
zookeeper學習之原理
一、zookeeper 是什麼
Zookeeper是一個分散式協調服務,可用於服務發現,分散式鎖,分散式領導選舉,配置管理等。這一切的基礎,都是Zookeeper提供了一個類似於Linux檔案系統的樹形結構(可認為是輕量級的記憶體檔案系統,但只適合存少量資訊,完全不適合儲存大量檔案或者大檔案),同時提供了對於每個節點的監控與通知機制。既然是一個檔案系統,就不得不提Zookeeper是如何保證資料的一致性的。
二、zookeeper 叢集架構
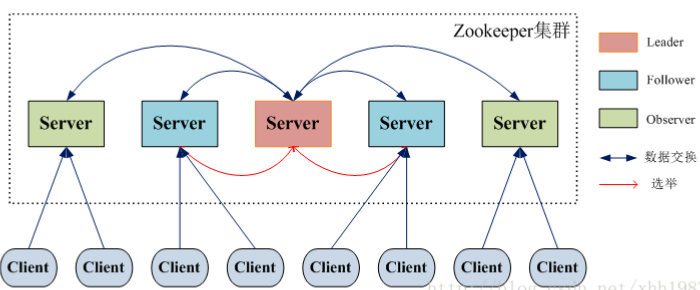
Zookeeper叢集是一個基於主從複製的高可用叢集,通常 Master伺服器作為主伺服器提供寫服務,其他的 Slave 伺服器通過非同步複製的方式獲取 Master 伺服器最新的資料,並提供讀服務,在 ZooKeeper 中沒有選擇傳統的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三種角色,每個角色承擔如下:
- Leader 一個Zookeeper叢集同一時間只會有一個實際工作的Leader,它會發起並維護與各Follwer及Observer間的心跳。所有的寫操作必須要通過Leader完成再由Leader將寫操作廣播給其它伺服器。
- Follower 一個Zookeeper叢集可能同時存在多個Follower,它會響應Leader的心跳。Follower可直接處理並返回客戶端的讀請求,同時會將寫請求轉發給Leader處理,並且負責在Leader處理寫請求時,對請求進行投票(“過半寫成功”策略)。
- Observer 角色與Follower類似,但是無投票權。
在叢集中zookeeper是如何保證master與slave資料一致性?
為了保證寫操作的一致性與可用性,Zookeeper專門設計了一種名為原子廣播(ZAB)的支援崩潰恢復的一致性協議。基於該協議,Zookeeper實現了一種主從模式的系統架構來保持叢集中各個副本之間的資料一致性。
寫資料時保證一致性:Zookeeper 客戶端會隨機連線到 Zookeeper 叢集的一個節點,如果是讀請求,就直接從當前節點中讀取資料;如果是寫請求且當前節點不是leader,那麼節點就會向 leader 提交事務,leader 會廣播事務,只要有超過半數節點寫入成功,該寫請求就會被提交(類 2PC 協議)。
伺服器執行時期的Leader選舉(當leader當機後如何選主)?
zookeeper 在叢集模式下,leader宕機也不會影響繼續提供服務,但是leader宕機在從新選主過程時無法對外提供服務,會有一個短暫的停頓過程(這裡就是與eureka的區別)。
- 叢集已存在leader現在又假如一臺伺服器:對於叢集中已經存在Leader而言,此種情況一般都是某臺機器啟動得較晚,在其啟動之前,叢集已經在正常工作,對這種情況,該機器試圖去選舉Leader時,會被告知當前伺服器的Leader資訊,對於該機器而言,僅僅需要和Leader機器建立起連線,並進行狀態同步即可。
- 叢集存在leader宕機需要重新選舉leader:例如server3 宕機了。則剩餘的 每個Server發出一個投票。Server1和Server2都會將自己作為Leader伺服器來進行投票,每次投票會包含所推舉的伺服器的myid和ZXID,使用(myid, ZXID)來表示,此時Server1的投票為(1, 0),Server2的投票為(2, 0),然後各自將這個投票發給叢集中其他機器。當新的leader選擇出來以後,第二步就是資料同步保證所有的節點與leader資料一致。
處理投票。針對每一個投票,伺服器都需要將別人的投票和自己的投票進行PK,PK規則如下
· 優先檢查ZXID。ZXID比較大的伺服器優先作為Leader。
· 如果ZXID相同,那麼就比較myid。myid較大的伺服器作為Leader伺服器。
為什麼最好使用奇數臺伺服器構成 ZooKeeper 叢集?
