
sharding-jdbc之ANTLR4 SQL解析
Sharding主要利用ANTLR4來解析SQL,以mysql為例,分析原始碼前可以先了解以下三點:
- antlr4,如何編寫
.g4語法檔案 - mysql 語法可以參考https://dev.mysql.com/doc/refman/8.0/en/sql-syntax-data-manipulation.html
- mysql g4檔案編寫可以參考https://github.com/antlr/grammars-v4/blob/master/mysql
原始碼分析
1.解析入口ParsingSQLRouter#parse
/** * 解析sql * * @param logicSQL 邏輯sql * @param useCache 是否快取解析後的結果 * @return */ @Override public SQLStatement parse(final String logicSQL, final boolean useCache) { //解析前鉤子,如:呼叫鏈etx parsingHook.start(logicSQL); try { //解析SQL SQLStatement result = new ShardingSQLParseEntry(databaseType, shardingMetaData.getTable(), parsingResultCache).parse(logicSQL, useCache); //解析成功後鉤子 parsingHook.finishSuccess(result, shardingMetaData.getTable()); return result; // CHECKSTYLE:OFF } catch (final Exception ex) { // CHECKSTYLE:ON //解析失敗鉤子 parsingHook.finishFailure(ex); throw ex; } }
public final class ShardingSQLParseEntry extends SQLParseEntry { private final DatabaseType databaseType; private final ShardingTableMetaData shardingTableMetaData; public ShardingSQLParseEntry(final DatabaseType databaseType, final ShardingTableMetaData shardingTableMetaData, final ParsingResultCache parsingResultCache) { super(parsingResultCache); this.databaseType = databaseType; this.shardingTableMetaData = shardingTableMetaData; } /** * 根據sql獲取解析引擎封裝物件 */ @Override protected SQLParseEngine getSQLParseEngine(final String sql) { //引數1:單例,載入statement、提取、過濾配置檔案 //引數2:資料庫型別 //引數3:需要解析sql //引數4:分片表元資料 return new SQLParseEngine(ShardingParseRuleRegistry.getInstance(), databaseType, sql, shardingTableMetaData); } }
2.ShardingParseRuleRegistry.getInstance()->ParseRuleRegistry#initParseRuleDefinition載入statement、提取、過濾配置檔案
private void initParseRuleDefinition() { //利用JAXB載入META-INF/parsing-rule-definition/extractor-rule-definition.xml配置檔案 ExtractorRuleDefinitionEntity generalExtractorRuleEntity = extractorRuleLoader.load(RuleDefinitionFileConstant.getExtractorRuleDefinitionFile()); //利用JAXB載入下META-INF/parsing-rule-definition/filler-rule-definition.xml配置檔案 FillerRuleDefinitionEntity generalFillerRuleEntity = fillerRuleLoader.load(RuleDefinitionFileConstant.getFillerRuleDefinitionFile()); //加對應型別(sharding、masterslave、encrypt)配置檔案 //META-INF/parsing-rule-definition/sharding/filler-rule-definition.xml FillerRuleDefinitionEntity featureGeneralFillerRuleEntity = fillerRuleLoader.load(RuleDefinitionFileConstant.getFillerRuleDefinitionFile(getType())); //根據資料庫型別載入對應的配置檔案 for (DatabaseType each : SQLParserFactory.getAddOnDatabaseTypes()) { //META-INF/parsing-rule-definition/sharding.mysql/filler-rule-definition.xml //databaseType:rules<segment,filler> fillerRuleDefinitions.put(each, createFillerRuleDefinition(generalFillerRuleEntity, featureGeneralFillerRuleEntity, each)); //META-INF/parsing-rule-definition/sharding.mysql/extractor-rule-definition.xml //META-INF/parsing-rule-definition/sharding.mysql/sql-statement-rule-definition.xml //databaseType:rules<xxxContext,SQLStatementRule> sqlStatementRuleDefinitions.put(each, createSQLStatementRuleDefinition(generalExtractorRuleEntity, each)); } } private FillerRuleDefinition createFillerRuleDefinition(final FillerRuleDefinitionEntity generalFillerRuleEntity, final FillerRuleDefinitionEntity featureGeneralFillerRuleEntity, final DatabaseType databaseType) { return new FillerRuleDefinition( generalFillerRuleEntity, featureGeneralFillerRuleEntity, fillerRuleLoader.load(RuleDefinitionFileConstant.getFillerRuleDefinitionFile(getType(), databaseType))); } private SQLStatementRuleDefinition createSQLStatementRuleDefinition(final ExtractorRuleDefinitionEntity generalExtractorRuleEntity, final DatabaseType databaseType) { //將所有提取器封裝到一起 //id:extractor ExtractorRuleDefinition extractorRuleDefinition = new ExtractorRuleDefinition( generalExtractorRuleEntity, extractorRuleLoader.load(RuleDefinitionFileConstant.getExtractorRuleDefinitionFile(getType(), databaseType))); //sql-statement-rule-definition.xml //Context:SQLStatementRule //SQLStatementRule封裝statement對應的提取器 return new SQLStatementRuleDefinition(statementRuleLoader.load(RuleDefinitionFileConstant.getSQLStatementRuleDefinitionFile(getType(), databaseType)), extractorRuleDefinition); }
3.SQLParseEntry#parse,這裡抽象SQLParseEntry,主要有不同入口(EncryptSQLParseEntry、MasterSlaveSQLParseEntry、ShardingSQLParseEntry)
@RequiredArgsConstructor
public abstract class SQLParseEntry {
private final ParsingResultCache parsingResultCache;
/**
* Parse SQL.
