redis 深入學習筆記
速度快-記憶體

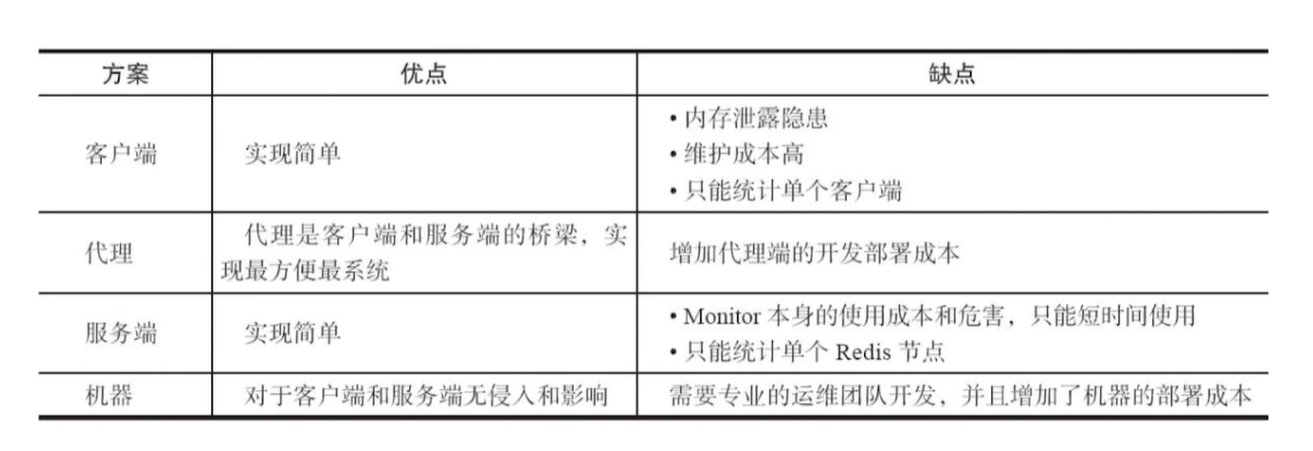
多種資料結構

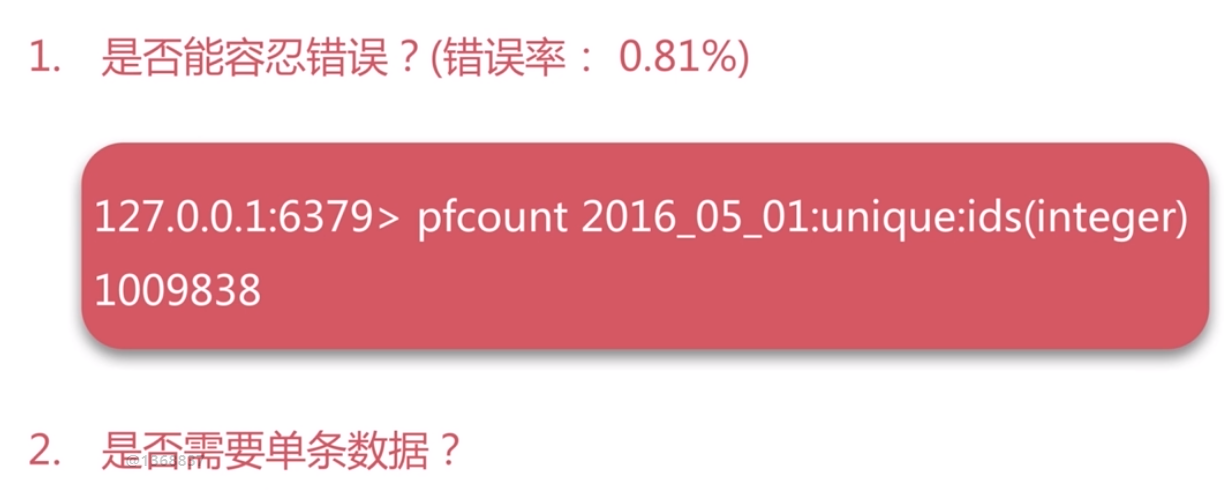
bitMaps 比如布隆過濾器, HyperLogLog 精確性不夠,
常用配置
預設不是守護程序, 實際一般都是 設定為 守護程序
daemonize yes
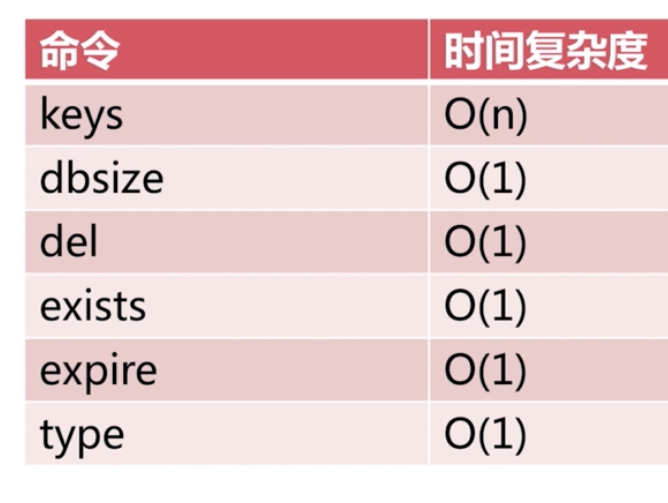
通用命令

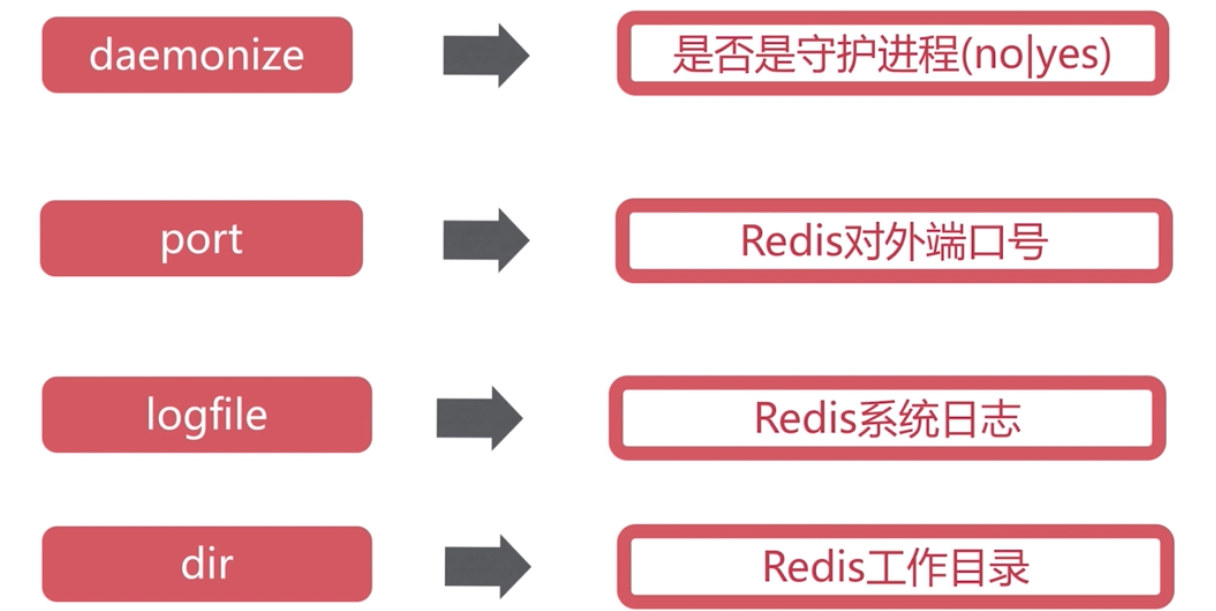
keys 命令一般在生產環境不使用,生產環境key 太多了,比較慢,而且會阻塞其他命令。最後不用,否則容易出現影響使用的問題。
keys* 可以在 從節點使用或者 scan
dbsize 可以在生產環境隨便使用

redis 是單執行緒的

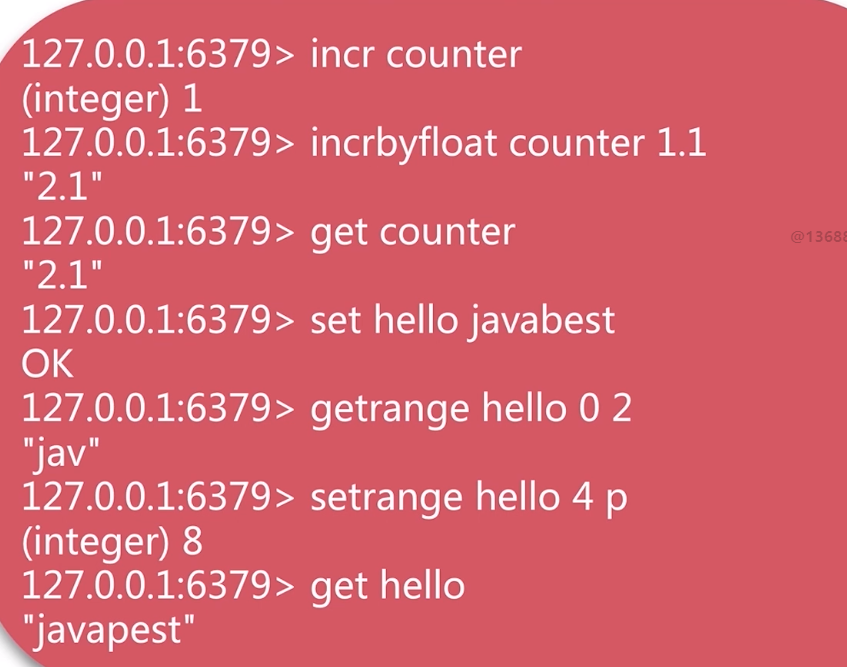
字串
key 和value 都是 位元組儲存的,一般都是 限制在 100K左右大小



中文裡面一個 文字就是 2個長度

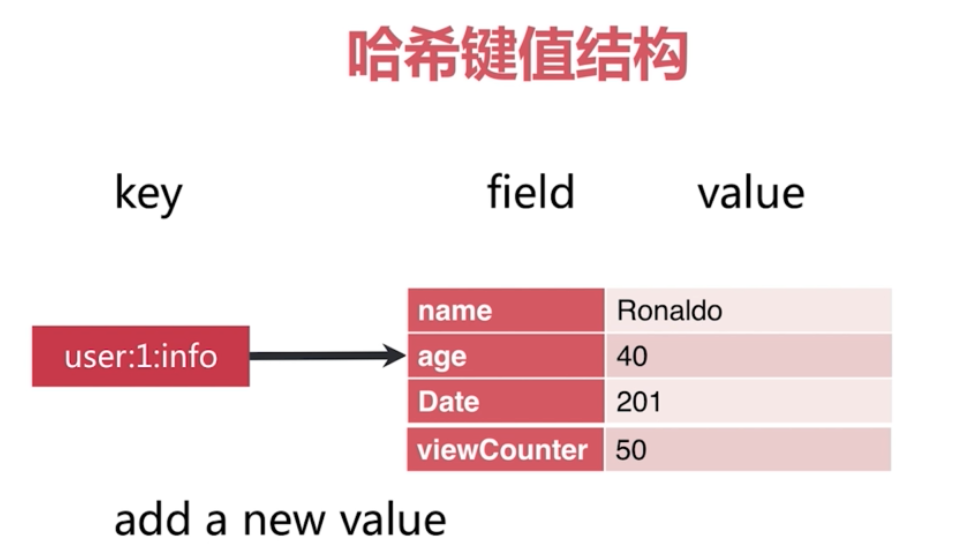
hash




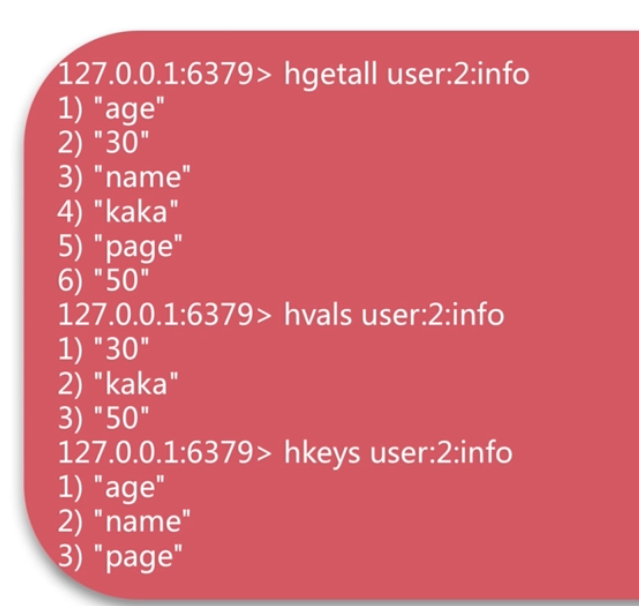
小心使用 hgetall 特別是 內容特別多時候

list
有序,可以重複,左右兩邊插入與彈出








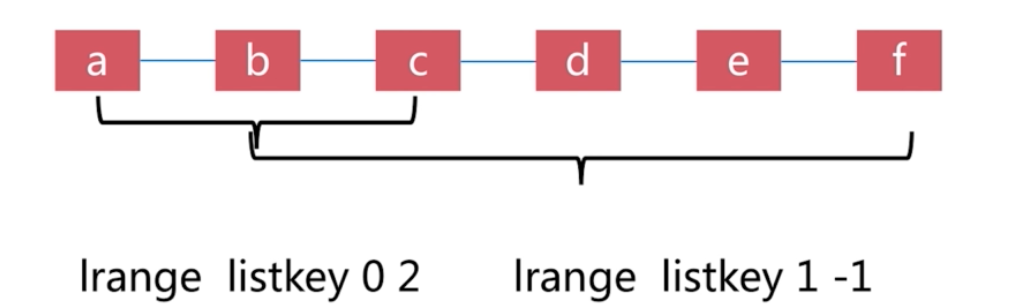


靈活執行實現不同功能

set
無序,無重複,集合間操作(交集,並級等)


smembers 無序,小心使用,內容太多了就不好
spop從集合彈出,且彈出一個。 srandmember 不會破壞集合

sadd 可以用於 標籤 業務需求,
sadd + sinter 可以用於 社交類 業務
zset 有序集合











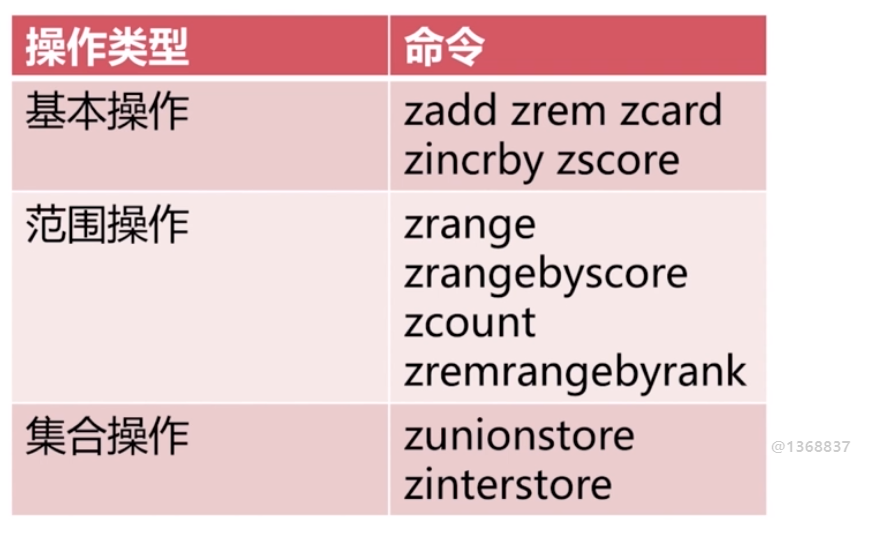
Jedis

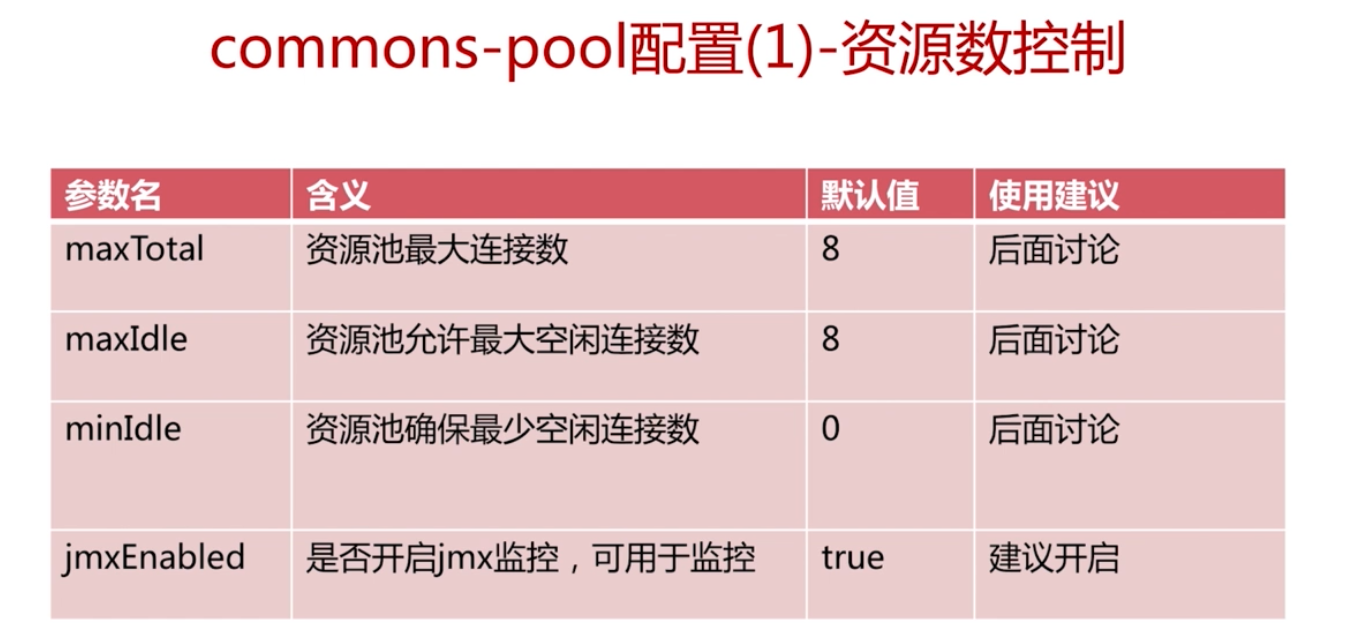
jedis 連線池配置
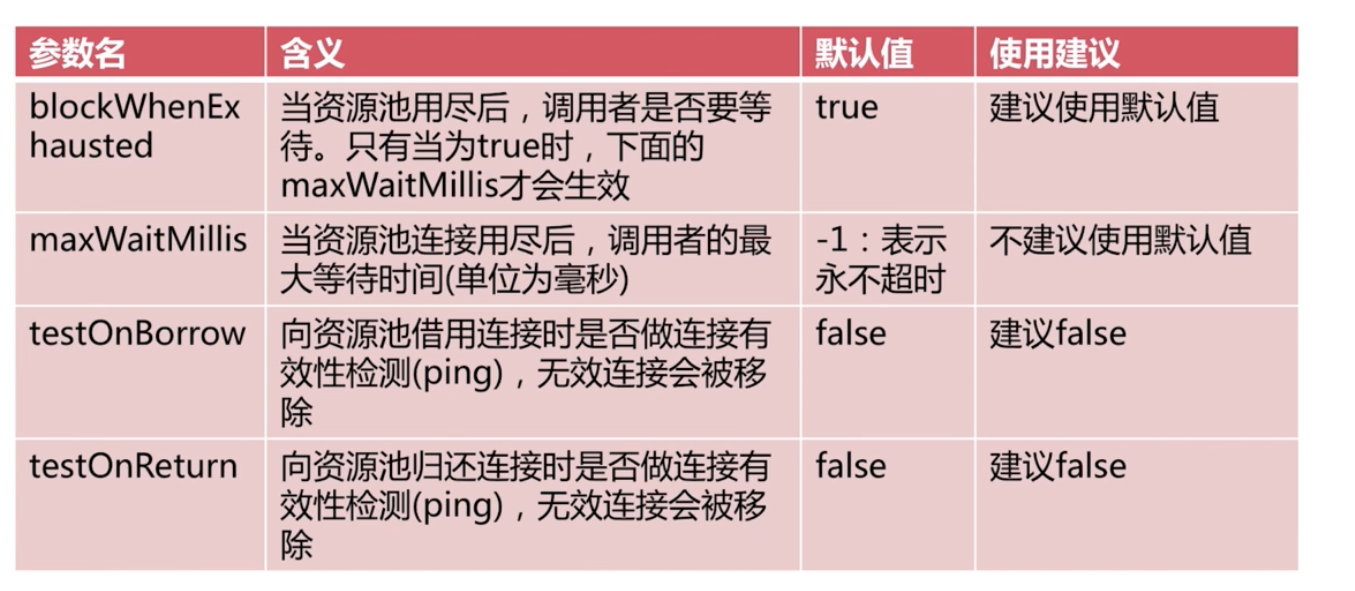
建議false 是因為 特別在高併發下,也影響效能,而且 可以通過 redis 配置來達到 連線基本永遠活性
合適maxTotal 比較難確定



常見問題


4. 網路或者DNS異常等原因
redis 慢查詢
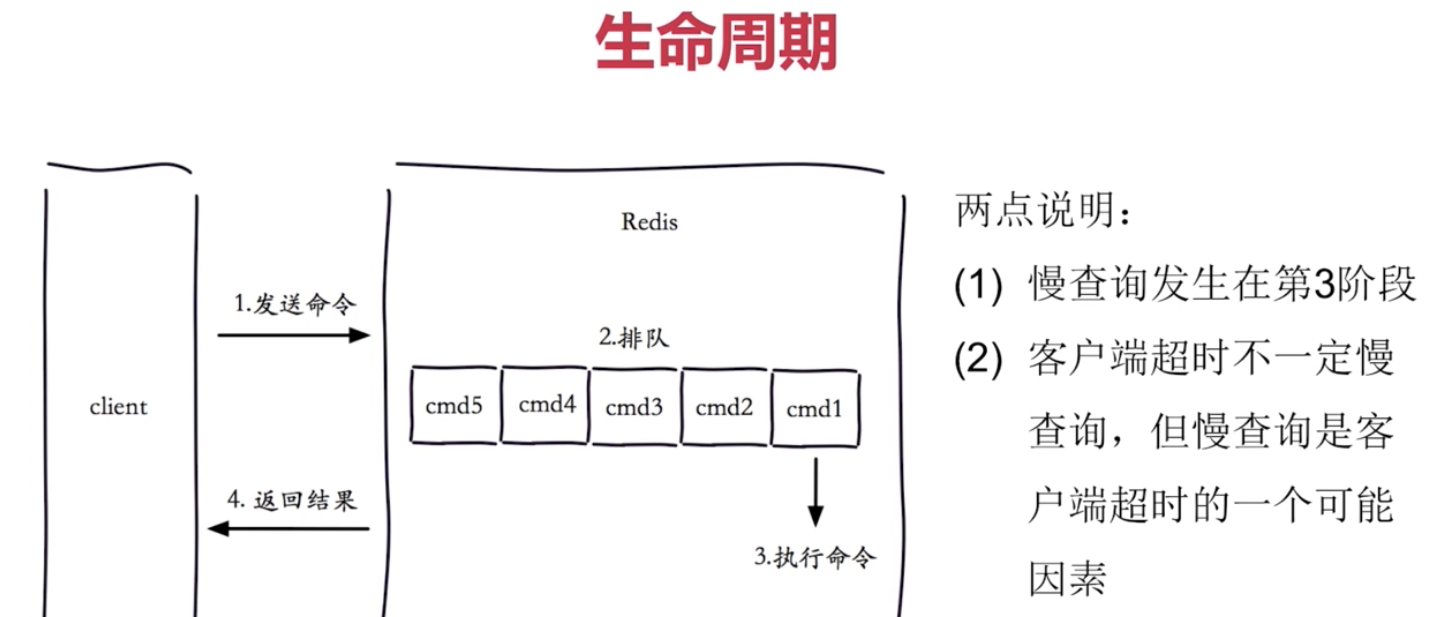
執行命令的時候 執行很慢,才屬於慢查詢
客戶端超時不一定慢查詢,但慢查詢是客戶端超時的一個可能因素
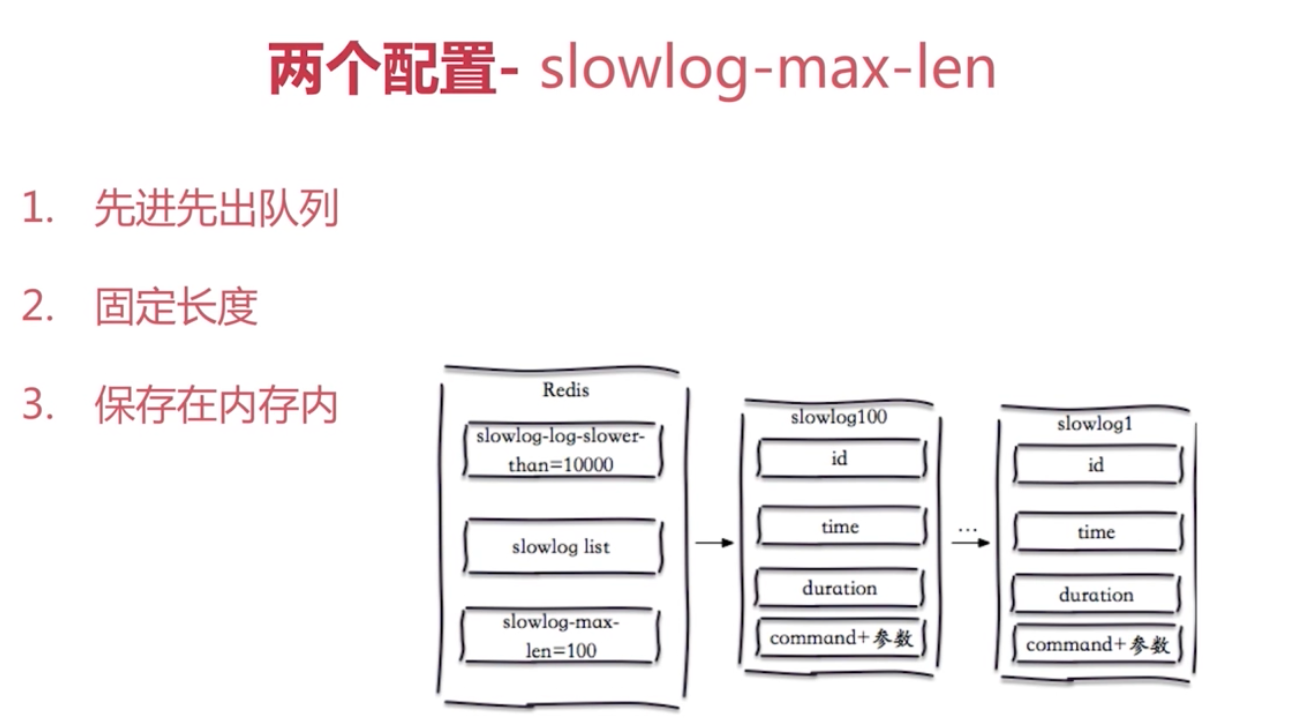
慢查詢儲存在記憶體中,redis 重啟之後就沒有了
slowlog-log-slower-than 慢查詢閾值

配置,可以啟動時候配置,也可以動態配置

命令

- slowlog-log-slower-than不要設定過大,預設是10ms,通常設定1ms
- slowlog-max-len不要設定過小,通常設定1000左右
定期持久化慢查詢(使用開源軟體或者其他手段去持久化慢查詢記錄),就可以 檢視歷史的慢查詢了
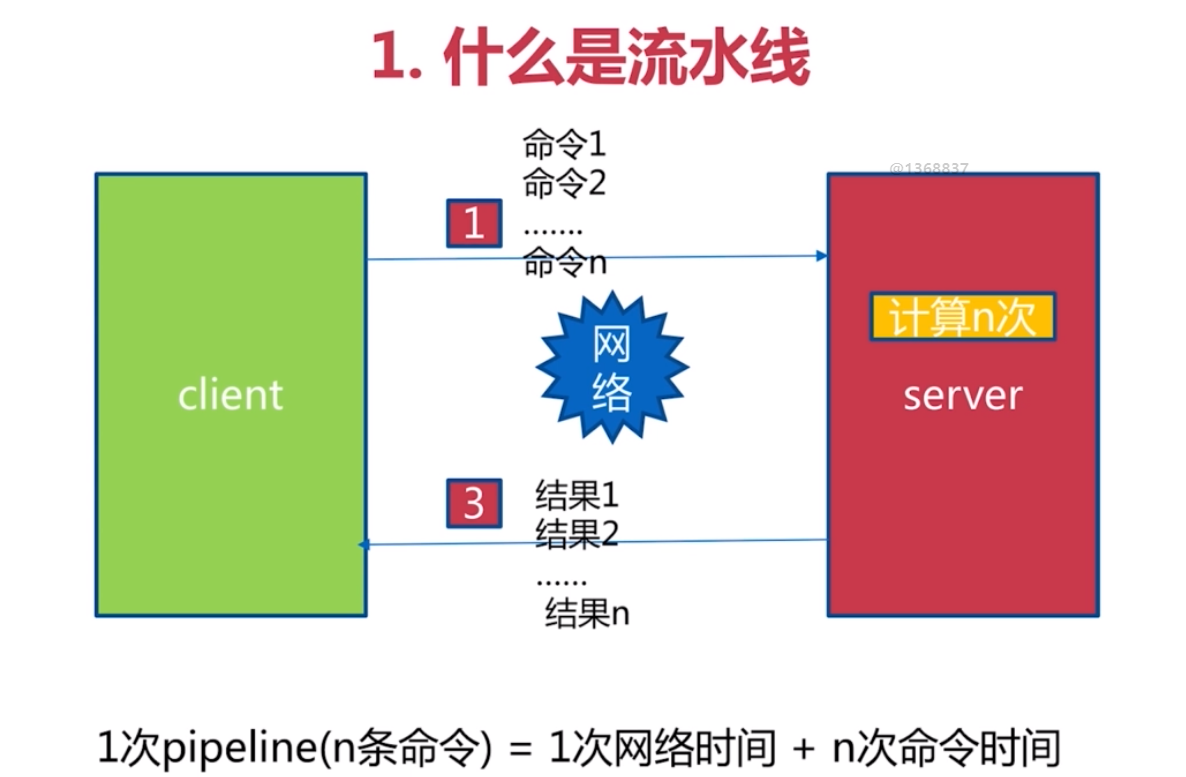
pipeline 流水線
主要是為了 節約網路時間, 提高通訊效率


