
跨庫資料遷移利器 —— Sqoop
一、Sqoop 基本命令
1. 檢視所有命令
# sqoop help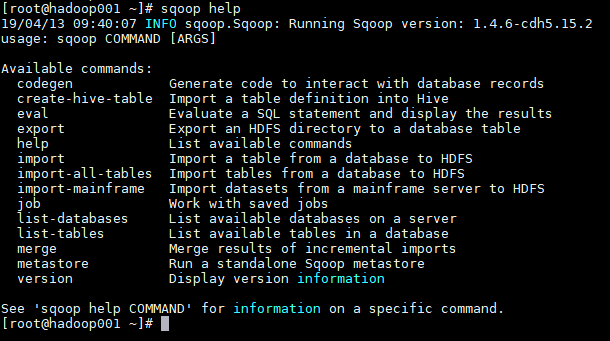
2. 檢視某條命令的具體使用方法
# sqoop help 命令名二、Sqoop 與 MySQL
1. 查詢MySQL所有資料庫
通常用於 Sqoop 與 MySQL 連通測試:
sqoop list-databases \
--connect jdbc:mysql://hadoop001:3306/ \
--username root \
--password root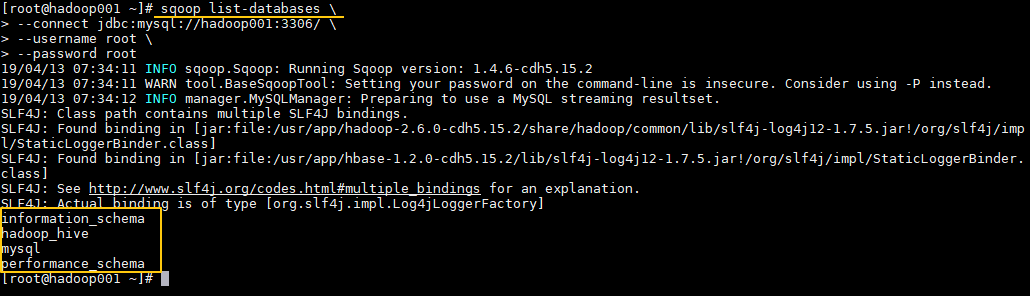
2. 查詢指定資料庫中所有資料表
sqoop list-tables \ --connect jdbc:mysql://hadoop001:3306/mysql \ --username root \ --password root
三、Sqoop 與 HDFS
3.1 MySQL資料匯入到HDFS
1. 匯入命令
示例:匯出 MySQL 資料庫中的 help_keyword 表到 HDFS 的 /sqoop 目錄下,如果匯入目錄存在則先刪除再匯入,使用 3 個 map tasks 並行匯入。
注:help_keyword 是 MySQL 內建的一張字典表,之後的示例均使用這張表。
sqoop import \ --connect jdbc:mysql://hadoop001:3306/mysql \ --username root \ --password root \ --table help_keyword \ # 待匯入的表 --delete-target-dir \ # 目標目錄存在則先刪除 --target-dir /sqoop \ # 匯入的目標目錄 --fields-terminated-by '\t' \ # 指定匯出資料的分隔符 -m 3 # 指定並行執行的 map tasks 數量
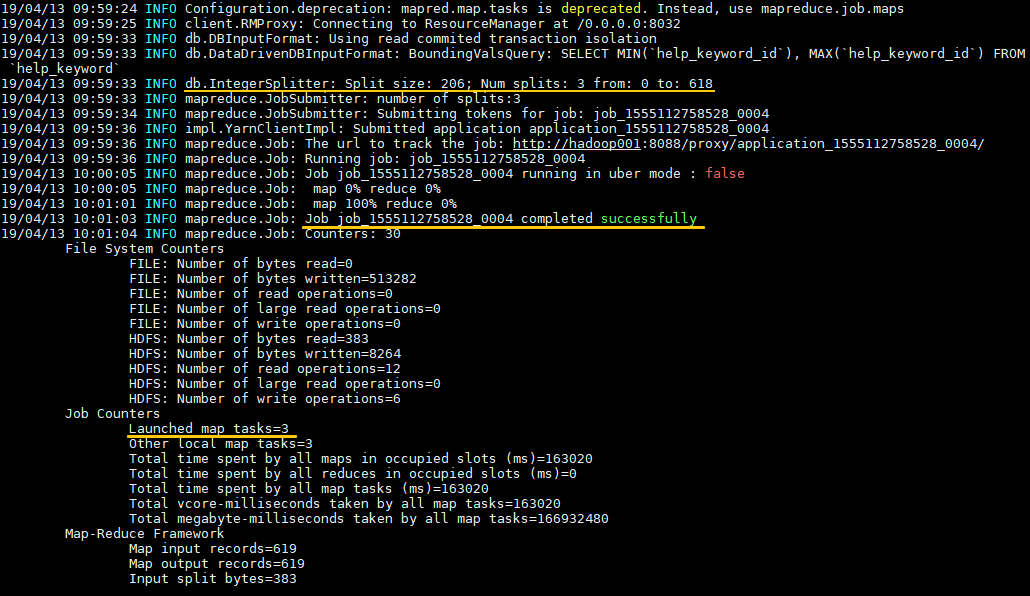
日誌輸出如下,可以看到輸入資料被平均 split 為三份,分別由三個 map task 進行處理。資料預設以表的主鍵列作為拆分依據,如果你的表沒有主鍵,有以下兩種方案:
- 新增
-- autoreset-to-one-mapper引數,代表只啟動一個map task,即不併行執行; - 若仍希望並行執行,則可以使用
--split-by <column-name>指明拆分資料的參考列。
2. 匯入驗證
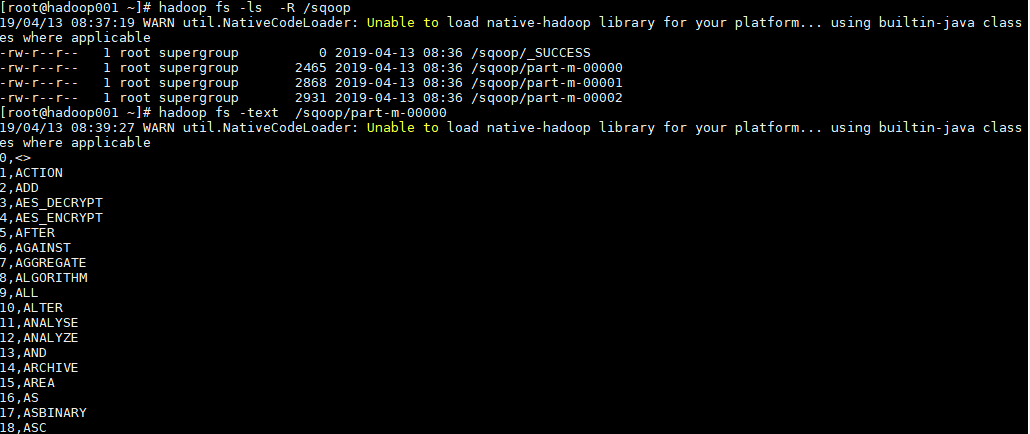
# 檢視匯入後的目錄
hadoop fs -ls -R /sqoop
# 檢視匯入內容
hadoop fs -text /sqoop/part-m-00000檢視 HDFS 匯入目錄,可以看到表中資料被分為 3 部分進行儲存,這是由指定的並行度決定的。
3.2 HDFS資料匯出到MySQL
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hdfs \ # 匯出資料儲存在 MySQL 的 help_keyword_from_hdf 的表中