*
* @param sql SQL
* @param useCache use cache or not
* @return SQL statement
*/
public final SQLStatement parse(final String sql, final boolean useCache) {
//從快取中獲取解析後的SQLStatement
Optional<SQLStatement> cachedSQLStatement = getSQLStatementFromCache(sql, useCache);
if (cachedSQLStatement.isPresent()) {
return cachedSQLStatement.get();
}
//解析
SQLStatement result = getSQLParseEngine(sql).parse();
//cache
if (useCache) {
parsingResultCache.put(sql, result);
}
return result;
}
private Optional<SQLStatement> getSQLStatementFromCache(final String sql, final boolean useCache) {
return useCache ? Optional.fromNullable(parsingResultCache.getSQLStatement(sql)) : Optional.<SQLStatement>absent();
}
//根據子類ShardingSQLParseEntry的getSQLParseEngine獲取SQLParseEngine
protected abstract SQLParseEngine getSQLParseEngine(String sql);
}
4.SQLParseEngine#parse,包含解析、提取、填充SQLStatement
public SQLParseEngine(final ParseRuleRegistry parseRuleRegistry, final DatabaseType databaseType, final String sql, final ShardingTableMetaData shardingTableMetaData) {
DatabaseType trunkDatabaseType = DatabaseTypes.getTrunkDatabaseType(databaseType.getName());
//sql解析引擎
parserEngine = new SQLParserEngine(parseRuleRegistry, trunkDatabaseType, sql);
//sql提取引擎
extractorEngine = new SQLSegmentsExtractorEngine();
//sql填充引擎
fillerEngine = new SQLStatementFillerEngine(parseRuleRegistry, trunkDatabaseType, sql, shardingTableMetaData);
}
/**
* Parse SQL.
*
* @return SQL statement
*/
public SQLStatement parse() {
//利用ANTLR4 解析sql
SQLAST ast = parserEngine.parse();
//提取ast中的token,封裝成對應的segment,如TableSegment、IndexSegment
Collection<SQLSegment> sqlSegments = extractorEngine.extract(ast);
Map<ParserRuleContext, Integer> parameterMarkerIndexes = ast.getParameterMarkerIndexes();
//填充SQLStatement
return fillerEngine.fill(sqlSegments, parameterMarkerIndexes.size(), ast.getSqlStatementRule());
}
5.SQLParserEngine#parse,解析SQL,封裝AST(Abstract Syntax Tree 抽象語法樹)
public SQLAST parse() {
//SPI 利用ANTLR4解析獲取SQLParser(MySQLParserEntry)執行,獲取解析樹
ParseTree parseTree = SQLParserFactory.newInstance(databaseType, sql).execute().getChild(0);
if (parseTree instanceof ErrorNode) {
throw new SQLParsingException(String.format("Unsupported SQL of `%s`", sql));
}
//獲取配置檔案中的StatementContext,比如CreateTableContext、SelectContext
SQLStatementRule sqlStatementRule = parseRuleRegistry.getSQLStatementRule(databaseType, parseTree.getClass().getSimpleName());
if (null == sqlStatementRule) {
throw new SQLParsingException(String.format("Unsupported SQL of `%s`", sql));
}
//封裝ast(Abstract Syntax Tree 抽象語法樹)
return new SQLAST((ParserRuleContext) parseTree, getParameterMarkerIndexes((ParserRuleContext) parseTree), sqlStatementRule);
}
/**
* 遞迴獲取所有引數佔位符
*
* @param rootNode 根節點
* @return
*/
private Map<ParserRuleContext, Integer> getParameterMarkerIndexes(final ParserRuleContext rootNode) {
Collection<ParserRuleContext> placeholderNodes = ExtractorUtils.getAllDescendantNodes(rootNode, RuleName.PARAMETER_MARKER);
Map<ParserRuleContext, Integer> result = new HashMap<>(placeholderNodes.size(), 1);
int index = 0;
for (ParserRuleContext each : placeholderNodes) {
result.put(each, index++);
}
return result;
}
6.使用SQLParserFactory#newInstance建立SQLParser
/**
* New instance of SQL parser.