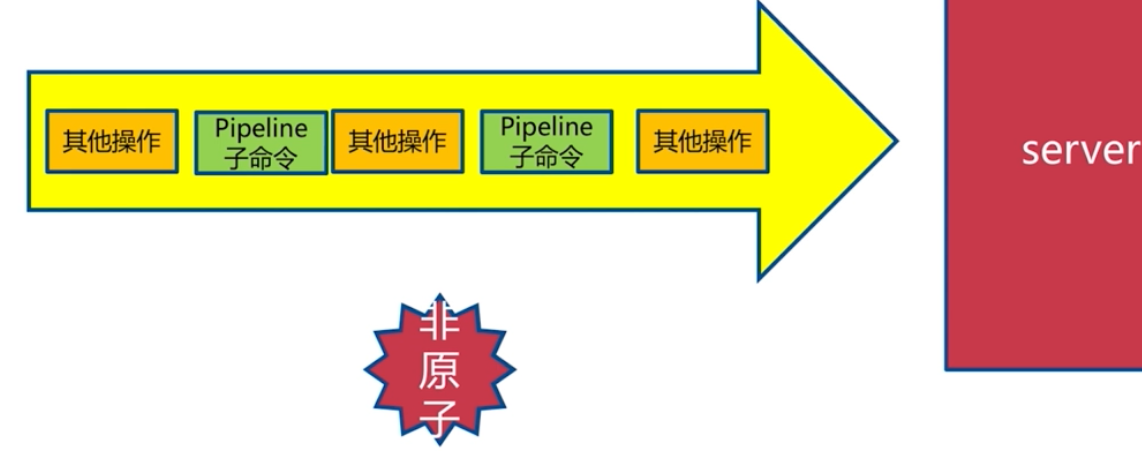
原生M操作是原子的。而 pipeline 命令不是原子的,會對命令進行拆分為小的命令

釋出訂閱

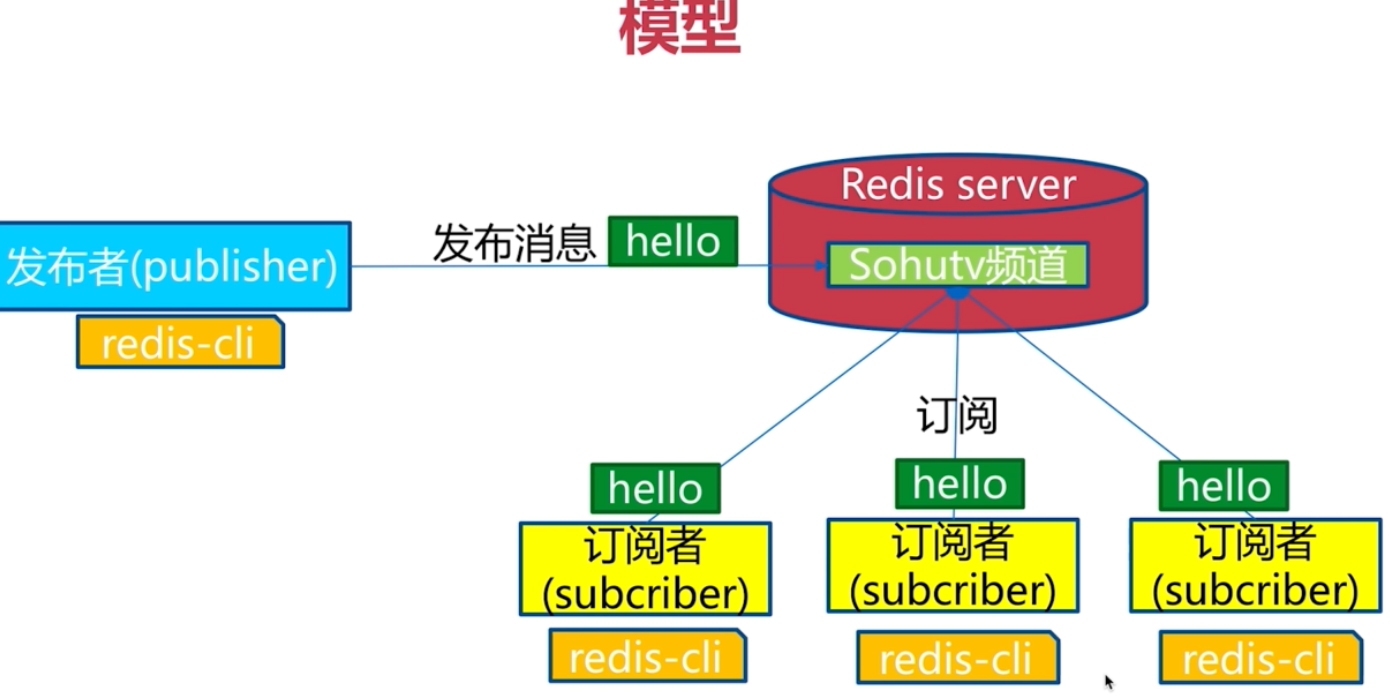
命令
釋出

訂閱

取消訂閱


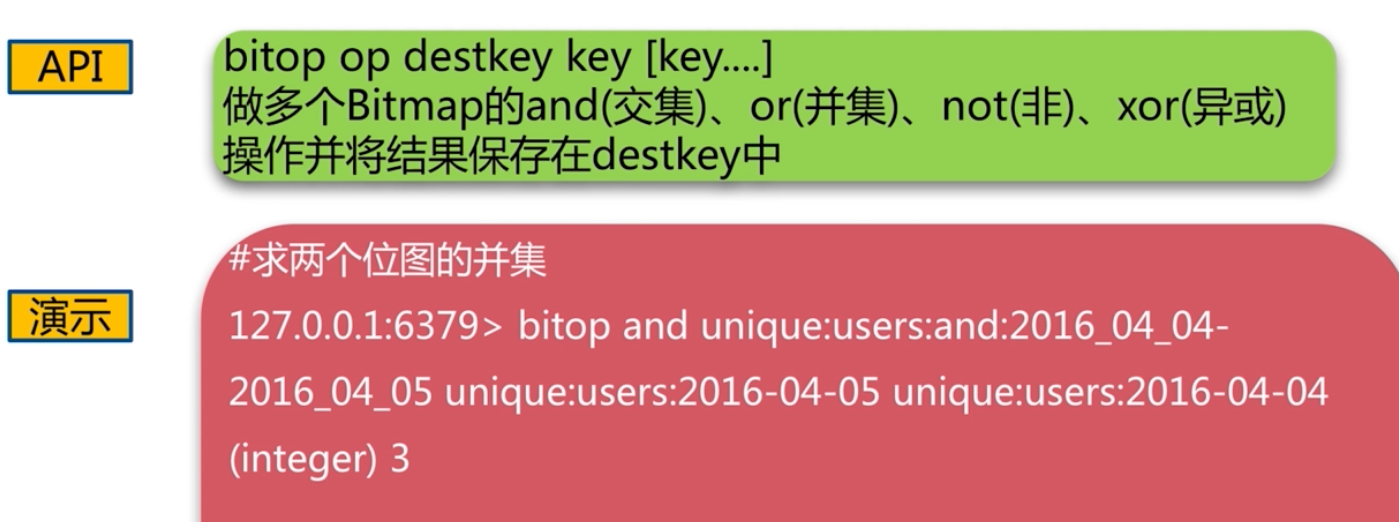
bitmap 點陣圖

value 只能是 0 或者1




HyperLogLog


GEO 地理資訊定位




geo 在 3.2 版本以上才有
持久化
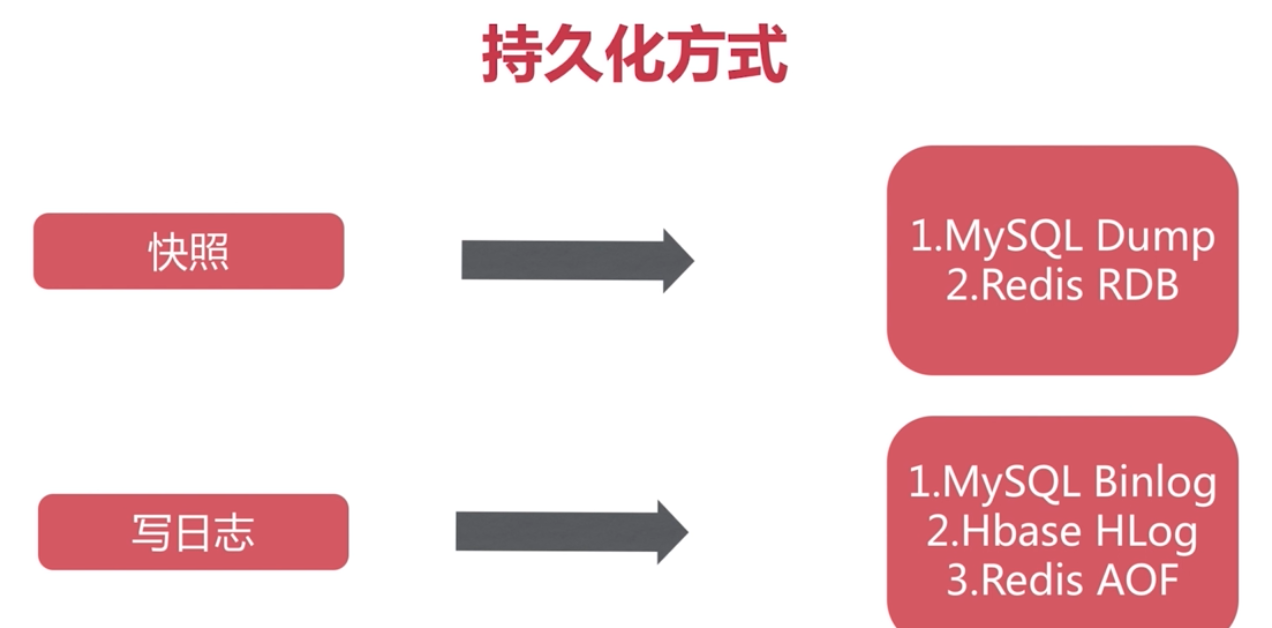
RDB
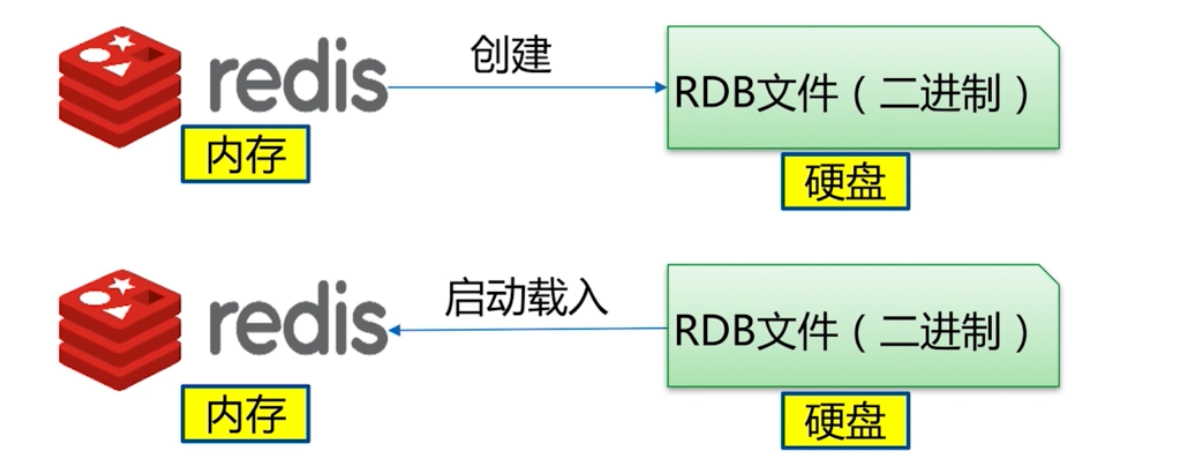
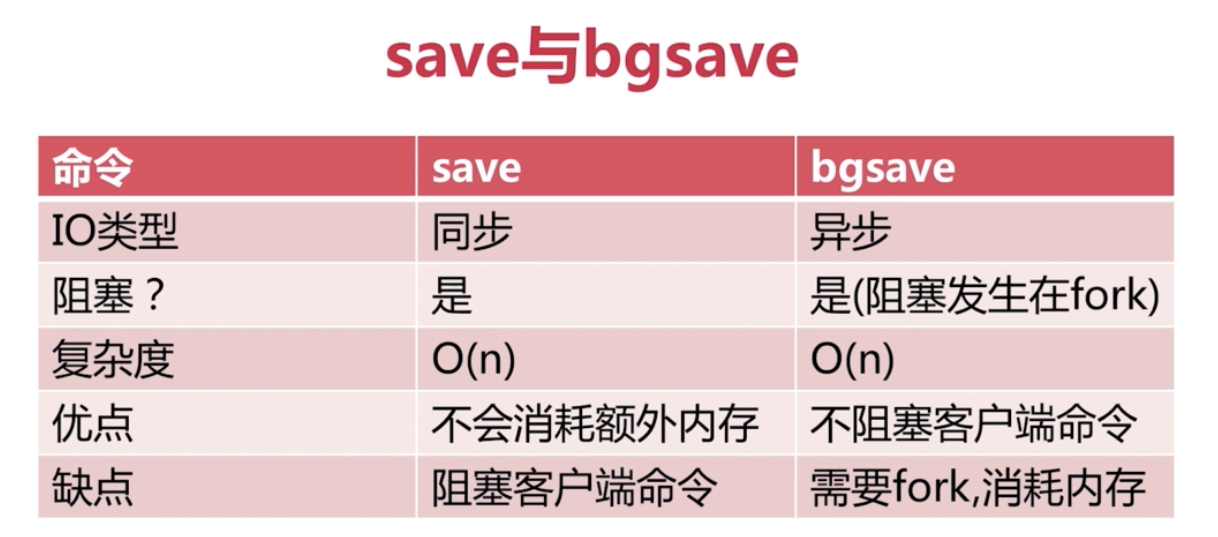
觸發機制: save (同步,將阻塞redis), bgsave(非同步), 自動
save 與 bgsave

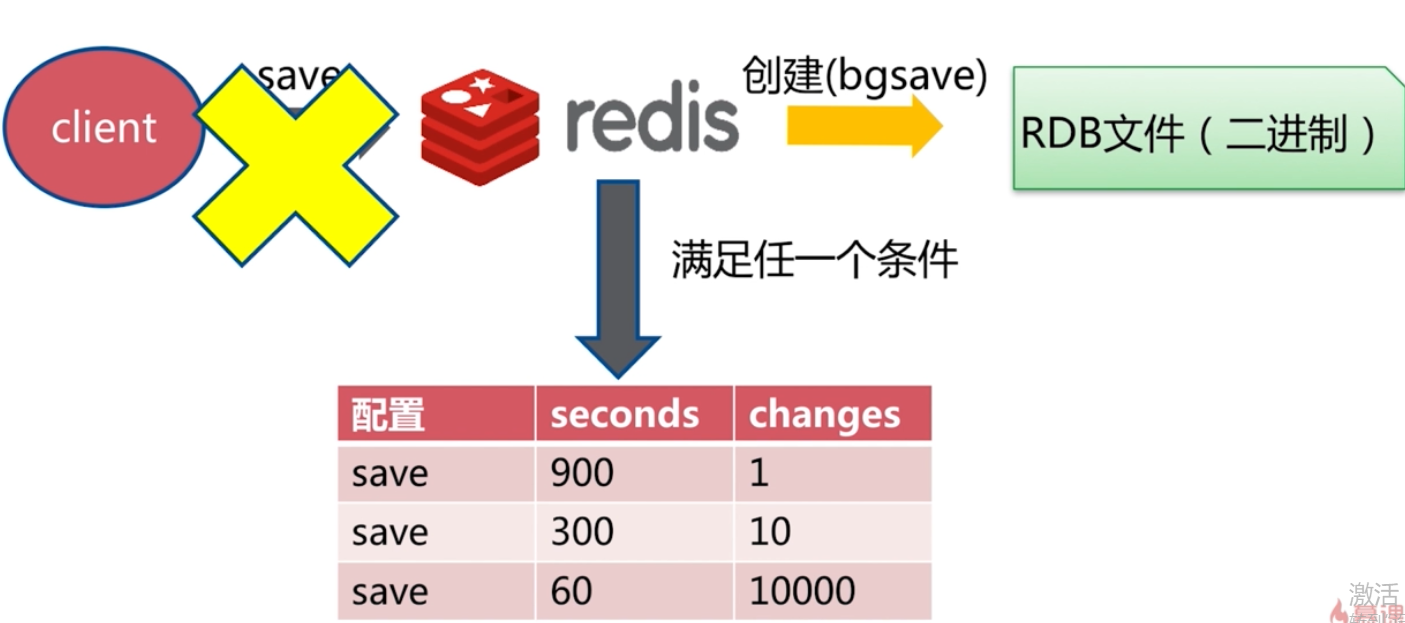
自動生成RDB
配置

rdbcompression 是否採用壓縮方式儲存, rdbchecksum 是否 檢驗
不容忽略方式
1, 全量複製, 2, debug reload , 3. shutdown (可以在關閉時候,生成 rdb)

通常情況下不會去 配置 save 的 自動配置
RDB耗時,耗效能,不可控,容易丟失資料
AOF
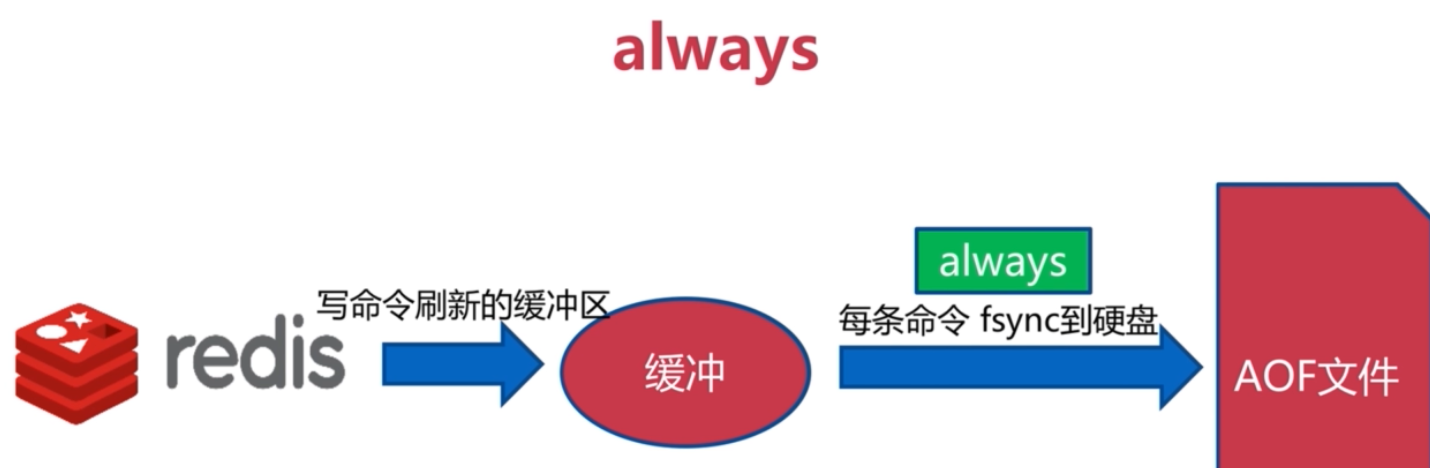

預設就是AOF策略就是everysec 這樣最多會丟失一秒內的資料‘

no策略也就是 預設按照作業系統來將緩衝資料重新整理到 AOF檔案。
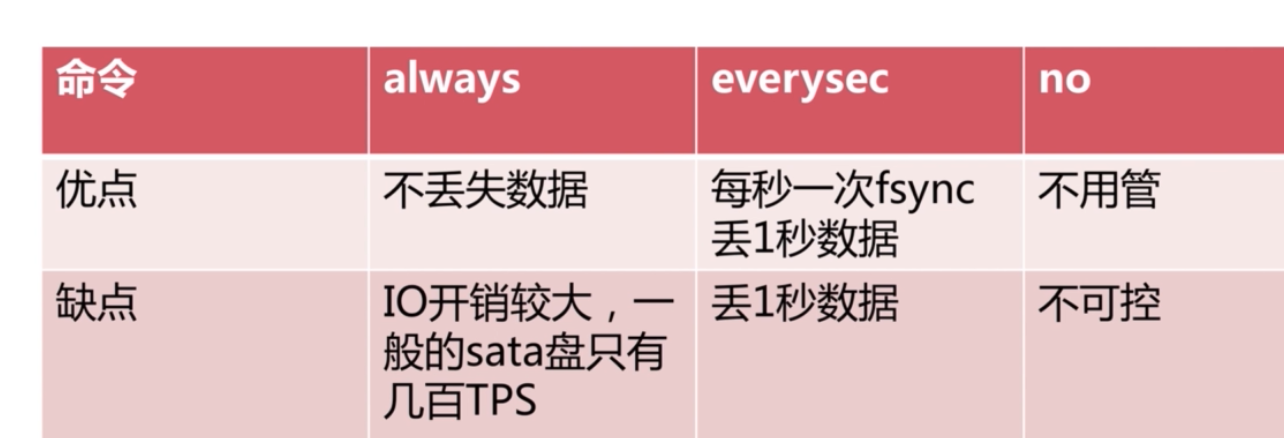
一般都是 使用 everysec

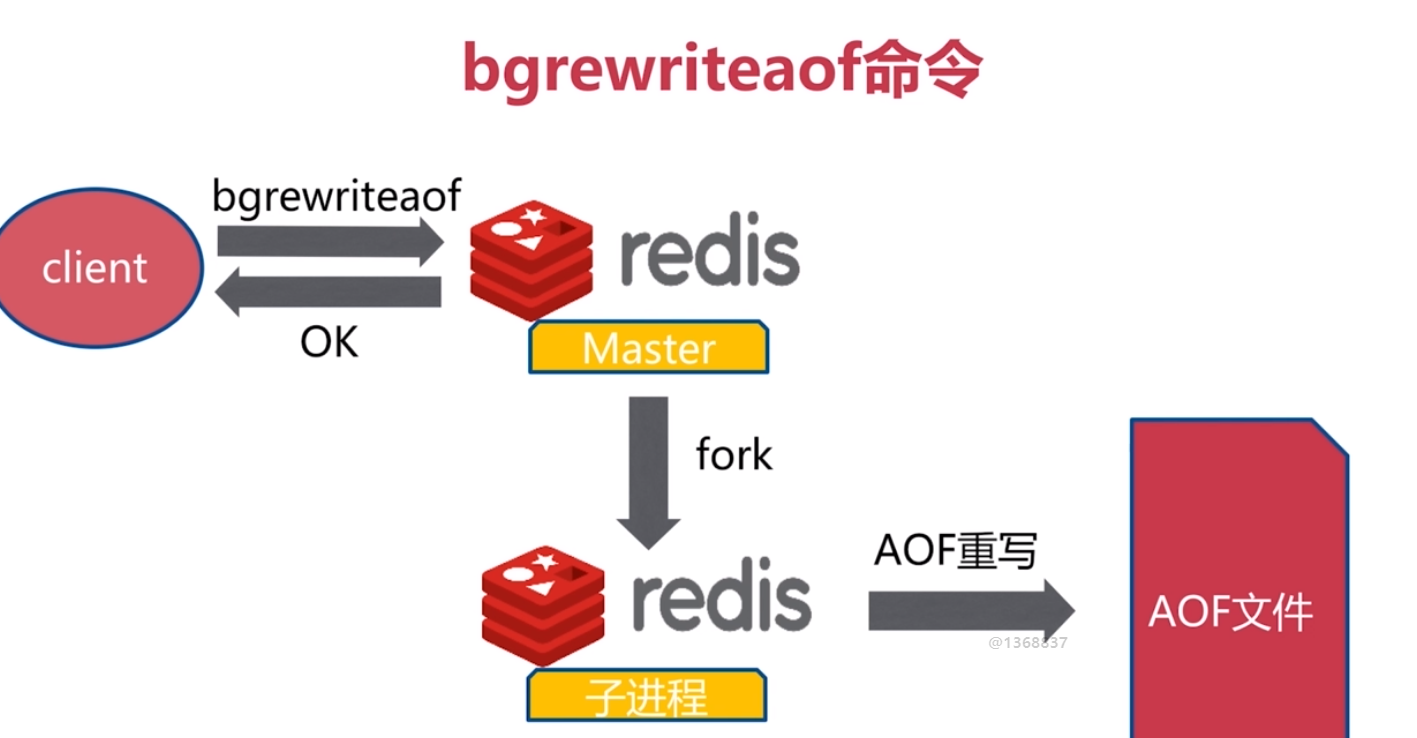
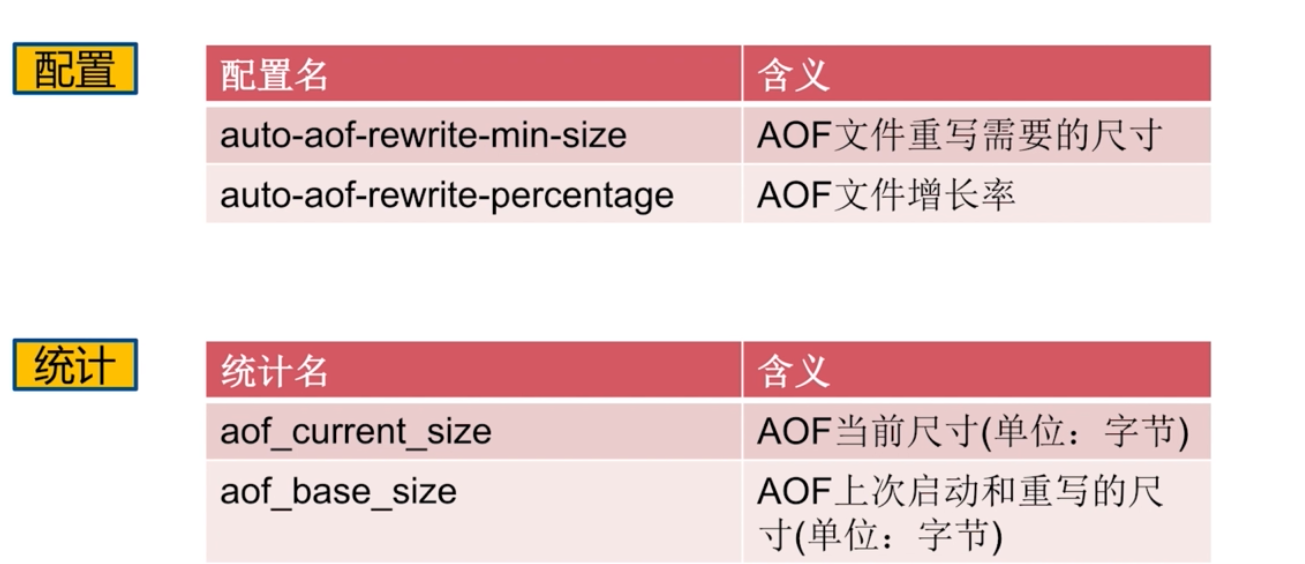
AOF自動重寫

配置

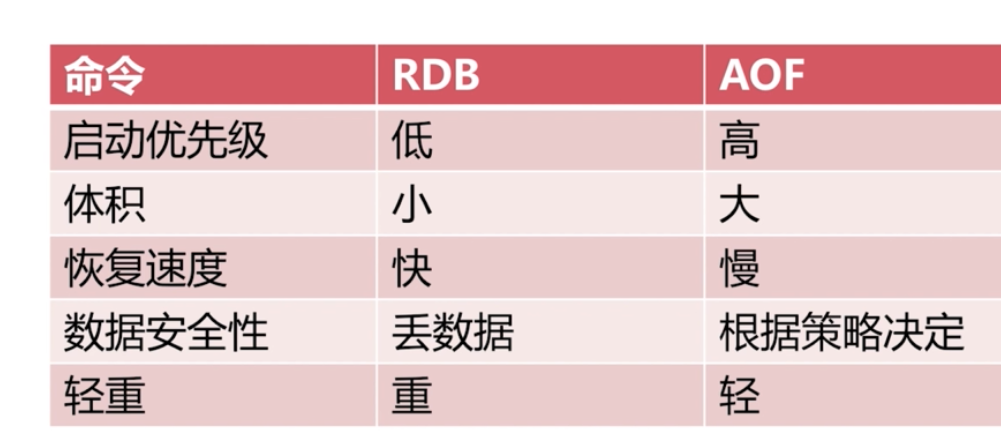

可以使用RDB 做備份來集中管理

使用AOF要考慮到 系統記憶體,需要預留一些記憶體給AOF的

fork 操作
https://www.jianshu.com/p/4425475fb596

info:latest_fork_usec 即上一次fork的微秒數,如果這個比較大,可能會在fork時候阻塞 redis

maxmemory 越大fork 越久
子程序開銷和優化

硬碟優化

redis 主從複製 及優化
redis 可以有 1主多從,
可以進行讀寫分離: 寫主節點,讀從節點
主從配置
1, salveof 命令

當主複製資料給從的時候,會將從服務的資料給清除掉
slaveof no noe 取消複製
2,配置
slaveof ip port
slave-read-only yes