--export-dir /sqoop \
--input-fields-terminated-by '\t'\
--m 3 表必須預先建立,建表語句如下:
CREATE TABLE help_keyword_from_hdfs LIKE help_keyword ;四、Sqoop 與 Hive
4.1 MySQL資料匯入到Hive
Sqoop 匯入資料到 Hive 是通過先將資料匯入到 HDFS 上的臨時目錄,然後再將資料從 HDFS 上 Load 到 Hive 中,最後將臨時目錄刪除。可以使用 target-dir 來指定臨時目錄。
1. 匯入命令
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待匯入的表
--delete-target-dir \ # 如果臨時目錄存在刪除
--target-dir /sqoop_hive \ # 臨時目錄位置
--hive-database sqoop_test \ # 匯入到 Hive 的 sqoop_test 資料庫,資料庫需要預先建立。不指定則預設為 default 庫
--hive-import \ # 匯入到 Hive
--hive-overwrite \ # 如果 Hive 表中有資料則覆蓋,這會清除表中原有的資料,然後再寫入
-m 3 # 並行度匯入到 Hive 中的 sqoop_test 資料庫需要預先建立,不指定則預設使用 Hive 中的 default 庫。
# 檢視 hive 中的所有資料庫
hive> SHOW DATABASES;
# 建立 sqoop_test 資料庫
hive> CREATE DATABASE sqoop_test;2. 匯入驗證
# 檢視 sqoop_test 資料庫的所有表
hive> SHOW TABLES IN sqoop_test;
# 查看錶中資料
hive> SELECT * FROM sqoop_test.help_keyword;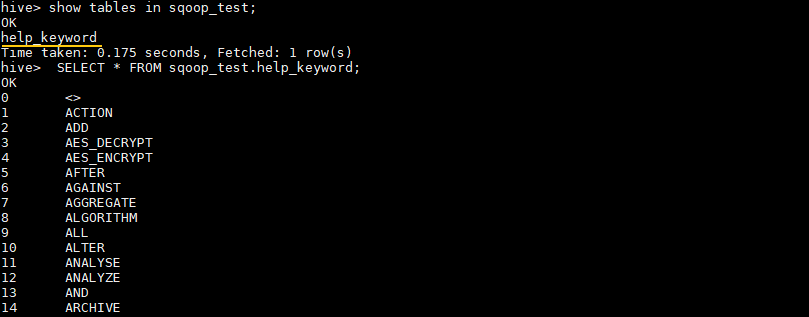
3. 可能出現的問題
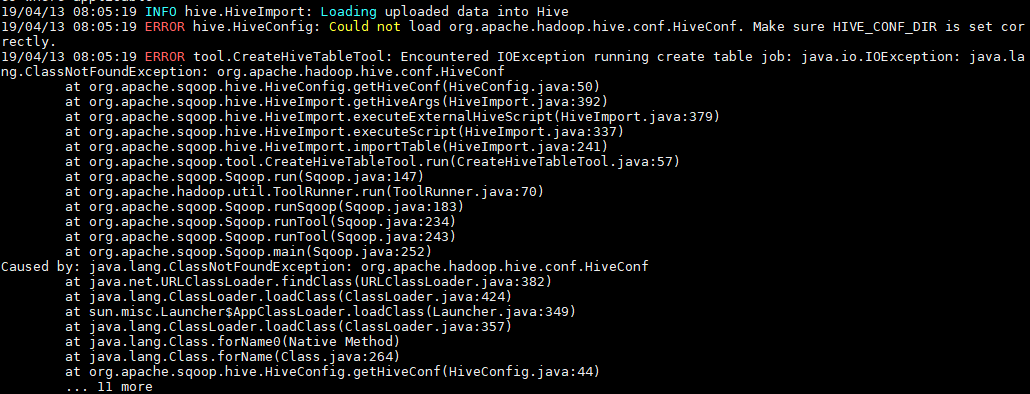
如果執行報錯 java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf,則需將 Hive 安裝目錄下 lib 下的 hive-exec-**.jar 放到 sqoop 的 lib 。
[root@hadoop001 lib]# ll hive-exec-*
-rw-r--r--. 1 1106 4001 19632031 11 月 13 21:45 hive-exec-1.1.0-cdh5.15.2.jar
[root@hadoop001 lib]# cp hive-exec-1.1.0-cdh5.15.2.jar ${SQOOP_HOME}/lib4.2 Hive 匯出資料到MySQL
由於 Hive 的資料是儲存在 HDFS 上的,所以 Hive 匯入資料到 MySQL,實際上就是 HDFS 匯入資料到 MySQL。