*
* @param databaseType database type
* @param sql SQL
* @return SQL parser
*/
public static SQLParser newInstance(final DatabaseType databaseType, final String sql) {
//SPI load所有擴充套件
for (SQLParserEntry each : NewInstanceServiceLoader.newServiceInstances(SQLParserEntry.class)) {
//判斷資料庫型別
if (DatabaseTypes.getActualDatabaseType(each.getDatabaseType()) == databaseType) {
//解析sql
return createSQLParser(sql, each);
}
}
throw new UnsupportedOperationException(String.format("Cannot support database type '%s'", databaseType));
}
@SneakyThrows
private static SQLParser createSQLParser(final String sql, final SQLParserEntry parserEntry) {
//詞法分析器
Lexer lexer = parserEntry.getLexerClass().getConstructor(CharStream.class).newInstance(CharStreams.fromString(sql));
//語法分析器
return parserEntry.getParserClass().getConstructor(TokenStream.class).newInstance(new CommonTokenStream(lexer));
}
7.以select為例,分析第四步的SQL解析、提取、填充過程
利用idea的antlr4外掛,使用Sharding的mysql .g4 檔案解析SQL;如圖:
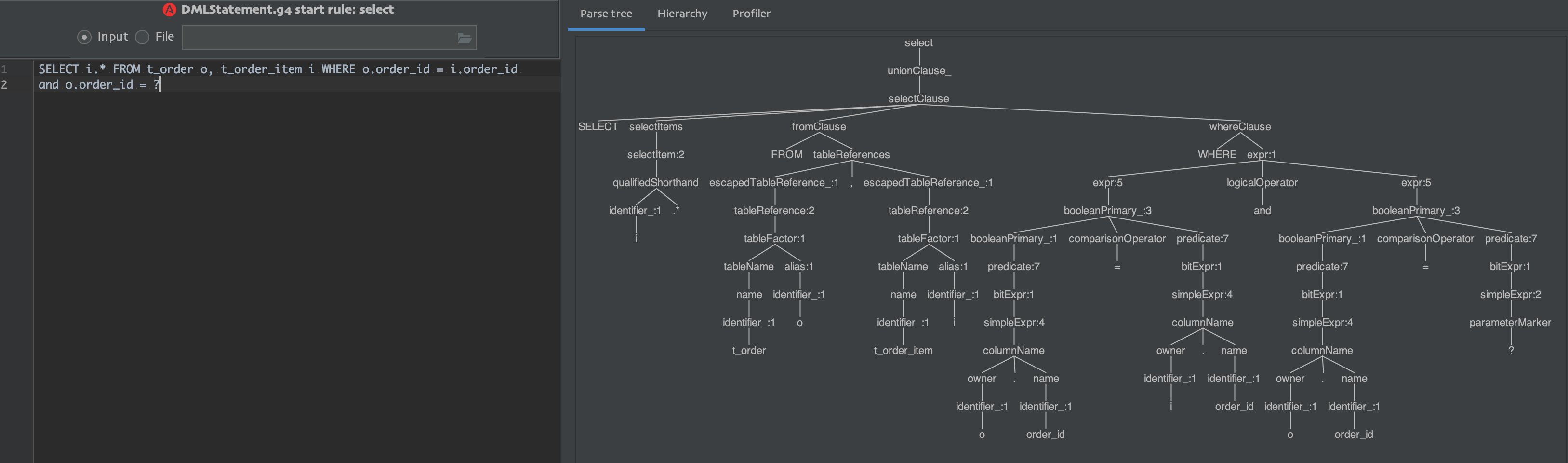
參考上圖,使用sharding parse解析模組提取(extractor) ParserRuleContext對應的引數封裝成Segment
8.SQLSegmentsExtractorEngine#extract,參考第七部圖,根據SQLStatementRule->tableReferences, columns, selectItems, where, predicate, groupBy, orderBy, limit, subqueryPredicate對應的提取器,生成對應型別的Segment
public final class SQLSegmentsExtractorEngine {
/**
* Extract SQL segments.