主從之間是 全量複製的
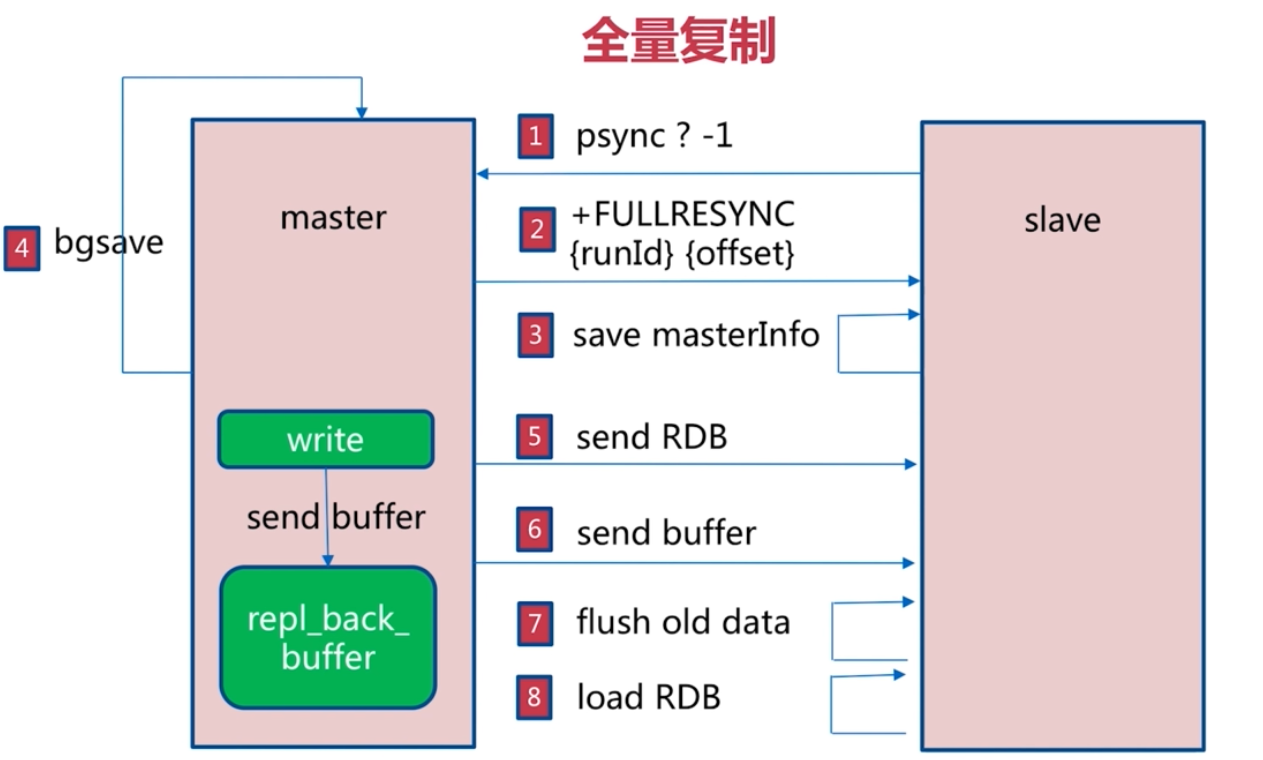

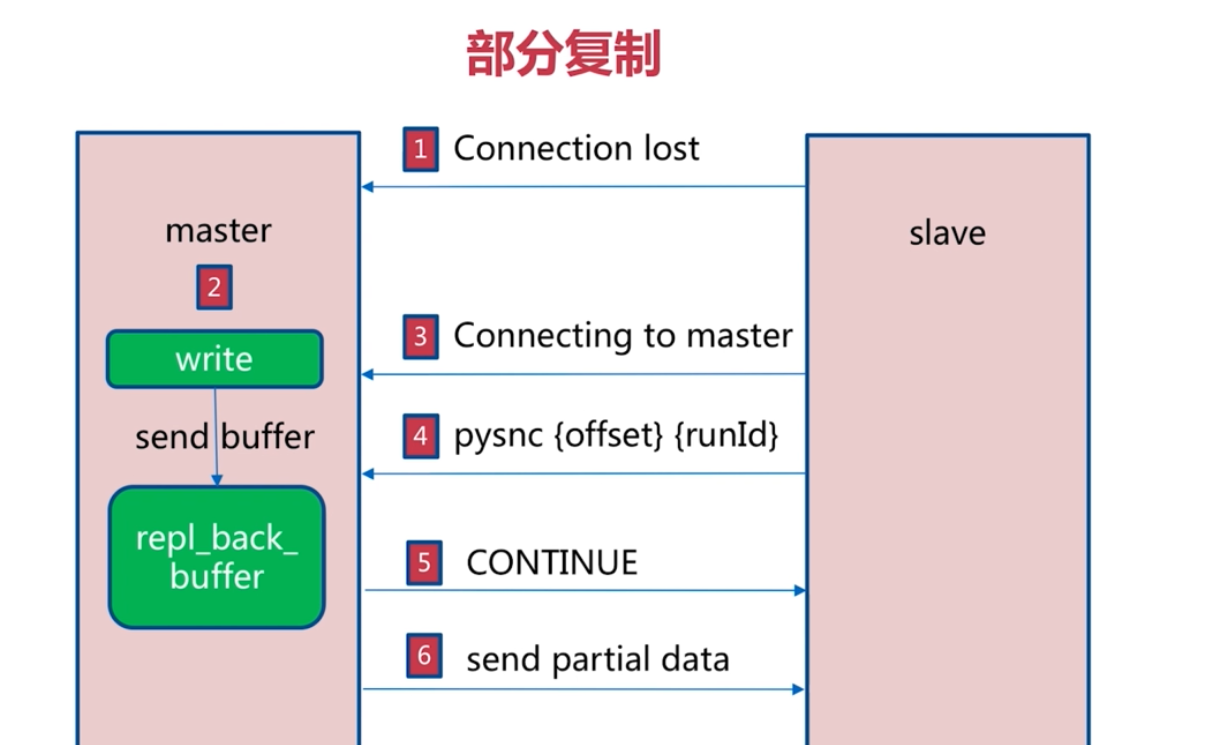
故障處理
使用sentinel 做故障轉移
主從複製問題
可以在從節點 做 備份也就是 做 rdb 的備份。這樣可以減輕 主節點的壓力
1, 讀寫分離

從節點不能刪除過期資料,所以會讀到過期資料
讀寫不好做,那就不要讀寫分離了,擴容 優化master好了
2. 主從配置不一致

3. 規避全量複製

4. 規避複製風暴
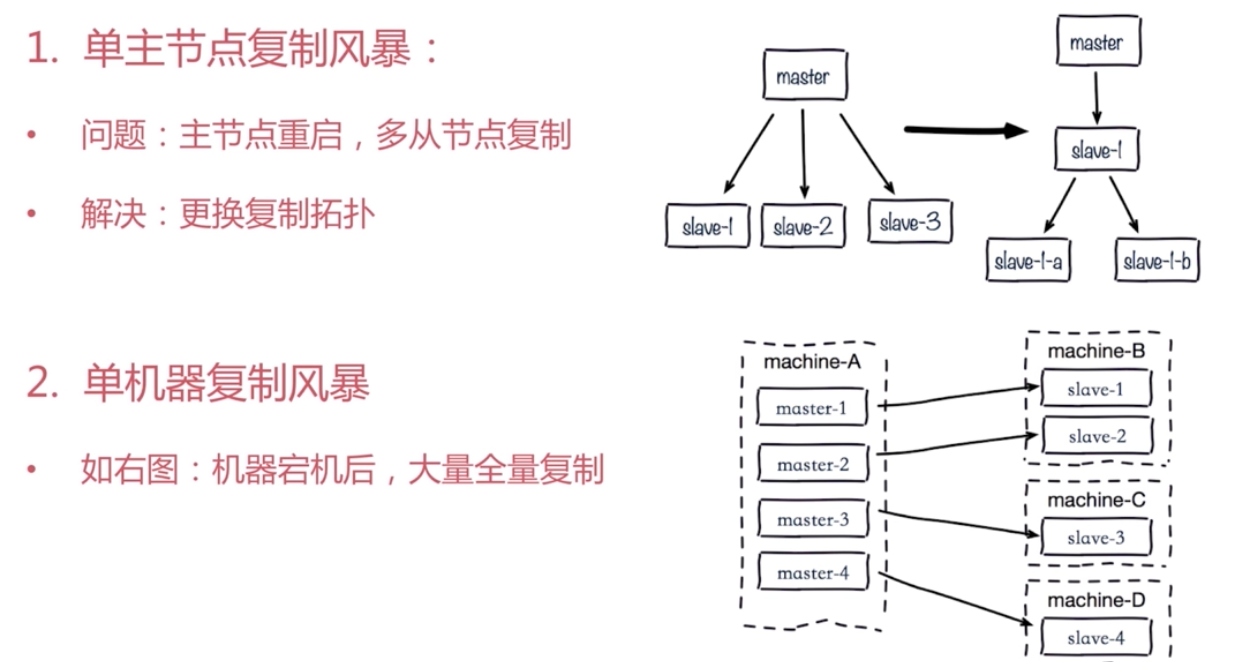
可以採用:主節點分散多機器
Redis Sentinel
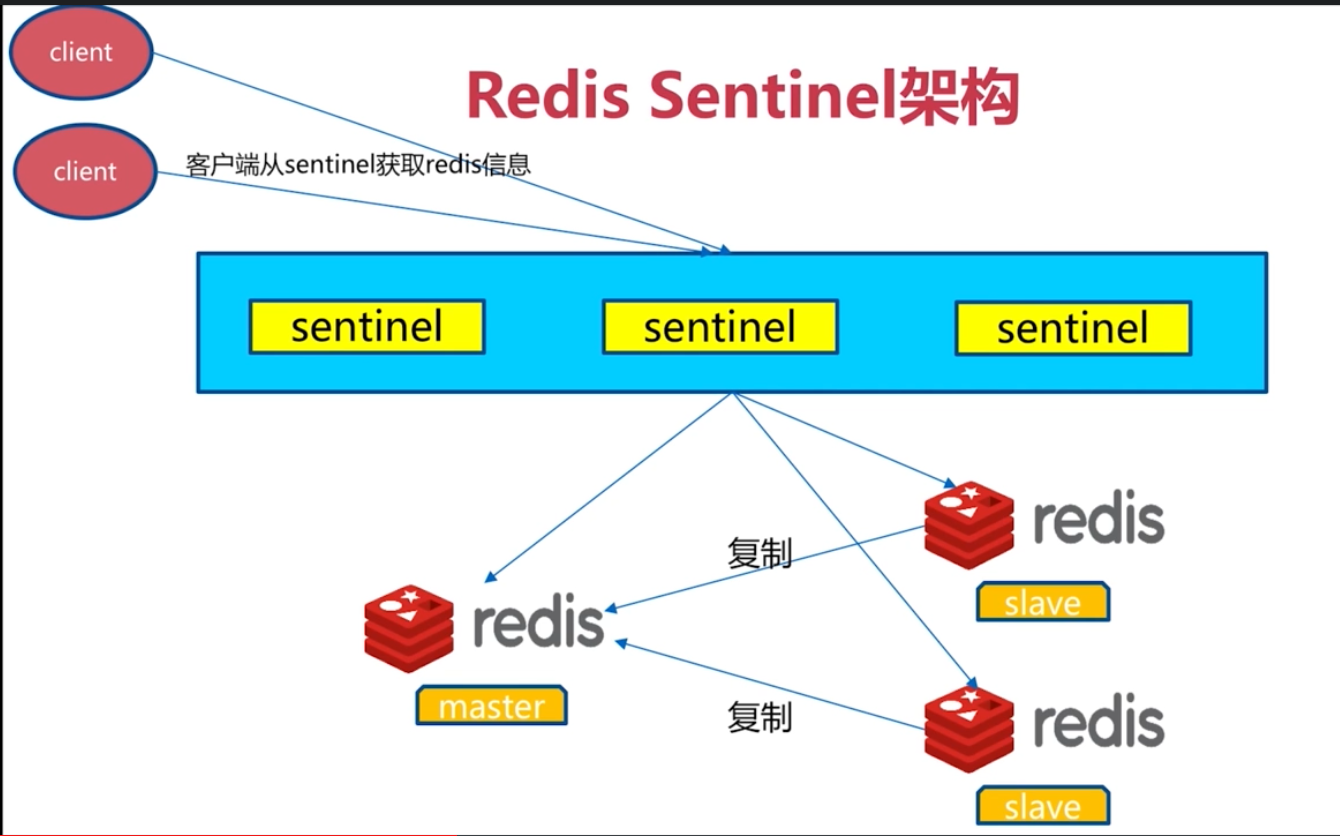
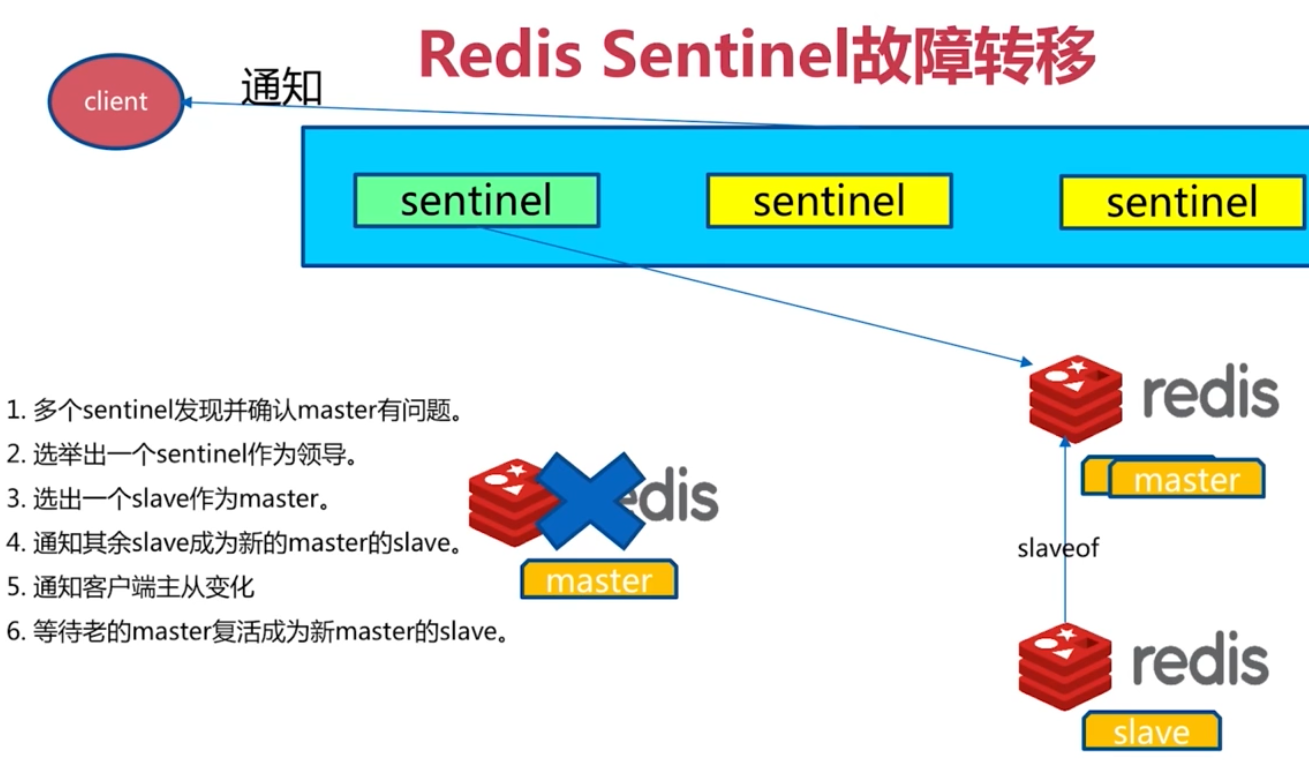
sentinel 可以管理多套 redis 主從

sentinel 的redis客戶端介入流程

master 節點變化時候, sentinel 會去通知客戶端的

sentinel 原理與三個定時任務





手動故障轉移,下線



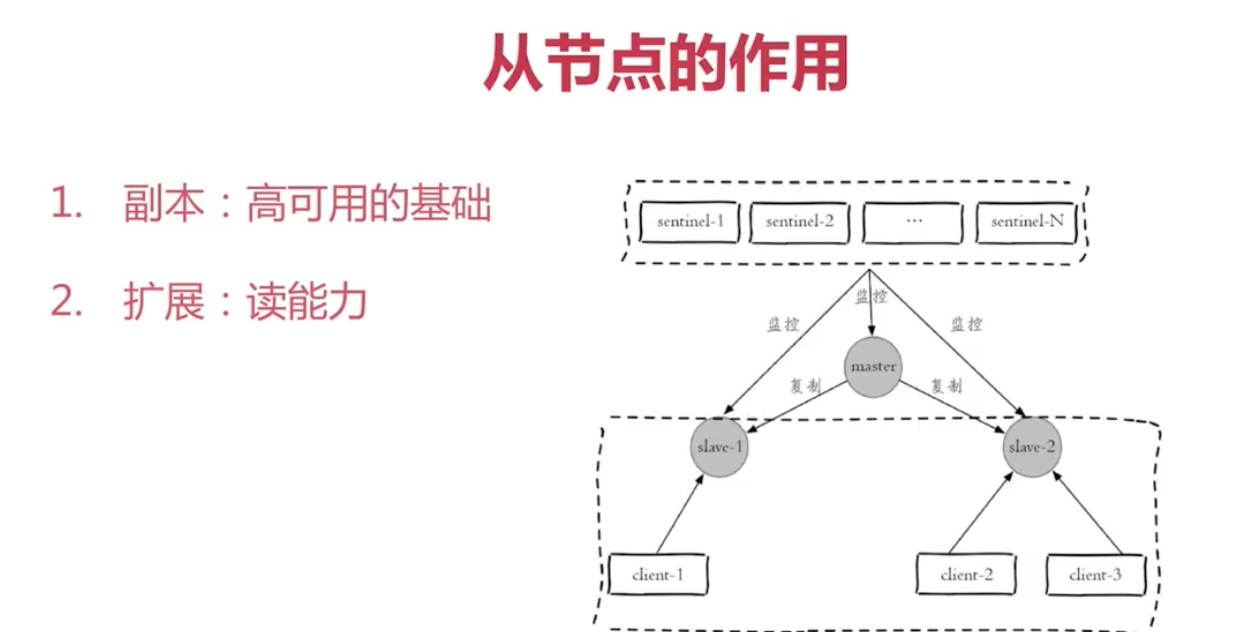
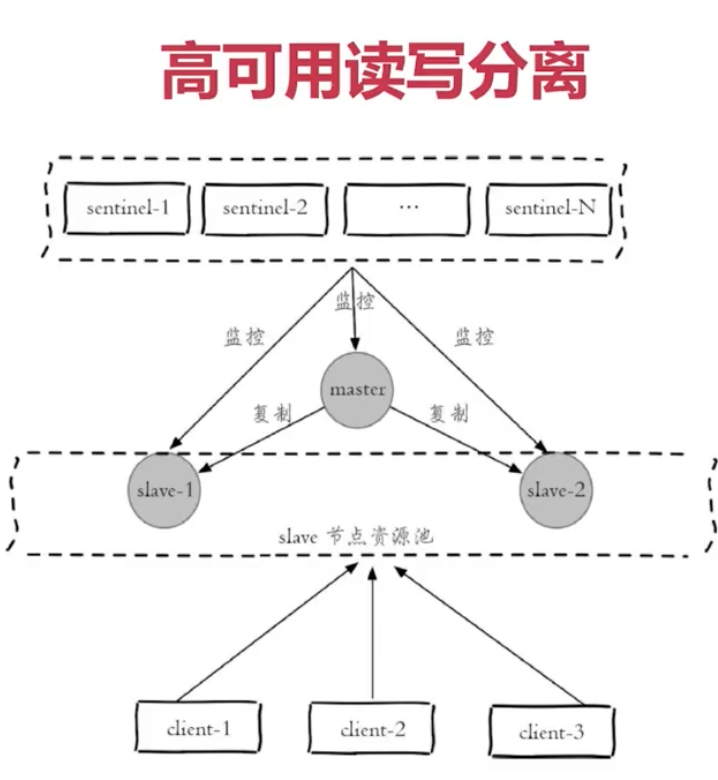
高可用讀寫分離




Redis Cluster 分散式叢集
呼喚叢集
1. 單機可以併發量 10萬/每秒
業務需要100W/每秒
2. 資料量
機器記憶體一般16到 256G記憶體,但是業務需要500G以上?
3. 規模化需求
資料分佈
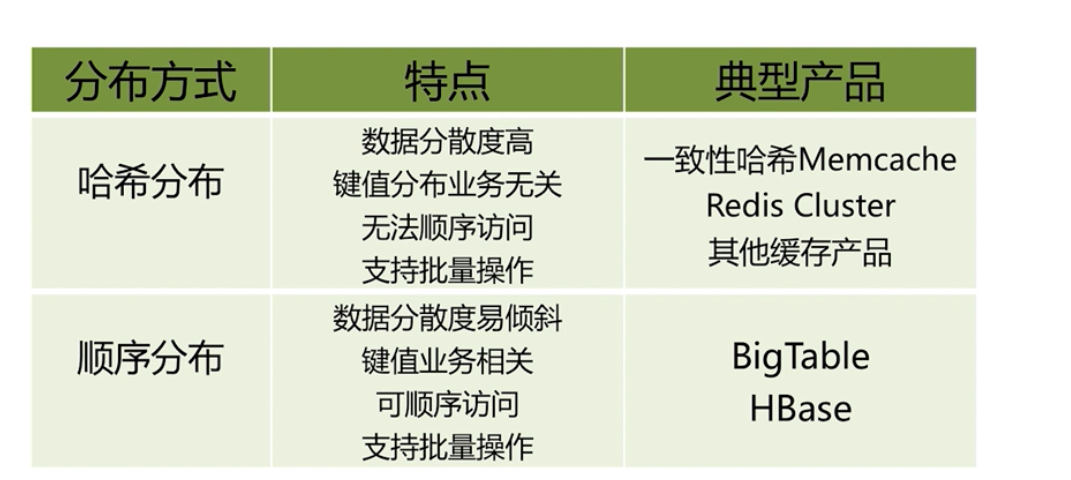
取餘分割槽
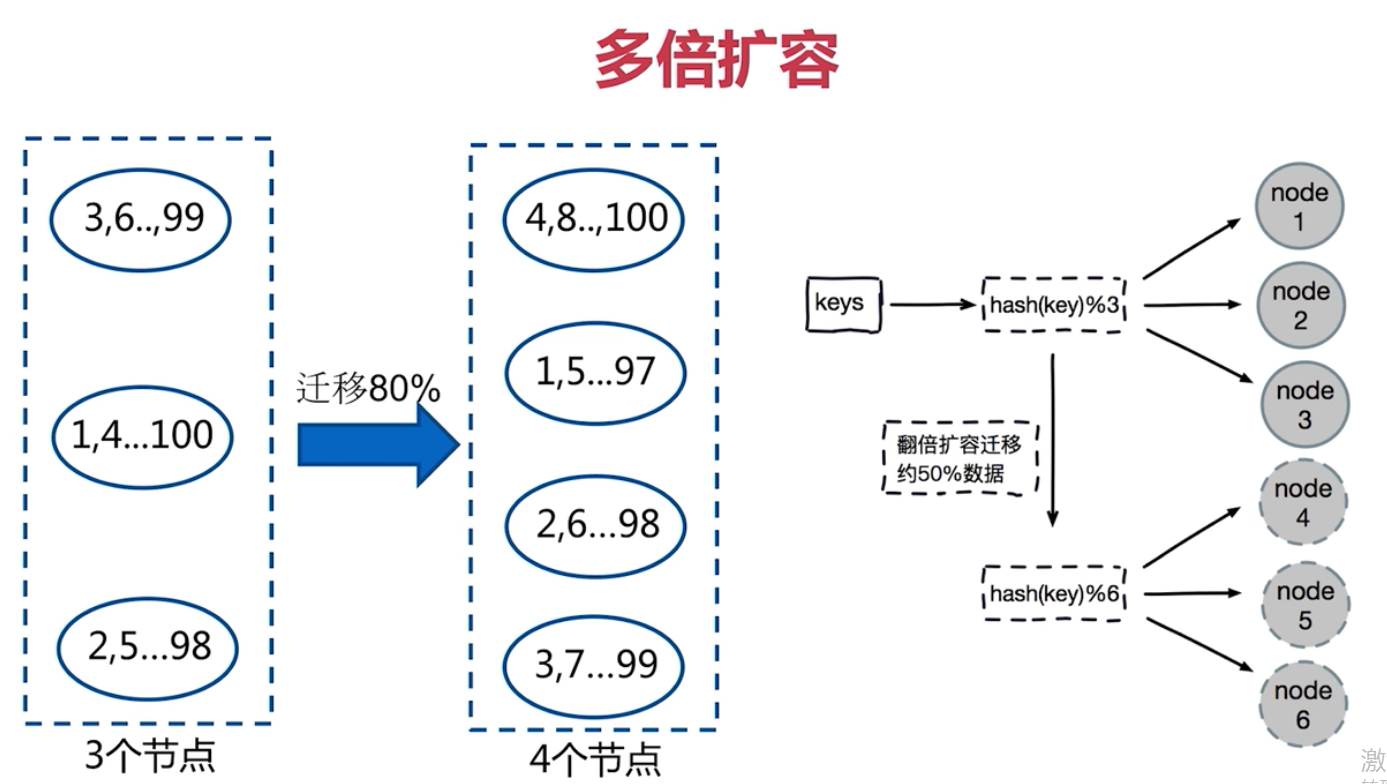


