
正則表示式-Regex詳解

1.什麼是正則表示式
正則表示式是對字串操作的一種邏輯公式,就是用事先定義好的一些特定字元、及這些特定字元的組合,組成一個“規則字串”,這個“規則字串”用來表達對字串的一種過濾邏輯。給定一個正則表示式和另一個字串,可以通過正則表示式從字串中獲取我們想要的特定部分。正則表示式靈活性、邏輯性和功能性非常強,可以迅速地用極簡單的方式達到字串額複雜控制,但對於共接觸的人來說比較晦澀難懂。由於正則表示式主要應用物件是文字,因此他在各種文字編輯器場合都有應用。
2.概念
正則表示式,又稱規則表示式。(英語:Regular Expression,在程式碼中常簡寫為regex、regexp或RE),電腦科學的一個概念。正則表示式通常被用來檢索、替換那些符合某個模式(規則)的文字。許多程式設計語言都支援利用正則表示式進行字串操作。例如,在Perl中就內建了一個功能強大的正則表示式引擎。正則表示式這個概念最初是由Unix中的工具軟體(例如sed和grep)普及開的。正則表示式通常縮寫成“regex”,單數有regexp、regex,複數有regexps、regexes、regexen。3.語法
您很可能使用 ? 和 * 萬用字元來查詢硬碟上的檔案。? 萬用字元匹配檔名中的 0 個或 1 個字元,而 * 萬用字元匹配零個或多個字元。下面先給出一個簡單的示例1
正則表示式規則: ^[0-9]+abc$
^ 為匹配輸入字串的開始位置。
[0-9]+匹配多個數字, [0-9] 匹配單個數字,+ 匹配"+"號前面的字元(這裡是數字[0-9])一個或者多個。
abc$匹配字母 abc 並以 abc 結尾,$ 為匹配輸入字串的結束位置。
以上的正則表示式可以匹配 123abc, 0abc, 但是不可以匹配 123abcd,abc, 因為不符合正則表示式規則
示例2
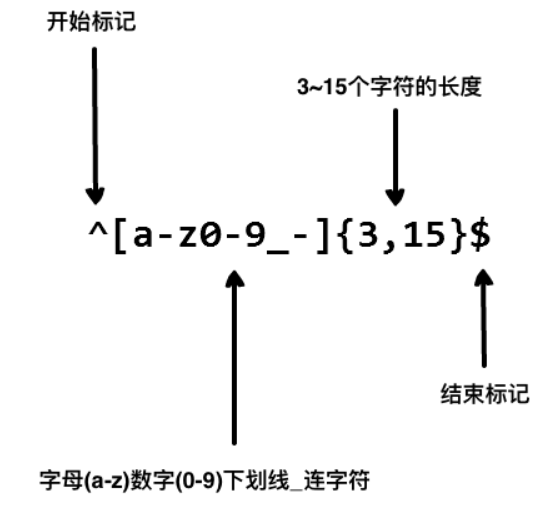
以上的正則表示式可以匹配 runoob、runoob1、run-oob、run_oob, 但不匹配 ru,因為它包含的字母太短了,小於 3 個無法匹配。也不匹配 runoob$, 因為它包含特殊字元。
正則表示式線上測試工具
https://c.runoob.com/front-end/854
https://regex101.com/($$推薦)

正則表示式(regular expression)描述了一種字串匹配的模式(pattern),可以用來檢查一個串是否含有某種子串、將匹配的子串替換或者從某個串中取出符合某個條件的子串等。
例如:
-
runoo+b,可以匹配 runoob、runooob、runoooooob 等,+ 號代表前面的字元必須至少出現一次(1次或多次)。
-
runoo*b,可以匹配 runob、runoob、runoooooob 等,* 號代表字元可以不出現,也可以出現一次或者多次(0次、或1次、或多次)。
-
colou?r 可以匹配 color 或者 colour,? 問號代表前面的字元最多隻可以出現一次(0次、或1次)。
構造正則表示式的方法和建立數學表示式的方法一樣。也就是用多種元字元與運算子可以將小的表示式結合在一起來建立更大的表示式。正則表示式的元件可以是單個的字元、字元集合、字元範圍、字元間的選擇或者所有這些元件的任意組合。
正則表示式是由普通字元(例如字元 a 到 z)以及特殊字元(稱為"元字元")組成的文字模式。模式描述在搜尋文字時要匹配的一個或多個字串。正則表示式作為一個模板,將某個字元模式與所搜尋的字串進行匹配。
4.表示式全集
| 字元 | 描述 |
|---|---|
| \ | 將下一個字元標記為一個特殊字元、或一個原義字元、或一個向後引用、或一個八進位制轉義符。例如,“n”匹配字元“n”。“\n”匹配一個換行符。序列“\\”匹配“\”而“\(”則匹配“(”。 |
| ^ | 匹配輸入字串的開始位置。如果設定了RegExp物件的Multiline屬性,^也匹配“\n”或“\r”之後的位置。 |
| $ | 匹配輸入字串的結束位置。如果設定了RegExp物件的Multiline屬性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表示式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等價於{0,}。 |
| + | 匹配前面的子表示式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等價於{1,}。 |
| ? | 匹配前面的子表示式零次或一次。例如,“do(es)?”可以匹配“does”或“does”中的“do”。?等價於{0,1}。 |
| {n} | n是一個非負整數。匹配確定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的兩個o。 |
