1 0 Aug20 ? 00:02:24 sequoiadb(11830) D
sdbadmin 1178 1 0 Aug20 ? 00:02:33 sequoiadb(11820) D
sdbadmin 1181 1 0 Aug20 ? 00:04:01 sequoiadb(11800) C
kill 掉11820的主節點,執行查詢和寫入sql
sdbadmin@sequoiadb:~$ kill 1178
sdbadmin@sequoiadb:~$ ps -ef|grep sequoiadb
sdbadmin 1166 1 0 Aug20 ? 00:02:24 sequoiadb(11840) D
sdbadmin 1169 1 0 Aug20 ? 00:01:43 sequoiadb(11810) S
sdbadmin 1172 1 0 Aug20 ? 00:02:24 sequoiadb(11830) D
sdbadmin 1181 1 0 Aug20 ? 00:04:01 sequoiadb(11800) C
sdbadmin 1369 1 0 Aug20 ? 00:01:33 /opt/sequoiadb
....
執行檢視 sql,檢視插入操作之前資料為121
mysql> select * from news.user_info;
+------+-----------+
| id | unickname |
+------+-----------+
| 1 | test1 |
........
| 119 | test119 |
| 120 | test120 |
| 121 | test121 |
+------+-----------+
121 rows in set (0.01 sec)
執行寫入 sql,檢視插入是否成功
mysql> insert into news.user_info(id,unickname)values(122,"s
uccess");
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from news.user_info;
+------+-----------+
| id | unickname |
+------+-----------+
| 1 | test1 |
.........
| 120 | test120 |
| 121 | test121 |
| 122 | success |
+------+-----------+
122 rows in set (0.00 sec)
資料(122, “success”)資料插入成功,在其中一個主節點掛掉情況下,讀寫都沒有受到影響,資料讀寫保持一致,高可用性得到驗證。
現在執行匯入1000w資料寫入指令碼 imprt.sh,在執行過程中 kill 掉主資料節點,模擬主節點故障場景,在巨杉資料庫圖形化監控介面 SAC 上檢視叢集讀寫變化。
Note:
如果需要獲取 imprt.sh 指令碼,關注“巨杉資料庫”公眾號回覆 “imprt” 即可獲取。
執行匯入資料指令碼
./imprt.sh 協調節點主機 協調節點端⼝ 次數
./imprt.sh 192.168.1.122 11810 100
如圖5所示,在執行匯入資料時刻,kill 掉主資料節點,insert 寫入下降,之後叢集恢復高可用
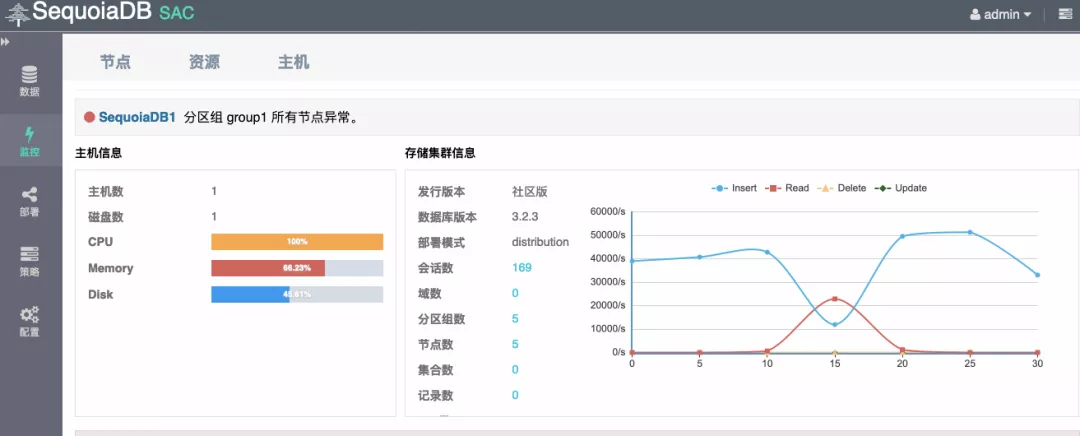
圖5 SAC監控介面叢集讀寫變化示意圖
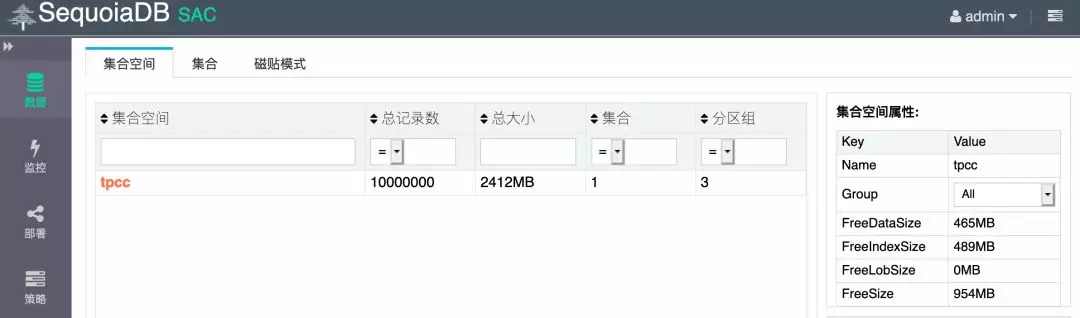
圖6 SAC檢視tpcc寫入資料量示意圖
從 SAC 視覺化介面中可以看到,當主資料節點在我們執行插入1000w資料操作的過程中出現故障,資料讀寫受到影響的持續時間很短。最後通過使用 imprt.sh 指令碼重新匯入插入失敗的資料,則可以保證資料最終一致性。
04 總結
SequoiaDB 分散式叢集具備較好的高可用性,叢集可以設定多個數據複製組,每個資料複製組由多個完全相同的副本構成,副本之間通過 Raft 演算法和日誌同步方式保持資料一致性。最後,本文也驗證了在執行千萬級資料寫操作時,若叢集主資料節點宕機,分散式叢集可以正常讀寫資料,並且資料保持最終一致,高可