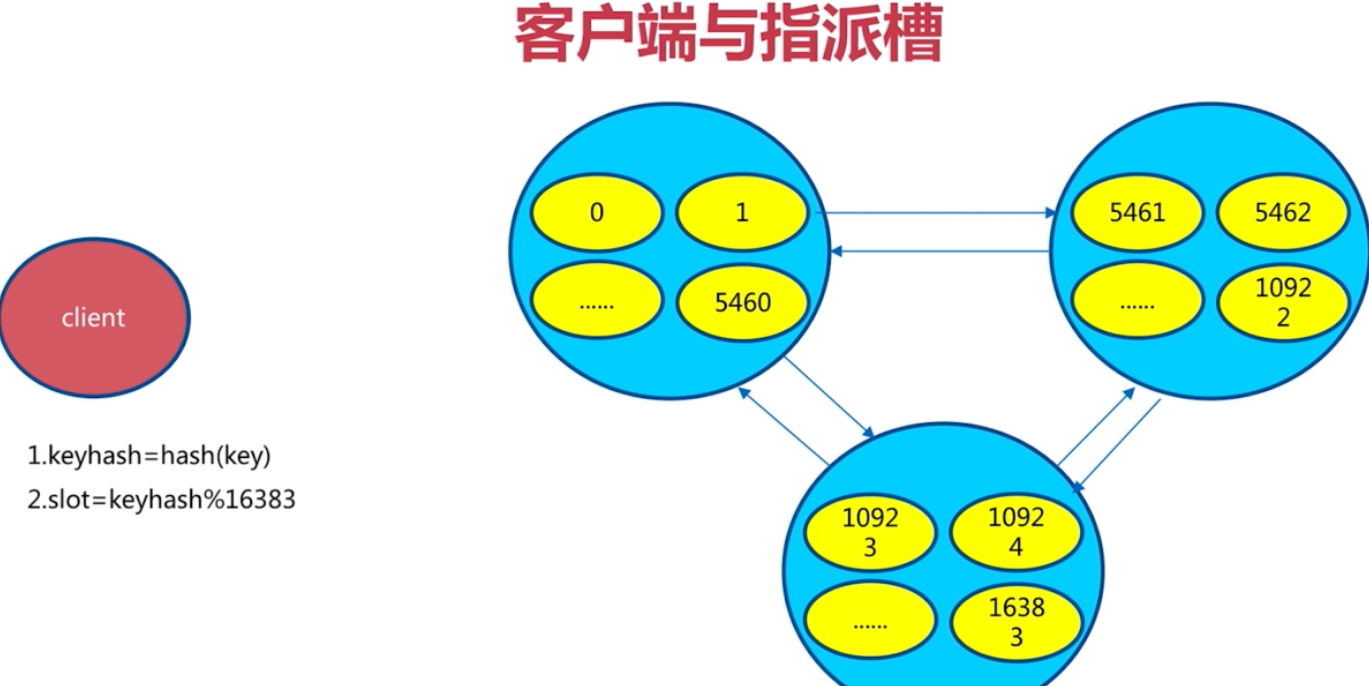
虛擬槽分割槽

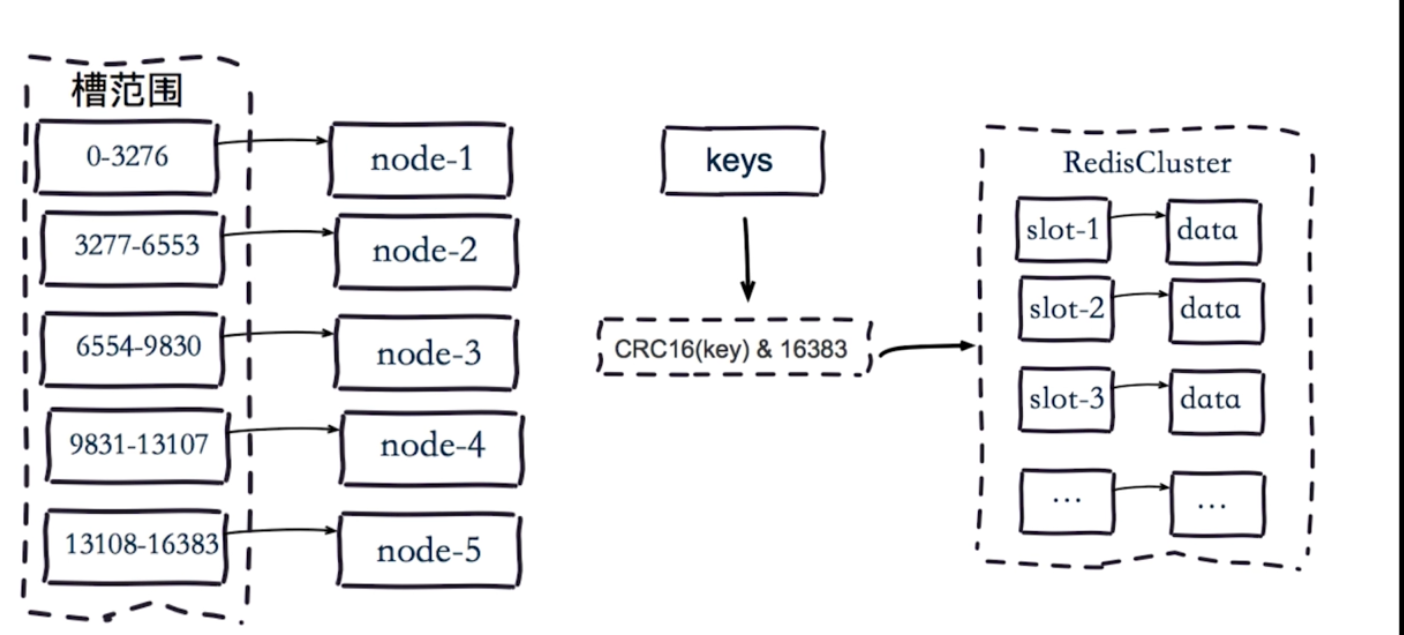
將槽範圍給不同的redis 節點去管理。
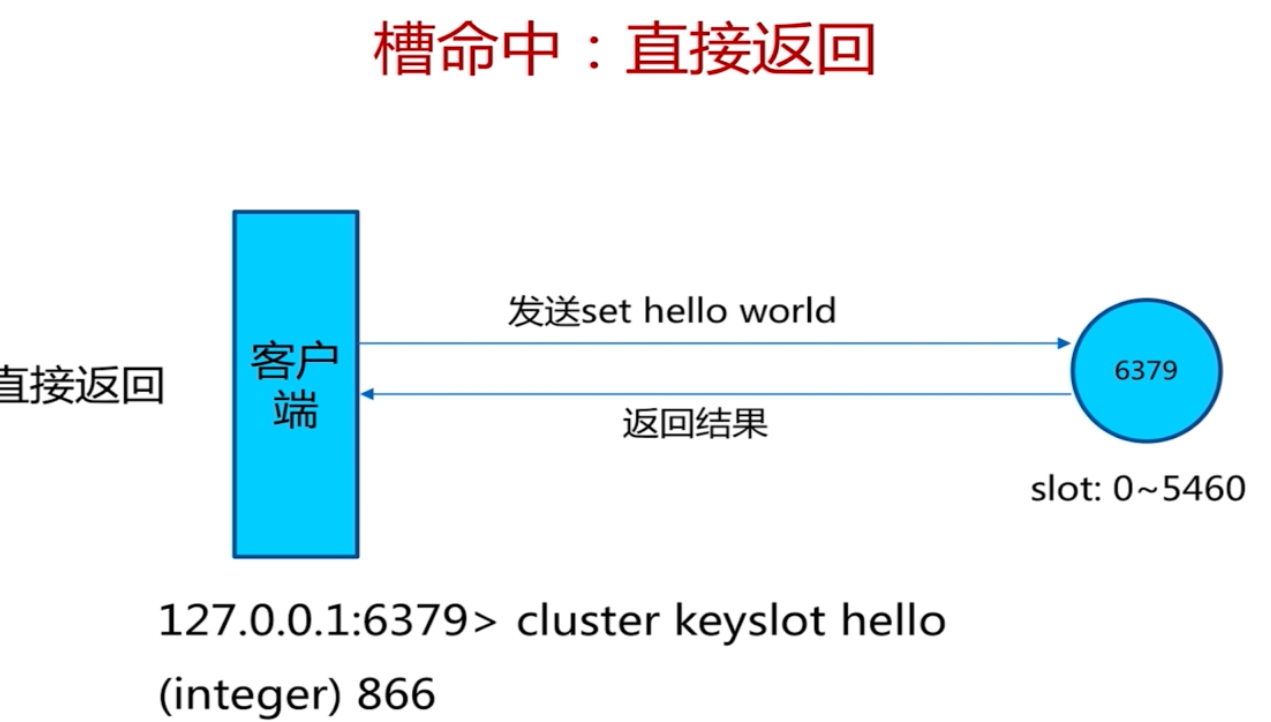
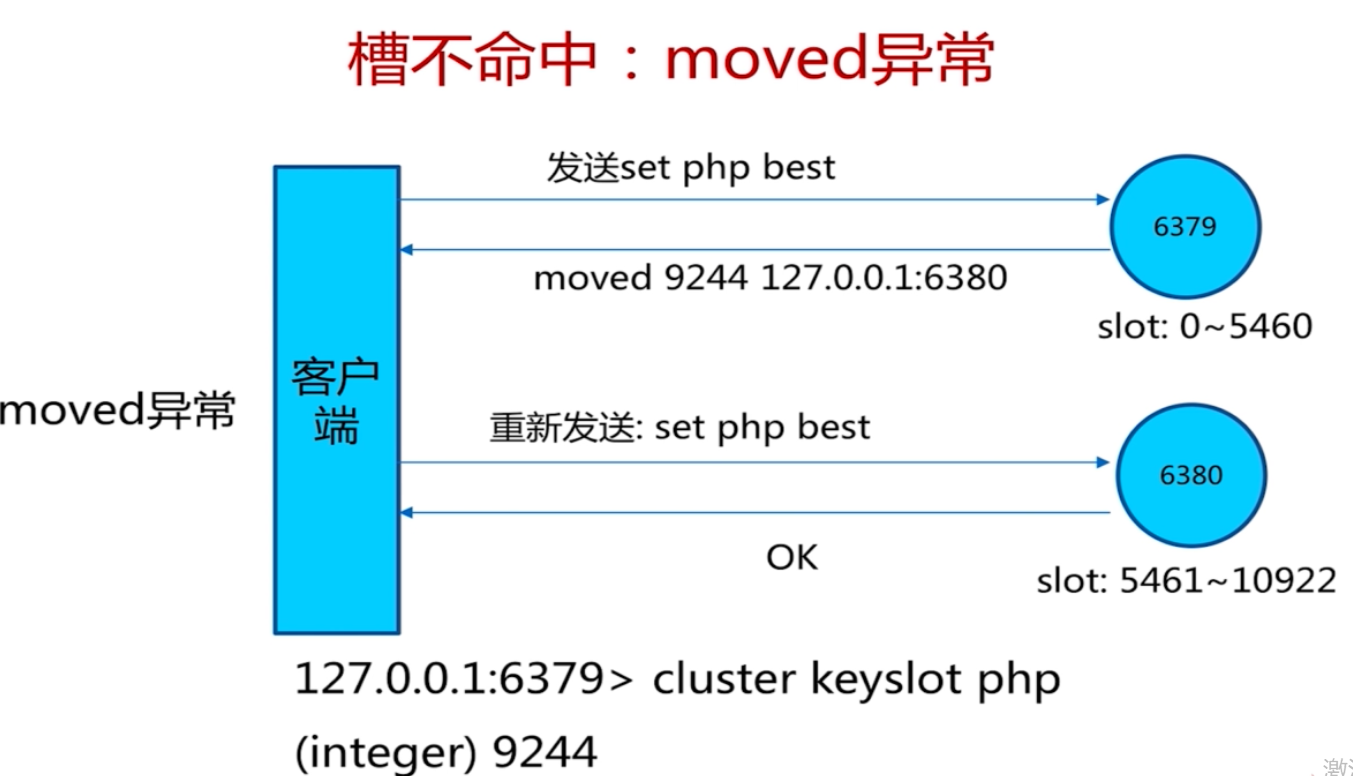
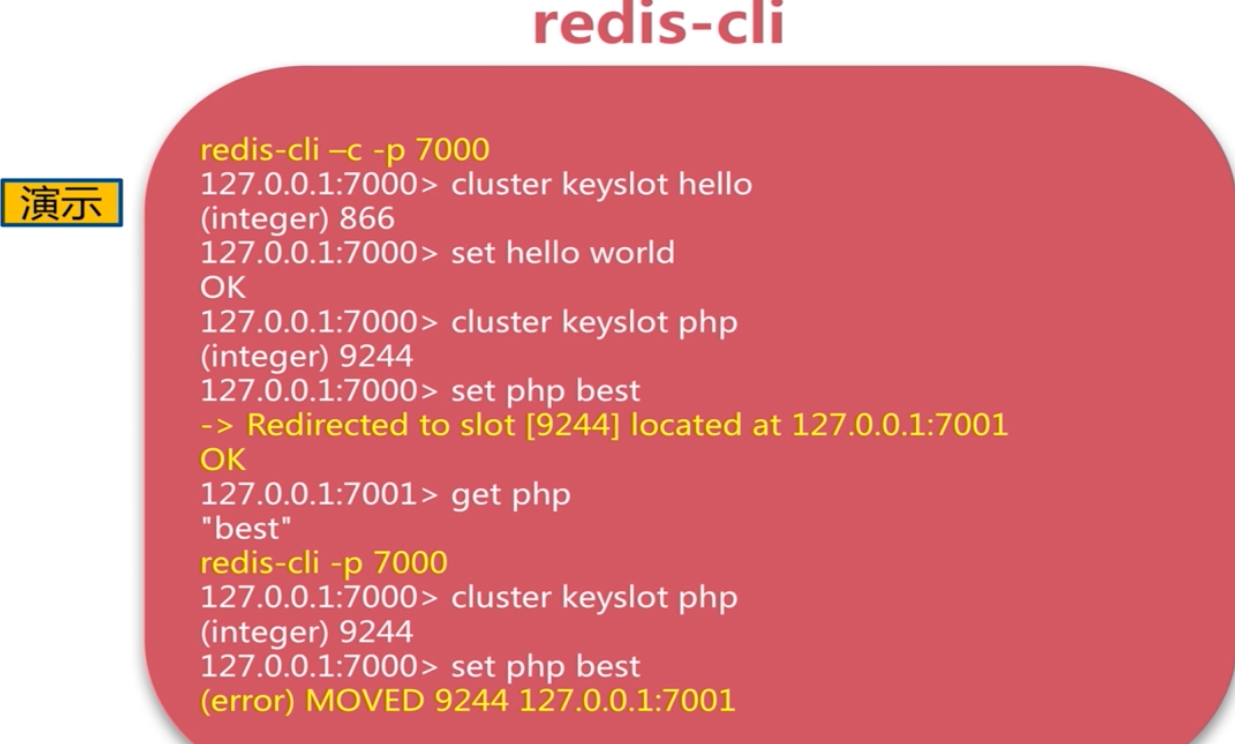
執行的時候, 使用key 去算出來去哪個節點去操作。比如取資料,
如果對應的redis 節點有資料那麼就取出來資料返回,如果發現 沒有資料,那麼其會知道應該去哪個節點去取數,然後再去對應redis節點去執行取數即可。
節點: cluster-enable:yes 就是以叢集方式 啟動
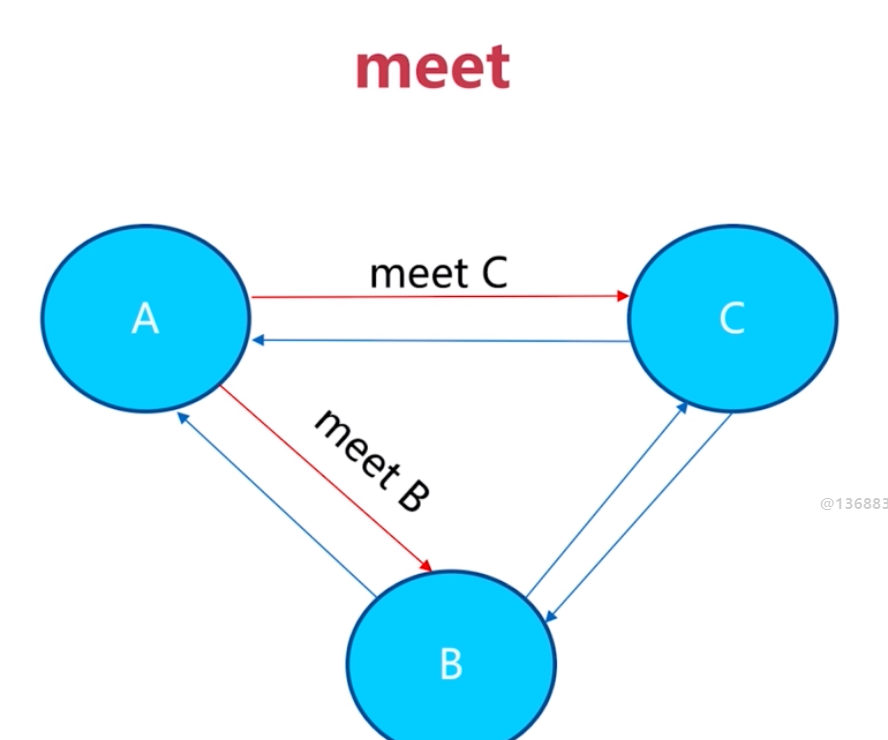
即節點之間可以互相通訊,所以節點共享資訊
特性:
1, 複製:每個 節點 都是 可以 有主從的,且 主掛了從可以變為主節點
2. 高可用
3. 分片 : 即有多個主節點,可以進行 讀寫分離
安裝配置
原生命令安裝


開啟節點和 開啟redis 命名一樣, 比如 redis-server redis-conf 一樣


cluster-require-full-coverage yes 即當某一個節點掛了,那麼整個叢集都不對外提供服務。一般是no


redis-trib 搭建分散式叢集
1, 需要ruby 環境




如果ruby 以上安裝不成功, 就是 ruby -v 沒成功
就可以使用 另一種方式去安裝
sudo yum install rubyhttp://www.ruby-lang.org/zh_cn/documentation/installation/#yum

replicats 1 代表 每個叢集 開啟一個對應的從節點
./redis-trib.rb create --replicas 1 127.0.0.1:8000 127.0.0.1:8001 127.0.0.1:8002 127.0.0.1:8003 127.0.0.1:8004 127.0.0.1:8005
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
127.0.0.1:8000
127.0.0.1:8001
127.0.0.1:8002
Adding replica 127.0.0.1:8003 to 127.0.0.1:8000
Adding replica 127.0.0.1:8004 to 127.0.0.1:8001
Adding replica 127.0.0.1:8005 to 127.0.0.1:8002
總共6個然後選擇3個做主,其他做對應主的從
叢集伸縮
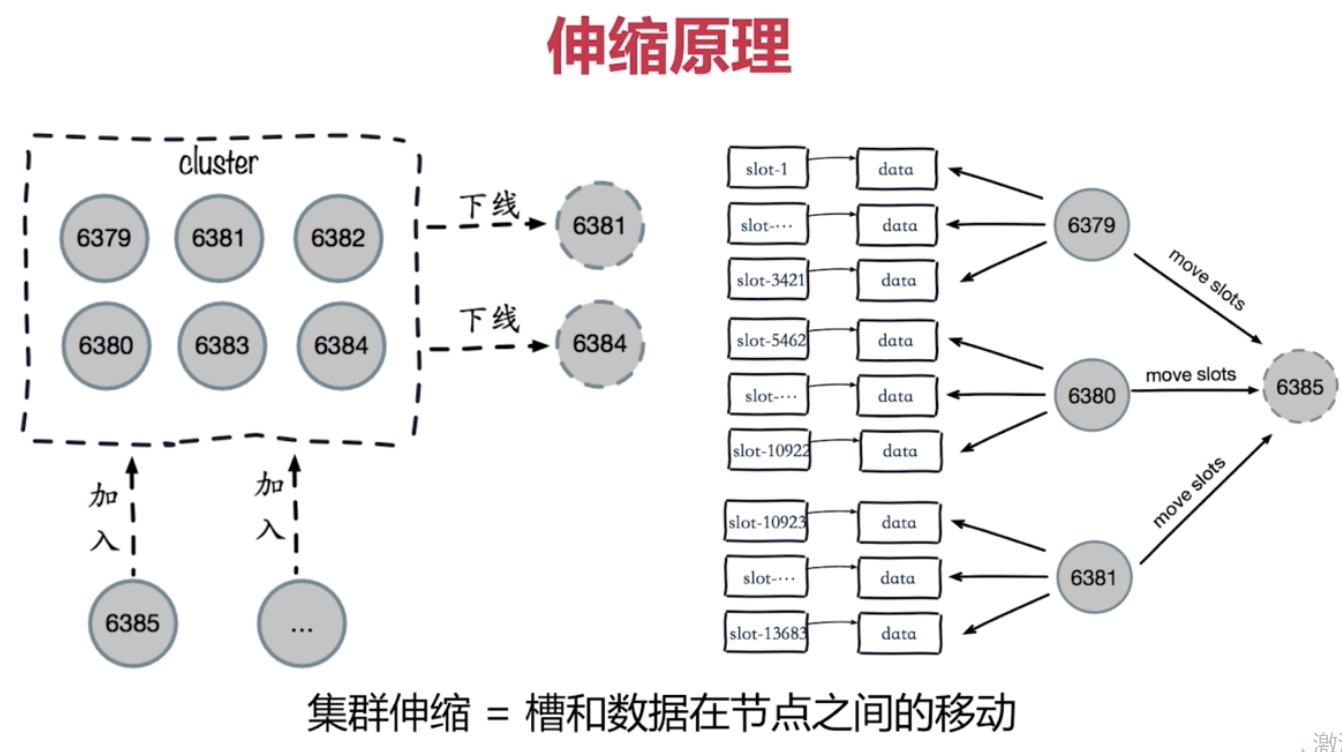
擴容: 準備新節點, 加入叢集,遷移槽和資料
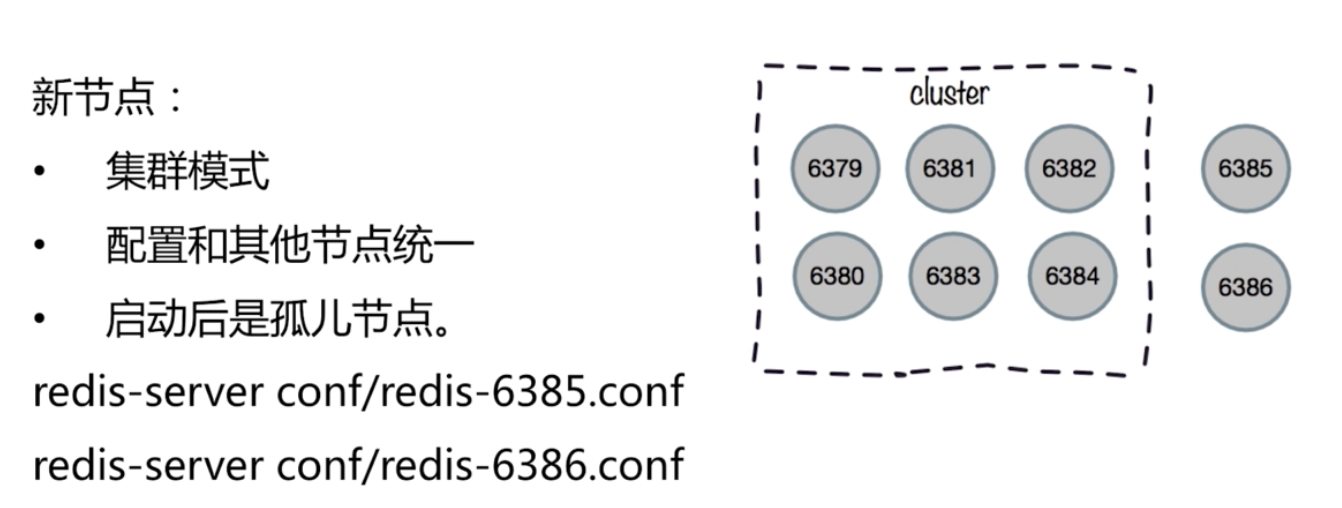
加入一個新節點,肯定要準備兩個redis了,這樣就可以做一主一從,一一對應


一般來說,都是一主兩從 。 可以做備份擴充套件與故障轉移


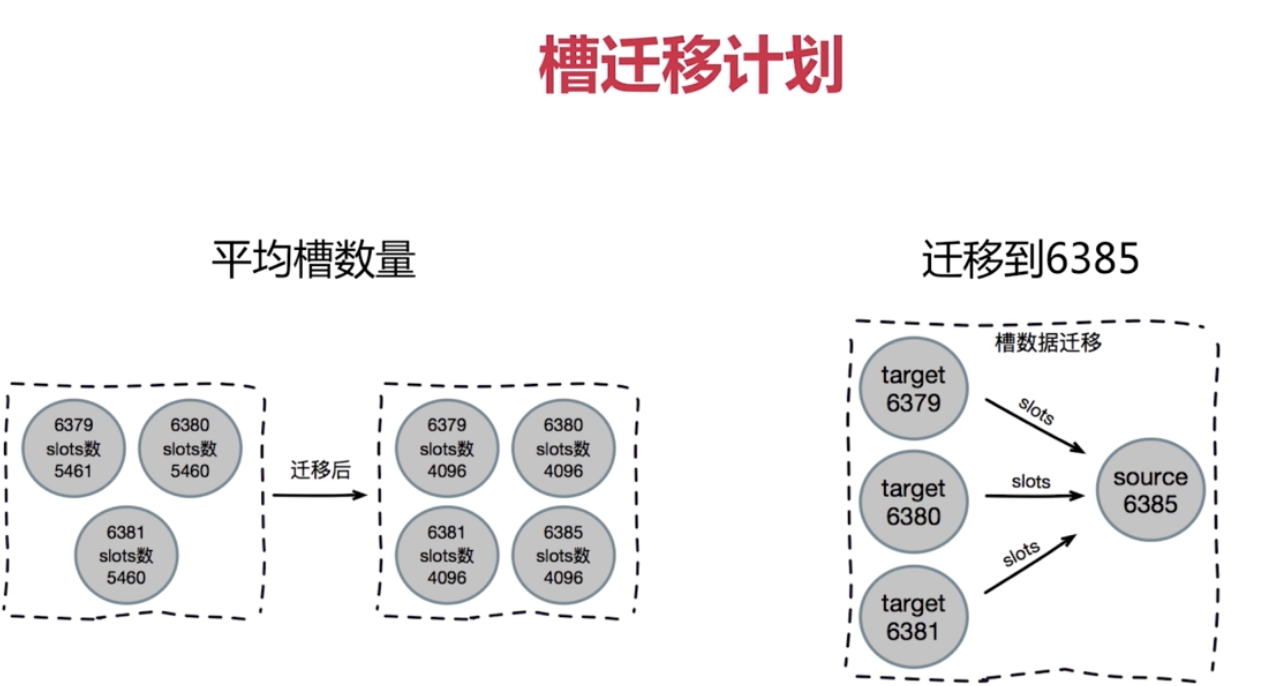

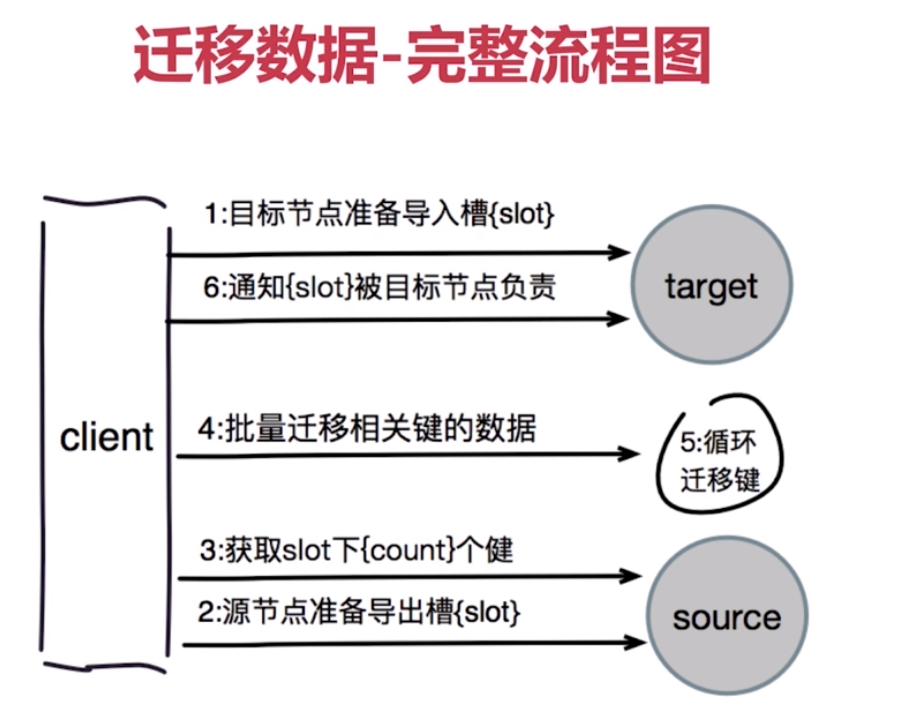
叢集收縮

槽遷移比如命令:
./redis-trib.rb reshard --from a785112f55f4415a5957689023d765eb45613cb7 --to 2dd4ef24bd12bdd1fb54337ad2516240925412ae --slots 2 127.0.0.1:8006
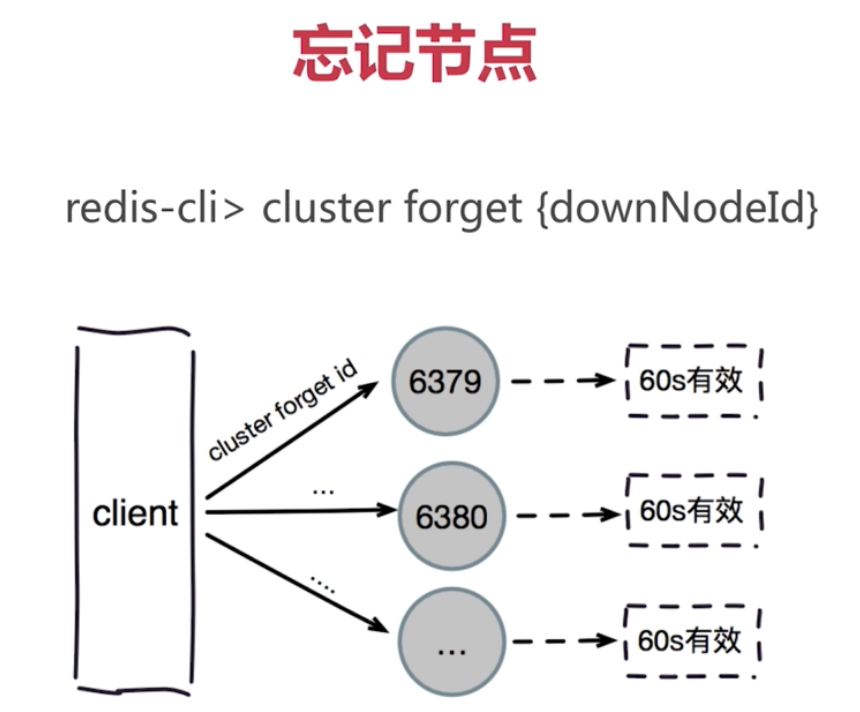
忘記節點可以使用 redis-trib.rb 命名去做節點的下線
./redis-trib.rb del-node 127.0.0.1:8000 a785112f55f4415a5957689023d765eb45613cb7
客戶端路由
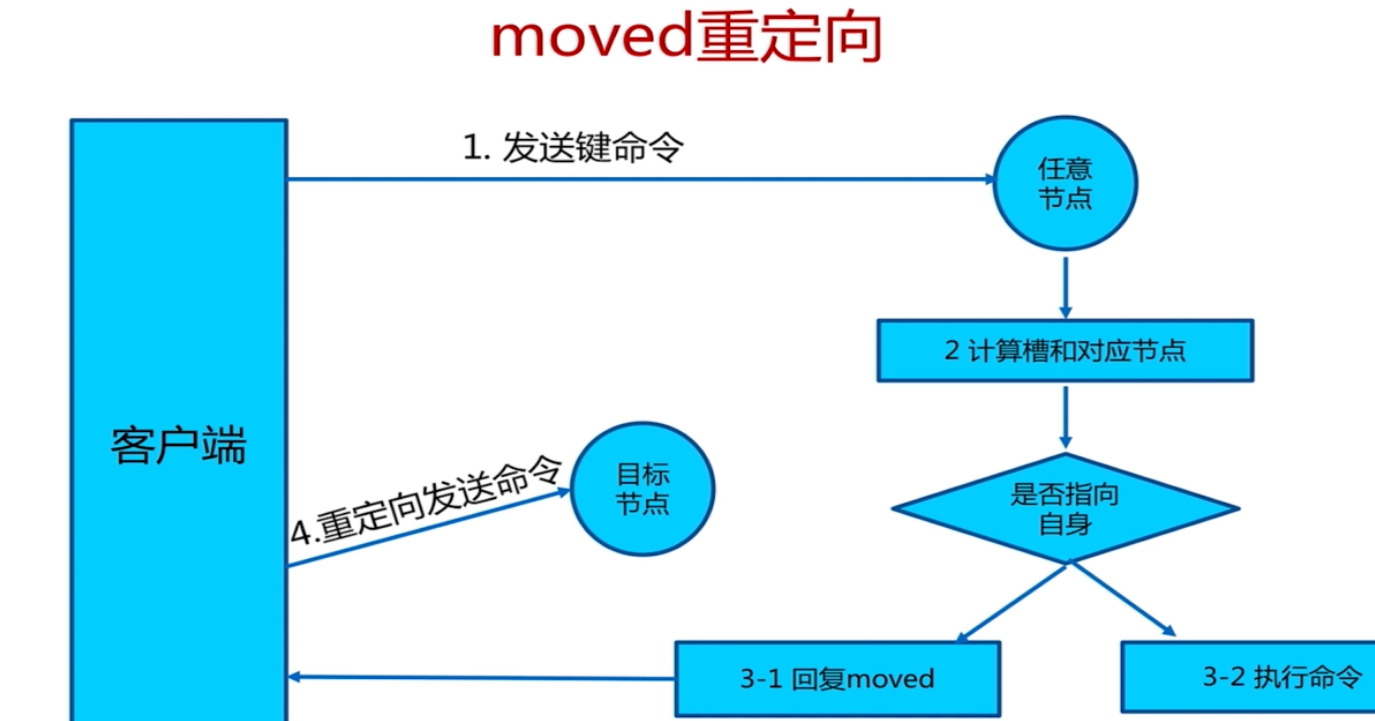
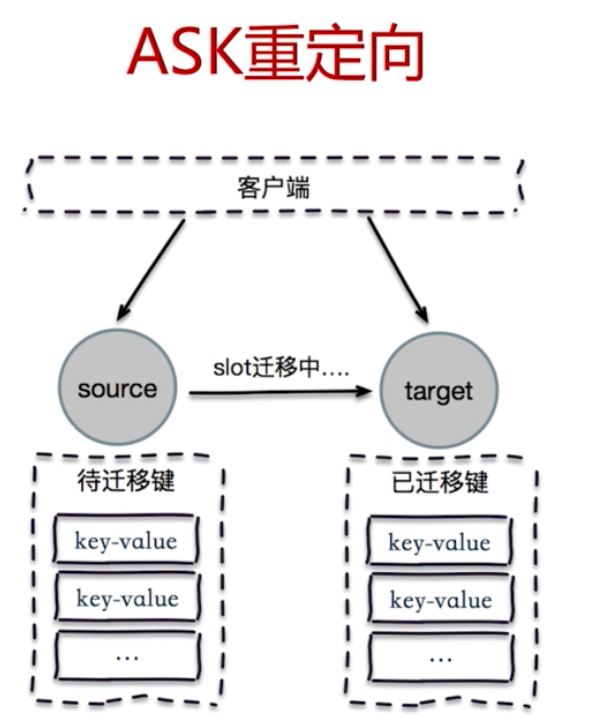