| {n,} | n是一個非負整數。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等價於“o+”。“o{0,}”則等價於“o*”。 |
| {n,m} | m和n均為非負整數,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”將匹配“fooooood”中的前三個o。“o{0,1}”等價於“o?”。請注意在逗號和兩個數之間不能有空格。 |
| ? | 當該字元緊跟在任何一個其他限制符(*,+,?,{n},{n,},{n,m})後面時,匹配模式是非貪婪的。非貪婪模式儘可能少的匹配所搜尋的字串,而預設的貪婪模式則儘可能多的匹配所搜尋的字串。例如,對於字串“oooo”,“o+?”將匹配單個“o”,而“o+”將匹配所有“o”。 |
| . | 匹配除“\n”之外的任何單個字元。要匹配包括“\n”在內的任何字元,請使用像“(.|\n)”的模式。 |
| (pattern) | 匹配pattern並獲取這一匹配。所獲取的匹配可以從產生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中則使用$0…$9屬性。要匹配圓括號字元,請使用“\(”或“\)”。 |
| (?:pattern) | 匹配pattern但不獲取匹配結果,也就是說這是一個非獲取匹配,不進行儲存供以後使用。這在使用或字元“(|)”來組合一個模式的各個部分是很有用。例如“industr(?:y|ies)”就是一個比“industry|industries”更簡略的表示式。 |
| (?=pattern) | 正向肯定預查,在任何匹配pattern的字串開始處匹配查詢字串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜尋,而不是從包含預查的字元之後開始。 |
| (?!pattern) | 正向否定預查,在任何不匹配pattern的字串開始處匹配查詢字串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜尋,而不是從包含預查的字元之後開始 |
| (?<=pattern) | 反向肯定預查,與正向肯定預查類擬,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 |
| (?<!pattern) | 反向否定預查,與正向否定預查類擬,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”則匹配“zood”或“food”。 |
| [xyz] | 字元集合。匹配所包含的任意一個字元。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 負值字元集合。匹配未包含的任意字元。例如,“[^abc]”可以匹配“plain”中的“p”。 |
| [a-z] | 字元範圍。匹配指定範圍內的任意字元。例如,“[a-z]”可以匹配“a”到“z”範圍內的任意小寫字母字元。 |
| [^a-z] | 負值字元範圍。匹配任何不在指定範圍內的任意字元。例如,“[^a-z]”可以匹配任何不在“a”到“z”範圍內的任意字元。 |
| \b | 匹配一個單詞邊界,也就是指單詞和空格間的位置。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B | 匹配非單詞邊界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由x指明的控制字元。例如,\cM匹配一個Control-M或回車符。x的值必須為A-Z或a-z之一。否則,將c視為一個原義的“c”字元。 |
| \d | 匹配一個數字字元。等價於[0-9]。 |
| \D | 匹配一個非數字字元。等價於[^0-9]。 |
| \f | 匹配一個換頁符。等價於\x0c和\cL。 |
| \n | 匹配一個換行符。等價於\x0a和\cJ。 |
| \r | 匹配一個回車符。等價於\x0d和\cM。 |
| \s | 匹配任何空白字元,包括空格、製表符、換頁符等等。等價於[ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字元。等價於[^ \f\n\r\t\v]。 |
| \t | 匹配一個製表符。等價於\x09和\cI。 |
| \v | 匹配一個垂直製表符。等價於\x0b和\cK。 |
| \w | 匹配包括下劃線的任何單詞字元。等價於“[A-Za-z0-9_]”。 |
| \W | 匹配任何非單詞字元。等價於“[^A-Za-z0-9_]”。 |
| \xn | 匹配n,其中n為十六進位制轉義值。十六進位制轉義值必須為確定的兩個數字長。例如,“\x41”匹配“A”。“\x041”則等價於“\x04&1”。正則表示式中可以使用ASCII編碼。. |
