
持續整合高階篇之Jekins引數傳入與常見任務
系列目錄
有的童鞋可能已經發現,PipeLine專案與自由式專案相比,可配置的項少了很多,比如說環境變數定義,所有步驟完成後執行動作,拉git程式碼庫等.其實這些功能並沒有缺,而是配置的方式不一樣了,以前是通過圖形化介面配置,雖然直觀簡便,但是功能不能包羅萬像,對於一些複雜的專案顯得捉襟見肘,而Jenkins PipeLine使用程式碼配置功能更加強大.以後的章節中我們會介紹常用的配置如何通過PipeLine裡的Groovy指令碼來實現.
前面講引數化構建的時候已經講到對於複雜的構建把一些重複的,常用的程式碼做成變數的重要性,這裡講解如何通過PipeLine方式定義專案級別的引數以及環境變數.
首先需要說明的是,節點級別和全域性級別以及檔案引數變數的配置在PipeLine裡依然有效,讀取的方式也一樣,只是會有一些小坑,這裡也會介紹
PipeLine中可以定義變數和環境變數,下面分別介紹如何定義變數和環境變更.
PipeLine中定義變數
PipeLine中定義變數非常簡單,只需要使用def 變數名=變數值的形式即可
看如下PipeLine程式碼(大家自己建立專案)
node { def hello="world" stage("echo"){ bat "echo $hello" } }
以上指令碼中我們先是定義了一個名為hello的變數,然後通過$變數名方式獲取到它,然後把它列印到控制檯.
有些童鞋對以上程式碼可能有點懵圈,bat執行的字串怎麼能包含
$變數名這樣的內容呢,bat不是隻能解析%變數名%型別的變數嗎.實際上是$變數名是groovy指令碼插值語法,執行到這行文字的時候groovy就會去嘗試解析$變數名,對於本例項,groovy會解析$hello,上面已經定義過,它的值是world,因此 groovy會把echo $hello先解析為'echo world'這樣純字串,然後再傳給bat執行.
需要注意的是以上定義的變數並非環境變數,對於bat指令碼,不能通過
%變數名%的形式被解析,因為環境變數中不存在這樣一個環境變數名,因此bat無法解析它.當然對於定義的節點級別的或者全域性的變數bat指令碼仍然可以通過%變數名%形式被解析.大家不要迷糊.
PipeLine中定義環境變數
上面定義變數的方式是定義了一個groovy變數,我們也說過它不能被傳入到指令碼內部被解析(比如bat 通過%變數名%形式解析),它必須通過groovy指令碼解析成普通字串然後傳給相應的指令碼執行程式.實際上PipeLine中也提供了一種建立環境變數的方法.這裡我們就介紹一下.
我們還是通過一段demo來講解
node {
withEnv(['build=Production',
'DB_ENGINE=sqlite']) {
stage('Build') {
bat "echo $build"
}
}
}以上通過WithEnv來定義環境變數,值放在中括號裡,大家注意寫法是"變數名=變數值",也就是變數名和賦值都放在一個引號內(單引號和雙引號都可以),而不是"變數名"="變數值"這種形式,一定要注意.
bat命令裡的解析方法是通過$變數名形式,我們講過,它是groovy的外掛方式,通過這裡我們可以看到,在PipeLine裡,環境變數也被當作了普通變數(即可以通過$變數名形式解析).當然我們說了這裡定義的是環境變數,環境變數是可以傳入指令碼內部被解析的,我們把bat這段程式碼改為如下
bat "echo %build%"控制檯仍然能夠輸出world.
對於powershell指令碼可以通過
$env:變數名方式獲取.但是對於powershell指令碼有一個坑必須注意,那就是Powershell獲取環境變數名使用$開頭,同時groovy指令碼插值變數也是以$開頭,這就會導致Groovy會嘗試解析 powershell的變數,這樣顯然無法獲取正確結果.如何解決這一問題呢?答案是執行powershell指令碼的時候使用powershell '要執行的指令碼',也即把雙引號改為單引號,如果雙引號改單引號,則groovy不再進行插值計算.