zookeeper有這樣一個特性:叢集中只要有過半的機器是正常工作的,那麼整個叢集對外就是可用的。也就是說如果有2個zookeeper,那麼只要有1個死了zookeeper就不能用了,因為1沒有過半,所以2個zookeeper的死亡容忍度為0;同理,要是有3個zookeeper,一個死了,還剩下2個正常的,過半了(2>3/2),所以3個zookeeper的容忍度為1。如果是4臺zookeeper 如果掛掉2臺, 還剩下2臺 (2 不大於 4/2),顯然不過半所以叢集還是不可用,4臺的容忍度還是1。因此不是 不能部署偶數臺,而是偶數臺對於高可用作用不大,浪費伺服器。
三、ZooKeeper 的一些重要概念
ZooKeeper 將資料儲存在記憶體中,這也就保證了 高吞吐量和低延遲(但是記憶體限制了能夠儲存的容量不太大,此限制也是保持znode中儲存的資料量較小的進一步原因)。
ZooKeeper 是高效能的。 在“讀”多於“寫”的應用程式中尤其地高效能,因為“寫”會導致所有的伺服器間同步狀態。(“讀”多於“寫”是協調服務的典型場景。)
會話(Session)
Session 指的是 ZooKeeper 伺服器與客戶端會話。在 ZooKeeper 中,一個客戶端連線是指客戶端和伺服器之間的一個 TCP 長連線。客戶端啟動的時候,首先會與伺服器建立一個 TCP 連線,從第一次連線建立開始,客戶端會話的生命週期也開始了。通過這個連線,客戶端能夠通過心跳檢測與伺服器保持有效的會話,也能夠向Zookeeper伺服器傳送請求並接受響應,同時還能夠通過該連線接收來自伺服器的Watch事件通知。 Session的sessionTimeout值用來設定一個客戶端會話的超時時間。當由於伺服器壓力太大、網路故障或是客戶端主動斷開連線等各種原因導致客戶端連線斷開時,只要在sessionTimeout規定的時間內能夠重新連線上叢集中任意一臺伺服器,那麼之前建立的會話仍然有效。
在為客戶端建立會話之前,服務端首先會為每個客戶端都分配一個sessionID。由於 sessionID 是 Zookeeper 會話的一個重要標識,許多與會話相關的執行機制都是基於這個 sessionID 的,因此,無論是哪臺伺服器為客戶端分配的 sessionID,都務必保證全域性唯一。
Watcher
Watcher(事件監聽器),是Zookeeper中的一個很重要的特性。Zookeeper允許使用者在指定節點上註冊一些Watcher,並且在一些特定事件觸發的時候,ZooKeeper服務端會將事件通知到感興趣的客戶端上去,該機制是Zookeeper實現分散式協調服務的重要特性。
ACL
Zookeeper採用ACL(AccessControlLists)策略來進行許可權控制,類似於 UNIX 檔案系統的許可權控制。Zookeeper 定義瞭如下5種許可權

四、zookeeper 的資料結構
ZooKeeper 允許分散式程序通過共享的層次結構名稱空間進行相互協調,這與標準檔案系統類似。 名稱空間由 ZooKeeper 中的資料暫存器組成 - 稱為znode,這些類似於檔案和目錄。 與為儲存設計的典型檔案系統不同,ZooKeeper資料儲存在記憶體中,這意味著ZooKeeper可以實現高吞吐量和低延遲。
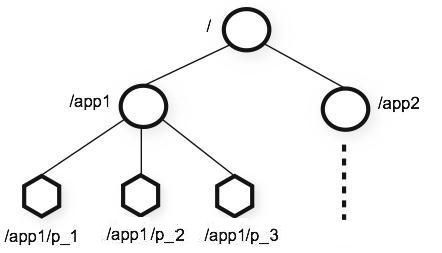
1、PERSISTENT--持久化目錄節點 客戶端與zookeeper斷開連線後,該節點依舊存在
2、PERSISTENT_SEQUENTIAL-持久化順序編號目錄節點 客戶端與zookeeper斷開連線後,該節點依舊存在,只是Zookeeper給該節點名稱進行順序編號
3、EPHEMERAL-臨時目錄節點 客戶端與zookeeper斷開連線後,該節點被刪除
4、EPHEMERAL_SEQUENTIAL-臨時順序編號目錄節點 客戶端與zookeeper斷開連線後,該節點被刪除,只是Zookeeper給該節點名稱進行順序編號
五、zookeeper的作用
1、命名服務
在zookeeper的檔案系統裡建立一個目錄,即有唯一的path,在我們使用tborg無法確定上游程式的部署機器時即可與下游程式約定好path,通過path即能互相探索發現。
2、配置管理
程式總是需要配置的,如果程式分散部署在多臺機器上,要逐個改變配置就變得困難。好吧,現在把這些配置全部放到zookeeper上去,儲存在 Zookeeper 的某個目錄節點中,然後所有相關應用程式對這個目錄節點進行監聽,一旦配置資訊發生變化,每個應用程式就會收到 Zookeeper 的通知,然後從 Zookeeper 獲取新的配置資訊應用到系統中就好。
3、叢集管理
所謂叢集管理無在乎兩點:是否有機器退出和加入、選舉master。
第一點,所有機器約定在父目錄GroupMembers下建立臨時目錄節點,然後監聽父目錄節點的子節點變化訊息。一旦有機器掛掉,該機器與 zookeeper的連線斷開,其所建立的臨時目錄節點被刪除,所有其他機器都收到通知:某個兄弟目錄被刪除,於是,所有人都知道他掉線了。新機器加入 也是類似,所有機器收到通知:新兄弟目錄加入。
對於第二點,我們稍微改變一下,所有機器建立臨時順序編號目錄節點,每次選取編號最小的機器作為master就好。
4、分散式鎖
有了zookeeper的一致性檔案系統,鎖的問題變得容易。鎖服務可以分為兩類,一個是保持獨佔,另一個是控制時序。
對於第一類,我們將zookeeper上的一個znode看作是一把鎖,通過createznode的方式來實現。所有客戶端都去建立 /distribute_lock 節點,最終成功建立的那個客戶端也即擁有了這把鎖。用完刪除掉自己建立的distribute_lock 節點就釋放出鎖。
對於第二類, /distribute_lock 已經預先存在,所有客戶端在它下面建立臨時順序編號目錄節點,和選master一樣,編號最小的獲得鎖,用完刪除,依次方便。 &n