smart客戶端

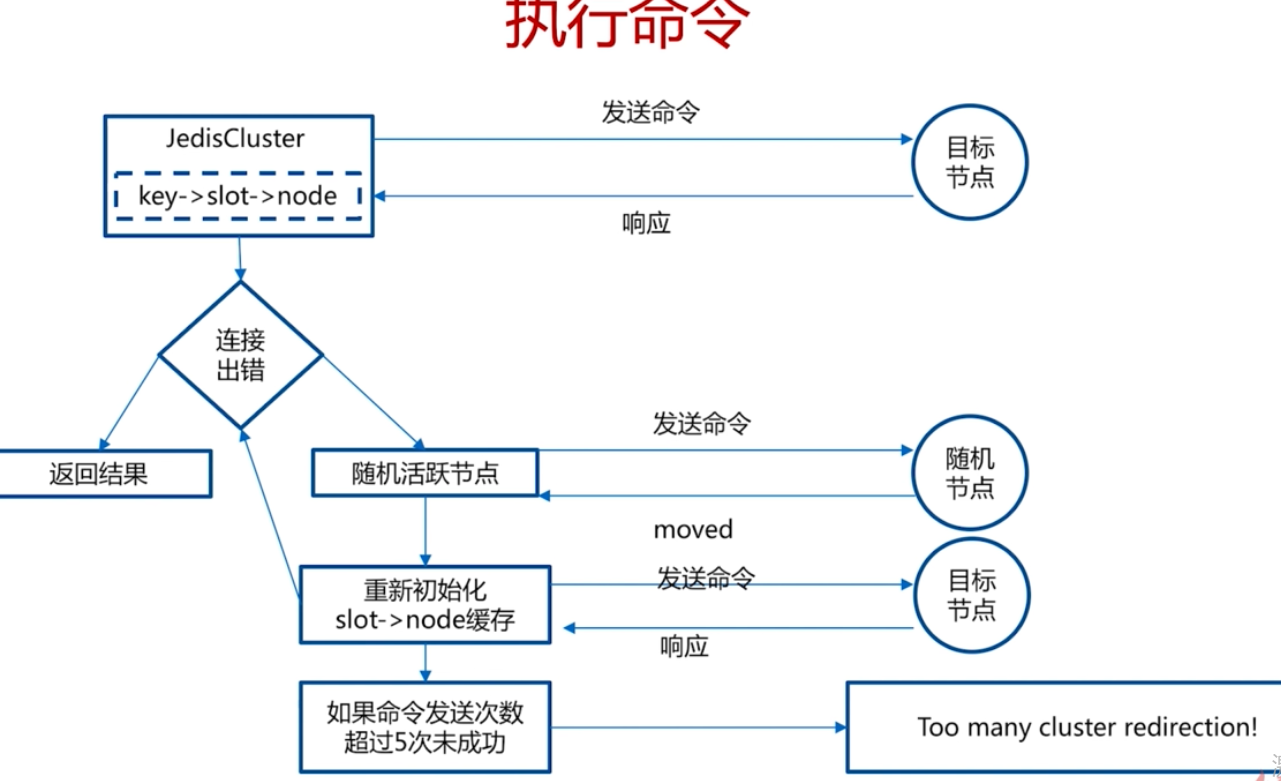


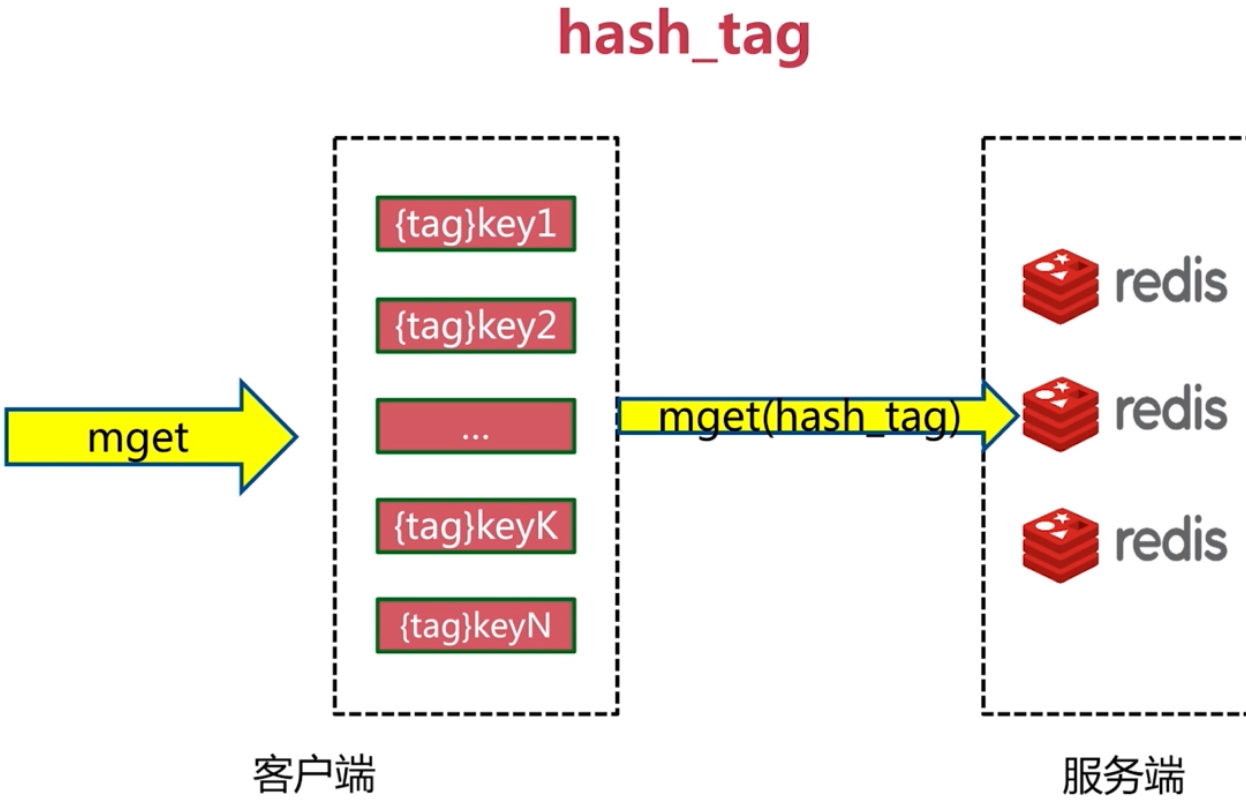
多節點操作

批量操作優化

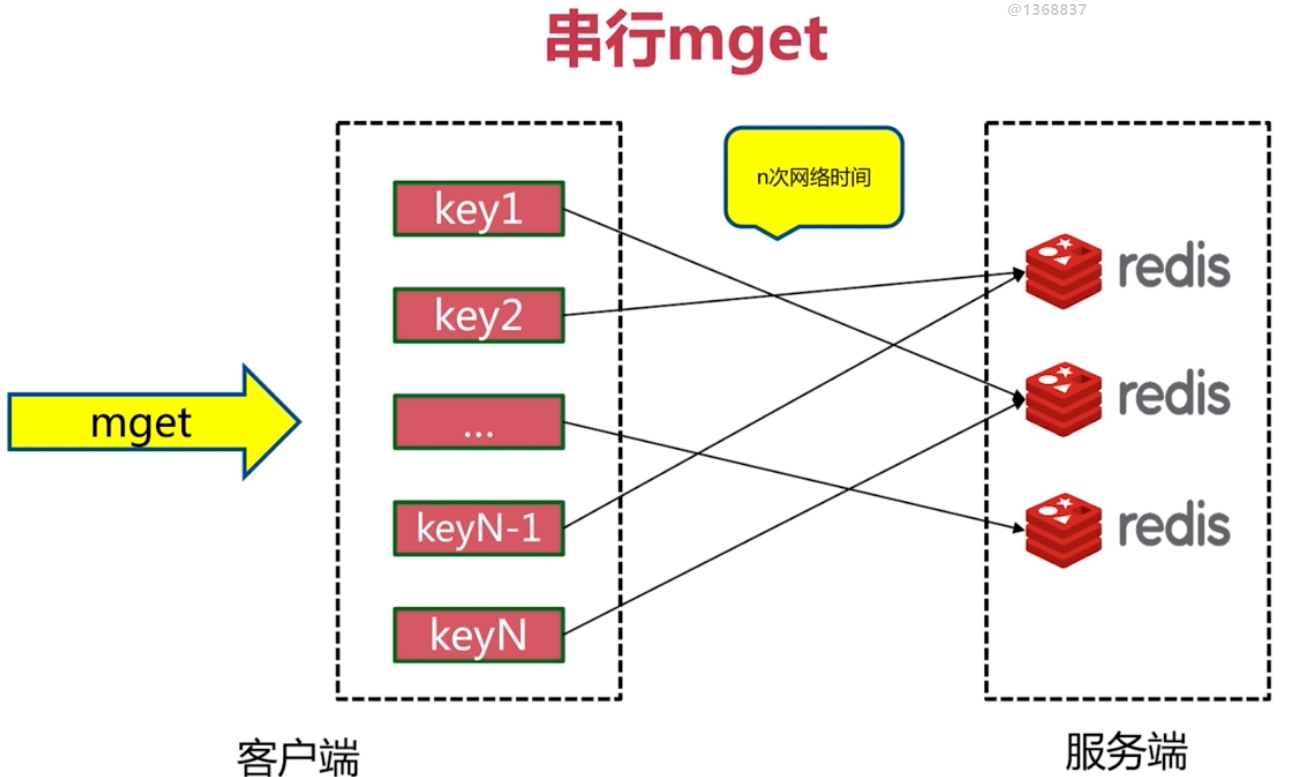
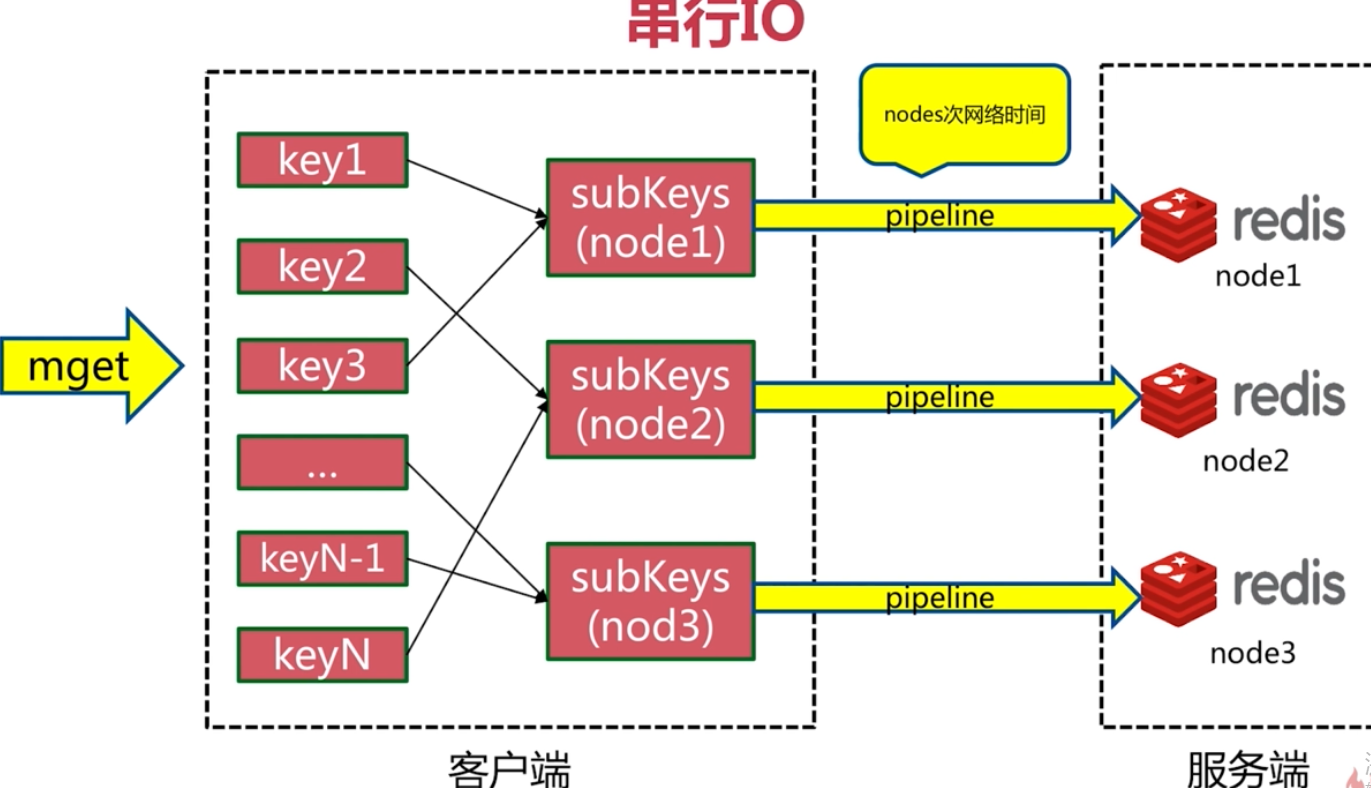
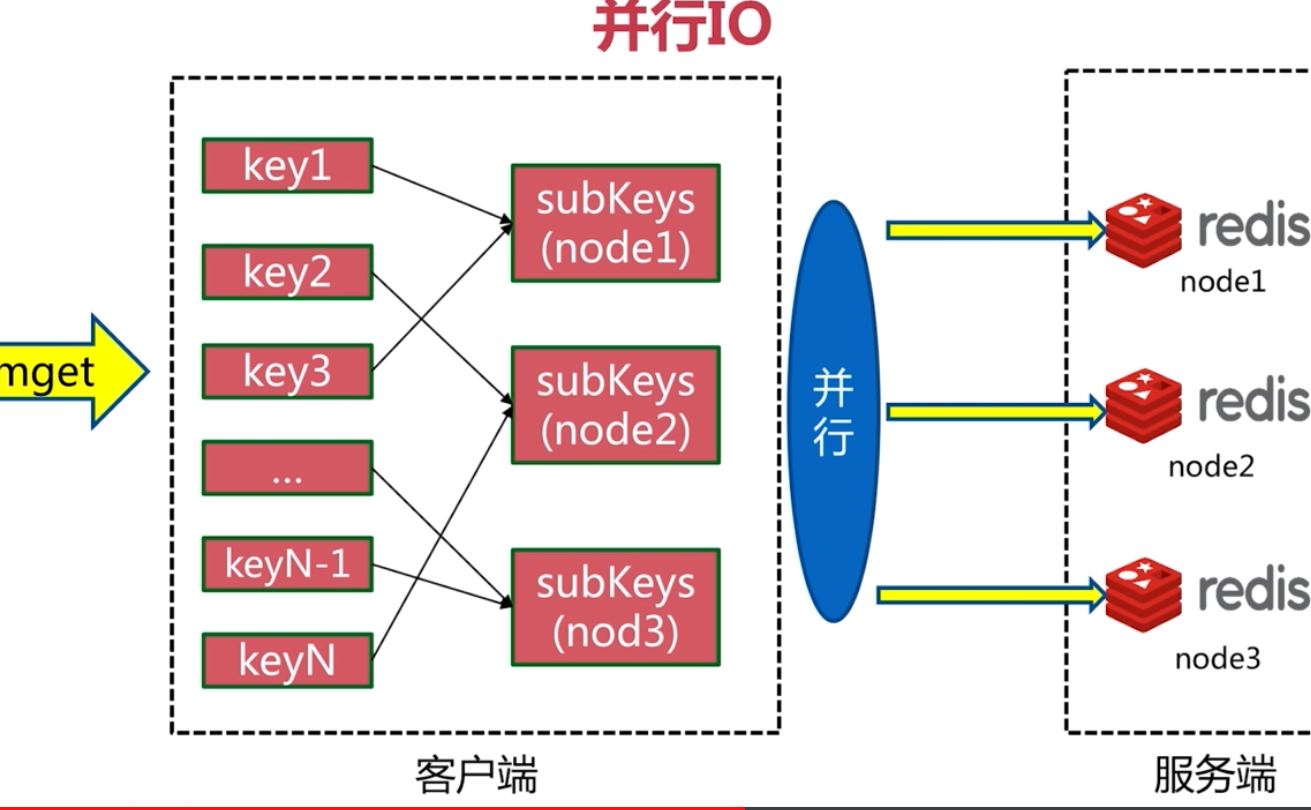
並行執行只需要一次網路時間

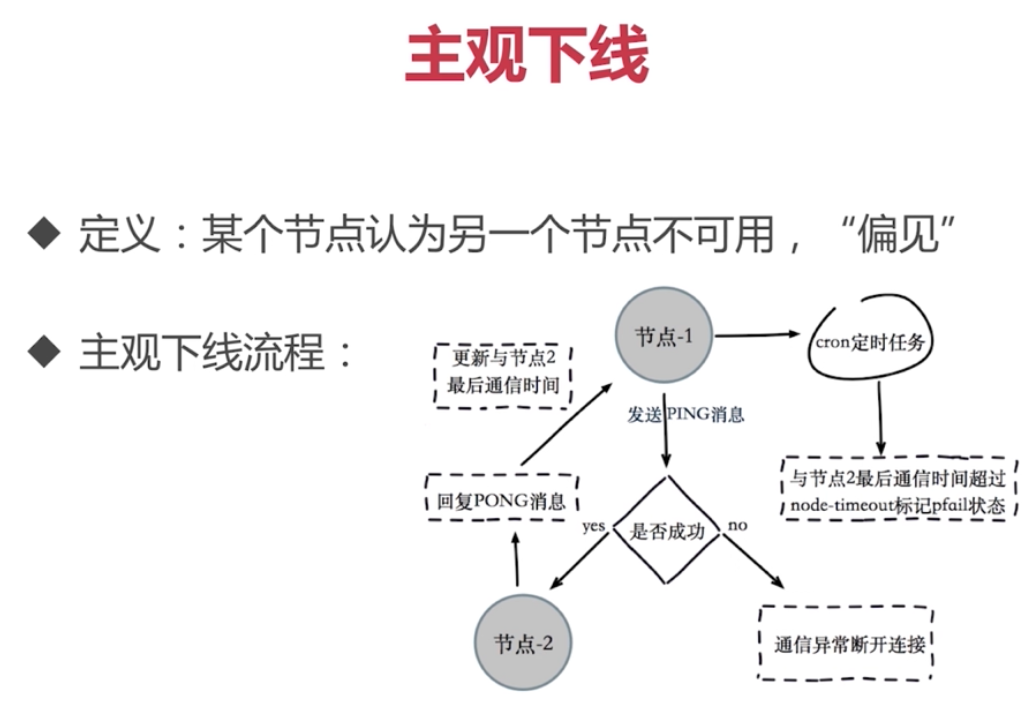
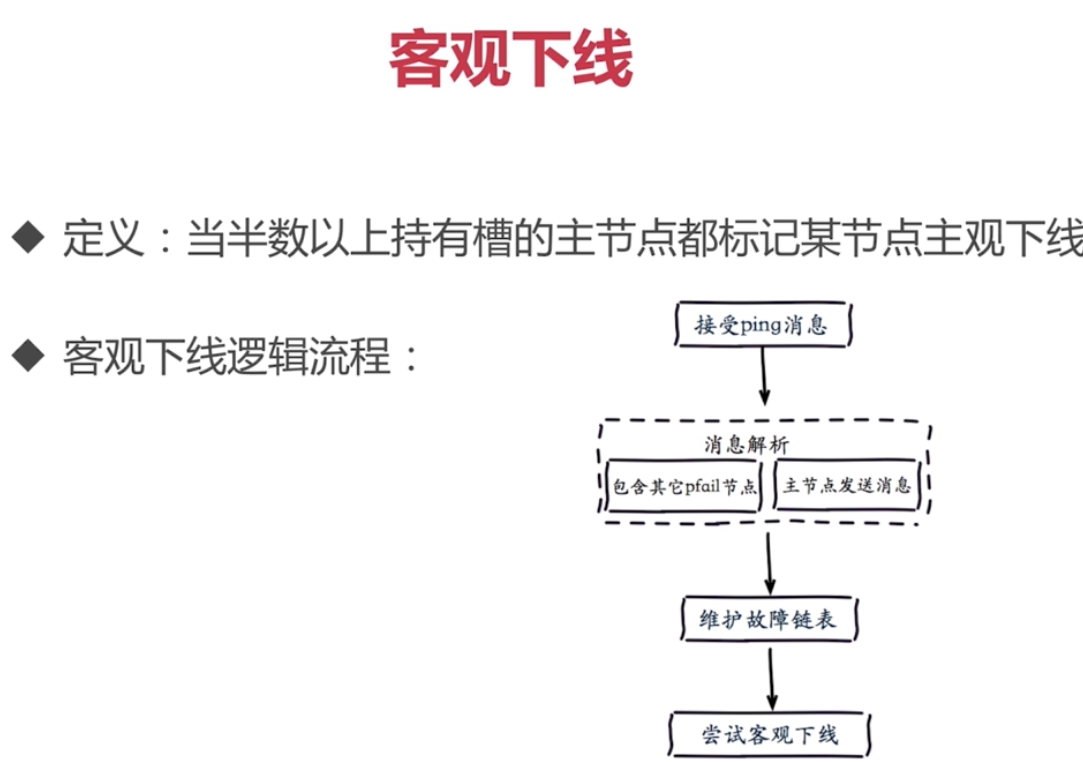
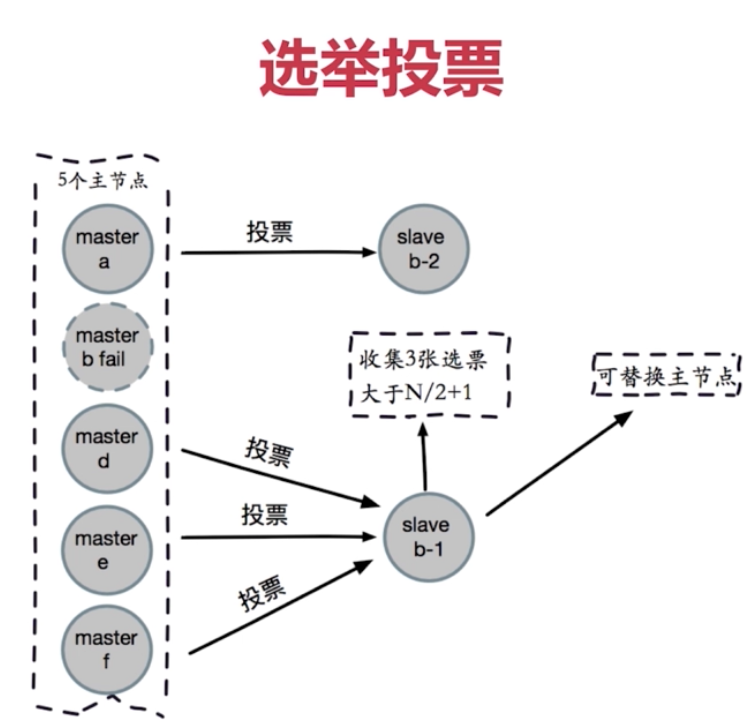
故障轉移