| \num | 匹配num,其中num是一個正整數。對所獲取的匹配的引用。例如,“(.)\1”匹配兩個連續的相同字元。 |
| \n | 標識一個八進位制轉義值或一個向後引用。如果\n之前至少n個獲取的子表示式,則n為向後引用。否則,如果n為八進位制數字(0-7),則n為一個八進位制轉義值。 |
| \nm | 標識一個八進位制轉義值或一個向後引用。如果\nm之前至少有nm個獲得子表示式,則nm為向後引用。如果\nm之前至少有n個獲取,則n為一個後跟文字m的向後引用。如果前面的條件都不滿足,若n和m均為八進位制數字(0-7),則\nm將匹配八進位制轉義值nm。 |
| \nml | 如果n為八進位制數字(0-3),且m和l均為八進位制數字(0-7),則匹配八進位制轉義值nml。 |
| \un | 匹配n,其中n是一個用四個十六進位制數字表示的Unicode字元。例如,\u00A9匹配版權符號(©)。 |
5.常用正則表示式
| 使用者名稱 | /^[a-z0-9_-]{3,16}$/ |
|---|---|
| 密碼 | /^[a-z0-9_-]{6,18}$/ |
| 十六進位制值 | /^#?([a-f0-9]{6}|[a-f0-9]{3})$/ |
| 電子郵箱 | /^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/ /^[a-z\d]+(\.[a-z\d]+)*@([\da-z](-[\da-z])?)+(\.{1,2}[a-z]+)+$/ |
| URL | /^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/ |
| IP 地址 | /((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)/ /^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/ |
| HTML 標籤 | /^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/ |
| 刪除程式碼\\註釋 | (?<!http:|\S)//.*$ |
| Unicode編碼中的漢字範圍 | /^[\u2E80-\u9FFF]+$/ |


6.為什麼使用正則表示式?
典型的搜尋和替換操作要求您提供與預期的搜尋結果匹配的確切文字。雖然這種技術對於對靜態文字執行簡單搜尋和替換任務可能已經足夠了,但它缺乏靈活性,若採用這種方法搜尋動態文字,即使不是不可能,至少也會變得很困難。
通過使用正則表示式,可以:
- 測試字串內的模式。
例如,可以測試輸入字串,以檢視字串內是否出現電話號碼模式或信用卡號碼模式。這稱為資料驗證。 - 替換文字。
可以使用正則表示式來識別文件中的特定文字,完全刪除該文字或者用其他文字替換它。 - 基於模式匹配從字串中提取子字串。
可以查詢文件內或輸入域內特定的文字。
例如,您可能需要搜尋整個網站,刪除過時的材料,以及替換某些 HTML 格式標記。在這種情況下,可以使用正則表示式來確定在每個檔案中是否出現該材料或該 HTML 格式標記。此過程將受影響的檔案列表縮小到包含需要刪除或更改的材料的那些檔案。然後可以使用正則表示式來刪除過時的材料。最後,可以使用正則表示式來搜尋和替換標記。
7.發展歷史
正則表示式的"祖先"可以一直上溯至對人類神經系統如何工作的早期研究。Warren McCulloch 和 Walter Pitts 這兩位神經生理學家研究出一種數學方式來描述這些神經網路。
1956 年, 一位叫 Stephen Kleene 的數學家在 McCulloch 和 Pitts 早期工作的基礎上,發表了一篇標題為"神經網事件的表示法"的論文,引入了正則表示式的概念。正則表示式就是用來描述他稱為"正則集的代數"的表示式,因此採用"正則表示式"這個術語。
隨後,發現可以將這一工作應用於使用 Ken Thompson 的計算搜尋演算法的一些早期研究,Ken Thompson 是 Unix 的主要發明人。正則表示式的第一個實用應用程式就是 Unix 中的 qed 編輯器。
如他們所說,剩下的就是眾所周知的歷史了。從那時起直至現在正則表示式都是基於文字的編輯器和搜尋工具中的一個重要部分。
8.應用領域
目前,正則表示式已經在很多軟體中得到廣泛的應用,包括 *nix(Linux, Unix等)、HP 等作業系統,PHP、C#、Java 等開發環境,以及很多的應用軟體中,都可以看到正則表示式的影子。
9.推薦書籍

參考:
https://www.runoob.com/regexp/regexp-tutorial.html
https://www.w3cschool.cn/zhengzebiaodashi/regexp-tutorial.html
https://regex101.