1. 檢視Hive表在HDFS的儲存位置
# 進入對應的資料庫
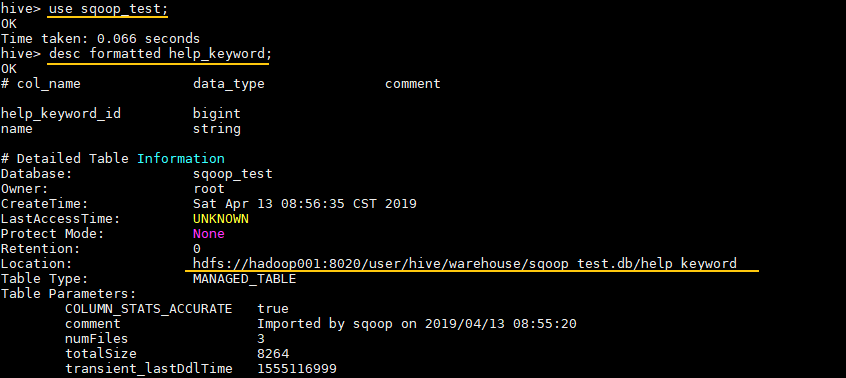
hive> use sqoop_test;
# 查看錶資訊
hive> desc formatted help_keyword;Location 屬性為其儲存位置:
這裡可以檢視一下這個目錄,檔案結構如下:

3.2 執行匯出命令
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hive \
--export-dir /user/hive/warehouse/sqoop_test.db/help_keyword \
-input-fields-terminated-by '\001' \ # 需要注意的是 hive 中預設的分隔符為 \001
--m 3 MySQL 中的表需要預先建立:
CREATE TABLE help_keyword_from_hive LIKE help_keyword ;五、Sqoop 與 HBase
本小節只講解從 RDBMS 匯入資料到 HBase,因為暫時沒有命令能夠從 HBase 直接匯出資料到 RDBMS。
5.1 MySQL匯入資料到HBase
1. 匯入資料
將 help_keyword 表中資料匯入到 HBase 上的 help_keyword_hbase 表中,使用原表的主鍵 help_keyword_id 作為 RowKey,原表的所有列都會在 keywordInfo 列族下,目前只支援全部匯入到一個列族下,不支援分別指定列族。
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待匯入的表
--hbase-table help_keyword_hbase \ # hbase 表名稱,表需要預先建立
--column-family keywordInfo \ # 所有列匯入到 keywordInfo 列族下
--hbase-row-key help_keyword_id # 使用原表的 help_keyword_id 作為 RowKey匯入的 HBase 表需要預先建立:
# 檢視所有表
hbase> list
# 建立表
hbase> create 'help_keyword_hbase', 'keywordInfo'
# 查看錶資訊
hbase> desc 'help_keyword_hbase'2. 匯入驗證
使用 scan 查看錶資料:

六、全庫匯出
Sqoop 支援通過 import-all-tables 命令進行全庫匯出到 HDFS/Hive,但需要注意有以下兩個限制:
- 所有表必須有主鍵;或者使用
--autoreset-to-one-mapper,代表只啟動一個map task; - 你不能使用非預設的分割列,也不能通過 WHERE 子句新增任何限制。
第二點解釋得比較拗口,這裡列出官方原本的說明:
- You must not intend to use non-default splitting column, nor impose any conditions via a
WHEREclause.