運維常見問題

頻寬消耗
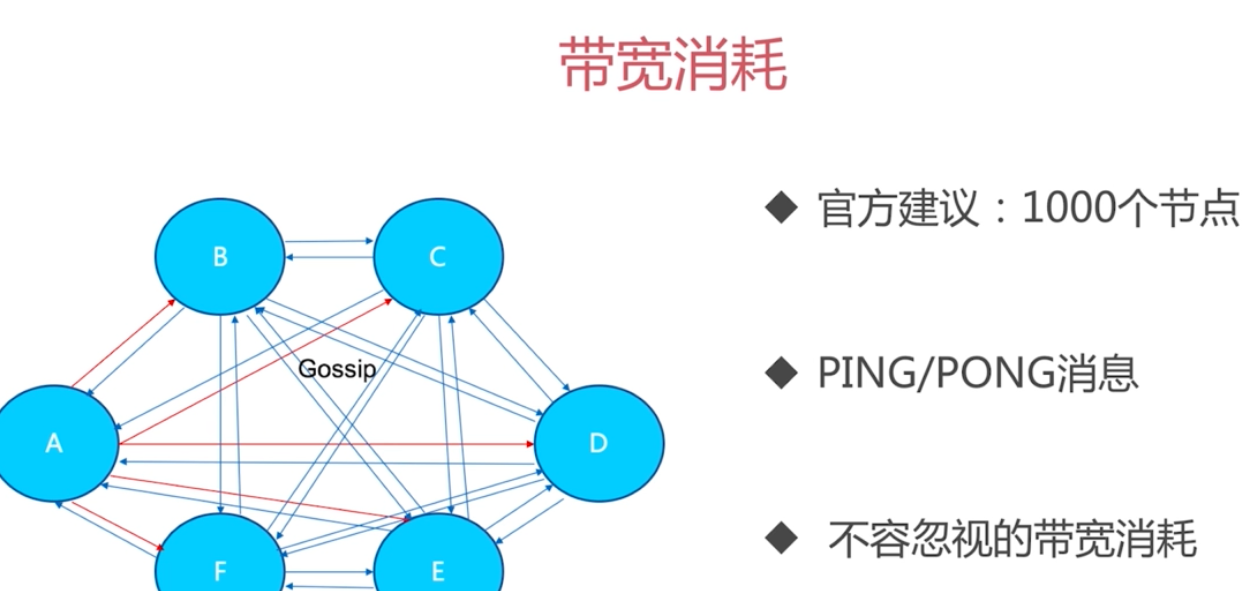
官方建議叢集節點不要超過1000個



叢集資料傾斜






讀寫分離


redis cluster 不建議使用 讀寫分離
資料遷移

分散式叢集與單機



快取使用與優化
收益

成本

使用場景

快取更新策略

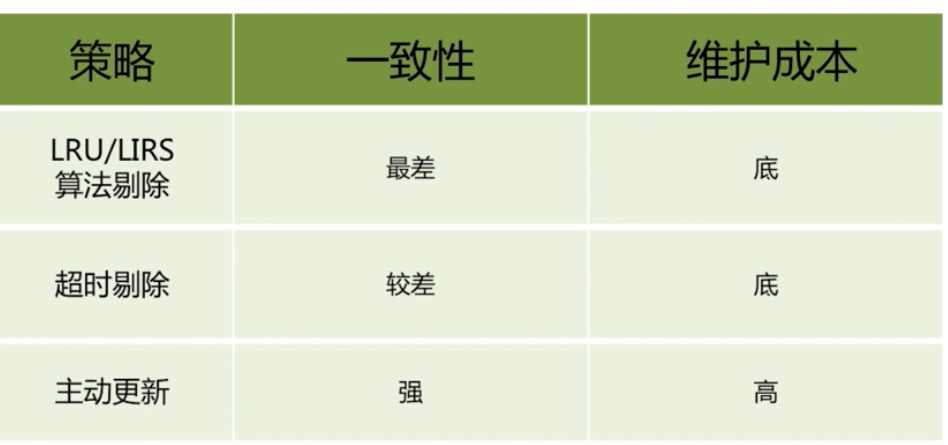

快取粒度


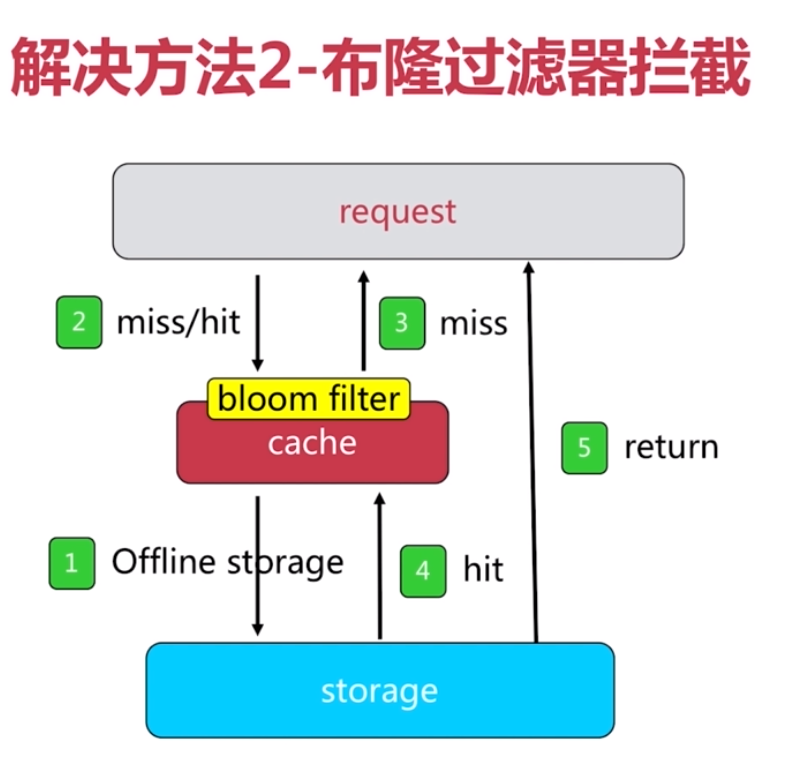
快取穿透


解決
1. 快取空物件

不一致的話,可以 使用訊息佇列重新整理快取,最終一致
快取雪崩
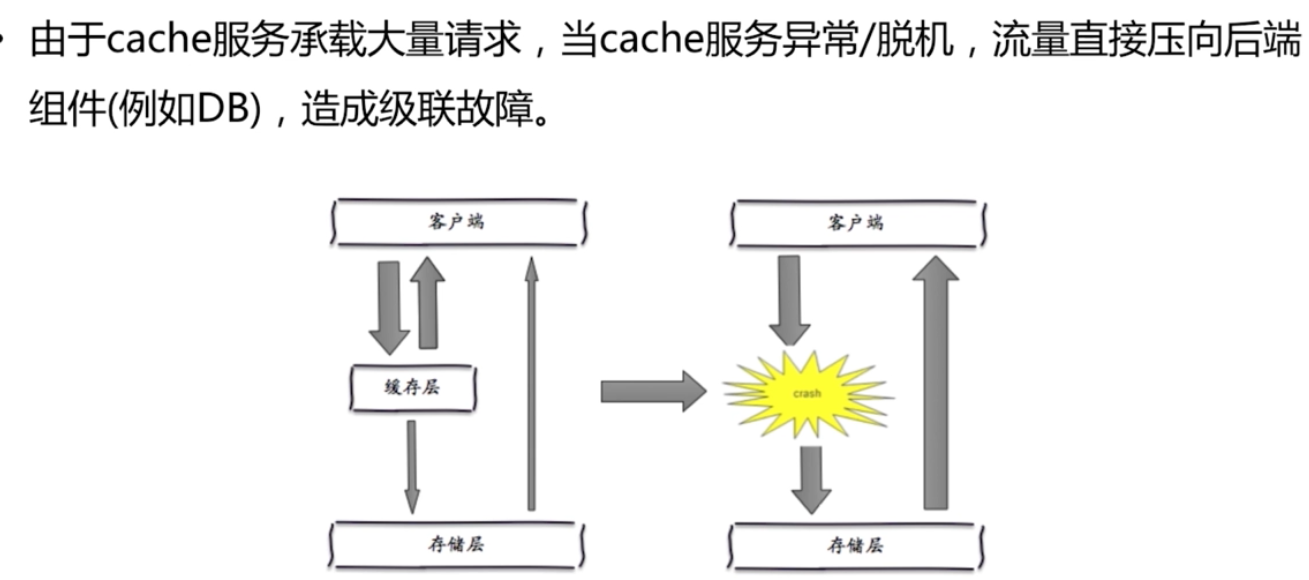
優化

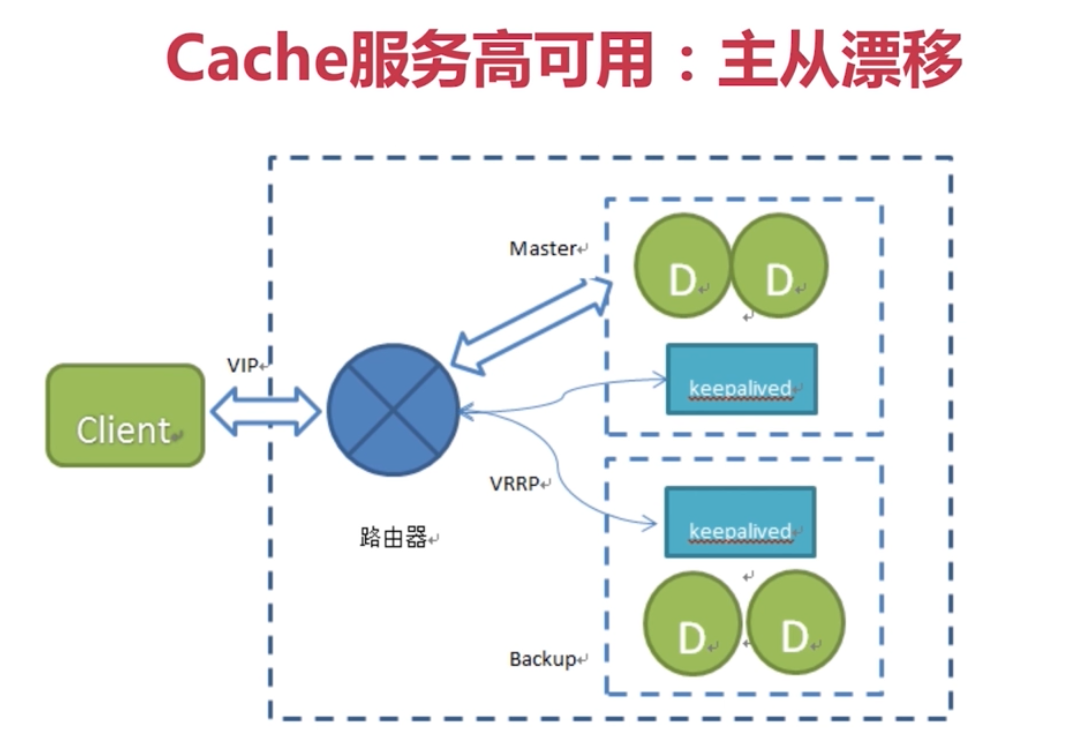
無底洞問題


更多機器!= 更高的效能, 是不一定的。
批量介面需求 等(mget,mset)
資料增長與水平擴充套件需求
優化IO

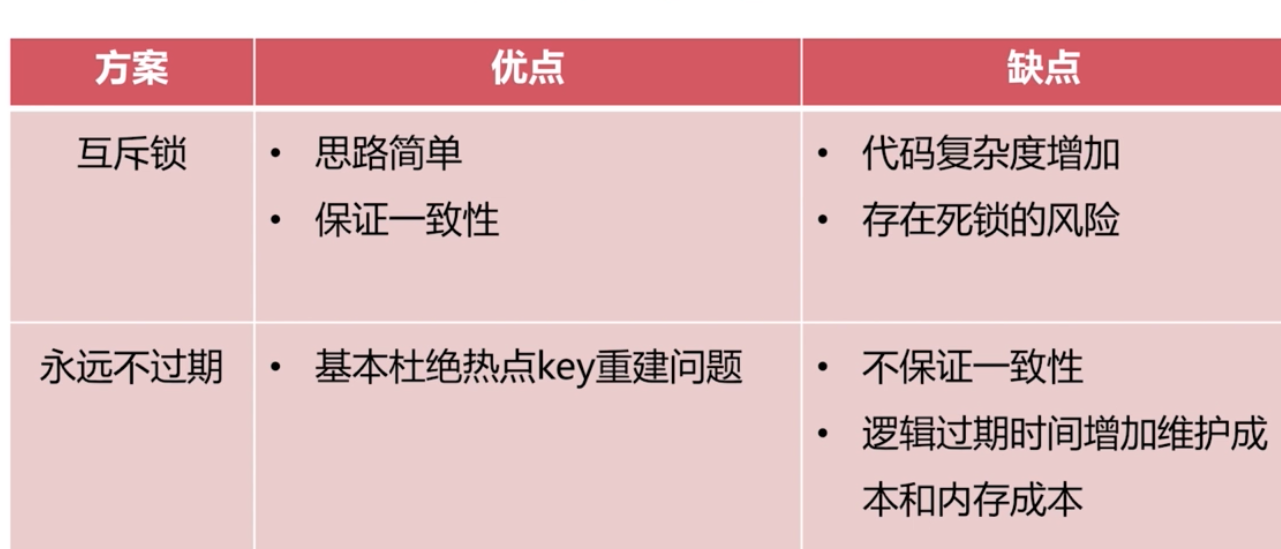
熱地key重建優化
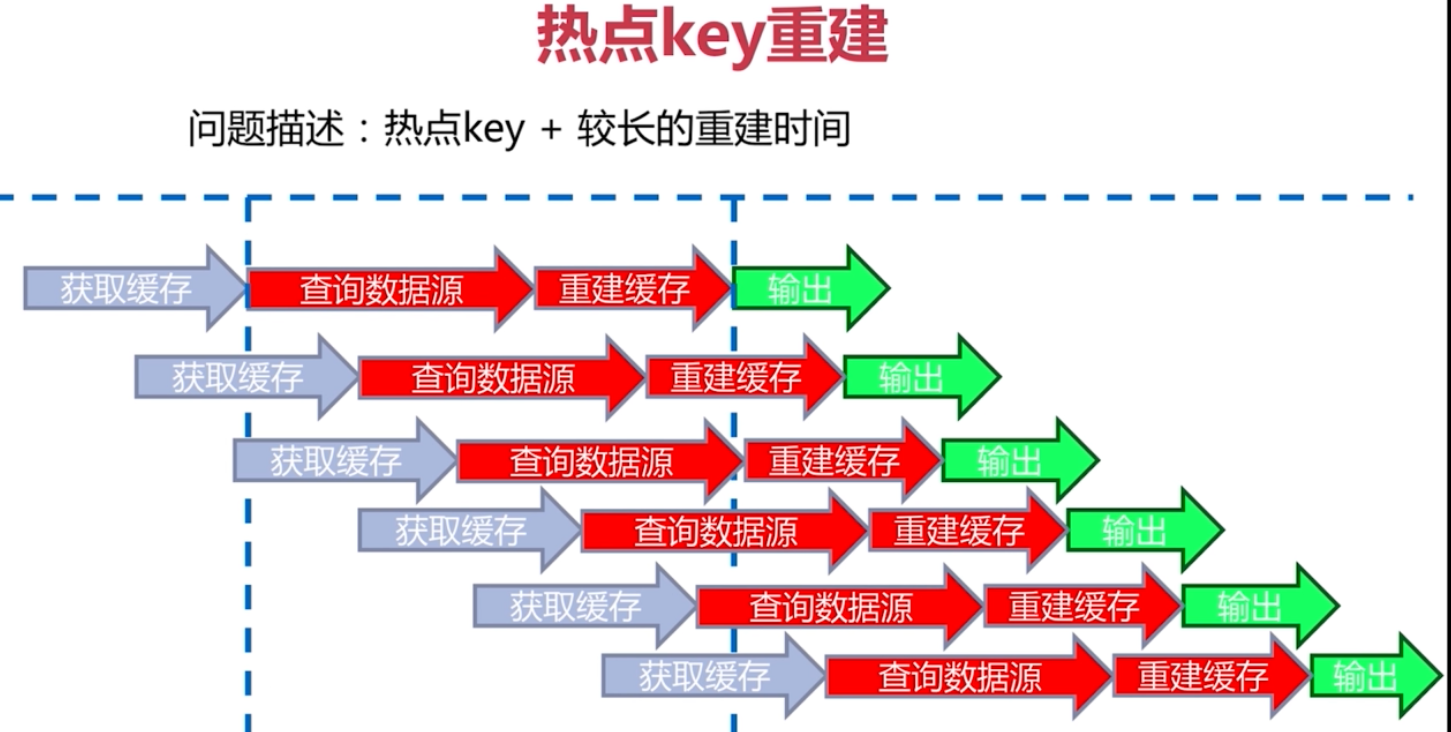

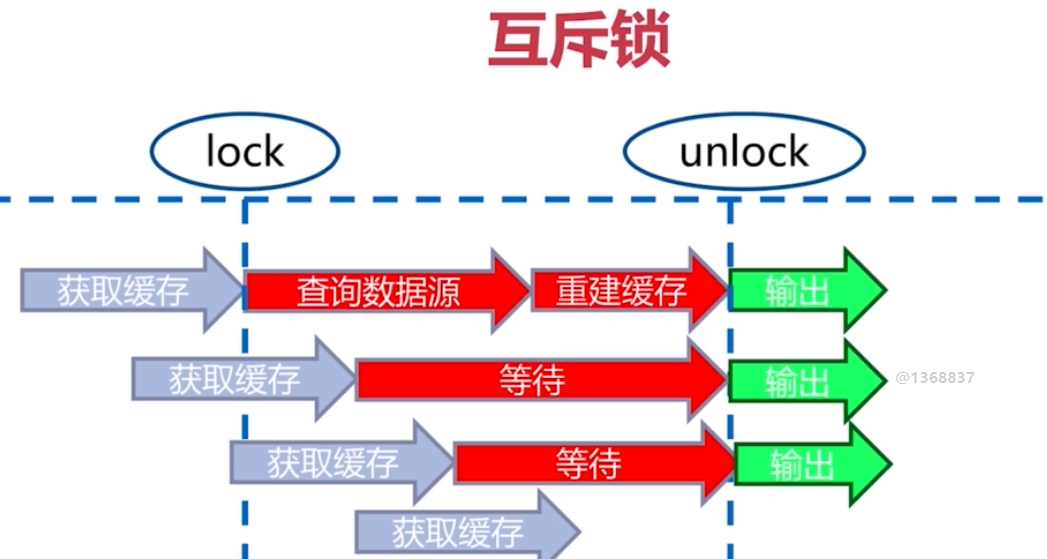
就是有 執行緒等待的問題

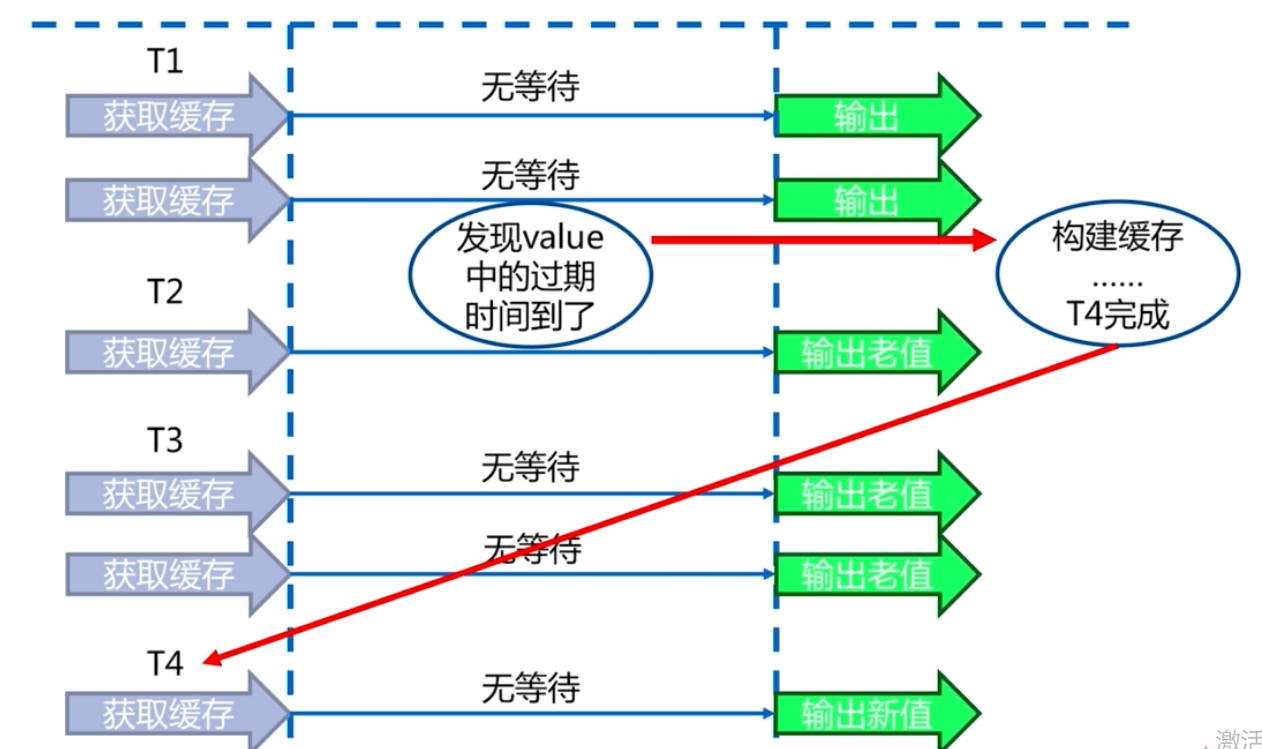
永不過期


Redis雲平臺CacheCloud



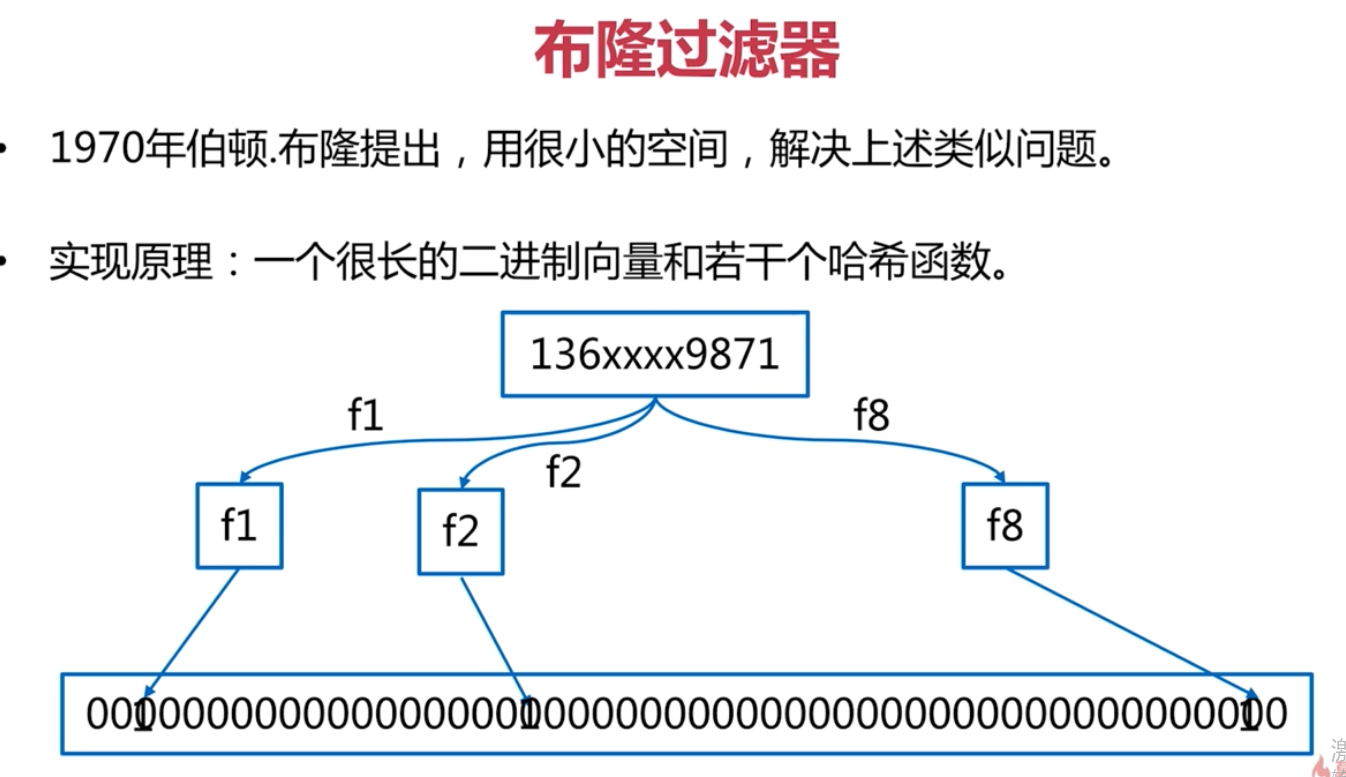
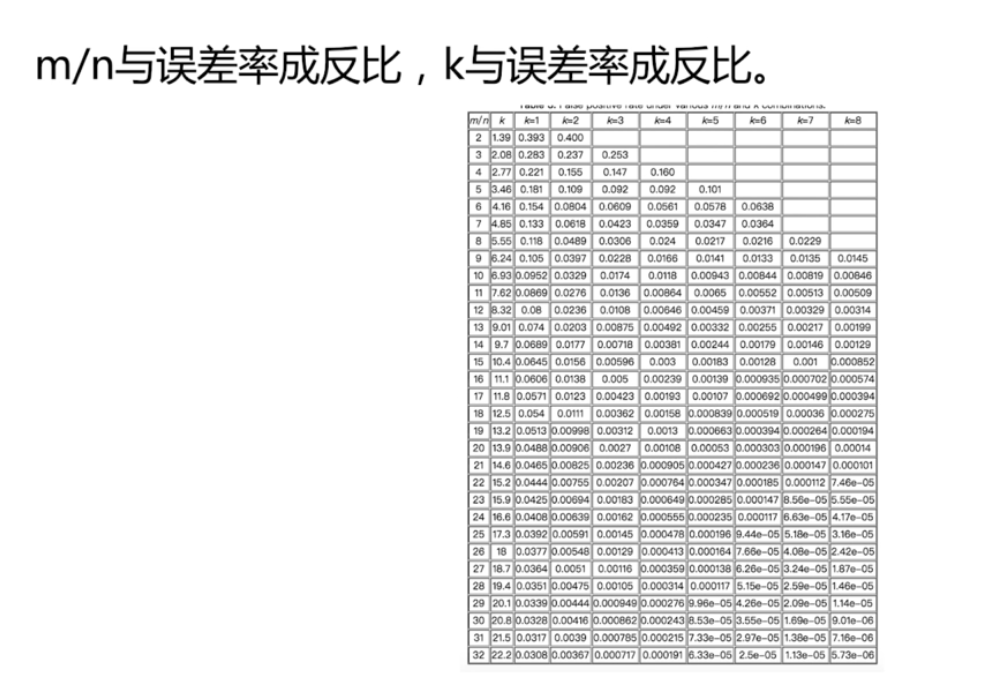
redis 分散式布隆過濾器

所以用布隆過濾器就適合。



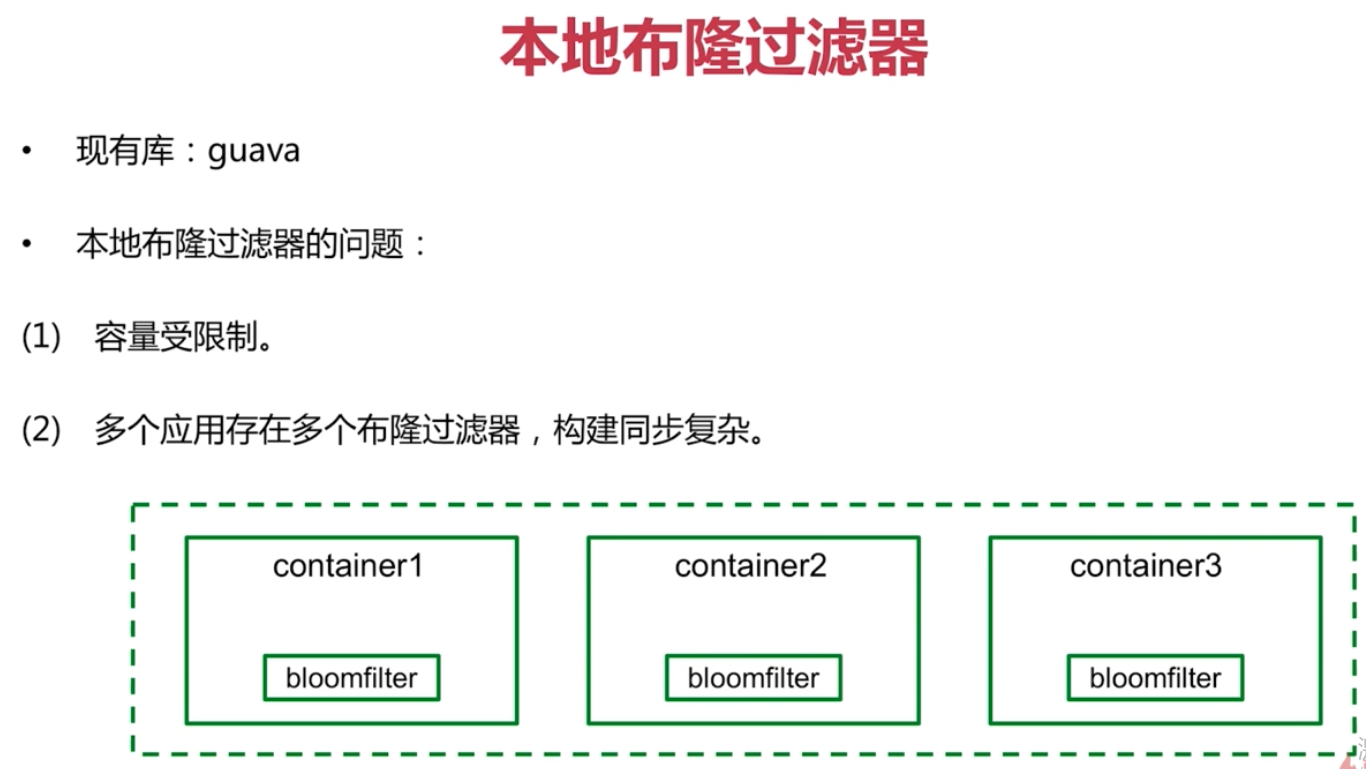
本地布隆過濾器
http://ifeve.com/google-guava-hashing/
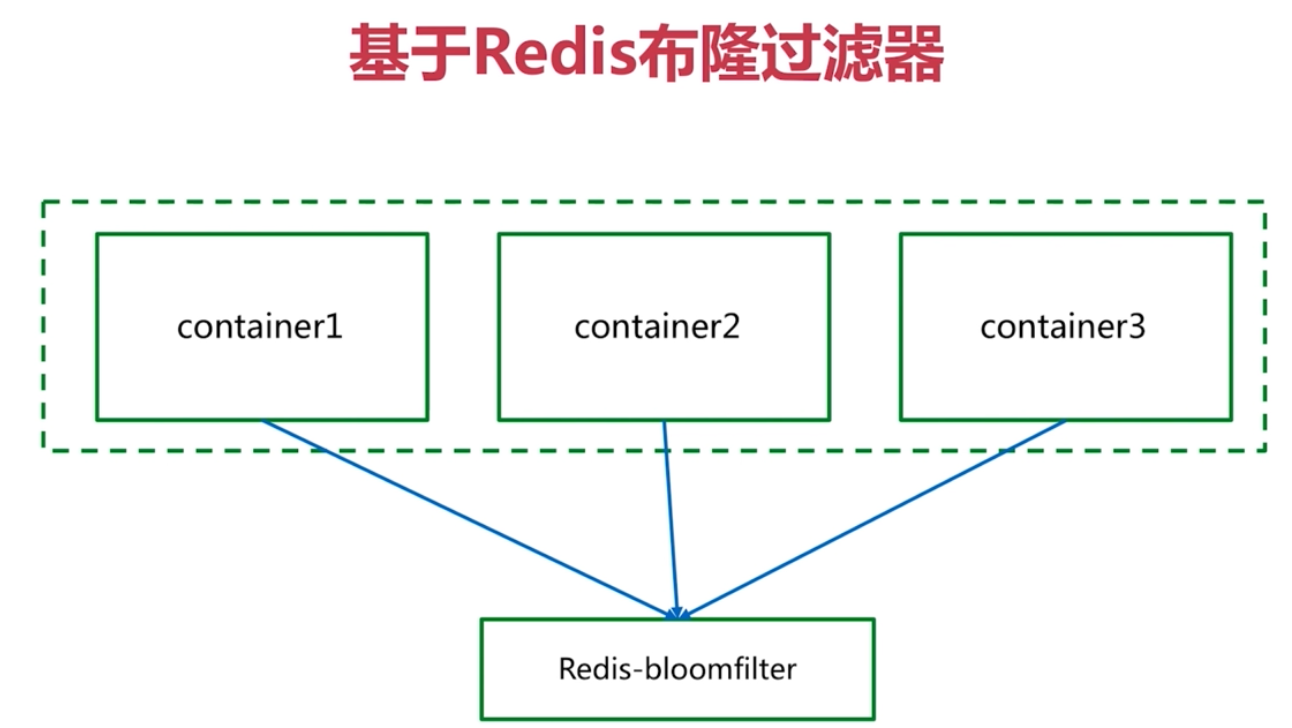