*
* @param ast SQL AST
* @return SQL segments
*/
public Collection<SQLSegment> extract(final SQLAST ast) {
Collection<SQLSegment> result = new LinkedList<>();
//遍歷Context對應提取器,封裝成對應對應型別的Segment,比如TableSegment、IndexSegment
//以SELECT i.* FROM t_order o, t_order_item i WHERE o.order_id = i.order_id and o.order_id = ?為例
//SelectContext->SQLStatementRule
//SQLStatementRule->tableReferences, columns, selectItems, where, predicate, groupBy, orderBy, limit, subqueryPredicate
//分析九個提取器
for (SQLSegmentExtractor each : ast.getSqlStatementRule().getExtractors()) {
//分兩種型別
//1.單一樹,直接提取單一RuleName下的token;參看sql解析後的語法樹對比比較清晰
if (each instanceof OptionalSQLSegmentExtractor) {
Optional<? extends SQLSegment> sqlSegment = ((OptionalSQLSegmentExtractor) each).extract(ast.getParserRuleContext(), ast.getParameterMarkerIndexes());
if (sqlSegment.isPresent()) {
result.add(sqlSegment.get());
}
//2.分叉樹,需遍歷提取RuleName下的所有Token;參看sql解析後的語法樹對比比較清晰
} else if (each instanceof CollectionSQLSegmentExtractor) {
result.addAll(((CollectionSQLSegmentExtractor) each).extract(ast.getParserRuleContext(), ast.getParameterMarkerIndexes()));
}
}
return result;
}
}
9.SQLStatementFillerEngine#fill,封裝SQLStatement,填充Segment
@RequiredArgsConstructor
public final class SQLStatementFillerEngine {
private final ParseRuleRegistry parseRuleRegistry;
private final DatabaseType databaseType;
private final String sql;
private final ShardingTableMetaData shardingTableMetaData;
/**
* Fill SQL statement.
*
* @param sqlSegments SQL segments
* @param parameterMarkerCount parameter marker count
* @param rule SQL statement rule
* @return SQL statement
*/
@SneakyThrows
public SQLStatement fill(final Collection<SQLSegment> sqlSegments, final int parameterMarkerCount, final SQLStatementRule rule) {
//如SelectStatement
SQLStatement result = rule.getSqlStatementClass().newInstance();
//邏輯sql
result.setLogicSQL(sql);
//引數個數
result.setParametersCount(parameterMarkerCount);
//segment
result.getSQLSegments().addAll(sqlSegments);
//遍歷填充對應型別的Segment
for (SQLSegment each : sqlSegments) {
//根據資料庫型別、segment找到對應填充器,來填充對應的segment
//如:TableSegment->TableFiller
Optional<SQLSegmentFiller> filler = parseRuleRegistry.findSQLSegmentFiller(databaseType, each.getClass());
if (filler.isPresent()) {
doFill(each, result, filler.get());
}
}
return result;
}
@SuppressWarnings("unchecked")
private void doFill(final SQLSegment sqlSegment, final SQLStatement sqlStatement, final SQLSegmentFiller filler) {
//新增欄位、欄位約束、修改欄位、欄位命令,這四種填充器需要設定分片表元資料
//主要通過分片表元資料來填充對應的SQLStatement
if (filler instanceof ShardingTableMetaDataAware) {
((ShardingTableMetaDataAware) filler).setShardingTableMetaData(shardingTableMetaData);
}
//如:
//利用TableFill來填充SelectStatement#tables
filler.fill(sqlSegment, sqlStatement);
}
}
以上Sharding的SQL解析大概過程,解析ParserRuleContext提取封裝對應的Segment,最後封裝SQLStatement,並根據Segment對應的Filler來填充SQLStatement;具體如何提取、填充可以檢視以下三個檔案
extractor-rule-definition.xml
filler-rule-definition.xml
sql-statement-rule-definition.xml