全庫匯出到 HDFS:
sqoop import-all-tables \
--connect jdbc:mysql://hadoop001:3306/資料庫名 \
--username root \
--password root \
--warehouse-dir /sqoop_all \ # 每個表會單獨匯出到一個目錄,需要用此引數指明所有目錄的父目錄
--fields-terminated-by '\t' \
-m 3全庫匯出到 Hive:
sqoop import-all-tables -Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect jdbc:mysql://hadoop001:3306/資料庫名 \
--username root \
--password root \
--hive-database sqoop_test \ # 匯出到 Hive 對應的庫
--hive-import \
--hive-overwrite \
-m 3七、Sqoop 資料過濾
7.1 query引數
Sqoop 支援使用 query 引數定義查詢 SQL,從而可以匯出任何想要的結果集。使用示例如下:
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--query 'select * from help_keyword where $CONDITIONS and help_keyword_id < 50' \
--delete-target-dir \
--target-dir /sqoop_hive \
--hive-database sqoop_test \ # 指定匯入目標資料庫 不指定則預設使用 Hive 中的 default 庫
--hive-table filter_help_keyword \ # 指定匯入目標表
--split-by help_keyword_id \ # 指定用於 split 的列
--hive-import \ # 匯入到 Hive
--hive-overwrite \ 、
-m 3 在使用 query 進行資料過濾時,需要注意以下三點:
- 必須用
--hive-table指明目標表; - 如果並行度
-m不為 1 或者沒有指定--autoreset-to-one-mapper,則需要用--split-by指明參考列; - SQL 的
where字句必須包含$CONDITIONS,這是固定寫法,作用是動態替換。
7.2 增量匯入
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \
--target-dir /sqoop_hive \
--hive-database sqoop_test \
--incremental append \ # 指明模式
--check-column help_keyword_id \ # 指明用於增量匯入的參考列
--last-value 300 \ # 指定參考列上次匯入的最大值
--hive-import \
-m 3 incremental 引數有以下兩個可選的選項:
- append:要求參考列的值必須是遞增的,所有大於
last-value的值都會被匯入; - lastmodified:要求參考列的值必須是
timestamp型別,且插入資料時候要在參考列插入當前時間戳,更新資料時也要更新參考列的時間戳,所有時間晚於last-value的資料都會被匯入。
通過上面的解釋我們可以看出來,其實 Sqoop 的增量匯入並沒有太多神器的地方,就是依靠維護的參考列來判斷哪些是增量資料。當然我們也可以使用上面介紹的 query 引數來進行手動的增量匯出,這樣反而更加靈活。
八、型別支援
Sqoop 預設支援資料庫的大多數字段型別,但是某些特殊型別是不支援的。遇到不支援的型別,程式會丟擲異常 Hive does not support the SQL type for column xxx 異常,此時可以通過下面兩個引數進行強制型別轉換:
- --map-column-java<mapping> :重寫 SQL 到 Java 型別的對映;
- --map-column-hive <mapping> : 重寫 Hive 到 Java 型別的對映。
示例如下,將原先 id 欄位強制轉為 String 型別,value 欄位強制轉為 Integer 型別:
$ sqoop import ... --map-column-java id=String,value=Integer參考資料
Sqoop User Guide (v1.4.7)
更多大資料系列文章可以參見 GitHub 開源專案: 大資料入門指南