分散式布隆過濾

redis 開發規範
key 設計
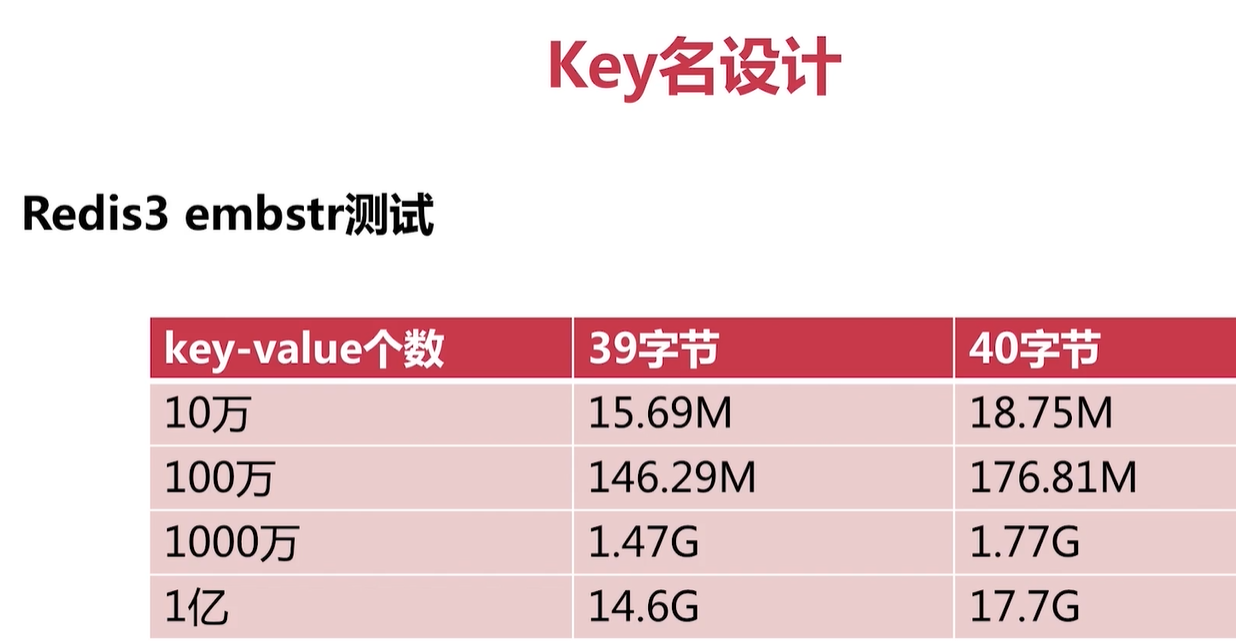
value 設計

bigkey





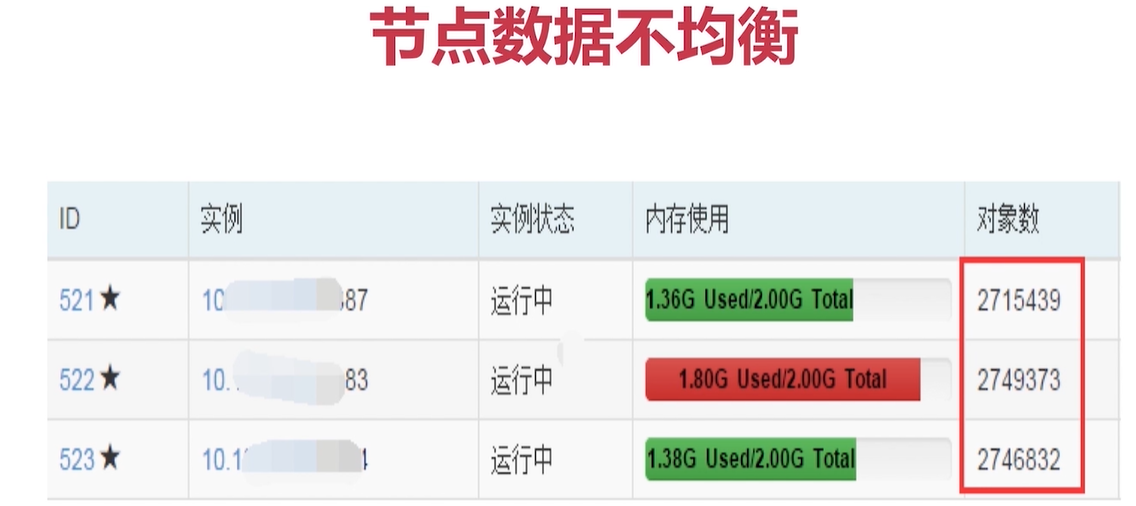
 序列化消耗太多CPU
序列化消耗太多CPU


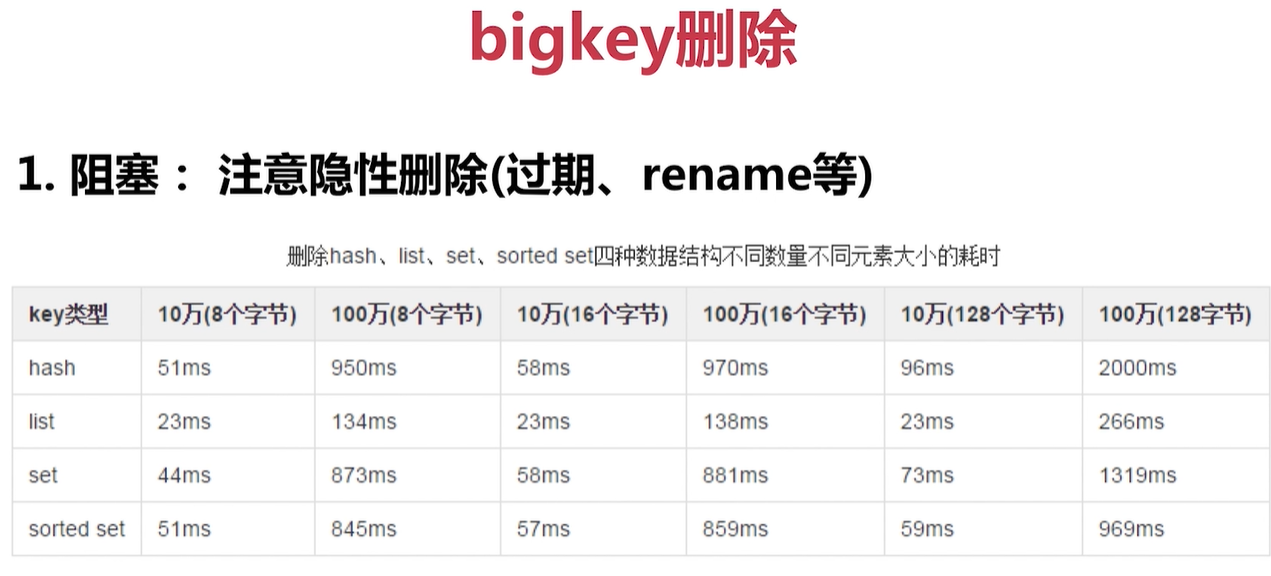
bigkey 越大,刪除越慢

lazy delete 不會阻塞 redis
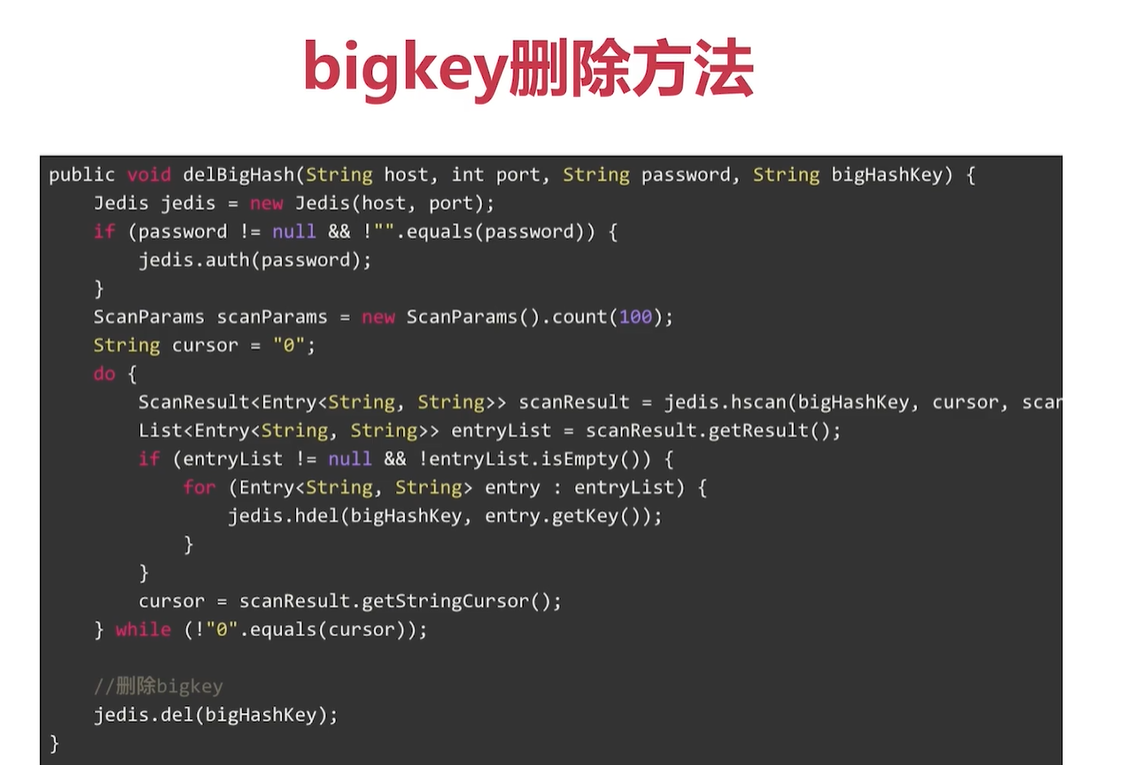
先刪除 小內容,最後整個刪除。比如 map 先 將內容都刪除,再將map 刪除



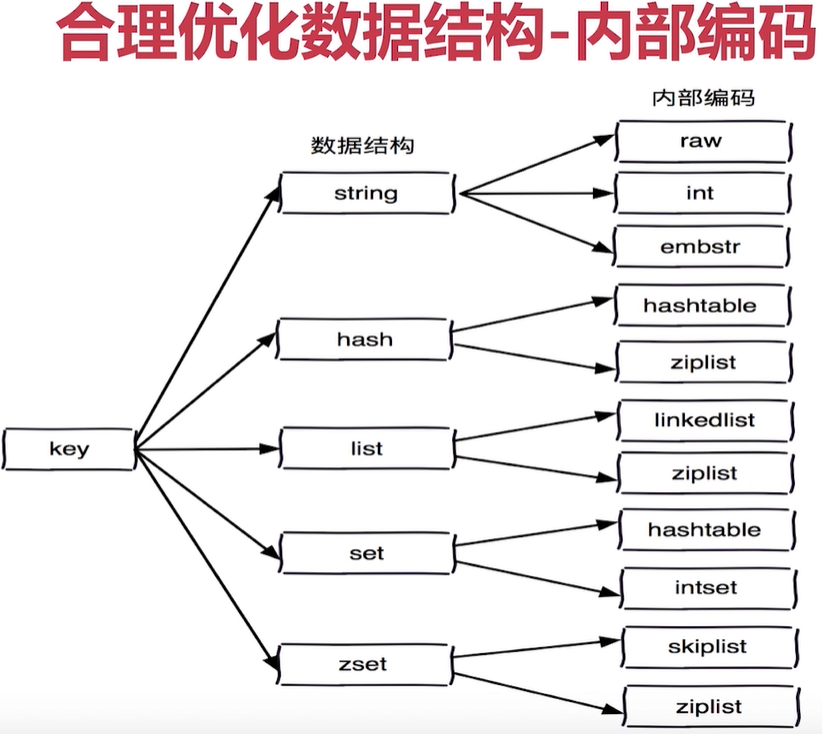
選擇合理的資料結構
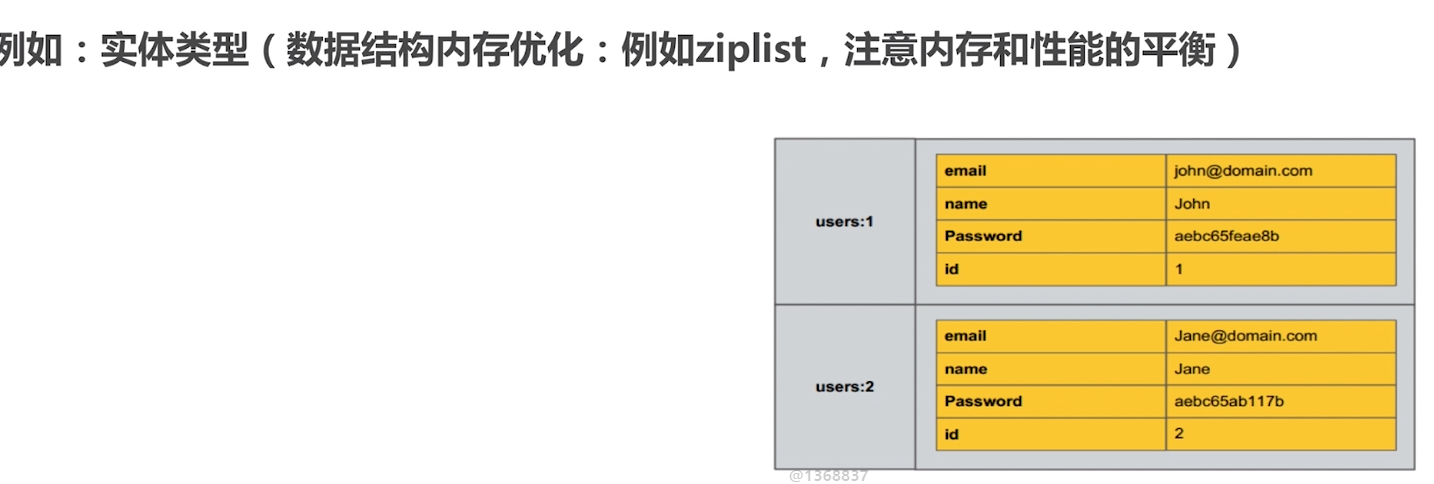

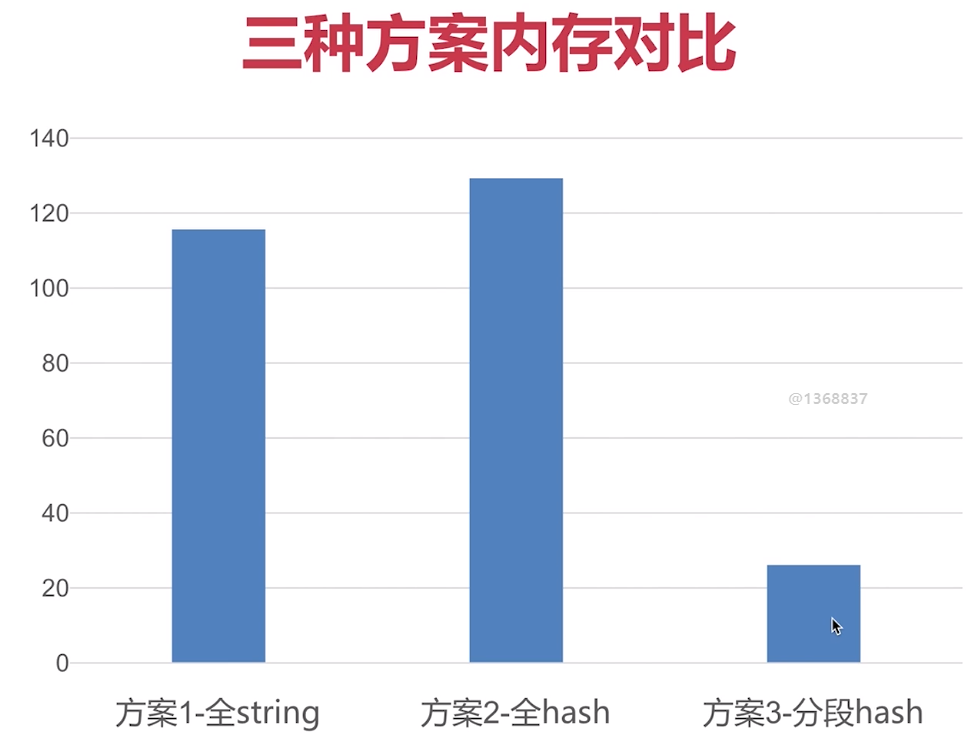

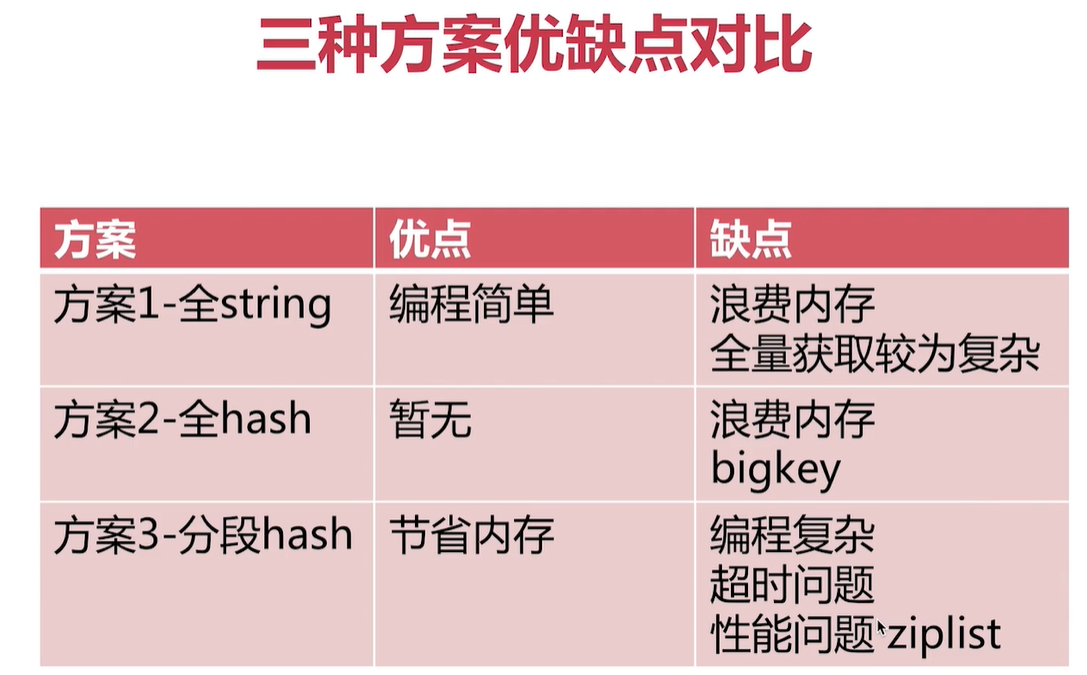
鍵值生命週期

命令優化






或者monitor 在redis 本地執行
redis客戶端優化


連線池引數優化
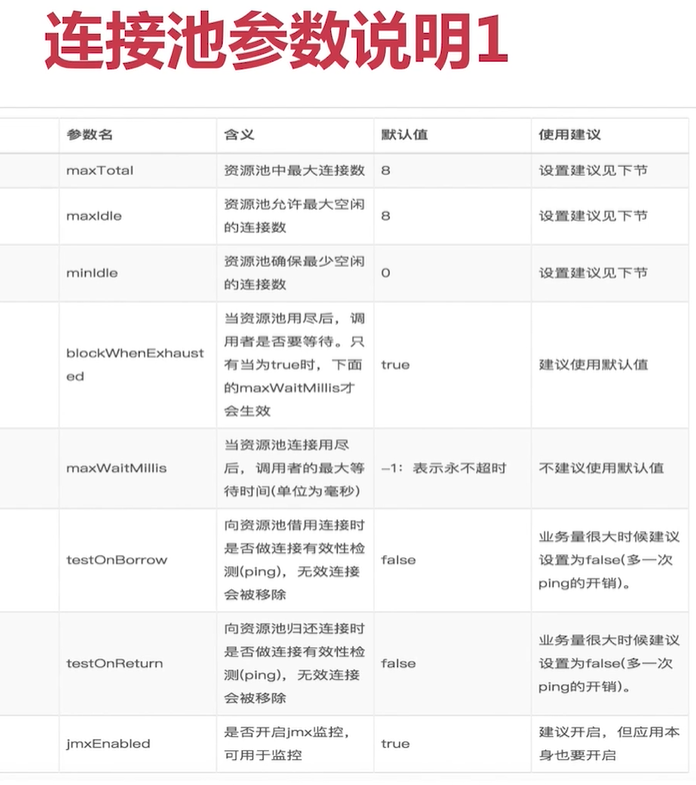
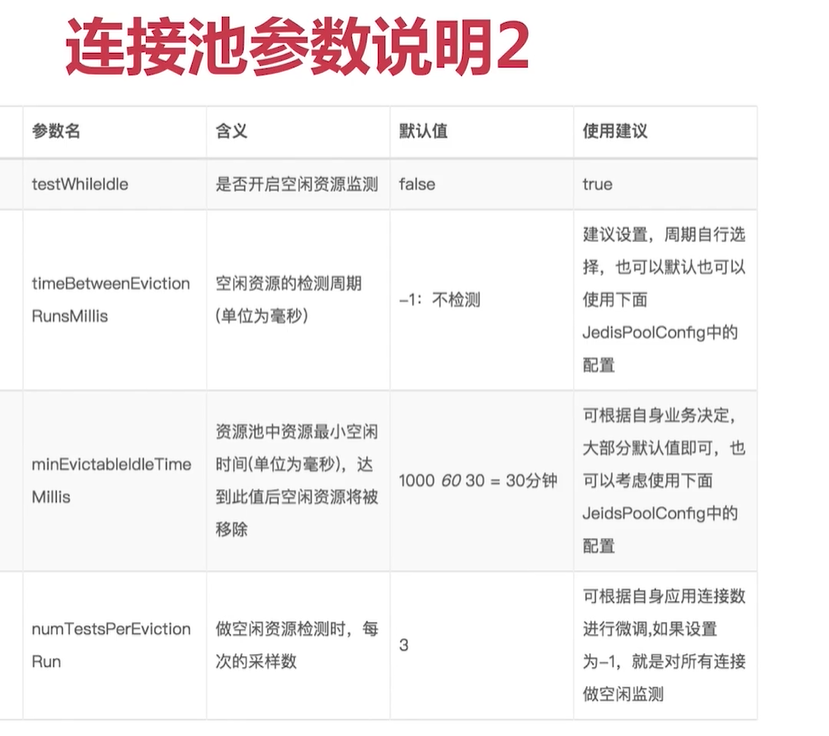
如何預估最大連線池

客戶端執行命令越短,maxTotal 就可以設定的越小


redis 記憶體優化
記憶體消耗
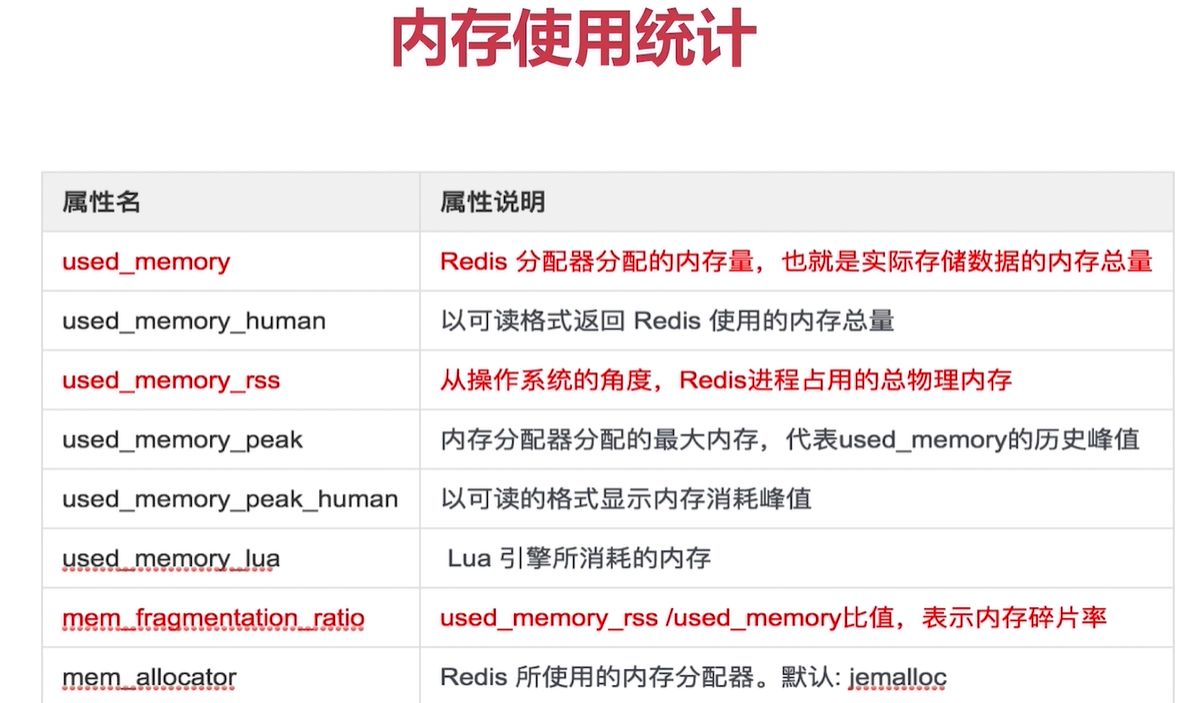
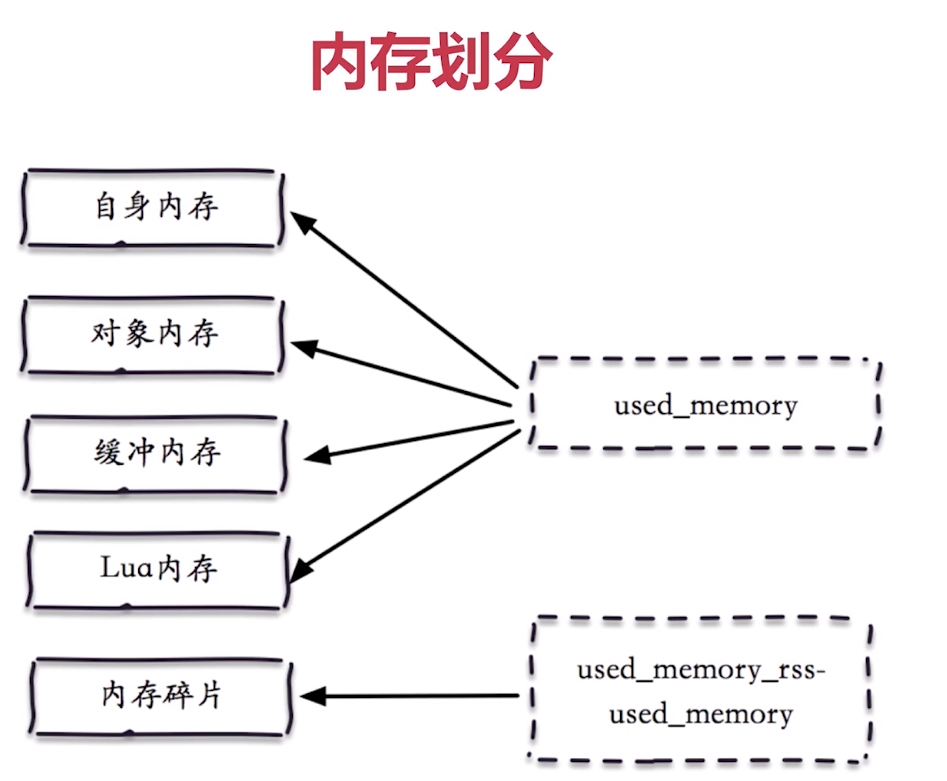
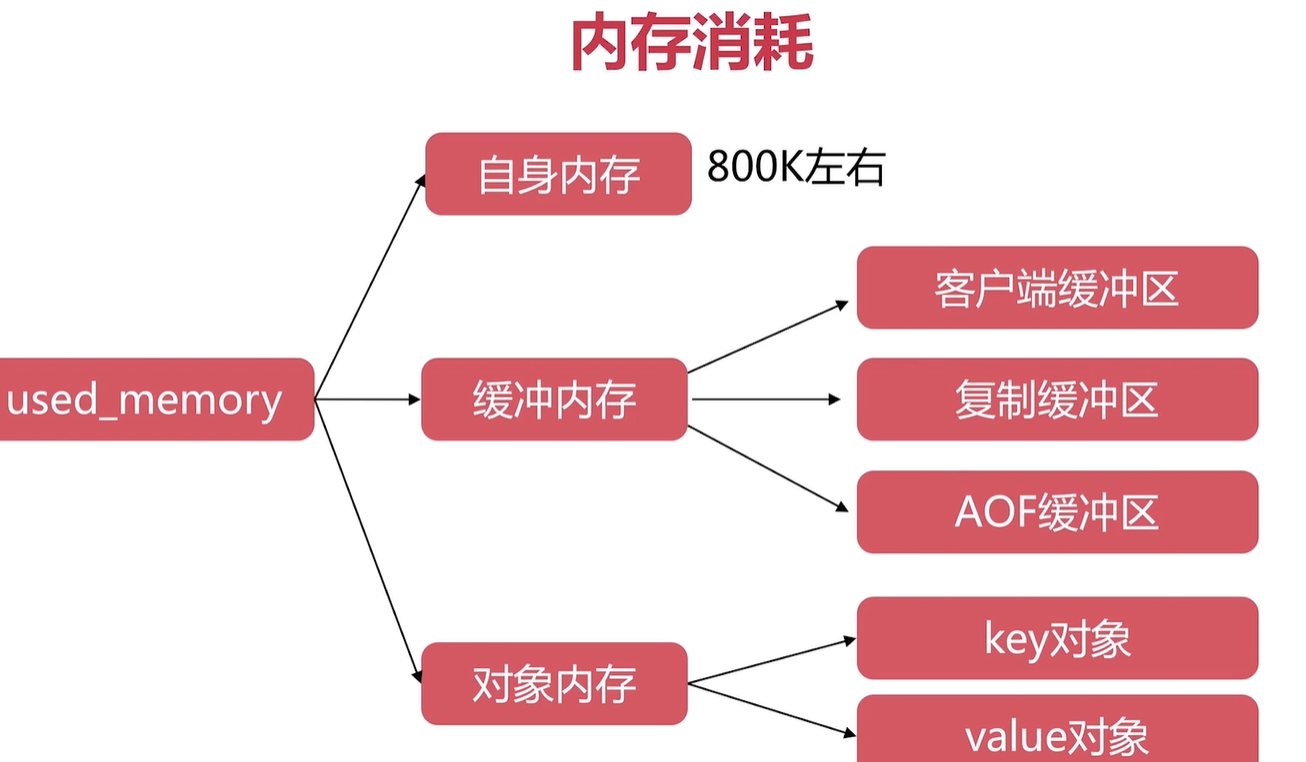
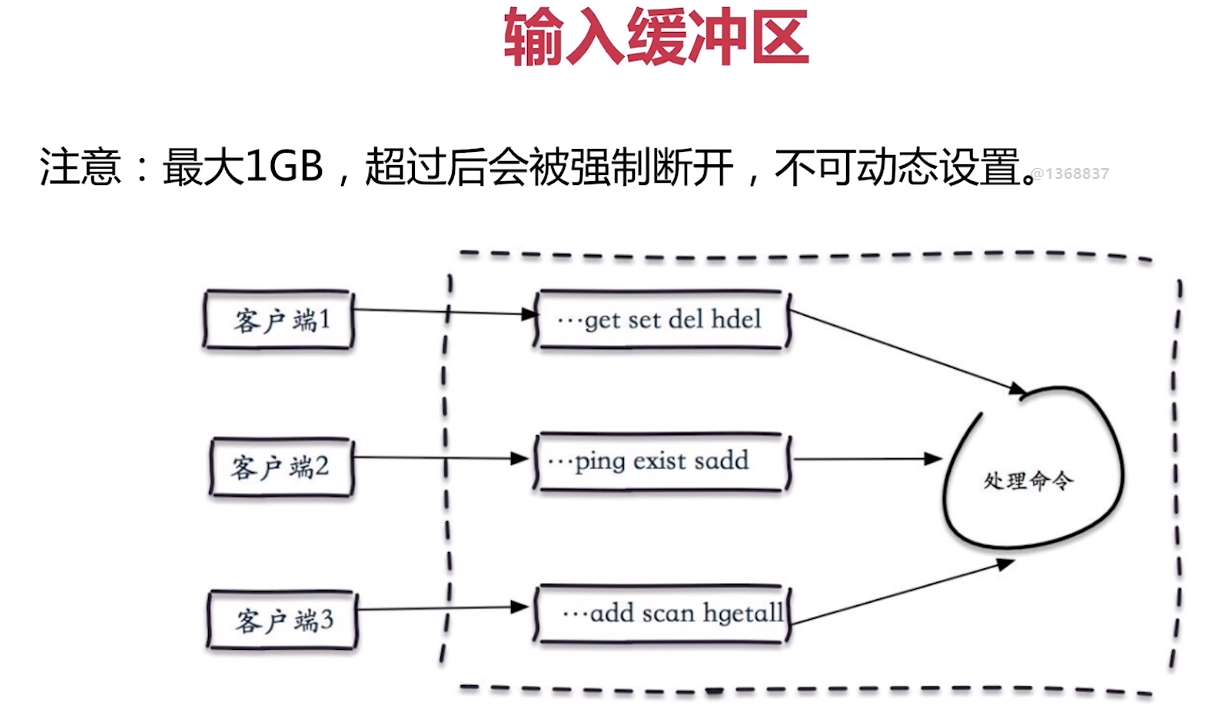
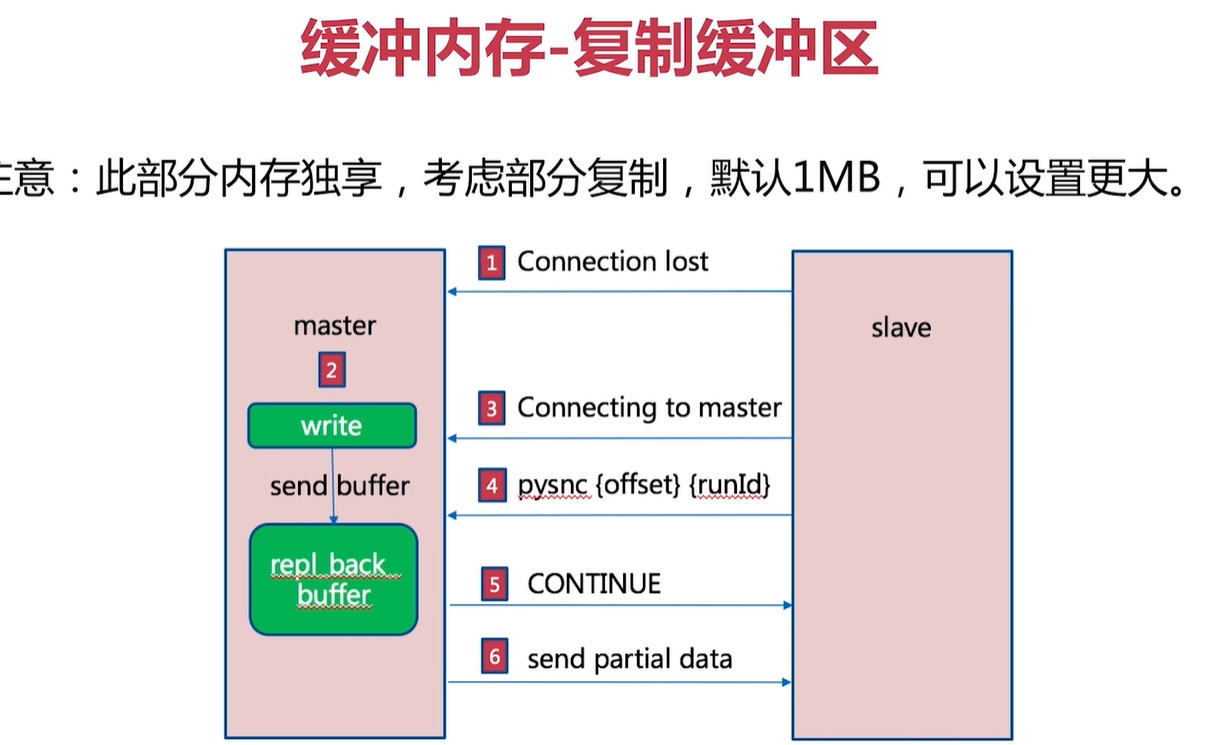
客戶端快取區