最佳實踐
1) 前面說過,groovy除了可以獲取通過def定義的變數外,也能夠獲取環境變數,因此建議使用$變數名的方式獲取變數的值,這樣groovy會提交對它們進行插值計算,這樣就彌補了不同指令碼使用環境變數方法不一樣的問題.同也不必考慮powrshell 引用變數會被插值計算,必須使用單引號包括指令碼的問題,減少腦細胞消耗量.
2) 通過以上我們可以看到PipeLine裡即可以通過def來定義變數,也可以通過WithEnv來定義,實際使用中發現WithEnv更麻煩,所有使用到它的程式碼塊都必須包含在withEnv程式碼塊內,如果巢狀過深,程式碼可讀性非常差.而def即可以宣告為全域性的(這裡說的全域性是對整個當前指令碼有效),也可以是塊級的,並且不用花括號,可讀性也更好.
常見任務在PipeLine中的處理
保證某一步驟最終一定執行
我們知道PipeLine裡可以書寫Groovy指令碼,指令碼如果出錯則程式碼將不會再繼續往下走,我們如何保證不論如何最終都會執行某一步動作呢,比如說釋放非託管資源,指令碼出錯時發出郵件通知等,這裡其實處理辦法非常簡單,那就是使用groovy的try finally語法,把最終要執行的程式碼寫在finally裡,這對程式設計師來說應該非常容易理解.
Script程式碼塊
我們前面已經說過,可以在jenkins PipeLine裡直接執行groovy指令碼,如果僅僅是定義一個變數這樣簡單的動作無所謂,如果有大量的程式碼和業務邏輯摻雜在一塊,則勢必影響程式碼可讀性.此時可以使用script程式碼塊把要執行的大段groovy指令碼包在裡面
如下圖示
node {
def hello="world"
stage("echo"){
script{
for(i=0;i<=3;i++){
println(i)
}
}
bat "echo $version"
}
}以上我們把迴圈語句放在程式碼塊裡,println可以把內容列印到Jenkins控制檯.
邏輯分支
這裡僅僅是列出來希望引起大家的注意,在指令碼式PipeLine裡邏輯分支非常簡單,只需要使用if分支語句即可,熟悉groovy指令碼的童鞋可以盡情發揮所掌握知識
並行任務
在PipeLine裡可以執行並行任務,充分利用並行任務在特定場景下將極大節約構建時間,提升構建效率.比如說我們的專案是一個模組非常多的專案,每個模組存在不同的倉庫裡,則我們在拉取專案進行編譯的時候可以並行拉取這個庫,把這些並行任務放在一個步驟裡,完成後再執行下一步編譯工作.
請看下面示例程式碼
node{
stage("poll source"){
parallel(
a: {
echo "This is branch a"
},
b: {
echo "This is branch b"
}
)
}
stage("build"){
echo "build successfully"
}
}以上程式碼在poll source步驟裡,我們通過parallel並行執行了a和b兩個任務.這樣將極大節約程式碼拉取時間.
我們儲存專案後點擊構建,構建完成後開啟BlueOcean檢視,點選進入本次構建,就會看到如下圖
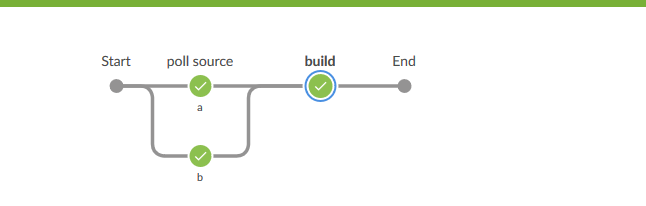
可以從圖形介面形象地看到poll source步驟分為a和b兩個並行的任務.然後它們彙集到下一步.
使用並行任務時一定要梳理好構建的邏輯,否則將會出現意想不到的結果.如果以上
a b 和build並行執行,則將會導致構建失敗,因為構建依賴於以上兩個步驟都執行完成.