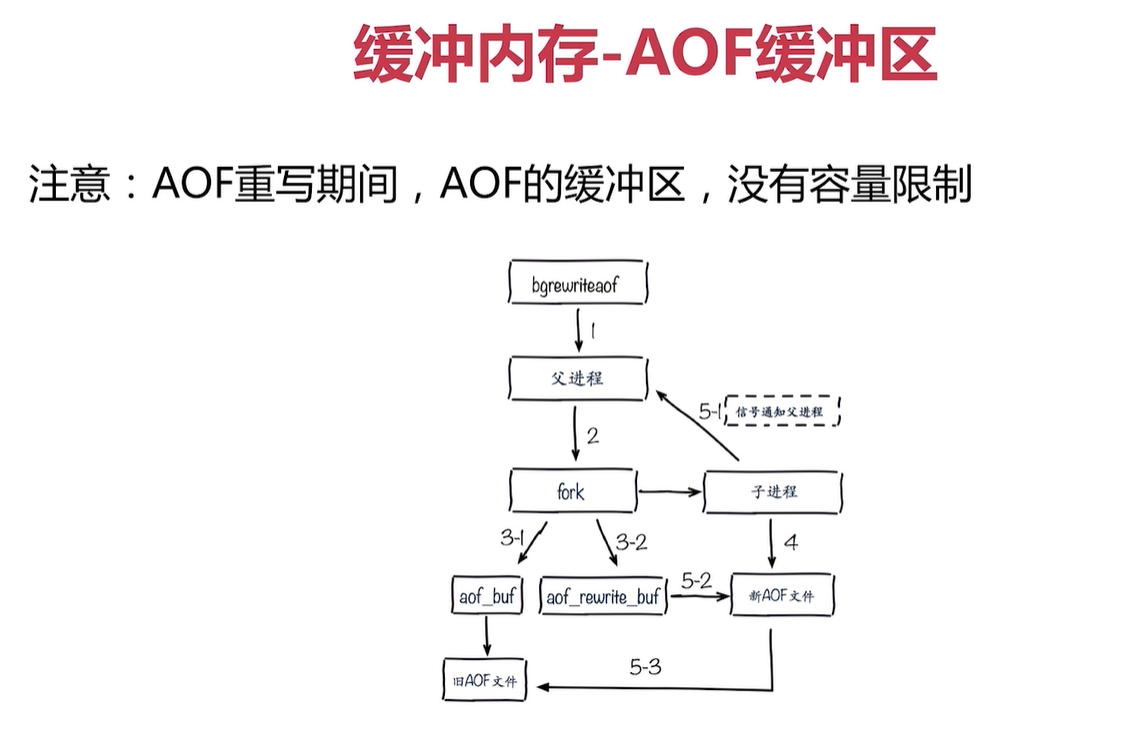
物件記憶體

記憶體碎片



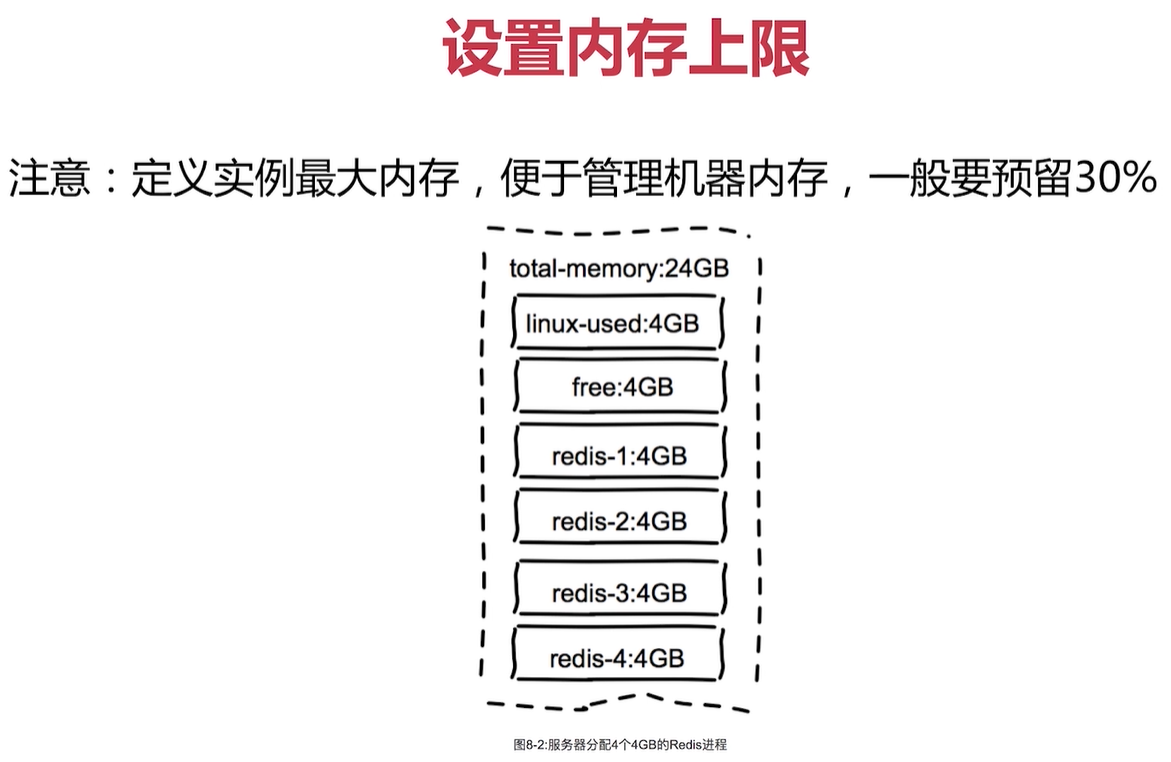
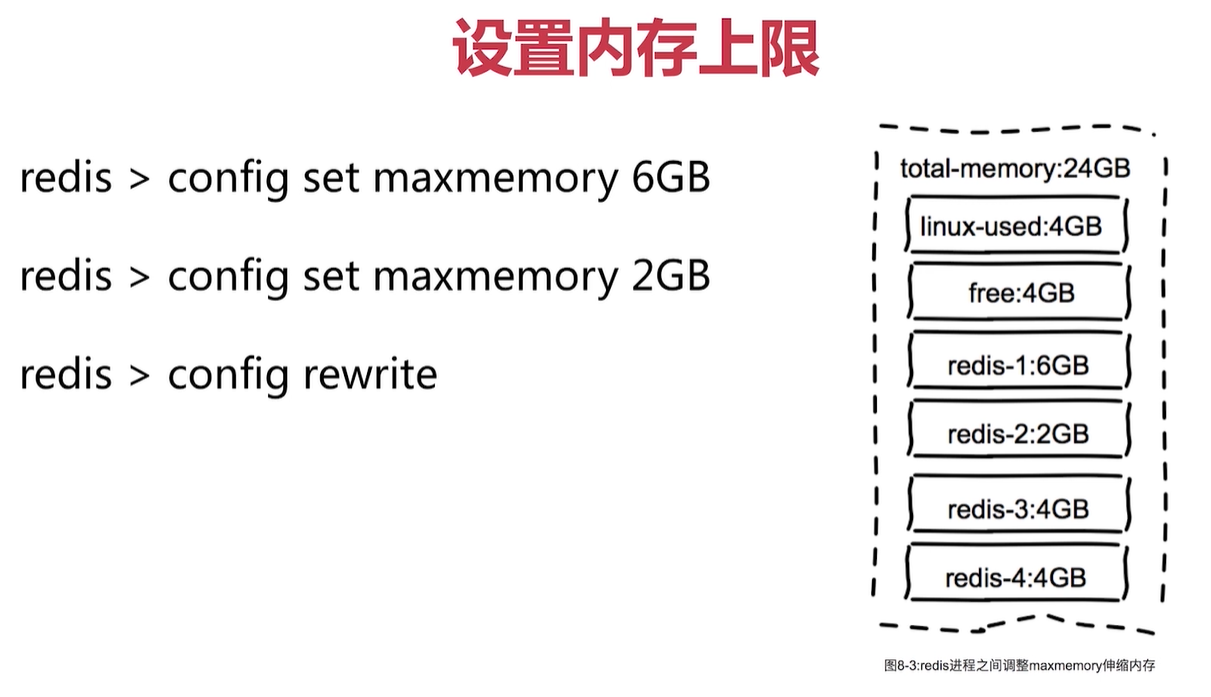
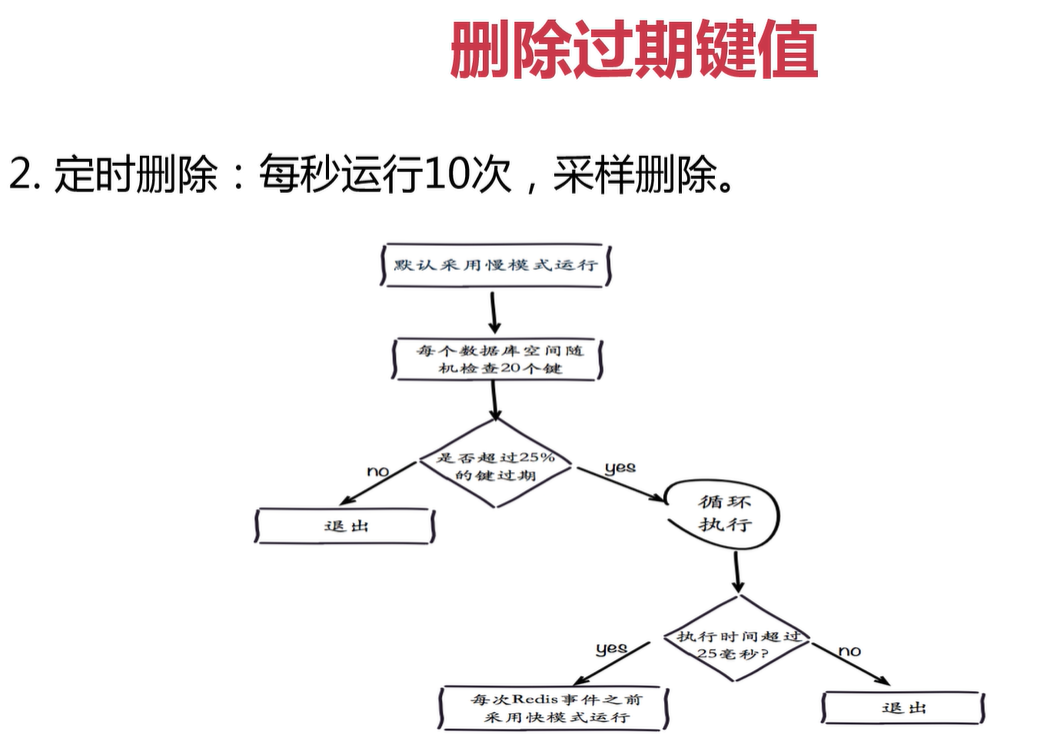
記憶體溢位策略


記憶體優化
合理選擇資料結構,
客戶快取區優化
客戶端溢位


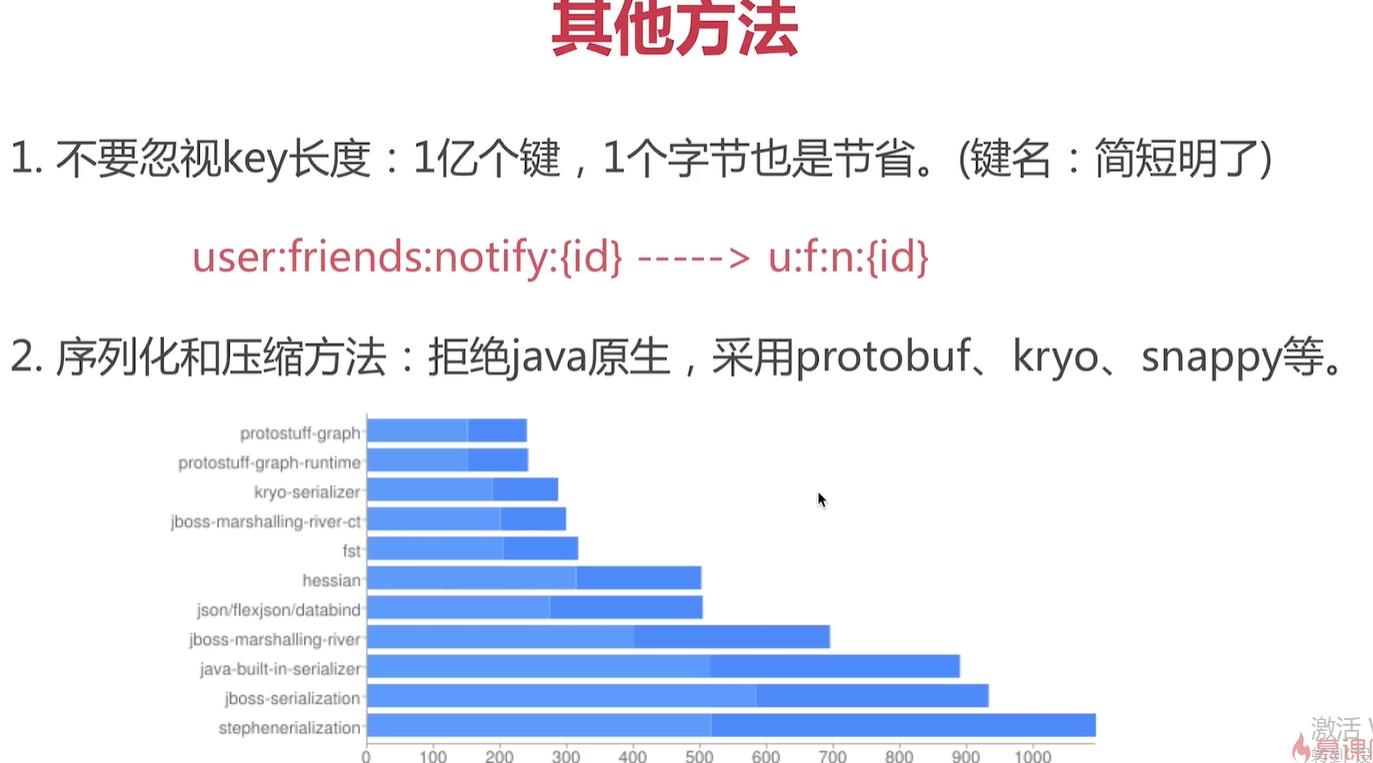
其他方法
大資料,冷資料, 不適合放在redis中
關係型,訊息佇列 資料也不適合放在 redis 中
開發運維的坑
Linux 核心優化 適合 redis

overcommit




swappiness



THP

加快 fork ,壞處就是 可能出現 慢查詢

OOM killer


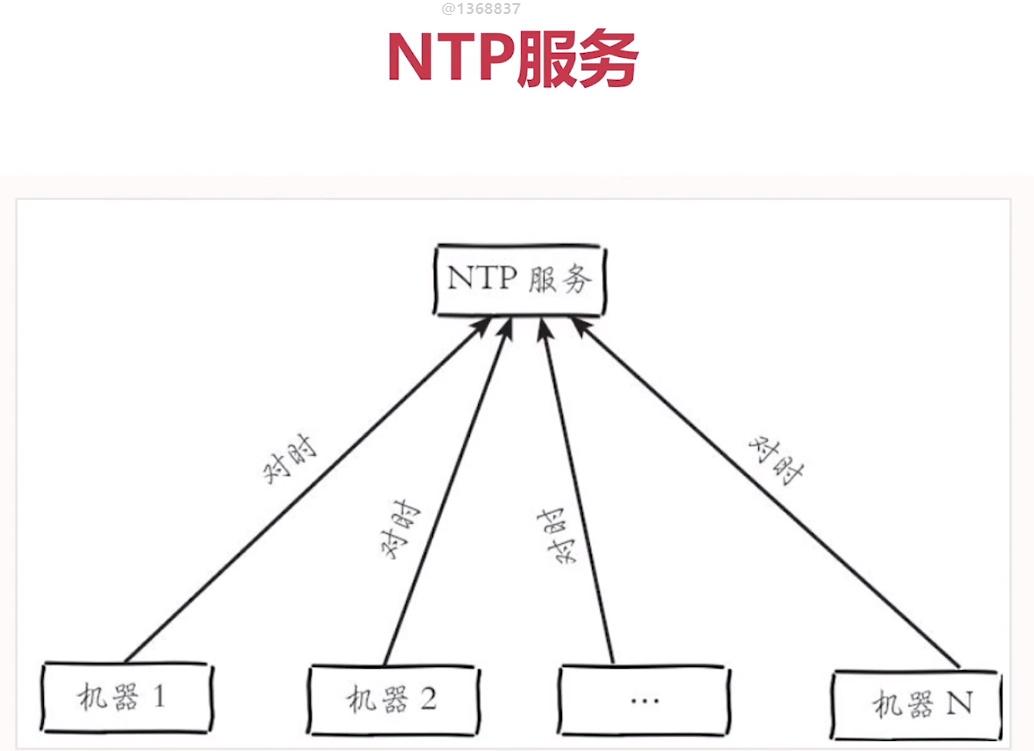
NTP 時鐘 保證機器之間 時鐘一致
ulimit

TCP backlog

安全的redis


安全七法
設定密碼




熱點key

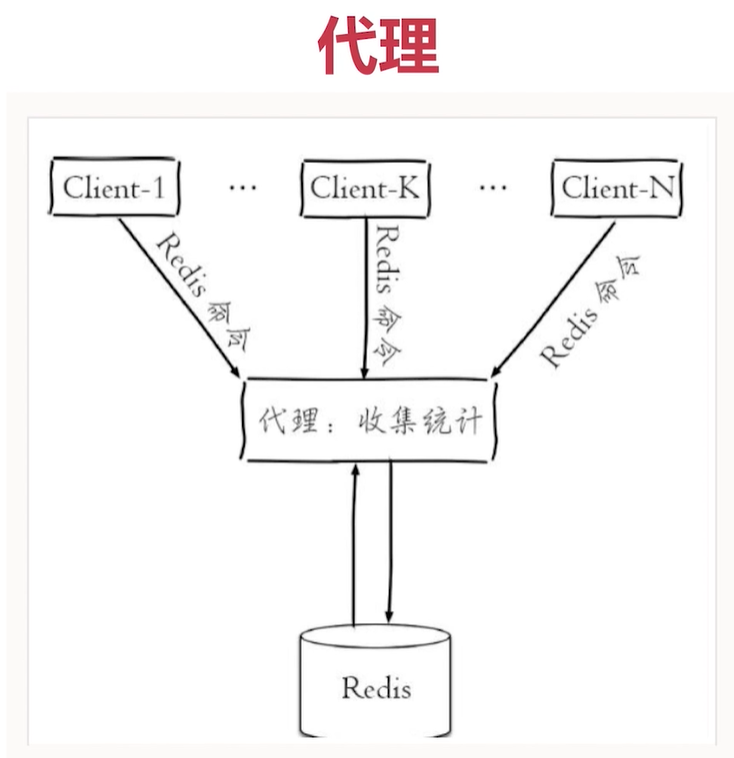
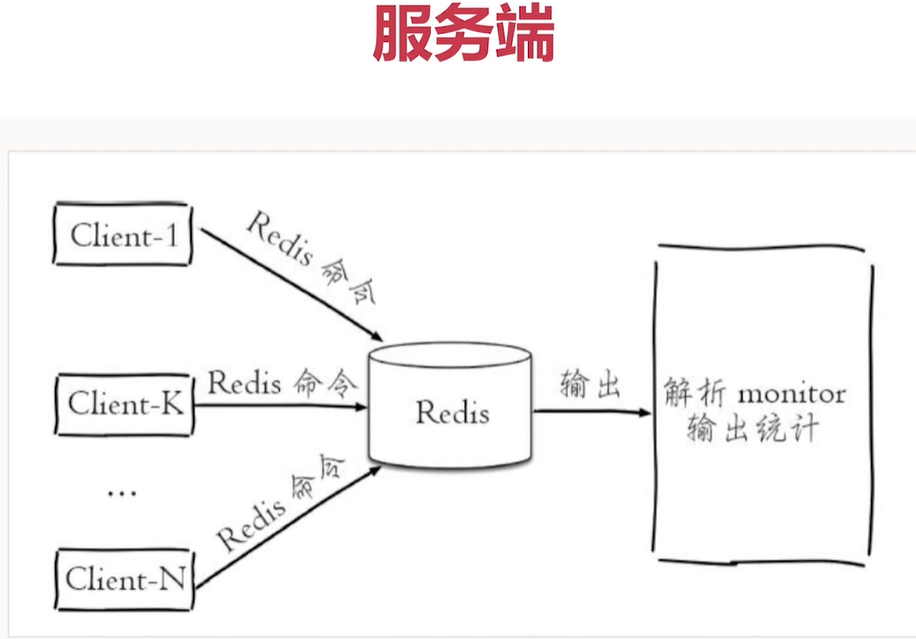
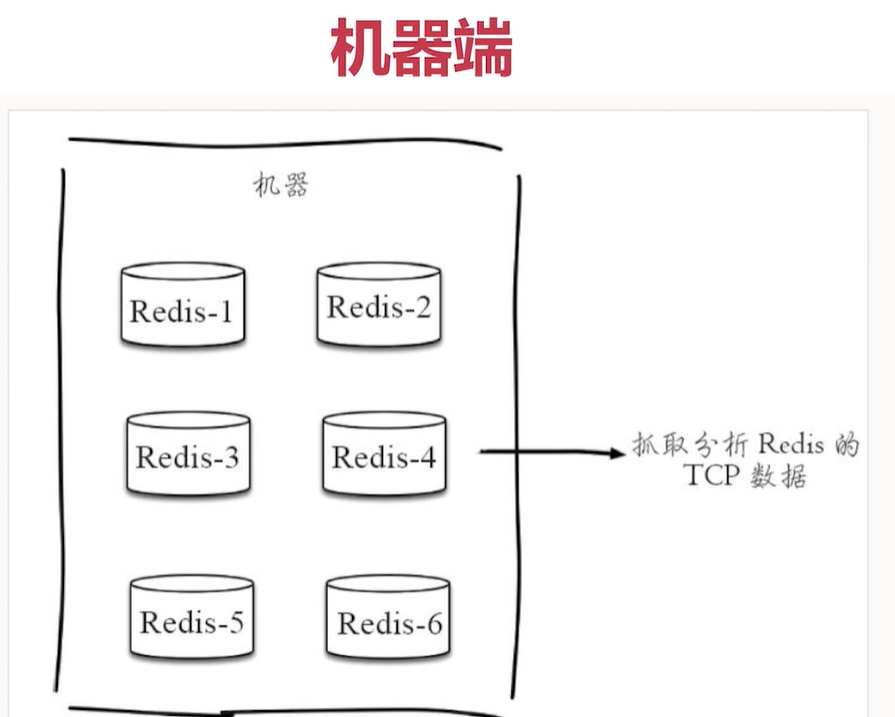
以上是找到 熱點key 的思路